




 本文深入探讨了Kafka的事务机制,介绍了KAFKA事务如何实现端到端的有且仅有一次语义,以及如何通过transactional producer和consumer配合工作。内容涵盖了KAFKA内部的Transaction Coordinator和Transaction Log组件,日志文件格式的扩展,事务的读写流程,以及事务状态的容错机制。此外,还讲解了如何在应用程序中配置和使用KAFKA事务。
本文深入探讨了Kafka的事务机制,介绍了KAFKA事务如何实现端到端的有且仅有一次语义,以及如何通过transactional producer和consumer配合工作。内容涵盖了KAFKA内部的Transaction Coordinator和Transaction Log组件,日志文件格式的扩展,事务的读写流程,以及事务状态的容错机制。此外,还讲解了如何在应用程序中配置和使用KAFKA事务。
1 前言
大家好,我是明哥!
KAFKA 作为开源分布式事件流平台,在大数据和微服务领域都有着广泛的应用场景,是实时流处理场景下消息队列事实上的标准。用一句话概括,KAFKA 是实时数仓的基石,是事件驱动架构的灵魂。
但是一些技术小伙伴,尤其是一些很早就开始使用 KAFKA 的技术小伙伴们,对 KAFKA 的发展趋势和一些新特性,并不太熟悉,在使用过程中也踩了不少坑。
有鉴于此,我们会通过一系列 KAFKA 相关博文,专门讲述 KAFKA 的这些新特性。
本文是该系列文章之一,讲述 KAFAK 的事务机制。
以下是正文。
2 技术大背景-大数据发展趋势
在前期的一篇博文中,我们讲述过大数据的发展趋势之一,就是大数据与数据库日益融合的趋势。
-
早期大数据粗放式发展时,为了快速推向市场,丢失了很多传统数据库领域里良好的一些特性,(如事务ACID,如记录级别的增删改,如秒级甚至毫秒级的延迟),由此欠下了很多技术债。
-
近些年随着技术的进一步成熟,大数据在不断朝着更精细化的方向发展,参考了很多传统数据库的理念和技术,补齐了很多早期的技术债,使得大数据组件越来越像存储与计算分离的数据库,也进而推出了数据据湖仓/湖仓一体的理念。
-
技术债之一,就是大数据参考数据库实现了对事务 acid 特性的支持。具体到框架层面,数据湖三剑客 DeltaLake/Hudi/Iceberg, 还有本文的 KAFKA 事务机制,都是这个范畴。
3 KAFKA 的事务是什么
- KAFKA 的事务机制,是 KAFKA 实现端到端有且仅有一次语义(end-to-end EOS)的基础;
- KAFKA 的事务机制,涉及到 transactional producer 和 transactional consumer, 两者配合使用,才能实现端到端有且仅有一次的语义(end-to-end EOS);
- 当然kakfa 的 producer 和 consumer 是解耦的,你也可以使用非 transactional 的 consumer 来消费 transactional producer 生产的消息,但此时就丢失了事务 ACID 的支持;
- 通过事务机制,KAFKA 可以实现对多个 topic 的多个 partition 的原子性的写入,即处于同一个事务内的所有消息,不管最终需要落地到哪个 topic 的哪个 partition, 最终结果都是要么全部写成功,要么全部写失败(Atomic multi-partition writes);
- KAFKA的事务机制,在底层依赖于幂等生产者,幂等生产者是 kafka 事务的必要不充分条件;
- 事实上,开启 kafka事务时,kafka 会自动开启幂等生产者。
4 KAFKA 内部是如何支持事务的
4.1 为支持事务机制,KAFKA 引入了两个新的组件:Transaction Coordinator 和 Transaction Log
为支持事务机制,KAFKA 引入了两个新的组件:Transaction Coordinator 和 Transaction Log,如下图所示:

