






转移学习推断跨异构网络的社会联系
人际关系负责社会网络的结构和通过这些网络传递信息。不同类型的社会关系对人的影响本质上是不同的。对社会关系类型的了解有助于许多应用,例如推荐和社区检测。例如,我们的亲密朋友往往和我们在同一个圈子里活动,而我们的同学可能分布在不同的社区。虽然大量的研究集中在推断特定社会网络中特定类型的关系,但很少有文献系统地研究跨多个异质网络预测社会关系的问题。
在这项工作中,我们开发了一个称为TranFG的框架,用于通过跨异构网络的学习对社会关系类型进行分类。该框架将社会理论引入到因子图模型中,通过从不同来源网络中借用知识,有效地提高了预测目标网络中社会关系类型的准确性。我们还提出了一些主动学习策略,以进一步提高推理性能。为了扩展模型以处理真正的大型网络,我们为该模型设计了一种分布式学习算法。
我们在六种不同的网络上评估了所提出的框架(TranFG),并与现有的几种方法进行了比较。TranFG在多个度量上明显优于现有方法。例如,通过利用来自具有标记为advisor-adise关系的合著者网络的信息,TranFG能够获得90%的F1分数(比其他方法提高8%-28%),用于预测企业电子邮件网络中的经理下属关系。该模型是有效的。在包含数万个节点的大型网络上,只需几分钟就可以训练出所提出的传输模型。
CCS概念:以人为中心的计算→协作和社会计算;信息系统→信息系统应用;万维网;网络→网络类型
附加关键词和短语:社会关系,社会网络,预测模型,社会影响
1 导言
在社交网络中,人际关系通常分为三类:强、弱或不存在。有人认为,更多的新信息通过弱关系而不是强关系流向个人[Granovetter 1973],而强关系则将亲密的朋友聚集到同一社交圈[Krackhardt 1992]。邓巴的数字[Gladwell 2001]表明,能够维持稳定社会关系的人数在100到230人之间,通常被视为150人。但是关系的类型会有很大的不同。例如,在这150人中,你可能有5个亲密的朋友、15个家庭成员、35个同事(或同学)和其他熟人[Goncalves等人,2011年]。
最近,在线社交网络(如Facebook、Twitter、LinkedIn、YouTube和Slashdot)的迅速发展为研究社交关系的基本模式提供了机会。例如,Facebook宣布,2012年10月,它的活跃账户达到10亿个。腾讯是中国最大的社交网络服务之一,拥有近8亿用户。人们通过不同类型的社会关系联系在一起,人与人之间的影响因社会关系的类型而有很大差异。例如,在移动通信网络中,人际关系大致可以分为四种类型:家庭、同事、朋友和熟人。同事对一个人的工作有很大的影响,而朋友对一个人的日常生活有很大的影响。在企业电子邮件网络中,人们通过向他人发送/接收电子邮件来建立联系,人们之间的联系可以分为经理-下属、同事等。毫无疑问,电子邮件网络中的行为是由发送者和接收者之间不同类型的关系控制的。
了解这些不同类型的社会关系可以使许多应用程序受益。例如,如果我们可以从移动通信网络中提取用户之间的友谊,我们就可以利用这些友谊来进行新产品的“口碑”推广。然而,这种信息(关系类型)在在线网络中通常是不可用的。用户可以通过单击“好友请求”、“关注”或“同意”轻松地向其他人添加链接(关系),但通常不会花时间为每个关系创建标签。事实上,一项针对欧洲手机用户的调查显示,只有16%的用户在手机上建立了联系小组[Roth等人,2010年];我们对LinkedIn数据的初步统计也显示,超过70%的联系没有得到很好的标记。此外,不同网络中关系类型的可用性非常不平衡。在某些网络中,例如Slashdot,可能很容易收集标记的关系(例如,用户之间的信任/不信任关系)。Facebook和Google+提供了一个功能,允许用户创建“圈子”(或“列表”)[McAuley和Leskovec 2014]。然而,在许多其他网络中,很难获得标记信息。我们能自动预测社交网络中的关系类型吗?在不同的网络中,完成这项任务的难度差别很大。我们能利用一个(源)网络中可用的标记关系来帮助预测另一个不同(目标)网络中的关系类型吗?这个问题被称为跨异构网络的传输链路预测。与在一个网络中推断社会关系的传统研究(例如,Wang等人[2010]、Crandall等人[2010]和Tang等人[2011])相比,这个问题显示出非常不同的挑战:
首先,没有共同的特点:由于两个网络(源和目标)可能非常不同,没有任何重叠,直接将现有的迁移学习方法应用于这项任务是一个挑战。图1给出了一个跨产品审阅者网络的链接预测示例,该网络来自Epinions.com网站以及一个来自大学的移动通信网络。在产品评价者网络(称为源网络)中,我们标记了(信任和不信任)关系,我们的目标是利用这些信息来帮助预测移动网络(称为目标网络)中用户之间的社会关系(家庭、朋友、同事)。这两个网络完全不同。幸运的是,从结构的角度来看,这两个网络都有一些共同的特性,例如服从幂律度分布[Barabasi and´Albert 1999]和满足社会平衡理论[Easley and Kleinberg 2010]。如何将标记源网络中的结构信息传递给目标网络,以帮助预测目标网络中的未标记结构,是一个基本的挑战。

图1.跨两个异构网络的传输链路预测示例:审阅者网络和移动通信网络。在我们的问题设置中,给定一个具有足够标记关系的源网络和一个只有少量标记关系的目标网络,我们的目标是利用源网络中的标记关系/结构来帮助预测目标网络中的关系类型。
第二,网络不平衡:输入网络的规模可能非常不平衡。例如,像Facebook这样的在线社交网络可能由数百万用户组成,而企业电子邮件网络可能只有数百个用户。考虑到效率和有效性,简单地在一个网络上训练一个模型,然后直接将其应用于另一个网络是不切实际的。
第三,模型泛化:现有的大多数预测社会关系的模型都是针对特定的网络设计的。例如,Wang等人[2010]只考虑了合著者网络。如何设计一个通用的框架以统一的方式将问题形式化?
在这项工作中,我们的目标是对跨异构网络的传输链路预测问题进行系统的研究。综上所述,本文的贡献如下:
—我们精确地定义了这个问题,并提出了一个基于转移的因子图(TranFG)模型。该模型将社会理论融入半监督学习框架,该框架可用于从源网络传递受监督信息,以帮助预测目标网络中的社会联系。
—我们提出了几种积极的学习策略,以提高建议模型的学习性能。为了将模型扩展到大型社交网络,我们开发了一种分布式学习算法。
—我们在六个不同的网络上评估了所提出的模型:Epinions、Slashdot、MobileU、MobileD、Coauthor和Enron。我们表明,与几种替代方法相比,所提出的模型可以显著提高预测不同网络中的社会联系的性能(就F1度量而言平均+14%)。
—我们的研究还揭示了社会科学的几个有趣现象:(1)社会平衡在友谊(或信任)网络上得到满足,但在用户通信网络(如移动通信网络)上不满足(< 20%,差异较大);(2)用户更有可能(比几率高+152%)与跨越结构洞的用户有相同类型的关系;(3)两个强关系比两个弱关系更有可能共享同一类型(在安然和合著者上高出15倍)。
本文是前人工作的延伸[唐等2012]。与以前的工作相比,我们有以下新的贡献:(1)提出了一个新的问题,即主动传输链路预测,并开发了几种有效的策略来解决这个问题;(2)为所提出的模型框架开发分布式学习算法;(3)在各种社会网络中研究新的社会理论——强/弱假设;以及(4)新提出的用于主动传输链路预测的算法的有效性和分布式学习算法的可伸缩性性能的经验评估。图2显示了四种算法在四个不同数据集上的性能比较。显然,提出的最大模型影响(MMI)性能比其他比较算法好得多。图3显示了TranFG模型的分布式学习算法的可伸缩性。分布式学习算法非常高效,用12个内核实现了9倍的加速。

