







摘要:
本文针对视频目标检测问题提出时空记忆网络。他的核心是时空记忆模块,作为一种递归计算单元去建模长时间目标外观和运动信息。STMM的设计使得可以用一个预训练的CNN主体结构初始化,这对提高检测精度非常重要。本文为了建模目标运动提出匹配变换去对齐视频中目标的运动。本文的方法在VID数据集上获得了state-of-art的结果,我们的受控实验证明了本文设计架构的有效性,代码和模型都公开在
http://fanyix.cs.ucdavis.edu/project/stmn/project.html
- 引言
视频检测的问题在于运动模糊、遮挡和极端的视点等,这使得图像检测器会出问题,但是视频提供了丰富的时空和运动信息,应该学习去集成他们,使得视频啊目标检测器更稳健。

从Fig1可以看出图像检测器在模糊、遮挡和极端视角下出现了误检,但是本文模型由于集成了前两帧目标质量较好的图像所以成功检测了出来。最近,很多研究者开始研究视频目标检测问题,比较有名的微软的2017ICCV和2018CVPR的FGFA模型[50,51],2017CVPR的商汤的T-CNN[24,25],2016年的seq-nms[19],2017ICCV牛津VGG组的D&T[14],还有2015年的工作[18],其实视频检测的研究最早大概在2015年左右,ImageNet用VID数据集组织视频检测比赛。这里面很多工作是通过后处理的方式,不能避免单帧检测器的失败。[14,50,51]开始在模型的训练中,通过预测帧间的平移,将帧与帧之间的特征集成起来。然而这些方法处理的是固定长度窗口的图像,不能建模较长的依赖性。[25]TPN开始考虑建模长时间的信息,但是速度比较慢,对管道的初始化依赖严重。
为了解决这些问题,我们提出Spatial-Temporal Memory Network(STMN),用一个网络统一建模长时间的外观和运动。他的核心为Spatial-Temporal Memory Module,一种卷积递归计算,可以集成到从静态图像训练得到的预训练模型中。这种设计在实际应用中是有用的,因为一个一百万张图像的图片数据集多样性要比一百万张图片的视频数据集好很多。本文显示这种设计比标准的ConvGRU要好。考虑到图像数据的二维特性,STMM中保留了每帧图像的二维空间信息。为了实现帧间的像素级对齐,本文提出MatchTran模块显式建模帧间的平移。由于每帧的图像是对齐的,集成的,这种特征对于区域的定位是有好处的,而且包含多帧信息对识别也好。同时每个区域的特征也可以用ROI Pooling从记忆模块中提取。
基于以上工作,本文在VID数据集中用不同的backbone和检测器均获得state-of-art的效果。 - 相关工作