- transaction coordinator 是运行在每个 kafka broker 上的一个模块,是 kafka broker 进程承载的新功能之一(不是一个独立的新的进程);
- transaction log 是 kafka 的一个内部 topic(类似大家熟悉的 __consumer_offsets ,是一个内部 topic);
- transaction log 有多个分区,每个分区都有一个 leader,该 leade对应哪个 kafka broker,哪个 broker 上的 transaction coordinator 就负责对这些分区的写操作;
- 由于 transaction coordinator 是 kafka broker 内部的一个模块,而 transaction log 是 kakfa 的一个内部 topic, 所以 KAFKA 可以通过内部的复制协议和选举机制(replication protocol and leader election processes),来确保 transaction coordinator 的可用性和 transaction state 的持久性;
- transaction log topic 内部存储的只是事务的最新状态和其相关元数据信息,kafka producer 生产的原始消息,仍然是只存储在kafka producer指定的 topic 中。事务的状态有:“Ongoing,” “Prepare commit,” 和 “Completed” 。
- 实际上,每个 transactional.id 通过 hash 都对应到 了 transaction log 的一个分区,所以每个 transactional.id 都有且仅有一个 transaction coordinator 负责。

4.2 为支持事务机制,KAFKA 将日志文件格式进行了扩展,添加了控制消息 control batch
为支持事务机制,KAFKA 将底层日志文件的格式进行了扩展:
- 日志中除了普通的消息,还有一种消息专门用来标志事务的状态,它就是控制消息 control batch;
- 控制消息跟其他正常的消息一样,都被存储在日志中,但控制消息不会被返回给 consumer 客户端;
- 控制消息共有两种类型:commit 和 abort,分别用来表征事务已经成功提交或已经被成功终止;
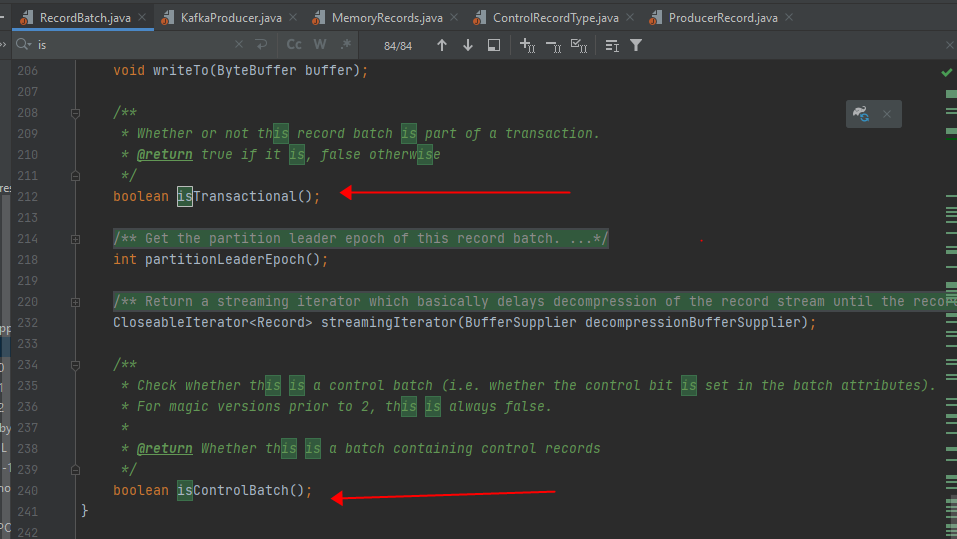
- RecordBatch 中 attributes 字段的第5位用来标志当前消息是否处于事务中,1代表消息处于事务中,0则反之;(A record batch is a container for records. )
- RecordBatch 中 attributes 字段的第6位用来标识当前消息是否是控制消息,1代表是控制消息,0则反之;
- 由于控制消息总是处于事务中,所以控制消息对应的RecordBatch 的 attributes 字段的第5位和第6位都被置为1;
参见源码:
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