图2.主动学习的表现。人机界面是我们提出的方法;随机、MU、MR是三种比较方法。

文章的其余部分组织如下。第2节介绍了本研究中使用的数据集。第三节阐述问题。第5节介绍了我们对不同网络的观察。第6节解释了提出的模型,并描述了学习模型的算法。第7节介绍了主动学习算法,以增强所提出的模型。第8节介绍了所提出模型的分布式学习算法。第9节给出了实验装置和结果。最后,第10节讨论了相关的工作,第11节结束。
2.数据描述
我们研究了六个不同网络上的转移链接预测问题:Epinions、Slashdot、MobileU、MobileD、Coauthor和Enron。
Epinions是一个由产品审查者组成的网络。数据集来自Leskovec等人[2010b]。网站上的每个用户都可以对任何产品发表评论,其他用户对评论的评价是信任还是不信任。在这些数据中,我们创建了一个由信任和不信任关系相关的审查者组成的网络。数据集由131,828个用户和841,372个关系组成,其中约85.0%为信任关系;80,668名用户获得了至少一种信任或不信任关系。我们在这个数据集上的目标是预测用户之间的信任关系。
Slashdot是一个朋友圈。Slashdot是一个分享科技相关新闻的网站。2002年,Slashdot推出了Slashdot Zoo,它允许用户将彼此标记为“朋友”(喜欢)或“敌人”(不喜欢)。数据集由77,357个用户和516,575个关系组成,其中76.7%是“朋友”关系。我们在这个数据集上的目标是预测用户之间的“朋友”关系。
MobileU是一个移动用户网络。数据集来自Eagle等人[2009]。它由大约10个月内107个用户的通话日志、蓝牙扫描数据和手机发射塔标识组成。如果两个用户相互交流(通过打电话和发短信)或者在同一个地方同时发生,我们就在他们之间建立了一种关系。数据总共包含5,436个关系。我们的目标是预测两个用户是否有朋友关系。为了进行评估,所有用户都需要完成一项在线调查,其中157对用户被标记为朋友。
MobileD是一个相对较大的企业移动网络,节点是公司的员工,关系是由几个月内相互发送的电话和短信形成的。在这个移动网络中,每个用户都被标上他或她在公司中的职位(如经理或普通员工)。总共有232个用户(50名经理和182名普通员工),用户之间有3567种关系(包括打电话和发短信)。这里的目标是根据用户的移动使用模式预测用户之间的经理-下属关系。
Coauthor是一个作者网络。数据集爬取自ArnetMiner.org [Tang等人2008],由815,946个作者和2,792,833个Coauthor关系组成。在这个数据集中,我们试图预测合著者之间的顾问-被顾问关系。为了评估,我们使用以下方法创建了一个较小的基础事实数据:(1)从数学系谱项目2和人工智能系谱项目3收集顾问建议信息,以及(2)从研究人员的主页手动搜索顾问建议信息。最后,我们创建了一个包含1,310个作者和6,096个Coauthor关系的数据集,其中514个是顾问-被顾问关系。
Enron是一个电子邮件通信网络[Diehl等人,2007]。它由151名Enron员工发送的136,329封电子邮件组成。这些员工之间有两种关系,即经理和同事。我们在这个数据集上的目标是预测用户之间的经理-下属关系。共有3572种关系,其中133种是经理-下属关系。
表一列出了六个网络的统计数据。这项工作中使用的所有数据集和代码都是公开的。请注意,有两个略有不同的预测任务:对于前三个数据集(即Epinions、Slashdot和MobileU),我们的目标是预测非定向关系(友谊或信任关系),而对于其他三个数据集(即Coauthor、Enron和MobileD),我们的目标是预测定向关系(源端的社会地位高于目标端,例如顾问-顾问关系和经理-下属关系)。原则上,对于每个预测任务,任何标记的网络都可以被认为是源网络,任何其他网络都可以是目标网络。更具体地说,为了预测无向关系,我们尝试了所有可能的情况:斜点(S)到斜点(T),斜点(S)到斜点(T),斜点(S)到移动点(T),斜点(S)到移动点(T),移动点(S)到斜点(T),移动点(S)到斜点(T)。然而,由于MobileU的规模比其他两个网络小得多,性能要差得多。因此,在实验中,我们只报告前四对网络的结果。(详见表三。)对于预测无向关系,我们尝试了所有可能的转移链接预测任务,并在表四中报告了结果。

