






笔者所在的公司生产环境之前部署的Kylin集群为:10.8.34.72(server.mode=all) ,10.8.34.80(server.mode=query) ,由于使用的用户越来越多,查询响应慢引起了用户的反感,前几天将集群部署调整为:10.8.34.72(server.mode=query) ,10.8.35.16(server.mode=query) ,10.8.34.80(server.mode=job) ,最近好几个cube在构建的时候,在第三个步骤Extract Fact Table Distinct Columns出现了IllegalStateException异常,如下图:
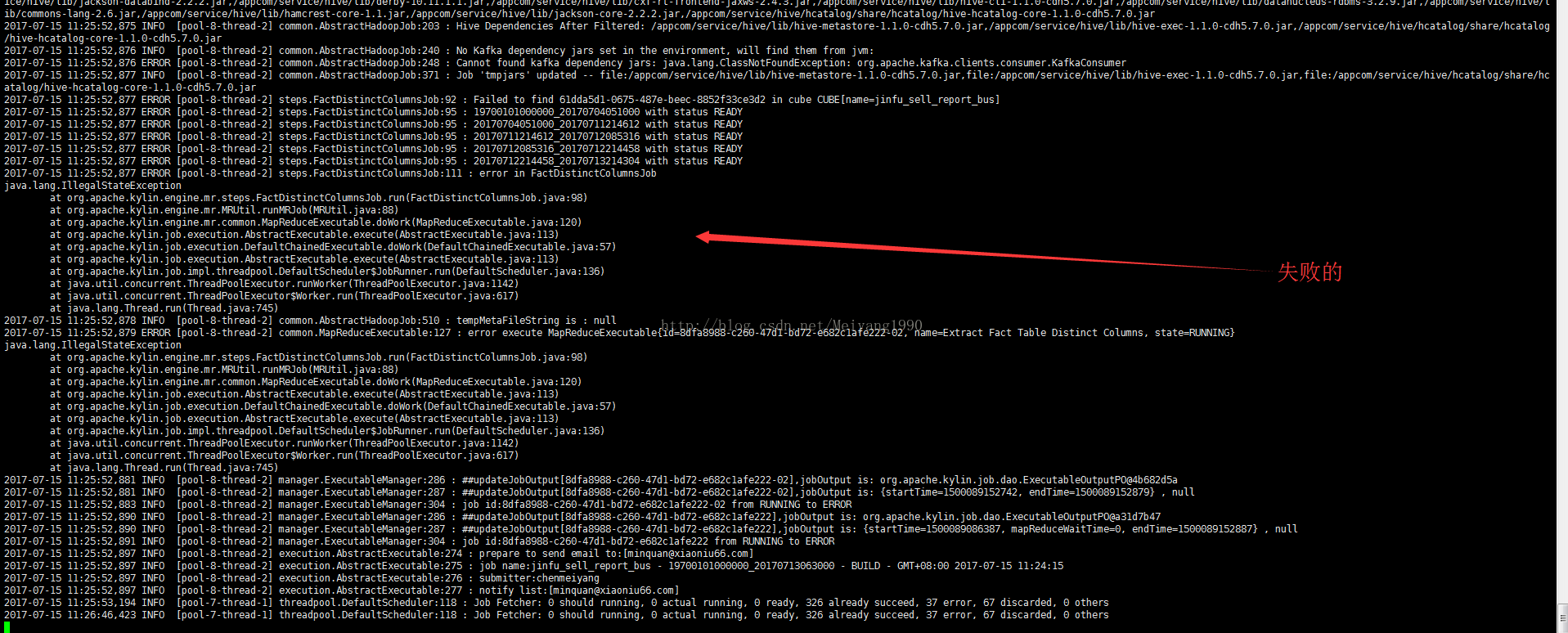
翻阅网上的资料,终于找出原因,应该是集群部署方式改变之后meta data同步 不正确导致的,经修改kylin.properties的配置项,重启kylin的所有节点,问题没有再出现了。
原配置项内容为:kylin.rest.servers=10.8.34.72:7070,10.8.34.80:7070
经修改,配置项内容为:kylin.rest.servers=10.8.34.72:7070,10.8.35.16:7070,10.8.34.80:7070(笔者以为34.80节点server.mode=job不需要添加进来 ,这个问题应该就是这个地方导致meta data无法同步)
转载文章: http://blog.bcmeng.com/post/kylin-case.html















 525
525

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









