







做推荐系统有很多的方法,比如说
1. 我们就找到网上歌曲分类好的排名按从高到底的方法推荐给他就可以了!但是这样不具有个性化。
方法2
用分类模型, 我们用每个人的信息(年龄,性别,产品信息。。。)作为特征,结果为是否会购买这个商品,是二分类问题
优点:缺点:


所以:我们最终认为 协同过滤 是最好的!!
方法3 :协同过滤
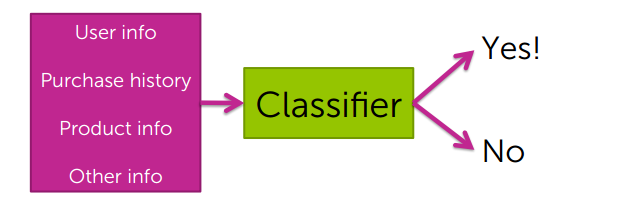
我们根据别人(与自己最类似的人)的购买情况,来给自己推荐做合适的商品。所以就要建一个同性矩阵(Co-occurrence matrix)
同性矩阵(Co-occurrence matrix)
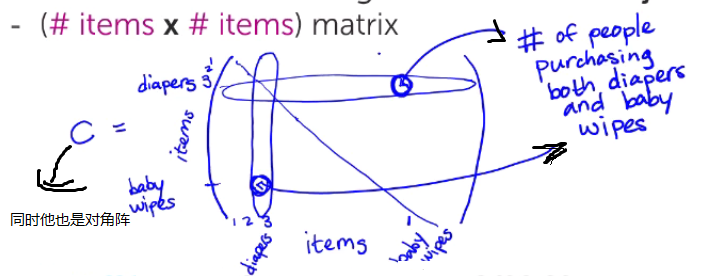
假设我们要给人A推荐商品,那我们就根据数据建立Co-occurrence matrix,Co-occurrence matrix 是一个n*n的矩阵,n表示商品总共的个数,Co-occurrence matrix的每一个空的值(i,j)表示既买了商品i,又买了商品j的人数。且是一个对角阵。
那我们怎么推荐呢??
很简单,假设商家发现人A买了一袋奶粉,那么就把Co-occurrence matrix奶粉的那一行取出来,得到一个向量,向量每一个值是购买奶粉的情况下,购买了其他产品的人数。我们只需把向量的值从大到小排列起来,取最大的值推荐给人A就可以了!!!
但是这也有缺陷,看下面,我们要对其归一化!!!
对数据进行归一化(正则化)
因为婴儿每小便一次就要换一次尿布,所以尿布的需求量就会很大,也就是说,不管是矩阵的哪一行的向量,其对应尿布的那个空值永远都比其他的大很多,那难道人A每买一次东西,就给他推荐尿布吗??这样就不个性化了,难道买个牙刷也推荐个尿布吗??为了防止这种问题的发生,我们就要对数据进行归一化处理!!!
归一化的方法有很多,现在用的是jaccard相似度

i j 表示商品i,和商品j 。
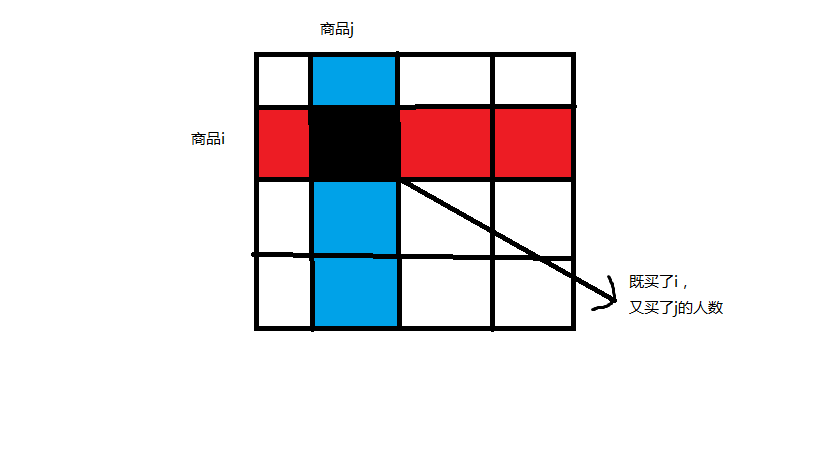
正则化后,值就变为 黑色的值 除以(红色+蓝色 - 黑色)
以上方法仍然有很大的缺陷
(你的系统没有考虑当个买家的个人信息,和他以前的购买历史!!!)
