









网络动力学模型之信息级联
背景:“随大流”现象
当人们之间形成一个关系网络后,他们在行为和决策方面的相互影响就成为可能,如他人的意见、他人购买的产品、他人的行为立场、他人参与的活动、他人使用的技术等。在很多情况下,认母实际上是很理性地放弃自己的选择,而去跟随别人的选择。
这种情况下,学术上称之为**群集(herding)或信息级联(information cascading)**效应。
有趣的是,在级联效应中,个体模仿他人的行为并不是盲目的,相反,它是根据有限的信息合理推论的结果。当然,模仿也有可能是出于社会压力导致的顺从,与所谓的信息没有什么关系,有时不容易分辨这两种现象。
信息效应和直接受益效应
模仿别人有两种本质上不同的合理性理由:
- 信息效应:单纯是因为“从众”,即基于对别人行为的推断而做出决定;
- 直接受益:因为选择了和别人同样的行为会使自己产生一定的收益,其他人的行为会直接影响到你的回报,而不是间接地改变你的信息。
一个简单的群集实验
想象这个实验在一个教室里进行,由一群学生参加。实验者在教室前面放置一个装有3个小球的小罐;然后向大家宣布罐中有2个红色球和1个蓝色球的可能性是50%(多数红色,majority-red),有2个蓝色球和1个红色球的可能性也是50%(多数蓝色,majority-blue)。
现在,每个学生依次排成队来到讲台上,背着大家拿出一个球察看颜色,再放回去。然后让这个同学猜测罐中是“多数红色”还是“多数蓝色”,并向剩余同学公布他的猜测(为了保证其猜测是经过合理分析的,假设猜中的同学可以获得奖金奖励)。公开宣布是这个实验设置的关键,还没轮到自己去抓球的人看不到前面学生抓到的球的颜色,但是可以听到那些学生宣布的猜测结果。
这个过程将在所有的学生中进行,如果前面两个猜测都是“蓝色”,那么后面每个人都会同样猜测“蓝色”(“红色”同理)。
一个信息级联持有的特征是——人们都没有幻觉每个人都拿到一个蓝色的球,但是一旦前两个猜测都是“蓝色”的话,后面所有人宣布的猜测也就没有什么参考价值了。
因此,每个人的最佳策略是依靠那些少量的有参考价值的信息来做决定的。
以上设置尽管非常简略,但仍然能够体现出一些关于“信息级联”的一般原则:
- 它表明这种级联非常容易发生(在我们的生活中),只需要满足适当的结构条件;
- 它还展示了决策行为的怪异模式,一个群体中每个学生都会做出完全一致的推测,而且是发生再所有的人都是在很理性地做决定。
- 它表明信息级联可能会导致非优化的结果:例如,假设罐中是多数红色,就有1/3的概率第一个学生抓到蓝色球,1/3的概率第2个学生抓到蓝色球;前两次都抓到蓝色球的概率是1/9。这个1/9的出错概率不会因更多的人参加而得到修正,因为在理性决策引导下,如果前面2个人猜蓝色,后面每个人都会跟着猜蓝色,无论这个群体有多大。
- 尽管级联可能形成最终的一致,但从根本上它也是很脆弱的。比如,假设进行到50号和51号学生都拿到了红色球,他们向全班展示手中的小球来“迷惑”大家,这种情况下,级联就会被打破,因为52号学生抉择时,就拥有四种真实的信息可以参考:1、2号公布的颜色,以及50、51号公布的颜色。
贝叶斯规则:非确定性决策模型
条件概率和贝氏规则
作用:计算各种事件的概率,并利用这些概率对决策行为进行推论。
假设:一个很大的样本空间,其中每一个点都代表一种特定的随机结果。
1、贝叶斯规则(Bayese’s Rule)
P
(
A
∣
B
)
=
P
(
A
)
∗
P
(
B
∣
A
)
P
(
B
)
P(A|B)=\frac{P(A)*P(B|A)}{P(B)}
P(A∣B)=P(B)P(A)∗P(B∣A)
- 条件概率
(又称后验概率)就是事件A在另外一个事件B已经发生条件下的发生概率。条件概率表示为P(A|B),读作“在B条件下A的概率”,
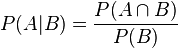
- 联合概率:
表示两个事件共同发生的概率。A与B的联合概率表示为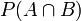 或者
P
(
A
,
B
)
P(A,B)
P(A,B)
或者
P
(
A
,
B
)
P(A,B)
P(A,B) - 边缘概率
(又称先验概率):是某个事件发生的概率。边缘概率是这样得到的:在联合概率中,把最终结果中那些不需要的事件通过合并成它们的全概率,而消去它们(对离散随机变量用求和得全概率,对连续随机变量用积分得全概率),这称为边缘化(marginalization),比如A的边缘概率表示为P(A),B的边缘概率表示为P(B)。
2、贝氏规则的应用:垃圾邮件过滤
贝氏规则是第一代垃圾邮件过滤器的重要组成部分,当前仍然是许多垃圾邮件过滤器的基础组成部分之一。
假设你收到一封邮件,主题行包含“check this out”,这通常是垃圾邮件包含的短语。单凭这一信息,而没有检查发件人或邮件内容,这封邮件是垃圾邮件的概率有多大?