3.问题定义
在这一节中,我们首先给出几个必要的定义,然后给出问题的表述。为了简化解释,我们用两个社交网络来构建问题,一个源网络和一个目标网络,尽管将这个框架推广到多网络环境是很简单的。
社交网络可以表示为G = (V,e),其中v表示一组用户,E ⊂ V ×V表示用户之间的一组关系。在我们的问题中,每个关系都有一个标签来指示关系的类型。我们可能有一些关系的标签信息,编码为,对于其他编码为
的关系,我们没有标签信息,其中
。
我们的总体目标是基于社交网络中的可用信息预测中的关系类型。更具体地说,设X是与E中的关系相关联的|E| × d属性矩阵,每行对应于一个关系,每列对应于一个属性,元素
定义关系
的第j个属性的值。关系
的标签表示为
,其中Y是标签的可能空间(例如,家庭、同事、同学)。原则上,标签可以是任意的离散值,但是在这项工作中,为了便于解释,我们将关注二进制情况,例如,移动网络中的朋友对非朋友,合著者网络中的顾问-顾问对同事,或者Epinions网络中的信任对不信任。鉴于此,我们可以得到部分标记网络的以下定义。
定义3.1。部分标记的网络:部分标记的网络被描述为五元组G = (V,,
,X,Y),其中V是一组用户,
是一组标记的关系,
是一组未标记的关系,X是与所有关系相关联的属性矩阵,Y是对应于
中的关系的一组标签,
表示关系
的类型。
在研究单个网络中的链路预测问题时,输入是一个部分标记的网络G = (V,,
,X,Y),目标是预测Y中的未知标签{y},在这项工作中,我们研究跨多个网络的链路预测问题。当考虑两个网络时,我们问题的输入由两个部分标记的网络
(源网络)和
(目标网络)组成,带有
![]() (带有
(带有![]() 的极端情况)。请注意,这两个网络可能完全不同(具有不同的顶点集,即
的极端情况)。请注意,这两个网络可能完全不同(具有不同的顶点集,即![]() ,以及在关系上定义的不同属性),例如产品审查者网络和移动通信网络。
,以及在关系上定义的不同属性),例如产品审查者网络和移动通信网络。
在不同的社交网络中,关系可以是无方向的(例如,移动网络中的友谊)或有方向的(例如,企业电子邮件网络中的经理-下属关系)。为了保持事物的一致性,如果不存在歧义,我们将集中讨论无向网络,尽管我们也将讨论有向网络。在无向网络中,如果我们预测一个有向关系标签(例如,经理-下属关系),那么我们将每个无向关系视为两个有向关系。此外,关系的标签可以是静态的(例如,家庭成员关系)或随时间变化的(例如,经理-下属关系)。在这项工作中,我们关注静态关系。因此,在形式上,我们可以定义以下问题:
问题1。跨社交网络的转移链接预测:给定具有大量标记关系的源网络和具有有限数量标记关系的目标网络
,目标是转移学习预测函数
![]()
用于通过利用来自源网络的监督信息(标记关系)来预测目标网络中的关系类型。
不失一般性,我们假设对于关系的每个可能类型
,预测函数将输出一个概率p(
|
);因此,我们的任务可以看作是为社会网络中的每一种关系获得一个三元组(
,
,p(
|
))。
值得注意的是,虽然我们说目标网络中只有有限数量的标记关系,但标记信息仍然非常重要。如果没有它们,就不清楚目标网络中的学习任务是什么,因为源网络和目标网络可能有不同的预测任务。另一方面,我们的假设是在目标网络中获得标记关系通常是昂贵的。因此,另一个挑战是如何在不损害预测性能的情况下最小化目标网络中标记关系的数量。
有几个关键问题使我们的问题表述不同于现有的关于社会关系挖掘的工作[Crandall等人,2010;Diehl等人,2007年;唐等2011;王等[2010]。首先,源网络和目标网络可能非常不同,例如,合著者网络和电子邮件网络。构成网络结构的最基本的共同因素是什么?第二,目标网络和源网络中的关系标签可能不同。通过使用源网络中可用的信息,我们可以多可靠地预测目标网络中关系的标签?第三,由于源网络和目标网络都是部分标记的,学习框架不仅要考虑标记信息,还要考虑未标记信息。
4.基本预测模型
我们首先描述了学习预测社交网络中的社会联系的几种基本预测模型。
4.1.单网络中的链路预测
当考虑单个网络时,该问题可以被视为分类问题。对于输入网络G = (V,,
,X,Y),每个关系都与一个属性向量和一个指示关系类型的标签
相关联。接下来的任务是找到一个分类模型来预测欧盟关系的标签。一个简单的想法是使用现有的算法,如支持向量机(SVMs)或逻辑回归来训练分类模型[Leskovec等人,2010a]。如果人们进一步想要考虑预测结果{y}之间的相关性,那么诸如条件随机场(CRFs)或因子图模型(FGM)的图形模型是优选的[唐等人,2011]。
我们使用SVMs [Cortes和Vapnik 1995]作为例子来解释如何预测单个社会网络中的社会联系。给定输入网络G中的标记关系,我们可以构建一个训练数据集![]() ,其中
,其中是与关系
对应于其标签的属性向量。分类模型一般有两个阶段,即学习和预测。在学习中,人们试图找到一个最佳的分离超平面,最大限度地分离不同类别的训练样本。超平面对应于SVM分类器。理论上保证了这种方法得到的线性分类器泛化误差小。利用高斯核和多项式核等核函数,可以将线性SVM进一步推广到非线性支持向量机。在预测中,可以使用训练好的分类模型来预测
关系的未知标签。在任务中应用逻辑回归的过程类似于支持向量机。
基于SVM的方法不能通过假设预测结果{y}相互独立来模拟它们之间的相关性。在真实的社交网络中,情况可能并非如此。例如,在合著者网络中,将一个合著者关系预测为顾问-被建议者关系将与另一个合著者关系的预测结果相关联。我们将在第6节解释如何考虑这种相关性。
4.2.跨网络迁移学习
为了将知识从源网络转移到目标网络,可以考虑转移学习模型。我们简要介绍了一个基线迁移学习模型,基于共聚类的迁移学习(CoCC)[戴等,2007a]。
CoCC的基本思想是将标记信息从一组“in-domain”文档的转移到另一组“out-of-domain”文档
。CoCC使用共聚类作为桥梁,将标记信息从域内传播到域外。对域外数据进行聚类旨在同时将域外文档
和单词W分别聚类成|C|文档聚类和k个单词聚类。这里C是两个域的标签空间。
从数学上讲,CoCC试图为基于coclusteringbased的学习优化以下损失函数:
![]()
其中![]() 度量文档和单词之间的互信息;
度量文档和单词之间的互信息;表示文档的聚类;
表示词的聚类;
![]() 定义聚类前后文档和单词之间互信息的损失;并且,类似地,
定义聚类前后文档和单词之间互信息的损失;并且,类似地,![]() 定义聚类前后类标签C和词W之间互信息的损失。通过最小化这个目标函数并建立一个
定义聚类前后类标签C和词W之间互信息的损失。通过最小化这个目标函数并建立一个和C之间的映射,CoCC能够根据聚类成员资格为
中的文档分配类,这使得基于共聚类的迁移学习成为可能。
局限性。为了解决我们的问题,CoCC有三个缺点。首先,它假设域内和域外数据的标签来自同一个标签集。其次,它假设两个域中的特征有很大的重叠。最后,将各种相关特性(如基于社会理论的特性)整合到CoCC模型中并不容易。
5.社会模式
我们现在进行一些高级别的调查,研究不同的因素如何影响不同网络中不同社会关系的形成。一般来说,如果我们考虑预测特定网络中的特定社会关系(例如,从合著者网络中挖掘顾问-被建议者关系[王等人2010]),我们可以定义特定领域的特征并基于标记的训练数据学习预测模型。当处理多个异构网络时,问题变得非常不同,因为不同网络中定义的功能可能有很大不同。为此,我们将我们的问题与几个基本的社会理论联系起来,并通过以下统计数据重点分析基于网络的相关性:
- 社会平衡[Easley和Kleinberg 2010]。不同网络中的社会平衡属性是如何满足和关联的?
- 结构洞[Burt 1992;楼和唐2013]。结构洞在不同的网络中会有相似的模式吗?
- 社会地位[戴维斯和莱因哈特1972;Guha等人,2004年;Leskovec等人,2010b]。不同的网络如何满足社会地位的属性?
- “两步流”[Lazarsfeld等1944]。不同的网络如何遵循信息扩散的“两步流”?
- 强/弱联系假说[Granovetter 1973;Krackhardt 1992]。不同网络中的强联系假设和弱联系假设是如何关联的?


图5。社会平衡。基于通信链接和友谊(或信任关系)的不同网络中平衡三元组的概率。基于通信链路,不同的网络具有非常不同的平衡概率(例如,移动网络中的平衡概率比Slashdot网络高近7倍)。然而,基于友谊,这三个网络有相对相似的概率。
社会平衡。社会平衡理论认为,社会网络中的人往往会形成一个平衡的网络结构。图4展示了这样一个例子来说明三和弦上的结构平衡理论,这是平衡理论适用的最简单的组结构。对于三元组,平衡理论意味着要么这三个用户都是朋友,要么只有一对是朋友。图5显示了三个无向网络(Epinions、Slashdot和MobileU)的平衡三元组的概率。基于基础(通信)链路的平衡三元组的概率计算如下
![]()
基于友谊(或信任关系)的概率计算如下
![]()
在每个网络中,我们比较了基于通信链路的平衡三元组和基于友谊(或信任关系)的平衡三元组的概率。例如,在移动网络中,通信链路包括在用户之间进行呼叫或发送消息。我们发现有趣的是,基于通信链路,不同的网络具有非常不同的平衡概率;例如,移动网络中的平衡概率比Slashdot网络高近7倍,而基于友谊(或信任关系),三个网络具有相对相似的平衡概率(最大差异为+28%)。
结构洞。粗略地说,如果一个用户与社交网络中彼此联系不紧密的人联系在一起,他或她就被认为跨越了社交网络中的一个结构性漏洞[伯特1992]。这样的用户也叫结构洞扳手[楼,唐2013]。基于结构性漏洞的论点表明,在网络中拥有互不认识的朋友是一种信息优势。一个拥有各种关系的销售经理可以被认为是一个结构性的漏洞扳手,与不同社区的个人有一些潜在的薄弱联系。更一般地说,我们可以认为像易趣这样的网站跨越了结构性的漏洞,因为它们促进了人们之间的经济互动,否则他们将无法找到彼此。