视频目标检测:
与本文类似的工作是[50,51]通过集成多帧特征来提高精度,但是与他们前后取多帧不同的是,本文采用时空记忆单元可以保留长时间的信息。[24]采用一个向量集成帧间信息,丢失了图像本身的二维信息,并且对每个管道单独计算特征向量,这使得系统比较慢,相比而言,本文一帧计算一个特征空间,和区域特征的计算是独立的。[14]试图将检测跟踪统一到一个框架中,他计算两帧之间的相关性来预测框的平移量,本文集成的不止两帧的信息,我们也计算帧间的相关性是使用MatchTran模块,不过计算的结果不是用来预测框的平移而是用来对齐特征图。总之这些技巧使我们的工作在VID数据集上获得了state-of-art的结果
RNN序列建模:
在CV领域中,RNN被用来做图像描述、visual attention、行为识别、人体姿势估计和语义分割。[43]2016年的一个工作,将RNN用于视频目标检测,不过在他们的网络中首先训练CNN来检测,再训练RNN去精修CNN的输出结果。虽然RNN在CV中广泛应用,但是大多是以向量的形式存在的,丢失了位置信息,[4]提出convGRU用来做行为识别,[41]用来做视频目标分割。本文这里用来做bbox的分类,同时可以使用Imagenet初始化,并且加入了MatchTran模块,这使得整个系统优于标准的ConvGRU. - 方法
3.1 概述:
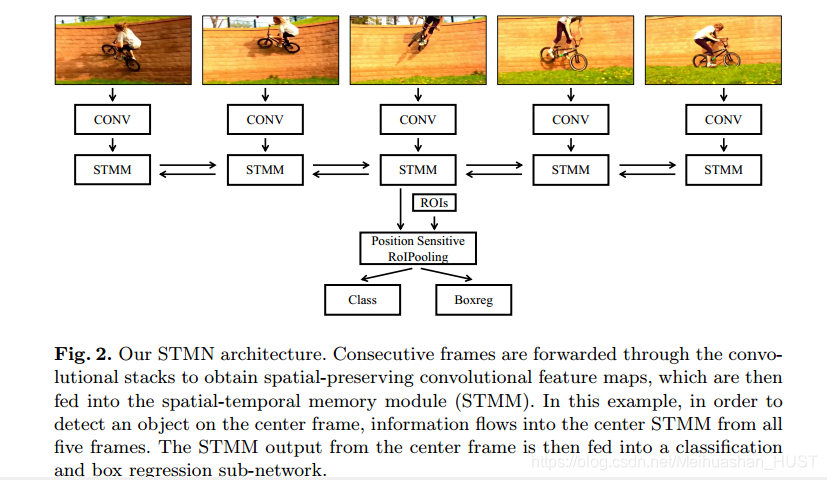
系统结构如Fig2所示,假设视频序列的长度为T,每一帧图像首先提取卷积特征得到F1,F2,F3.…Ft作为表观特征,为了沿时间轴集成这些特征,每一帧的Fi送入STMM,STMM获得Ft后结合Mt-1,Mt-1融合了之前所有帧的信息,然后更新为Mt,注意到这里的时间线是双向的,Mt 包含了时间信息,再送到卷积/全连接层进行分类和回归。这种做法的提升在于,如Fig2,图像检测器往往只看过自行车的侧视图,所以看到前视图的时候就会识别不出来,但是本文的方法,他已经看过了两边的侧视图,所以他识别出前视图会容易一些。
3.2 STMM
在每一帧输入Ft和Mt-1
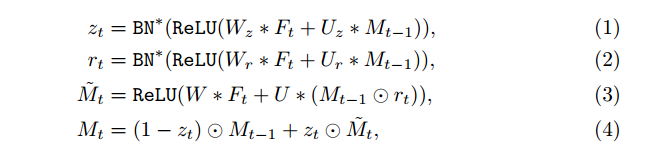
这里圈表示点乘,星号表说卷积。rt为更新门,表示Mt-1里有多少需要忘掉,从而生成暂时的Mt’,zt为重置门决定了之前的状态Mt-1和暂时的状态Mt’以怎样的权重融合生成Mt。为了生成门,首先对Ft和Mt-1做放射变换,再relu,由于门是0到1之间的数,所以这里用的BN*,但不是均值为0,标准差为1的分布,因为两个不同的地方,首先,计算batch的均值和标准差,然后根据Fig3的函数归一化。