Solution:
这是一个条件概率的问题,是在寻求以下表达式的值:
P [ 是 一 个 垃 圾 邮 件 ∣ 主 题 行 包 含 “ c h e c k t h i s o u t ” ] P[是一个垃圾邮件|主题行包含“check \ this\ out”] P[是一个垃圾邮件∣主题行包含“check this out”]
为方便起见,用“spam”表示”是一个垃圾邮件“,用”check this out“表示”主题行包含‘check this out’”。因此,我们希望得到以下表达式的值:
P[spam | "check this out"]
此外,假设收到的所有邮件中40%是垃圾邮件,其余60%是你想要接收的邮件。此外,假设1%的垃圾邮件在主题行中包含短语“check this out",有0.4%的非垃圾邮件也在主题行中包含这个短语。因此,可以得到以下概率值:
P
[
s
p
a
m
]
=
0.4
P[spam] = 0.4
P[spam]=0.4
P
[
"
c
h
e
c
k
t
h
i
s
o
u
t
"
∣
s
p
a
m
]
=
0.01
P["check\ this \ out" | spam]=0.01
P["check this out"∣spam]=0.01
P
[
"
c
h
e
c
k
t
h
i
s
o
u
t
"
∣
n
o
t
s
p
a
m
]
=
0.004
P["check\ this \ out" | not\ spam]=0.004
P["check this out"∣not spam]=0.004
运用贝叶斯规则,可得:
P
[
s
p
a
m
∣
"
c
h
e
c
k
t
h
i
s
o
u
t
"
]
=
P
[
"
c
h
e
c
k
t
h
i
s
o
u
t
"
∣
s
p
a
m
]
∗
P
[
s
p
a
m
]
P
[
"
c
h
e
c
k
t
h
i
s
o
u
t
"
]
P[spam | "check\ this\ out"]=\frac{P["check\ this\ out"|spam]*P[spam]}{P["check\ this\ out"]}
P[spam∣"check this out"]=P["check this out"]P["check this out"∣spam]∗P[spam]
因此,只需要计算
P
[
"
c
h
e
c
k
t
h
i
s
o
u
t
"
]
P["check\ this\ out"]
P["check this out"]的概率值即可得所求;即需要计算短语"check this out在所有邮件中的发生概率,有:
P
[
"
c
h
e
c
k
t
h
i
s
o
u
t
"
]
=
P
[
s
p
a
m
]
∗
P
[
"
c
h
e
c
k
t
h
i
s
o
u
t
"
∣
s
p
a
m
]
+
P
[
n
o
t
s
p
a
m
]
∗
P
[
"
c
h
e
c
k
t
h
i
s
o
u
t
"
∣
n
o
t
s
p
a
m
]
=
0.4
×
0.01
+
0.6
×
0.004
=
0.064
P["check\ this\ out"] = P[spam]*P["check\ this \ out" | spam]+P[not spam]*P["check\ this \ out" | not\ spam]=0.4\times 0.01+0.6\times 0.004=0.064
P["check this out"]=P[spam]∗P["check this out"∣spam]+P[notspam]∗P["check this out"∣not spam]=0.4×0.01+0.6×0.004=0.064
带入以上数值,得到:
P
[
s
p
a
m
∣
"
c
h
e
c
k
t
h
i
s
o
u
t
"
]
=
0.004
0.0064
=
0.625
P[spam|"check\ this\ out"]=\frac{0.004}{0.0064}=0.625
P[spam∣"check this out"]=0.00640.004=0.625
上述分析和计算结果说明,当采用了短语
"check this out"作为鉴别信息时,识别这封邮件为垃圾邮件的概率将高于原始概率统计0.4.