假设同性矩阵(Co-occurrence matrix)用Q表示。那么Q(i,j)是通过计算整个商场既购买商品i,又购买商品j得到的总人数。假设人A要买商品i,那么取出矩阵Q的第i行向量,比较第i行的每一个值,找出最大值对应的商品就是要推荐的商品。可以发现,这个系统对人A的了解,恐怕就只有他买了商品i,罢了。其他的都是通过整个商场的数据得到的,所以不管是哪一个人,只要是买了商品i,得到被推荐的商品与人A就是一模一样的。
那这就不好了,人A买了i,你推荐商品k,其他人买了i,你也推荐k。
这说明你的系统没有考虑当个买家的个人信息,和他以前的购买历史!!!
现在就考虑人A的以前的购买历史
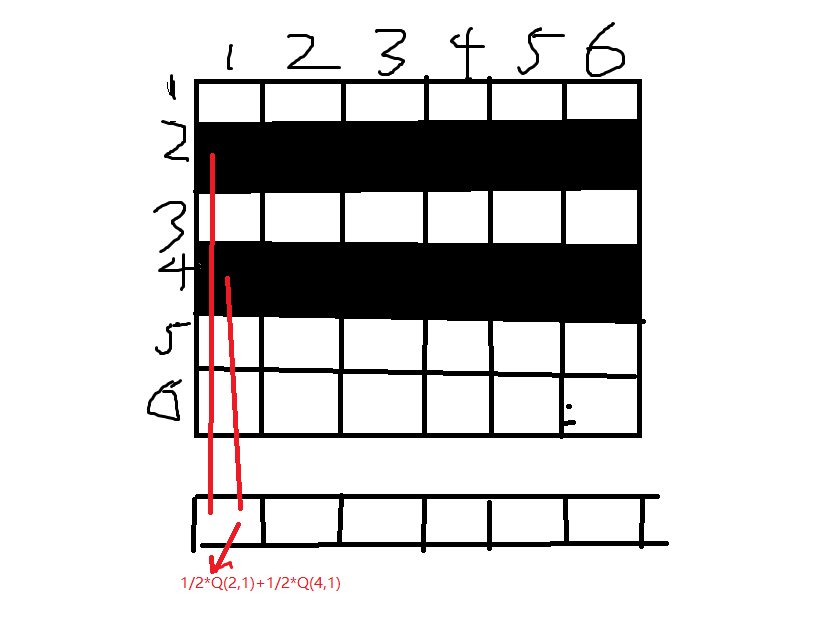
如上图所示,假设人A以前购买过物品2和物品4,那么6个商品我们最终要把那个推荐给A呢??那么就给视频加权重。这里我们认为A购买过的商品2和4一样重要,所以加的权重都是1/2,当然,我们也可以通过某些因素改变权重。比如根据商品2和商品4购买时间的不同赋予不同的权重。
当然,以上还有缺陷
比如:
1. 我们只是加入了A的历史购买记录,没有考虑个人的特征(性格,年龄,性别… …)
2. 没有考虑任何物品的特征(存储时间,作用。。。 。。。)
3. 当有新用户,或者新产品时,我们就没有他的任何数据(不知道他买过什么… …)
矩阵因子分析模型
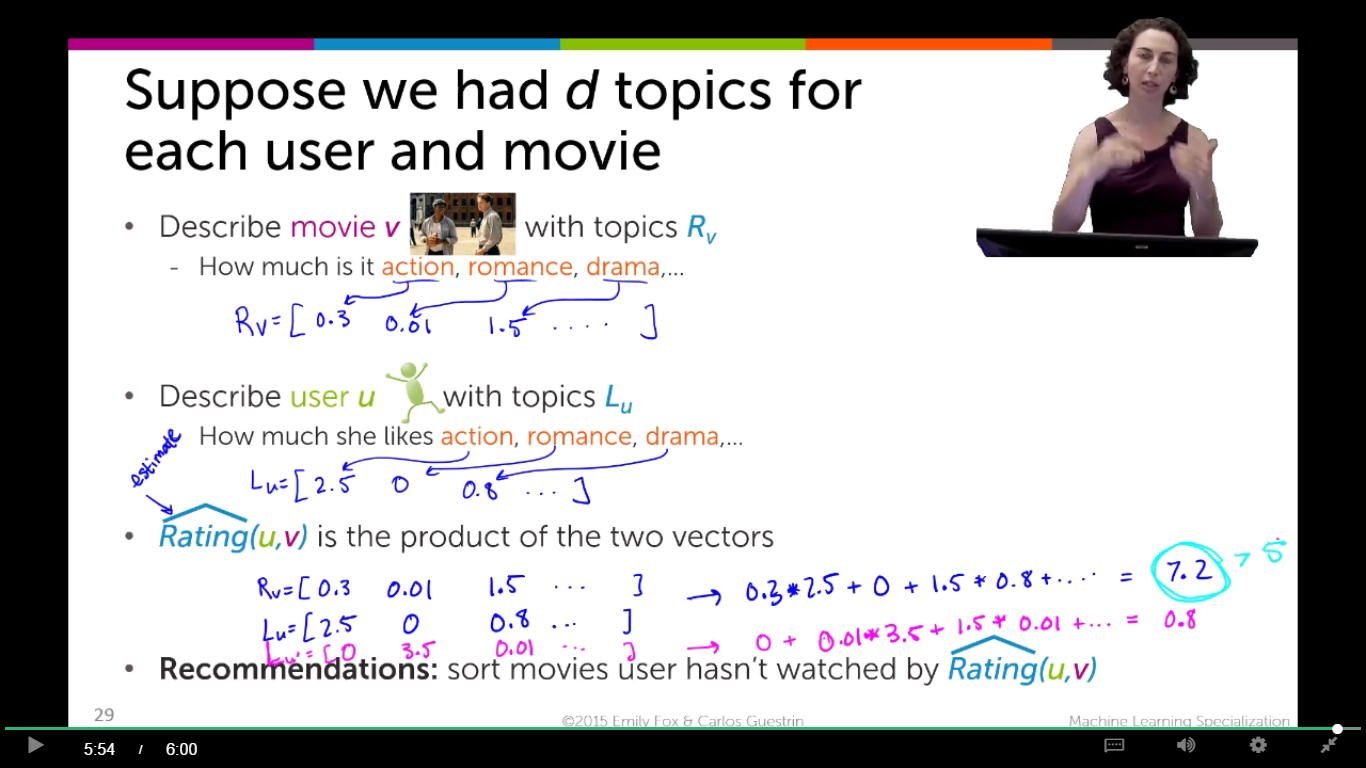
如果我们知道电影v 的特征 {动作片,感情片,悬疑片 … …}的打分
