









原文作者:Gustavo Duarte
原文地址:http://duartes.org/gustavo/blog/post/what-your-computer-does-while-you-wait
Cache: a place for concealment and safekeeping
This post shows briefly how CPU caches are organized in modern Intel processors. Cache discussions often lack concrete examples, obfuscating the simple concepts involved. Or maybe my pretty little head is slow. At any rate, here’s half the story on how a Core 2 L1 cache is accessed:
这篇文章简单阐述了现代Intel处理器是如何管理CPU的caches的。对于Cache的讨论通常都缺乏具体的例子,这通常容易使简单的概念被模糊化。或者可能是我的脑子不够用,所以不容易理解。无论如何,下面描述了一个Core2 的L1 cache是如何被访问的前半程描述:
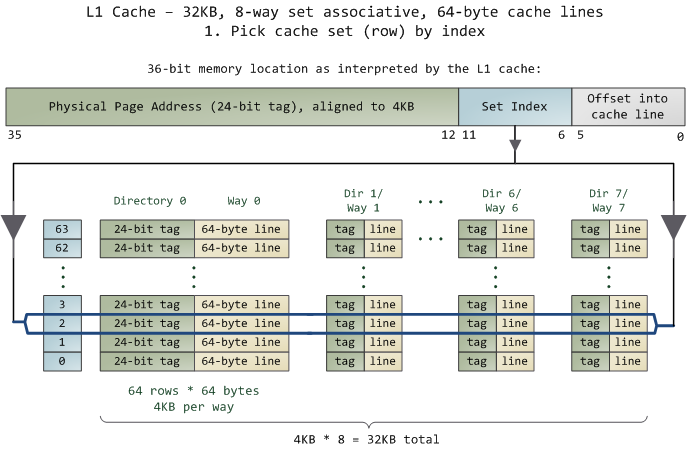
The unit of data in the cache is the line, which is just a contiguous chunk of bytes in memory. This cache uses 64-byte lines. The lines are stored in cache banks or ways, and each way has a dedicateddirectory to store its housekeeping information. You can imagine each way and its directory as columns in a spreadsheet, in which case the rows are the sets. Then each cell in the way column contains a cache line, tracked by the corresponding cell in the directory. This particular cache has 64 sets and 8 ways, hence 512 cells to store cache lines, which adds up to 32KB of space.
cache中的单位数据被叫做line,它是内存中的一段连续的字节。上图所示的cache使用的是64字节为一个line的。这些line存储在被称作cache banks或者ways的字段中,并且每个way都有一个明确的directory来存储该way所属的字段信息。把每个way和它的directory看成是电子表格中的列,而cache中的sets就对应着行。在每个way的列中都包含一个cache line,它被每个单元中的directory所标识。在上图中,有64个set,每个set包含8个way,因此总共有512个cache lines,所有这些加起来总共是32KB.
In this cache’s view of the world, physical memory is divided into 4KB physical pages. Each page has4KB / 64 bytes == 64 cache lines in it. When you look at a 4KB page, bytes 0 through 63 within that page are in the first cache line, bytes 64-127 in the second cache line, and so on. The pattern repeats for each page, so the 3rd line in page 0 is different than the 3rd line in page 1.
对于这个cache来说,它所能认识到的物理内存都是以4KB为单位的物理页。每个页包含4KB/64bytes=64条cache line。一个4KB的页中,页中的0-63bytes在cache line 1中,64-127 bytes在line 2中,以此类推。
In a fully associative cache any line in memory can be stored in any of the cache cells. This makes storage flexible, but it becomes expensive to search for cells when accessing them. Since the L1 and L2 caches operate under tight constraints of power consumption, physical space, and speed, a fully associative cache is not a good trade off in most scenarios.
在一个fully associative cache的cache中,内存中的任意一line都可以被储存在cache任意单元中。这使得存储起来更灵活,但是它会导致增加搜索指定的单元的成本。因为L1和L2 cache之间的操作严格受限于电量,物理空间和两者的速度,所以fully associative cache在通常的场合下不是很适用。
Instead, this cache is set associative, which means that a given line in memory can only be stored in one specific set (or row) shown above. So the first line of any physical page (bytes 0-63 within a page)must be stored in row 0, the second line in row 1, etc. Each row has 8 cells available to store the cache lines it is associated with, making this an 8-way associative set. When looking at a memory address, bits 11-6 determine the line number within the 4KB page and therefore the set to be used. For example, physical address 0x800010a0 has 000010 in those bits so it must be stored in set 2.