图6。结构孔。SH连通和SH不连通分别代表两个连通和两个不连通用户(A和B)与用户C具有相同类型关系的概率,条件是用户C跨越一个结构洞。“随机”表示两个用户(A和B)与用户C具有相同类型关系的平均概率,而不管C是否跨越一个结构洞。很明显,如果C跨越一个结构性的洞,用户更有可能(平均比几率高+70%)与C有相同类型的关系。
我们在这里的想法是测试一个结构孔扳手是否倾向于与其他用户有相同类型的关系。我们首先使用一个简单的算法来识别网络中的结构孔扳手。根据结构洞的非正式描述[伯特1992],对于每个节点,我们计算没有直接连接的邻居对的数量。所有用户根据配对数量进行排名,排名最高的1%结构孔扳手被视为网络中的结构孔扳手。图6显示了两个用户(甲和乙)与另一个用户(比如丙)有相同类型关系的概率,条件是丙是否跨越了一个结构洞。“随机”表示两个用户(A和B)与用户C具有相同类型关系的平均概率,而不管C是否跨越一个结构洞。
我们有两个有趣的观察结果:(1)如果C跨越一个结构洞,用户更有可能与C具有相同类型的关系(例如,在Epinions中,两个用户与结构洞扳手具有相同类型关系的概率比随机情况高+20%),以及(2)断开连接的用户比连接的用户更有可能与被分类为跨越结构洞的用户具有相同类型的关系。一个例外是移动网络,数据集中的大多数移动用户是大学生,因此朋友之间经常交流。

图7。地位理论图解。(A)和(B)满足身份论,而(C)和(D)不满足身份论。这里,正“+”表示目标节点的状态高于源节点,负“-”表示目标节点的状态低于源节点。总共有16种不同的情况。

图8。五种最常见的黑社会社会地位的分布。给定一个三元组(A,B,C),让我们用1来表示顾问-受建议者关系,用0来表示同事关系。数字011表示a和B是同事,B是C的顾问,Ais是C的顾问。
社会地位。另一种社会心理学理论是地位理论[戴维斯和莱因哈特1972;Guha等人,2004年;Leskovec等人,2010b]。这个理论是建立在有向关系网络的基础上的。假设每个有向关系由一个加号“+”或一个负号“-”标记(其中符号“+”/“表示目标节点的状态高于/低于源节点)。然后状态理论假设,如果在三个节点的三角形(称为三元组)中,我们取每个负关系,反转其方向,并将其符号翻转为正,那么所得的三角形(具有所有正关系符号)应该是无环的。图7展示了四个例子。前两个三角形满足状态排序,后两个不满足。我们对Coauthor和Enron网络进行了分析,目的是找到有指导的关系(顾问-顾问和经理-下属)。我们发现,这两个网络中有近99%的三合会成员满足社会地位理论,这一点在Leskovec等人[2010b]中也得到了验证。我们通过观察两个网络中不同形式的三和弦的分布来进行更多的研究。具体来说,总共有16种不同形式的三和弦[Leskovec等人,2010b]。我们选择了两个网络中五种最常见的三和弦形式。为了便于理解,给定一个三元组(A,B,C),我们用1表示顾问-被顾问关系,用0表示同事关系,用三个连续的数字011表示A和Bare同事、B是C的顾问和A是 C的顾问。有趣的是,虽然三个网络(Coauthor、Enron和MobileD)完全不同,但三种概率最高的三合会是相同的,即000、100和101(“101”表示三个用户在三合会中的状态分别为高、低和高)。图8描绘了三个网络中概率最高的五个三元组。实际上,111等一些模式似乎不合理。然而,由于各种原因,现实网络中仍然存在一些情况。在我们的问题中,我们有兴趣理解这种情况在多大程度上是不合理的,以及不同的网络如何在这种社会模式上相互关联。模式关联将用于将信息从源网络传输到目标网络。

图9。意见领袖。OL-意见领袖;OU -普通用户。两类用户有直接关系的概率(从较高的社会地位到较低的地位,即安然中的经理-下属关系和合著者中的顾问-顾问关系)。Average表示两个随机用户具有高状态与低状态用户关系的平均概率。很明显,意见领袖(PageRank检测到的)比普通用户更有可能拥有更高的社会地位。
意见领袖。两步流动理论最早是在Lazarsfeld等人[1944]中介绍的,后来在文献[Katz 1957;卡茨和拉扎斯菲尔德1955]。该理论表明,想法(创新)通常首先流向意见领袖,然后从他们流向更广泛的人群。例如,在企业电子邮件网络中,经理可能充当意见领袖,帮助向下属传播信息。
我们这里的基本思路是考察“意见领袖”是否比普通用户更有可能拥有更高的社会地位(管理者或顾问)。为此,我们首先通过页面排名将用户分为两组(意见领袖和普通用户)。6对意见领袖的研究相当多。例如,宋等人[2007]提出了一种类似PageRank算法(称为影响力排名)来识别意见领袖,而王等人[2011]提出了一种在社交网络中寻找核心成员(精英用户)的算法。然而,设计寻找意见领袖的新措施超出了本文的重点;因此,我们采用简单直观的方法PageRank来选择意见领袖。有了PageRank,根据网络结构,我们选择PageRank评分最高的前1%的用户作为意见领袖,其余的作为普通用户。然后,我们检查两个用户(A和B)具有直接社会关系(从较高社会地位的用户到较低社会地位的用户)的概率,例如顾问-被建议者关系。图9展示了一些有趣的发现。首先,在所有安然、合著者和移动网络中,意见领袖(由PageRank检测到)比普通用户更有可能拥有更高的社会地位(+71%–+156%)。第二,也是更有趣的是,在Enron公司,普通用户很可能比意见领袖拥有更高的社会地位。它的平均可能性比合著者网络大得多(30倍)。原因可能是在企业电子邮件网络中,一些经理可能不活跃,大多数与管理相关的通信都是由他们的助理完成的。
强关系对弱关系。人际关系通常有三种类型:强、弱或无。强关系假设意味着一个人的亲密朋友倾向于和他或她在同一个圈子里活动。相比之下,熟人构成了更不确定、更有活力的社会关系。因此,直观地,用户可能与关系强的朋友具有相似类型的关系,而与关系弱的朋友具有更多样的关系。因此,我们研究了社会关系的类型如何与其强度相关联。
为了简单起见,我们通过以下方式量化社会联系的强度。在Coauthor网络中,对于每一种关系,我们计算被链接的两位作者合著的出版物的数量。在移动网络中,每一种社会关系的强度都是由联系在一起的两个人之间的电话/短信数量来量化的。在Enron公司,实力是通过两个用户之间发送的电子邮件数量来估计的。这时,我们根据实力对所有的社会关系进行排名,把前三分之一视为强关系,其余为弱关系。