Rv=[0.3, 0.01 , 1.5 , … …]
某一个人的特征{动作片,感情片,悬疑片 … …}
Lv=[2.5 , 0 , 0.8 , … …]
那么我们就可以预测出该人在看完电影v后,对该电影的打分:(就是二者的电积)
Rating(u,v)=Rv * Lv
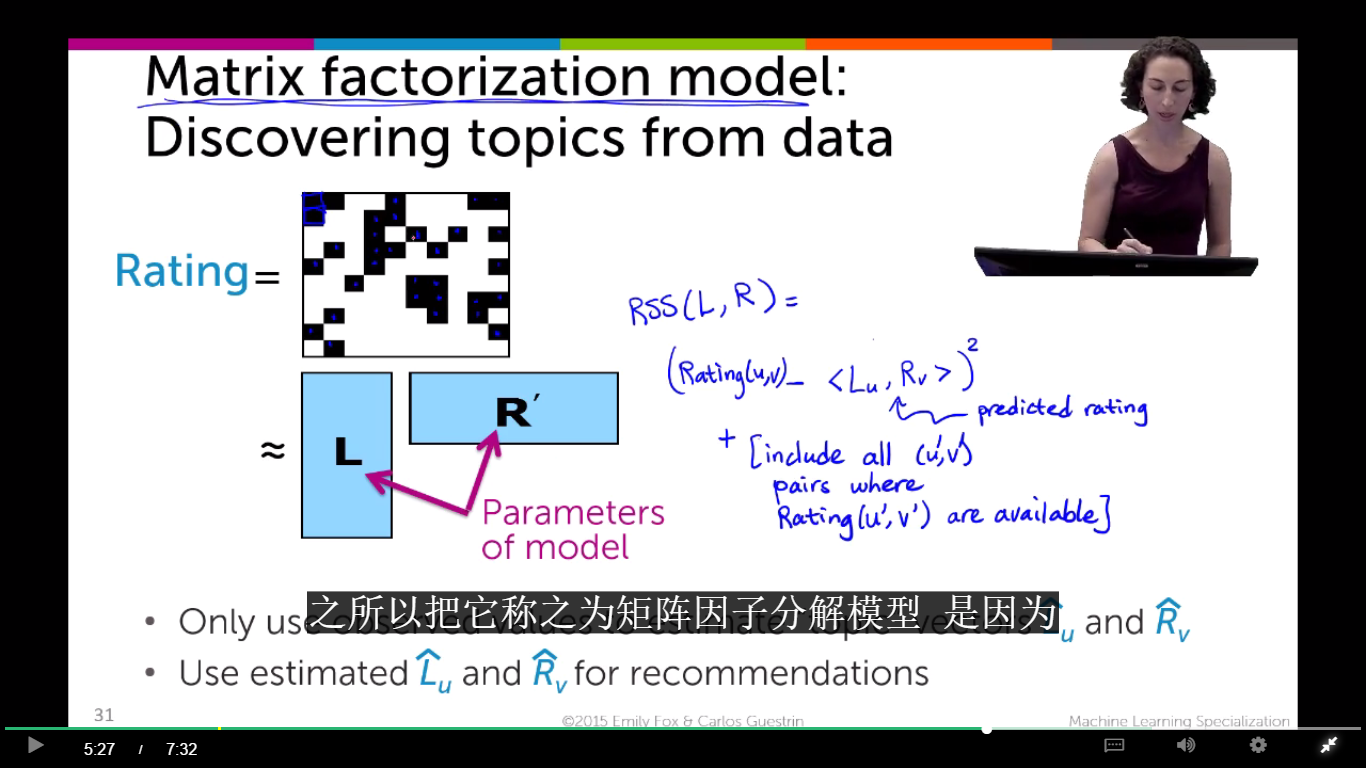
上面的矩阵中,横坐标表示一个人,纵坐标表示每一个电影。黑格子表示人对电影的打分,白格子表示该人为看过这个电影。由于每个人看的电影一定不多,所以以上的矩阵是稀疏矩阵。。。
我们想对一个人推荐电影,用上面推荐奶粉的方法,就要把什么的白格子的预测出来。所以现在的目的是要把上面白的填满!!!
用什么方法呢??? ——————就是 矩阵因子分析模型
从上图可以看出,想求Rating 的话,我们把它分解为L(人的特征值[0.3, 0.01 , 1.5 , … …]),和R (电影的特征值[0.3, 0.01 , 1.5 , … …])。求出了 L , R 就可以求出 Rating。然而我们该怎样求出 L, 和R呢??
我们把L ,R 的值看成是模型的参数,可以借鉴求回归的方法来做!!
求回归的参数时,我们是要求参数对应的预测值 的误差平方的和最小
因此,在求L,R的参数时,也是这样。可以看上图右边的蓝字。就是
min [sum(每一个黑格子的真实值 - 每一个黑格子的预测值)^2 ]
得到的参数就是 L ,R 的估计值。
度量
精确率
召回率
精度率和召回率都大是最好的。。。二者都为1 时,结果是最好的,但是这不可能。