第二每个batch独立计算均值和标准差,而不是用传统夫人BN的指数加权的方式,这使得我们测试的时候不用视训练的长度而定。(这一段其实个人都是不理解的,为什么是BN,为什么这么改)
和传统ConvGRU不同的地方。视频检测训练的过程中的一个现实的问题就是,视频的冗余性,使得数据的多样化和图像数据集没法比,所以希望能迁移图像数据集中的训练结果。本文用RFCN初始化网络,将PSROI Pooling的前一个卷积层替换为本文的STMM,由于RFCN的激活函数是ReLU所以他的输出都是非负的,而传统的ConvGRU的sigmod和tanh函数使得GRU部分的输出为[-1,1],这样是不匹配的,所以我们将GRU的激活函数改为ReLU,同时STMM的卷积层不是随机初始化而是用替换出去的卷积层的参数初始化。
3.3 时空信息对齐
由于目标的运动,如果不对齐的话,会造成融合的特征图长时间不能忘记目标的信息,
造成虚警,而且和其他特征图重叠之后,会降低特征图的质量。就像Fig4所示。

为了解决这个问题,对于Ft(x,y)的邻域,本文在Ft-1图的(x,y)处2k+1*2k+1邻域计算相似性,使用余弦距离,公式如下所示
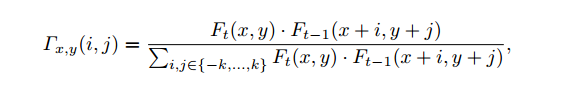
使用系数I,本文将非对齐的Mt-1变换到对齐的Mt-1,对齐公式如下
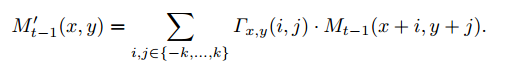
相当于用2k+1邻域内的Ft-1与Ft的相关系数,对Mt-1的特征图的值进行加权重构。对齐后的Mt-1才是最终的,也就是这部分之前提到的Mt-1.对齐的示意图如Fig5
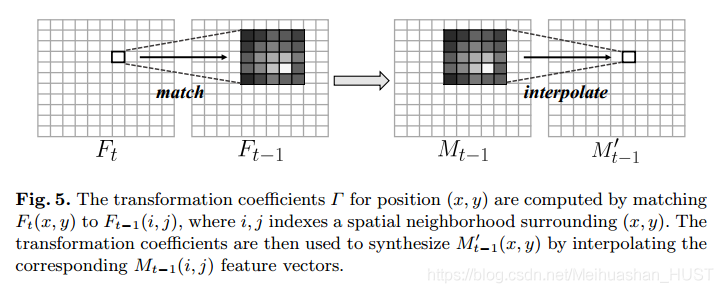
K的选择涉及到性能和速度的权衡,在我们的实验中选k=2.
类似的[50,51]有对齐的工作,光流动问题在于计算比较慢,而且需要存储光流这也占用了内存。对于FlowNet,他的速度是24.3ms,而我们的速度是2.9ms,有数量级的优势,但是上述方法的问题在于不是一个主流的解法,对于预测平移应用光流是自然的想法,是有理论支持的,而且不用关心k是否选的合适,本文的想法受[14]的启发,[14]是将相关系数送入网络进行bbox的预测,而本文是将他进行特征图的对齐。
3.4 使用Seq-NMS对输出的结果进行后处理 - 结果
检测器采用RFCN,训练并初始化STMN,训练的时候序列长度为7,测试的时候序列长
度为11,STMM特征图的通道数为512,考虑到视频的冗余性,每10帧采样一帧。
4.1 结果比较

在分类测试中,蛇、猴子、松鼠这三类结果最差,视频中这三类出现了较强的运动模糊和变形,STMM对他们的特征提取帮助不大。这里是有问题的,在自行车这个例子中,车子也出现了变形,为什么就可以了呢,这里存在疑问,正常来讲,特征集成就是解决这些问题的。
4.3 受控实验

最后一个是标准的ConvGRU,他采用sigmod和tanh作为激活函数,GRU的参数随机初始化得到44.8的分数,然后将sigmod和tanh改成relu,预训练后大迁移到VID数据集,使得准确率提升到48这个还是显著的,说明增加数据量对网络的好处,设计这种结构使得可以用更多的数据之前做预训练,但是最近KaiMing He不进行预训练,加入GN之后,随机初始化达到一样的效果,不过是在数据量足够多的前提下,这里的性能提升应该是数据量不够,所以用预训练就好一些。然后改成STMN,提升了1,加入特征对齐后,提升了1.7,特征对齐似乎重要性并不是那么高,或者是加权的对齐方式存在问题,起到的作用并不多,并没有做好特征对齐。
改变窗口大小,3,7,11,13性能为-1.9,0,0.7,1.0的性能提升,说明训练的时候视频序列越长,建模的时间信息越长,性能会更好。由于平台限制这里选取11.
4.4 时间开销
整个网络在TITAN X上0.028sec/frame具有较好的实时性














 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