因此,我们可以将主题行中出现这个短语看成是一个弱信号,为我们提供该邮件是否为垃圾邮件的证据。
在实践中,检测每一封邮件多种不同的信号,包括邮件的正文、邮件的主题、发送者的属性(你是否认识他们?他们的邮件地址有什么特点?)、邮件服务的属性,以及一些其他的特征。
在群集实验中运用贝氏规则
首先注意到每个学生的抉择本质上是取决于一个条件概率:当听到别人的猜测后,每个学生都试图估算出小罐是“多数蓝色“还是”多数红色“的条件概率 。
为了最大限度赢得猜中的机会(即假设每一个试验者都是绝对理性的),如果以下表达式成立,就应该猜多数蓝色:
P
r
[
m
a
j
o
r
i
t
y
−
b
l
u
e
∣
看
到
或
听
到
的
颜
色
]
>
1
/
2
Pr[majority-blue | 看到或听到的颜色]>1/2
Pr[majority−blue∣看到或听到的颜色]>1/2
即,猜测的结果(多数蓝色)发生的可能性是基于已有的信息(看到或听到的颜色)来得到的;否则,猜多数红色。如果两个条件概率都恰好是0.5,那么猜什么都无所谓了。
下面给出在实验开始之前已经存在的设置情况。
(1)首先,小罐是多数蓝色还是多数红色的先验概率都是1/2:
P
r
[
m
a
j
o
r
i
t
y
−
b
l
u
e
]
=
P
r
[
m
a
j
o
r
i
t
y
−
r
e
d
]
=
1
2
Pr[majority-blue] = Pr[majority-red] = \frac{1}{2}
Pr[majority−blue]=Pr[majority−red]=21
(2)而且,基于两种小罐小球的组成情况:
P
r
[
b
l
u
e
∣
m
a
j
o
r
i
t
y
−
b
l
u
e
]
=
P
r
[
r
e
d
∣
m
a
j
o
r
i
t
y
−
r
e
d
]
=
1
2
Pr[blue | majority-blue] = Pr[red | majority-red] = \frac{1}{2}
Pr[blue∣majority−blue]=Pr[red∣majority−red]=21
第1个学生拿到1个篮球
他需要确定
P
r
[
m
a
j
o
r
i
t
y
−
b
l
u
e
∣
b
l
u
e
]
Pr[majority-blue | blue]
Pr[majority−blue∣blue]的发生概率,即需要根据其当前看到的颜色——blue,来判断小罐中是多数蓝色还是多数红色?
这里,我们使用“贝氏规则”来计算其发生概率,验证理性者做出选择的概率:
P
r
[
m
o
j
o
r
i
t
y
−
b
l
u
e
∣
b
l
u
e
]
=
P
r
[
m
a
j
o
r
i
t
y
−
b
l
u
e
]
∗
P
r
[
b
l
u
e
∣
m
a
j
o
r
i
t
y
−
b
l
u
e
]
P
r
[
b
l
u
e
]
Pr[mojority-blue|blue]=\frac{Pr[majority-blue]*Pr[blue|majority-blue]}{Pr[blue]}
Pr[mojority−blue∣blue]=Pr[blue]Pr[majority−blue]∗Pr[blue∣majority−blue]
其中,分子部分为
1
/
2
∗
2
/
3
=
1
/
3
1/2*2/3=1/3
1/2∗2/3=1/3,对于分母部分,分析拿到蓝球有2种情况:
(1)小罐是多数红色;(2)小罐是多数蓝色:
P
r
[
b
l
u
e
]
=
P
r
[
m
a
j
o
r
i
t
y
−
b
l
u
e
]
∗
P
r
[
b
l
u
e
∣
m
a
j
o
r
i
t
y
−
b
l
u
e
]
+
P
r
[
m
a
j
o
r
i
t
y
−
r
e
d
]
P
r
[
b
l
u
e
∣
m
a
j
o
r
i
t
y
−
r
e
d
]
=
1
/
2
∗
2
/
3
+
1
/
2
∗
1
/
3
=
1
2
Pr[blue]=Pr[majority-blue]*Pr[blue|majority-blue]+Pr[majority-red]Pr[blue|majority-red]=1/2*2/3+1/2*1/3=\frac{1}{2}
Pr[blue]=Pr[majority−blue]∗Pr[blue∣majority−blue]+Pr[majority−red]Pr[blue∣majority−red]=1/2∗2/3+1/2∗1/3=21
即,可以看作从6个球中(3个红色,3个蓝色)任意取1个球取出来是蓝色或者是红色的概率都是相等的。
因此,就可以得到:
P
r
[
m
a
j
o
r
i
t
y
−
b
l
u
e
∣
b
l
u
e
]
=
1
/
3
1
/
2
=
2
3
Pr[majority-blue|blue]=\frac{1/3}{1/2}=\frac{2}{3}
Pr[majority−blue∣blue]=1/21/3=32
因为这个条件概率大于1/2,因此,当第1个同学拿到蓝球时,他应该猜测是多数蓝色。
注意:除了能够提供猜测的最终抉择之外,贝氏规则还可以提供这个猜测准确的概率为2/3.