如果 我们把所有的商品都推荐给他,那么召回率就是1,但是精确率就特别小了!!
如果我们尽可能的少推荐,他的精确率就比 推荐商品数目多要高!!精度-召回率曲线
他们是随着推荐的商品数量改变的
以上图为例!!!
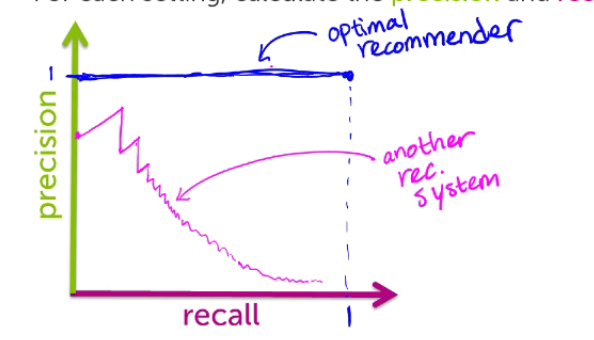
最理想的情况: 假设我们仅仅推荐一件商品,而且这个商品那个人感兴趣。那么精确率就会为1=1/1,而召回率就会很低,很低。随着推荐的商品数增加,最理想的情况是,即使这样我们推荐的商品仍是顾客最想要的。那么精确率依然为1, 召回率会逐渐增加到1. (就像上图中蓝线一样)
一般情况: 以上是最理想情况。一般情况是,随着推荐的是商品数逐渐增加,那么我所看到的“世界”就会越大。由于总的“like” 不会改变,但是“like & shown”就只会增加,不会减少,所以召回率
但是 “like & shown”一定增加的没有 “shown”快,所以精确率
就像上面粉色的线一样。。。
如何用精确-召回率 曲线 判断那个模型好呢??
1. 如果不知道 自己要推荐商品的数目(也就是不知道自己的 召回率)!
那么可以计算每个模型的曲线与横坐标维成的面积,哪个大,那个就好
2. 方法2 :如果你知道你要推荐商品的数目,那么精确率越大越好(不用管召回率)!!!















 1775
1775

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