相反,set associative的cache更符合通常的使用场景。它意味着内存中指定的一个line如上图所示,只能被存储在一个特别的set(或行)中。任何一个物理页的0-63字节必须被存储在0行,而第二条line必须存储在1行,以此类推。每行有8个单元可供存储与它相关的8个cache line。当查询一个物理地址时,6-11 bits被用来指定一个4KB页中的行号,它就是该cache中哪一个set是被使用来存储该地址。例如,物理地址0x800010a0的6-11bits是000010,它丢应的就是set 2。
But we still have the problem of finding which cell in the row holds the data, if any. That’s where the directory comes in. Each cached line is tagged by its corresponding directory cell; the tag is simply the number for the page where the line came from. The processor can address 64GB of physical RAM, so there are64GB / 4KB == 224 of these pages and thus we need 24 bits for our tag. Our example physical address 0x800010a0 corresponds to page number524,289. Here’s the second half of the story:
但是,我们找到了该地址属于set 2之后,还是不知道具体哪一个way中包含该地址。这时,directory的作用就体现出来了。每个cache line都被它所对应的directory单元中的值所标识;这个标识是一个简单数字,它表示这个line所在的页。Core 2处理器可以寻址64GB的物理内存,所以总共有64GB/4KB==224个页,因此我们需要24位来存储我们的标识。我们的例子中,0x800010a0所对应的页号是524,289。以下是cache结构的下半部分说明:
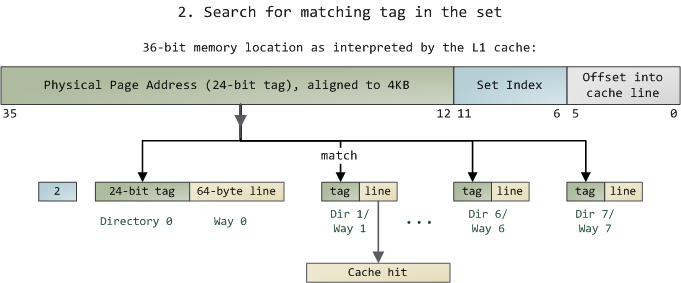
Since we only need to look in one set of 8 ways, the tag matching is very fast; in fact, electrically all tags are compared simultaneously, which I tried to show with the arrows. If there’s a valid cache line with a matching tag, we have a cache hit. Otherwise, the request is forwarded to the L2 cache, and failing that to main system memory. Intel builds large L2 caches by playing with the size and quantity of the ways, but the design is the same. For example, you could turn this into a 64KB cache by adding 8 more ways. Then increase the number of sets to 4096 and each way can store 256KB. These two modifications would deliver a 4MB L2 cache. In this scenario, you’d need 18 bits for the tags and 12 for the set index; the physical page size used by the cache is equal to its way size.
因为我们只需要查找一个set的8个way,所以对于这8个way的tag的匹配查找操作是非常快的;事实上,所有tags的匹配查找是被实现为同时进行。如果发现一个合法的cache line包含对应的tag,那么就称为cache hit。 否则,就会到L2 cache去查找,如果L2 cache还没找到,就会去到主存查找(此时的查找效率会变得很低)。Intel提供了比较大的L2 cache。例如,你可以通过增加额外的8 ways从而使得cache大小变为64KB.这就使得sets可以达到4096并且每个way可以存储256KB。这两项改变使得L2 cache为4MB。此时,你需要18bits作为tags并且12bits作为set的索引;而被这个cache使用的物理页的大小也就会是4MB。
If a set fills up, then a cache line must be evicted before another one can be stored. To avoid this, performance-sensitive programs try to organize their data so that memory accesses are evenly spread among cache lines. For example, suppose a program has an array of 512-byte objects such that some objects are 4KB apart in memory. Fields in these objects fall into the same lines and compete for the same cache set. If the program frequently accesses a given field (e.g., the vtable by calling a virtual method), the set will likely fill up and the cache will start trashing as lines are repeatedly evicted and later reloaded. Our example L1 cache can only hold the vtables for 8 of these objects due to set size. This is the cost of the set associativity trade-off: we can get cache misses due to set conflicts even when overall cache usage is not heavy. However, due to the relative speeds in a computer, most apps don’t need to worry about this anyway.