图10。强关系对弱关系。两种社会关系共享同一类型的概率,取决于这两种社会关系是强还是弱。Average表示两个随机社会关系共享同一类型的概率。很明显,在所有三个数据集上,两个强联系导致共享同一类型的可能性高于机会,而两个弱联系则更不确定。
图10显示了两种社会关系共享同一类型的可能性,取决于这两种社会关系是强还是弱。它清楚地表明,在所有的数据集中,两个强关系导致共享同一类型的可能性比机会更高,而两个弱关系更不确定:两个弱关系共享同一类型的可能性仅仅是安然和合著者两个随机社会关系的九分之一。
总结。根据这些统计,我们有以下直觉:
- 基于通信链路的平衡三元组的概率在不同的网络中非常不同,而基于友谊(或信任关系)的平衡概率彼此相似。
- 用户更有可能与跨越结构性漏洞的用户建立相同类型的关系(高出25%-152%)。
- 大多数三元组(99%)满足社会地位理论的性质。对于五个最常见的三元组,Coauthor,Enron和 MobileD网络共享一个类似的分布。
- 意见领袖比普通用户更有可能拥有更高的社会地位(高出几率(+71%–156%)。
- 两个强关系共享同一类型的可能性比几率高(+22%–52%),而两个弱关系的不确定性要大得多(两个随机社会关系共享同一类型的可能性的九分之一)。
基于这些观察,我们相应地定义了第4节中介绍的迁移学习模型的特征。不同特征的重要性将由学习模型决定。粗略地说,如果基于社会理论的特征具有相似的模式(例如,社会平衡在两个网络上具有相似的分布),则该特征在学习模型中具有高权重;否则,它的重量会很小。
6.传输链路预测的模型框架
我们提出了一个基于传输的框架。该框架的基本思想是将社会理论整合到一个因子图模型中,用于学习和预测不同网络中的社会关系类型。
6.1.概率因子图模型
让我们从图形模型的简单介绍开始。图形模型与基于分类的模型(如SVM)的主要区别在于,图形模型可以通过结合“边缘”特征(也称为相关特征)来对预测结果之间的相关性进行建模。一般来说,有两种图形模型:有向图形模型和无向图形模型[Wainwright和Jordan 2008]。在这项工作中,我们考虑无向图形模型。在无向图形模型中,图形由变量![]() 和这些变量之间的相关性的集合构成,根据图形结构,图形上的概率分布可以分解为在图形的小集团上定义的函数的集合。团c是图中变量的完全连通子集。例如,如果团c由图中的两个顶点组成,那么Yc表示两个对应变量的集合(例如,
和这些变量之间的相关性的集合构成,根据图形结构,图形上的概率分布可以分解为在图形的小集团上定义的函数的集合。团c是图中变量的完全连通子集。例如,如果团c由图中的两个顶点组成,那么Yc表示两个对应变量的集合(例如,![]() )。根据无向图模型的理论[Hammersley
)。根据无向图模型的理论[Hammersley
and Clifford 1971],我们可以将一个函数与每个团相关联,即f(Yc)。鉴于此,图的概率分布分解为

其中Z是一个归一化因子,也被视为一个常数,选择该常数是为了确保分布被归一化,从而概率之和等于1。
因子图提供了一种描述(无向)图形模型的替代方法,更强调分布的因子分解[Kschishang等人,2001]。我们将在以下章节中使用因子图进行解释。基本上,应用图形模型预测社会关系的过程也包括两个阶段:培训和预测。通常在图形模型中,人们试图最大化与给定训练数据中对应关系的属性的关系相关联的标签的条件概率,即![]() 。因此,在训练中,它试图找到使标记关系
。因此,在训练中,它试图找到使标记关系上的条件概率最大化的参数配置,并且在预测中,它试图为未标记的关系
找到一组标签
以使条件概率P最大化
![]() 。当图结构包含圈时,直接最大化条件概率
。当图结构包含圈时,直接最大化条件概率![]() 往往是难以处理的。因子图是一种将“全局”概率分解为“局部”因子函数乘积的方法,每个因子函数取决于图中变量的子集[Kschischang等人,2001]。
往往是难以处理的。因子图是一种将“全局”概率分解为“局部”因子函数乘积的方法,每个因子函数取决于图中变量的子集[Kschischang等人,2001]。
等式(4)可以用因子函数来解释。每个f(Yc)代表一个在Yc中包含的变量上定义的因子。这种表示在变量子集之间的条件独立性方面也有一个属性,在无向图形模型中也称为马尔可夫属性。这里我们简单介绍一下条件独立的概念。感兴趣的读者可以参考Lauritzen [1996]。对于无向图形模型,如果两个变量在图形模型中是断开的,那么我们说这两个变量是独立的。假设,
,
是三个变量的任意三重。设
接
,
接
。如果变量
和
仅通过
连接(即,在没有变量
的情况下断开),我们说变量
和
是条件独立的。这个性质也可以从多个变量推广到多个不相交的变量子集。

图11。三元因子图(TriFG)模型的图形表示。每个椭圆表示一种关系;例如,(,
)表示
和
之间的关系。符号
表示与关系(
,
)相关的属性向量。对于每一种关系,我们用一个对应的潜在变量y来表示它的类型。每个黑色方块表示一个因子函数,该函数将相关变量作为输入,并输出一个实数。
关于我们问题中概率因子图模型的图形结构,我们将每个关系视为图形模型中的一个观察变量x。我们把每个观察变量和一个潜在变量联系起来,并在每个观察变量和它的潜在变量之间定义一个局部因子函数。我们还定义了潜在变量之间的相关性。请注意,相关性可以在多个关系之间定义;例如,三元函数被定义为捕捉社会平衡结构的相关性。关系之间的相互关系构成了因子图模型的图形结构。更具体地说,如果我们定义了两个潜在变量之间的相关函数,那么在两个变量之间就产生了一个边,如果我们定义了一个社会平衡的相关函数,那么就构造了一个三元函数结构。图11显示了三元因子图(TriFG)模型的图形表示[娄等人,2013]。每个椭圆表示一种关系;例如,(,
)表示
和
之间的关系。更准确地说,在模型中,它表示与关系相关联的属性向量x。每个圆是一个变量y,表示对应关系的类型。每个黑色方块表示一个因子函数,该函数将相关变量作为输入,并输出一个实数。因子函数f(x1,y1)被定义在与关系(
,
)( 或
)相关联的属性上,并且因子h(y1,y2)被定义为捕捉y1和y2之间的相关性。具体来说,如果我们只考虑成对相关,即成对关系之间的相关,那么就可以相应地构造成对因子图模型[Kschischang等,2001;唐等2011]。它的基本原理也类似于条件随机场[Lafferty等人,2001],马尔可夫随机场的条件变化。在我们的因子图模型中,我们将两两相关和三元组都视为派系,因为我们在第5节中讨论的几个社会理论(如社会平衡和社会地位)是基于三元组的。在这种情况下,基本的成对因子图被扩展为三元因子图(TriFG)。如图11中的例子所示,我们可以定义六个属性因子函数,
![]() 和
和![]() ;四个成对相关因子函数,
;四个成对相关因子函数,![]() ;和一个三元相关因子函数
;和一个三元相关因子函数![]() 。根据因子图中的因子分解原理[Kschischang等人,2001],我们可以用这些因子函数的乘积来表示联合概率
。根据因子图中的因子分解原理[Kschischang等人,2001],我们可以用这些因子函数的乘积来表示联合概率![]() ,如下所示:
,如下所示:
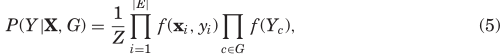
其中![]() 表示根据属性xi定义的因子函数,c是图上的团(例如,三元组(y4,y5,y6)),
表示根据属性xi定义的因子函数,c是图上的团(例如,三元组(y4,y5,y6)),![]() 是包括在团c中的一组标签变量。最后,Z是一个归一化因子,是y所有可能值的总和,形式上可以写成
是包括在团c中的一组标签变量。最后,Z是一个归一化因子,是y所有可能值的总和,形式上可以写成

有不同的方法来实例化两个因子函数![]() 和
和![]() 。一种广泛使用的方法是将它们定义为指数线性函数,即,
。一种广泛使用的方法是将它们定义为指数线性函数,即,

其中和
是两个归一化因子,以确保分布的和等于1;等式(6)表明,我们为与关系
相关联的每个属性
定义了一个特征函数
![]() ,并且
,并且是第j属性的权重。它可以定义为二元函数或实值函数。例如,为了预测来自发表网络的顾问-受建议者关系[王等人,2010],我们可以将实值特征函数定义为当作者
和
分别发表他们的第一篇论文时的年差。等式(8)表示我们为网络中的每个团定义了一组相关特征函数
![]() 。这里
。这里是第k个相关特征函数的权重。最简单的团代表两个关系
和
之间的成对相关
![]() 。
。
通过将等式(6)和(8)集成到等式(5)中,我们可以获得以下对数似然目标函数:

这里我们用θ表示所有未知参数,即({α},{μ});和
被合并成Z,Z可以被视为一个常数,以确保分布之和等于1。
如果给我们一个标签为Y的网络G,学习预测模型就是估计一个参数配置θ*= ({α},{μ})最大化对数似然目标函数![]() ,即,
,即,
![]()
注意和限制。值得注意的是,在实践中,训练和预测都将在同一个网络上进行,这不同于传统的学习设置,传统的学习设置是馈送几个图形进行训练,而使用其他图形进行预测。在这种情况下,有必要设计一种能够在同一输入网络上同时执行训练和预测的方法。在下面的小节中,我们将把因子图看作一个部分标记的网络,并一起执行学习和预测任务。因子图模型的另一个限制是,它假设训练和预测中的所有例子具有相同的特征分布。这使得很难将因子图模型直接应用于我们预测跨社交网络的社交联系的问题,因为在我们的问题中,源网络和目标网络可能非常不同,在X中没有任何共同特征。
6.2.基于转移的因子图模型
现在我们讨论如何设计一个因子图模型来学习预测不同网络之间的社会联系。基本思想是利用图形模型的能力,该模型可以对预测结果之间的相关性进行建模,同时避免现有迁移学习模型的局限性。更具体地说,我们专注于学习具有两个异构网络(源网络和目标网络
)的预测模型。坦率地说,我们可以为这两个网络定义两个独立的目标函数。面临的挑战是如何将两个网络连接起来,这样我们就可以从源网络传输标记信息,以帮助预测目标网络中的社会联系。由于源网络和目标网络可能来自任意域,因此很难基于先验知识定义它们之间的相关性。
为此,我们提出了一个基于转移因子图的模型。我们的想法是基于这样一个事实,即我们在第5节中讨论的社会理论在所有网络中都是通用的。直觉上,我们可以利用这种相关性,使不同的网络满足每个要转移的社会理论。然后,我们可以根据社会理论定义特征,同时优化两个网络上的目标函数。通过将社会理论整合到我们的预测模型中,我们在源网络和目标网络上定义了以下对数似然目标函数:
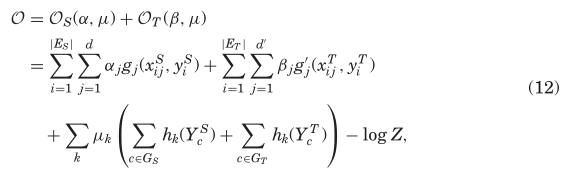
其中d和d’分别是源网络和目标网络中的属性数。在该目标函数中,第一项和第二项分别定义了源网络和目标网络上的似然性,而第三项定义了两个网络中定义的公共特征上的似然性;函数是根据社会理论定义的公共特征,
是相应特征的权重(重要性)。根据定义,如果一个共同特征具有相似的模式(例如,社会平衡在两个网络上具有相似的分布),那么该特征将具有高权重μ;否则,它的重量会很小。这样的定义还意味着两个网络的属性可以完全不同,因为它们是用不同的参数{α}和{β}优化的,而从源网络传递到目标网络的信息是根据社会理论定义的共同特征的重要性。
如前所述,另一个问题是输入网络可能被部分标记;因此,有必要在同一输入网络上同时执行训练和预测。我们将在第6.4节讨论这个问题。
6.3.因子函数定义
我们现在转到因子函数的定义。主要有两种类型的功能。第一类功能是特定于域的功能,在不同的网络中有所不同。例如,在移动网络中,我们可以将每个关系的特征定义为两个用户之间的通话次数。附录详细介绍了我们如何为每个网络定义这些功能。
第二类特征是根据社会理论定义的共同特征。这是这项工作的贡献之一。
社会平衡:定义了四个(实值)特征,分别代表网络中四种(非)平衡三角形的比例。
社会地位:根据社会地位理论[Leskovec等2010b],共有16个不同的三合会。在我们的案例中,我们发现其中只有7个存在于我们的网络中。我们在三元组上定义了七个(实值)特征(011、101、110、100、000、111和111),分别表示三元组形成的概率。
结构洞:我们定义了基于关系相关性的特征,即两个关系和
之间的相关性。例如,如果两个带C都与被识别为结构孔扳手的A连接,则为两个关系(A-B和A-C)定义两个相关特征:一个用于连接的B和C,另一个用于未连接的B和C。
意见领袖:为每个关系(甲乙)定义了四个(二元)特征。其中两个代表当和都是意见领袖或普通用户时,而另外两个特征代表当一个是意见领袖而另一个是普通用户时。
强/弱联系:定义了三个(实值)特征来表示两个关系都是强联系,都是弱联系,或者一个是强联系,另一个是弱联系。
最后,我们定义了四个(实值)基于平衡的特征,七个(实值)基于状态的特征,四个(二进制)特征用于意见领袖,六个(实值)相关特征用于结构洞,三个(实值)特征用于强/弱联系。
6.4.模型学习和预测
最后一个问题是学习TranFG模型,并预测目标网络中未知关系的类型。学习TranFG模型是为了估计一个参数配置θ = ({α},{β},{μ})使对数似然目标函数O(α,β,μ)最大化。学习算法总结在算法1中。

有两个挑战。首先,由于社交网络中的网络结构可以是任意的(可能包含循环),因此使用诸如连接树的现有方法来获得目标函数的精确解是难以解决的[wiegrinck 2000]。可以考虑许多近似算法,例如Loopy置信传播(LBP)[墨菲等人1999]和Mean field[邢等人2003]。人们还可以推导出原始优化问题(方程(12))的对偶形式,并使用投影次梯度方法[Komodakis等人,2011]来求解该问题。我们选择了循环信念传播,因为它易于实施和有效。具体来说,我们近似边际分布![]() 使用LBP。利用边际概率,梯度可以通过对所有三元组求和来获得。理论上,该算法不能保证收敛,并可能导致局部最大值,但实际上它的性能是好的。我们将在实验部分对算法的有效性和效率进行实证研究。
使用LBP。利用边际概率,梯度可以通过对所有三元组求和来获得。理论上,该算法不能保证收敛,并可能导致局部最大值,但实际上它的性能是好的。我们将在实验部分对算法的有效性和效率进行实证研究。
另一个挑战是两个输入网络都可能被部分标记。为了解决这个问题,我们使用标签关系来推断未知标签。这里Y|YL表示从已知标签推断的标签配置Y。技术上,我们使用额外的LBP过程来推断未标记关系的边际概率。在算法1中,步骤1用于计算源网络中未知关系的边际分布,步骤2用于分别计算目标网络中未知关系的边际分布。在唐等人[2011]中首次引入了类似的学习算法。
我们使用梯度下降法(或牛顿-拉夫森法)来求解目标函数。具体来说,我们首先写出每个未知参数(α,β,μ)相对于目标函数的梯度(我们以α为例,推导其梯度w .r .t .目标函数):