假设前面2个同学都猜测蓝色,而第3个同学拿到了一个红色球
前面2个同学都传递了真实的信息(即拿到什么颜色的球,就猜测为多数什么颜色),因此第3个同学实际上掌握了三次抓球的结果:蓝色、蓝色、红色。他希望根据以下表达式的值:
P
r
[
m
a
j
o
r
i
t
y
−
b
l
u
e
∣
b
l
u
e
,
b
l
u
e
,
r
e
d
]
Pr[majority-blue|blue, blue, red]
Pr[majority−blue∣blue,blue,red]
来进行猜测,利用贝氏规则,有:
P
r
[
m
a
j
o
r
i
t
y
−
b
l
u
e
∣
b
l
u
e
,
b
l
u
e
,
r
e
d
]
=
P
r
[
m
a
j
o
r
i
t
y
−
b
l
u
e
]
∗
P
r
[
b
l
u
e
,
b
l
u
e
,
r
e
d
∣
m
a
j
o
r
i
t
y
−
b
l
u
e
]
P
r
[
b
l
u
e
,
b
l
u
e
,
r
e
d
]
Pr[majority-blue|blue, blue, red]=\frac{Pr[majority-blue]*Pr[blue,blue,red|majority-blue]}{Pr[blue,blue,red]}
Pr[majority−blue∣blue,blue,red]=Pr[blue,blue,red]Pr[majority−blue]∗Pr[blue,blue,red∣majority−blue]
分子很容易得到,是
1
/
2
∗
(
2
/
3
∗
2
/
3
∗
1
/
3
)
=
2
27
1/2*(2/3*2/3*1/3)=\frac{2}{27}
1/2∗(2/3∗2/3∗1/3)=272
对于分母
P
r
[
b
l
u
e
,
b
l
u
e
,
r
e
d
]
Pr[blue,blue,red]
Pr[blue,blue,red],我们同样考虑在2种小罐(多数蓝色和多数红色)种的发生概率:
P
r
[
b
l
u
e
,
b
l
u
e
,
r
e
d
]
=
P
r
[
m
a
j
o
r
i
t
y
−
b
l
u
e
]
×
P
r
[
b
l
u
e
,
b
l
u
e
,
r
e
d
∣
m
a
j
o
r
i
t
y
−
b
l
u
e
]
+
P
r
[
m
a
j
o
r
i
t
y
−
r
e
d
]
×
P
r
[
b
l
u
e
,
b
l
u
e
,
r
e
d
∣
m
a
j
o
r
i
t
y
−
r
e
d
]
=
1
/
2
∗
2
/
3
∗
2
/
3
∗
1
/
3
+
1
/
2
∗
1
/
3
∗
1
/
3
∗
2
/
3
=
6
54
=
1
9
Pr[blue,blue,red]=Pr[majority-blue]\times Pr[blue, blue, red|majority-blue]+Pr[majority-red]\times Pr[blue,blue,red|majority-red]=1/2*2/3*2/3*1/3 + 1/2*1/3*1/3*2/3 = \frac{6}{54}=\frac{1}{9}
Pr[blue,blue,red]=Pr[majority−blue]×Pr[blue,blue,red∣majority−blue]+Pr[majority−red]×Pr[blue,blue,red∣majority−red]=1/2∗2/3∗2/3∗1/3+1/2∗1/3∗1/3∗2/3=546=91
因此,可以得到结果为:
P
r
[
m
a
j
o
r
i
t
y
−
b
l
u
e
∣
b
l
u
e
,
b
l
u
e
,
r
e
d
]
=
2
/
27
1
/
9
=
2
3
Pr[majority-blue|blue, blue, red]=\frac {2/27}{1/9}=\frac {2}{3}
Pr[majority−blue∣blue,blue,red]=1/92/27=32
因此,第3个同学的猜测结果为:多数蓝色。
这就证实了第1节中的推断,如果前面连续2个同学都猜测同样的结果,则第3个同学应该忽略掉他自己看到的结果(抓到的红色球),赞同他已经听到的前面2个猜测(蓝色)。
最后,一旦这3次抓球活动已经发生,所有接下来的学生将拥有和第三个同学同样的信息,因此运行相同的计算过程,结果将形成一个后续全部选择**蓝色** 的信息级联。














 1581
1581











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