如果所有的set都填满,则如果需要存储一个新的line则必须选择换出一个已存在的line。为了避免这种换出,对于效率要求比较搞的程序会尝试把它们的数据组织为是占满一个cache line的。例如,一个程序有一个包含512字节元素的数组,其中有一些元素在内存中存储在不同的4KB的区域。那些在同一个4KB区域的元素会坐落在同一个line的同一个set中。如果程序频繁的访问给定的这种元素,该set就会不断被填充然后又由于需要再次访问又被换出,换入多次。比如,我们的例子中L1 cache由于set大小的限制只能最多包含8个这样的元素。 这就是set associativity的开销的权衡:我们会由于set的冲突而导致cache miss即使当所有的cache使用率不是很高的情况下。然后,由于电脑中不同模块见的相对速度,大多数的程序不需要关心这种问题。
A memory access usually starts with a linear (virtual) address, so the L1 cache relies on the paging unit to obtain the physical page address used for the cache tags. By contrast, the set index comes from the least significant bits of the linear address and is used without translation (bits 11-6 in our example). Hence the L1 cache is physically tagged butvirtually indexed, helping the CPU to parallelize lookup operations. Because the L1 way is never bigger than an MMU page, a given physical memory location is guaranteed to be associated with the same set even with virtual indexing. L2 caches, on the other hand, must be physically tagged and physically indexed because their way size can be bigger than MMU pages. But then again, by the time a request gets to the L2 cache the physical address was already resolved by the L1 cache, so it works out nicely.
一个内存的访问通常开始于一个linear(虚拟)地址, 所以L1 cache依赖于分页单元去获得被cache tags所使用的物理页地址。相反,set的索引确实来自于虚拟地址的least significant bits并且是不许要被翻译的(例如上面说到的6-11bits)。因此,L1 cache是使用物理地址作为tag而使用虚拟地址来索引(set number)的,从而帮助CPU进行并行的查找操作。L2 cahce,却是使用物理地址作为tag并且使用物理地址来索引,因为它们的大小可以大于MMU的页大小。但是,请注意,因为当需要从L2 cache查找的时候,由于已经经过了L1 cache的查找,所以查找的地址已经由虚拟地址翻译为了物理地址,所以,一切都工作正常。
Finally, a directory cell also stores the state of its corresponding cached line. A line in the L1 code cache is either Invalid or Shared (which means valid, really). In the L1 data cache and the L2 cache, a line can be in any of the 4 MESI states: Modified, Exclusive, Shared, or Invalid. Intel caches are inclusive: the contents of the L1 cache are duplicated in the L2 cache. These states will play a part in later posts about threading, locking, and that kind of stuff. Next time we’ll look at the front side bus and how memory access really works. This is going to be memory week.
最后, 每个line的directory单元也存储着它所对应的cache line的状态。一个L1 code cache line中的line可以是invalid或者shared(即valid)。在L1 data cache和L2 cache,1个line可以是MESI状态中的任意一个:Modified, Exclusive, Shared, 或者Invalid。 Intel的caches是Inclusive:L1 cache中的内容会copy到L2 cache。 这些状态会在之后的关于线程,锁和其它类似的一篇文章中起关键作用。 以后,我们会看到前端总线和内存访问是如何真正工作的。
Update: Dave brought up direct-mapped caches in a comment below. They’re basically a special case of set-associative caches that have only one way. In the trade-off spectrum, they’re the opposite of fully associative caches: blazing fast access, lots of conflict misses.
更新: Dave在这篇文章的评论中提到的direct-mapped caches。它们其实就是一个中基本的set-associative的特殊caches,它的每个line只有一个way。从它的权衡来看,它是fully associative caches的相反面:高速的访问,但是会有更多的cache冲突miss。
Me: 最后,我还是推荐大家有空去看看大牛Ulrich Drepper关于Memory的那篇paper啊!!!














 2646
2646











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