其中我们假设和
在给定的数据集中均匀分布,因此P(
,
)具有均匀分布;
![]() 是给定源网络中数据分布的局部因子函数
是给定源网络中数据分布的局部因子函数![]() 的期望,
的期望,![]() 是给定目标网络中的数据分布局部因子函数
是给定目标网络中的数据分布局部因子函数![]() 的期望;
的期望;![]() 是给定数据分布的因子函数
是给定数据分布的因子函数![]() 的期望值(即源和目标网络中所有三元组的因子函数
的期望值(即源和目标网络中所有三元组的因子函数![]() 的平均值);以及每个方程中的第二项,即
的平均值);以及每个方程中的第二项,即![]() 和
和![]() ,分别表示模型学习到的分布下的期望,即
,分别表示模型学习到的分布下的期望,即![]() 。由于图形结构可以是任意的,并且可能包含循环,我们使用循环信念传播(LBP)[墨菲等人,1999]来近似梯度。为了利用未标记的关系,我们需要在每次迭代中执行两次LBP过程,一次用于估计未知变量的边际分布yi=?另一次是所有派系的边际分布。最后,利用梯度,我们用学习率η更新每个参数。关于学习率η,我们采用一种经验但有效的方法来设置它的值——首先我们使用一个大的η,并在随后的学习迭代中逐渐减小它的值。这种方法已经广泛应用于机器学习中。我们还可以看到,在学习过程中,算法使用了一个额外的循环信念传播来预测未知关系的标签。在学习之后,所有未知的关系都被赋予最大化边际概率的标签。
。由于图形结构可以是任意的,并且可能包含循环,我们使用循环信念传播(LBP)[墨菲等人,1999]来近似梯度。为了利用未标记的关系,我们需要在每次迭代中执行两次LBP过程,一次用于估计未知变量的边际分布yi=?另一次是所有派系的边际分布。最后,利用梯度,我们用学习率η更新每个参数。关于学习率η,我们采用一种经验但有效的方法来设置它的值——首先我们使用一个大的η,并在随后的学习迭代中逐渐减小它的值。这种方法已经广泛应用于机器学习中。我们还可以看到,在学习过程中,算法使用了一个额外的循环信念传播来预测未知关系的标签。在学习之后,所有未知的关系都被赋予最大化边际概率的标签。
笔记。值得注意的是,在第5节中研究的社会模式捕捉了两个网络之间的共同特征,并且所提出的TranFG模型可以通过结合社会模式来推广到不同的网络,尽管还有一个挑战,即网络不平衡。两个网络的输入规模可能非常不平衡:一个非常大,另一个小得多。这使得转移学习的性能(包括效率和有效性)在不同的网络上不稳定。
7主动迁移学习
针对网络不平衡的问题,本文提出采用主动学习的方法对提出的TranFG模型进行改进。通过主动学习,我们的目标是最小化目标网络中的标记关系。随着人们对标记关系研究的深入,有必要获得足够的标记信息。如第9.2节所示,目标网络中标记关系的数量确实对预测性能有很大的影响。通过主动学习,我们的目标是在不影响预测性能的前提下最小化标记关系的数量。我们考虑了几种不同的主动学习策略,实验结果证明了所提策略的有效性。
有许多主动学习方法,如最大不确定性和信息密度[Settles and Craven 2008],而大多数方法不考虑网络信息。在这一部分中,我们首先介绍了两种基本的方法,最大不确定性(MU)和最大代表性(MR),它们不考虑网络信息。在此基础上,提出了一种最大模型影响(MMI)方法,该方法综合考虑关系的不确定性和网络信息,主动选择未标记的关系进行查询。Zhuang等人[2012]首次提出了MMI方法。
最大不确定度(MU)。主动学习的直接策略是选择目标网络中最不确定的实例(即我们案例中的关系)。未标记关系的不确定度由其熵
测量:
![]()
其中可在学习因子图模型后获得。对于每个关系,我们计算其熵,然后根据得到的熵得分对所有关系进行排序。最后,在主动学习中,选取熵得分最高的m个关系。
最大代表性(MR)。最大不确定性策略倾向于选择异常值。避免这种情况的一个想法是使用信息密度策略[Settles and Craven 2008],目标是选择最具代表性(未标记)的关系,这些关系应该是信息量最大的关系。特别是,我们可以通过一个关系的余弦相似性来衡量它的信息性,这个余弦相似性是指与该关系相关的属性。关系的信息性可以定义为

其中![]() 。再次,在主动学习中,我们选择代表性得分最高的m关系。
。再次,在主动学习中,我们选择代表性得分最高的m关系。
最大模型影响(MMI)。在提出的TranFG模型中,关系是相互关联的,意识到一些“有影响力”的关系可能有助于预测其他关系的类型。然而,前两种策略没有考虑相关信息。基于Kempe等人[2003]提出的线性阈值模型(LTM)的思想,我们提出了一种影响传播方法。LTM模型是一种影响最大化模型,其目标是在网络中找到一个能够最大化影响传播的节点子集(种子节点)。LTM模型为每个节点设置一个阈值,并为节点i和j之间的边设置一个权重
,满足
![]() ,其中NB(i)表示节点i的一组邻居。在每个时间戳中,如果
,其中NB(i)表示节点i的一组邻居。在每个时间戳中,如果![]() ,则节点i将被激活。
,则节点i将被激活。
我们通过将反映影响传播强度的每一个关系的分数纳入模型,来发展LTM的变化。主动学习方法的基本思想是,如果我们主动标记一组未知关系,并触发许多其他关系获得分数,使他们的每一个分数都大于其阈值,那么我们认为这是一个好的选择。为了量化这一点,我们定义了以下传播过程:(1)初始化:图形与TranFG模型相同。当关系的标签被赋予时,我们称之为“激活”。初始激活的关系集是标记关系
的集合。我们为每个关系指定阈值
![]() 。从这个意义上说,具有更高不确定性的关系更容易激活。(2)影响:当关系
。从这个意义上说,具有更高不确定性的关系更容易激活。(2)影响:当关系被激活时,它将其获得的分数增量
扩展到权重为
的因子图中的相邻关系
![]() ,即
,即![]() (3)扩展:如果用户标记了关系,则将其设置为激活,并将其获得的分数分配为1。其他关系的获得分数在开始时设置为0。一旦失活关系
(3)扩展:如果用户标记了关系,则将其设置为激活,并将其获得的分数分配为1。其他关系的获得分数在开始时设置为0。一旦失活关系获得超过阈值的分数,即
,它将被激活并同样地传播其获得的分数。最后,将最大模型影响得分
定义为在未知关系
上使用关系标签
时,目标网络中激活关系的总数。在我们的实验中,为了有效地评估MMI中关系的影响,我们采用了类似于Chen等人[2009]中开发的方法。
算法与分析。找到一组最大化最大模型影响分值总和的关系。[2003].因此,类似地,我们使用贪婪策略,以最优解的比率(1-1/e)来逼近解。具体来说,在主动学习过程中,我们为每个未标记的关系计算MMI分数,并最终在每次迭代中选择具有最高代表性分数的关系。我们对贪婪算法的逼近率分析如下。
首先,我们首先给出子模集函数的定义。
定义7.1(子模型)。在集合S上定义的集合函数F被称为子模函数,如果对于所有的A⊂B⊂S和s∉ B,它满足
![]()
函数F是单调递增的,如果对于所有集合S⊆T⊆V,存在
![]()
对于一个既单调递增又是子模的函数F,我们可以主动地把k个关系一个接一个地选入一个集合T,假设关系是![]() ,我们用
,我们用表示第i步
![]() 。我们看到,每次在T中加入一个关系,就有一个F(T)的增量。如果以前的一些关系没有增加,这个增量会变大或保持不变。在每一步,我们选择添加一个关系y ∈ E,使
。我们看到,每次在T中加入一个关系,就有一个F(T)的增量。如果以前的一些关系没有增加,这个增量会变大或保持不变。在每一步,我们选择添加一个关系y ∈ E,使![]() 。这样我们可以用一个贪婪的启发式,就是每次我们选择f(T)增加最多的关系,就是,
。这样我们可以用一个贪婪的启发式,就是每次我们选择f(T)增加最多的关系,就是,
![]()
直观地说,贪心算法可以为最大化F(T)的k-关系集T的采样问题生成一个很好的近似解。假设生成集为T,最优集为T*。根据f的单调性质,我们考虑了T∪T*,它的函数值大于(或在更差的情况下等于)T*的函数值。我们可以这样构造T∪T*:我们首先使用一个贪婪的启发式算法,并在其中加入T的k个关系,然后我们一个接一个地在T*-T中加入关系,对于T*-T中的每个关系, 增量不大于T中任一关系的增量,因为l ≤ k,所以必须有![]() 。 Nemhauser等人[1978]报道了一种更紧密的结合。对于E上的每一个单调递增的子模非负函数F,贪婪启发式算法生成的集合至少是最优解的(1-1/e)。
。 Nemhauser等人[1978]报道了一种更紧密的结合。对于E上的每一个单调递增的子模非负函数F,贪婪启发式算法生成的集合至少是最优解的(1-1/e)。
8.分布式学习
由于真实的社交网络可能包含数百万用户和关系,因此学习算法在大型网络中很好地扩展是很重要的。为了解决这个问题,我们开发了一种基于MPI(消息传递接口)的分布式学习方法。第9节将介绍所提出方法的可扩展性能。
基本上,学习算法包括两个步骤:(1)通过循环信念传播计算每个参数的梯度和(2)用梯度下降优化所有参数。最昂贵的部分是计算梯度的步骤。因此,我们开发了一种分布式算法来加速这个过程。我们采用主从架构;也就是说,一台主机负责优化参数,而另一台从机负责计算梯度。在算法的开始,TranFG的图形模型被划分成M个大致相等的部分,其中M是从处理器的数量。这个过程是由图划分软件METIS完成的[Karypis和Kumar 1998]。子图然后分布在从属节点上。请注意,在我们的实现中,不同子图之间的相关性(因子)被消除,这导致了近似的解决方案。METIS是一个图形分割工具。它的目标是最小化图的边的切割,这样在切割之后,图上的所有节点可以被分组到M个子图中。通过最小化切割,我们可以得到一个更好的近似值。在分布式学习的每次迭代中,主机向所有从机发送最新的参数θ。从属机器随后开始在相应的子图上执行循环信念传播,以计算“局部”信念(边际概率)。具体来说,每个从属处理器根据以下等式计算子图上的“局部”置信(边际概率)(我们再次使用
![]() 作为解释中的例子):
作为解释中的例子):

其中σ表示归一化常数;![]() 是从节点
是从节点传播到节点
的“信念”;NB(i)\j表示子图
中除
以外的所有邻近节点;
![]() 表示子图
表示子图中与
相关的所有定义的因子函数。通过
![]() 计算;符号
计算;符号![]() 表示从每个子图中收集的未规范化的“局部”信念。
表示从每个子图中收集的未规范化的“局部”信念。
在获得局部信念后,每个从机计算参数梯度并将其发送回主机。最后,主机收集并总结从不同子图获得的所有梯度,并通过梯度下降法更新参数。表二总结了主机和从机之间传输的数据。

还有一点值得注意。由于许多相关因子是在三元组上定义的,如果我们简单地消除那些跨不同子图定义的相关因子,消除的基于三元组的因子将占完全定义的基于三元组的因子的很大一部分,即使有少量的M。这极大地损害了所提出的三元组模型的性能。为了缓解这个问题,我们提出了一种基于虚拟节点的方法。特别地,假设图形模型中的三个关系(y1,y2,y3)与三元组因子h(y1,y2,y3)相关联。如果分区将两个关系(例如y1和y2)分配到一个子图中,并将另一个关系(例如y3)分配到另一个子图中,那么我们在第一个子图中创建虚拟关系,使得三元组因子仍然可以在子图中计算。(为了避免冗余,我们不考虑与虚拟关系相关联的本地属性因素。)如果这三个关系被分配给三个不同的子图,那么我们随机选择一个子图并创建两个虚拟关系来计算基于三元组的相关因子函数,并忽略它在其他两个子图中的计算。
9.实验结果
9.1。实验装置
所提出的框架非常通用,可以应用于许多不同的网络。在实验中,我们考虑了六种不同的网络:Epinions、Slashdot、MobileU、MobileD、Coauthor和Enron。在前三个网络(Epinions、Slashdot和MobileU)中,我们的目标是预测无向关系(如友谊),而在其他三个网络(MobileD、Coauthor和Enron)中,我们的目标是预测有向关系(如顾问-顾问关系)。
比较方法。我们比较了以下预测社会关系类型的方法。
SVM:类似于莱斯科维克等人[2010a]中使用的逻辑回归模型,SVM使用与每个关系相关联的属性作为特征来训练分类模型,然后使用分类模型来预测测试数据集中关系的标签。对于SVM,我们使用SVM灯。
CRF:它训练了一个条件随机场[拉弗蒂等人,2001],其属性与每个关系相关联,关系之间也有相关性。
PFG:该方法也是基于通用报告格式,但它使用未标记的数据来帮助学习预测模型。该方法由唐等人[2011]提出。
COCC:利用聚类将标签信息从一个网络转移到另一个网络[戴等,2007a]。这是一种基于迁移学习的方法。
TranFG:这是一种提议的方法,它利用来自源网络的标记信息来帮助预测目标网络中的关系类型。
我们还比较了王等人[2010]在出版物网络中提出的挖掘顾问-被顾问关系的方法。这种方法是特定于领域的,因此我们只在Coauthor网络上进行比较。
在所有实验中,我们对所有方法使用相同的特征定义。在 Coauthor网络中,我们不考虑某些特定领域的相关特性。
评估措施。为了定量评估所提出的模型,我们考虑了以下性能指标:
—预测精度。我们通过不同的方法应用所学习的模型来预测目标网络中的链接类型,并根据精确度、召回率和F1-Measure来评估其性能。
—社会理论如何能有所帮助。我们分析社会理论如何帮助提高预测性能。
—主动学习能有多大帮助。我们使用不同的主动学习算法来选择关系以主动查询它们的标签,并评估主动学习如何帮助提高预测性能。
—效率和可扩展性性能。我们将计算时间作为效率度量来评估所提出模型的效率和可伸缩性。
9.2.预测性能与分析
跨异构网络的预测准确性。我们比较了预测友谊(或信任关系)的四种方法在四对网络上的性能:外倾(S)到外倾(T),外倾(S)到外倾(T),外倾(S)到移动(T),外倾(S)到移动(T)。在所有实验中,我们使用目标网络中40%的标记数据进行训练,其余的用于测试。对于传输,我们考虑源网络中的标记信息。表三列出了四个测试用例中不同方法的性能。我们的方法显示出比三种替代方法更好的性能。我们对每个结果进行了符号测试,结果表明我们的方法在三种方法上的所有改进都具有统计学意义(p≤0.01).



表四显示了五种方法(包括在Coauthor数据集上挖掘顾问-被建议者关系的[王等人2010])在六对网络上预测定向关系(源端具有比目标端更高的社会地位)的性能:Coauthor(或MobileD) (S)到Enron(T)、Enron(或MobileD) (S)到Coauthor(T)、Coauthor(或Enron)(S)到MobileD (T)。在每个测试案例中,我们再次使用目标网络中40%的标记数据进行训练,其余的用于测试,而对于传输,我们考虑来自源网络的标记信息。我们看到,通过利用来自源网络的监督信息,我们的方法明显提高了性能(Coauthor的F1分数提高了约15%,移动用户提高了20%,安然公司提高了23%)。另一个现象是预测精度与源网络的大小相关。例如,当预测Enron网络中的经理-下属关系时,我们使用Coauthor网络(1,310个作者和6,096个关系)作为源网络比使用移动网络(232个用户和3,567个关系)作为源网络(89.6%对81.8%)获得更高的准确性。从结果中还可以看出,不同预测任务的转移性能是不同的。例如,从Epinions传输比从Slashdot传输对MobileU网络更好。实际上,传输链路预测的性能取决于源网络与目标网络之间的相关性。如果两个网络彼此更相似,则可以从源网络传输更多信息来帮助目标网络。
PFG方法可以看作是我们的方法的不可转移的对应物,它不考虑来自源网络的标记信息。从表三和表四中,我们可以看到,利用传递的信息,我们的方法明显提高了关系分类性能。另一个现象是,PFG在大多数情况下比其他两种方法(SVM和通用报告格式)有更好的表现。PFG利用了目标网络中未标记的信息,从而提高了性能。唯一的例外是Slashdot (T)的Epinions (S),Slashdot中的用户似乎具有相对一致的模式,并且仅具有一些一般特征,例如入度、出度和公共邻居的数量,基于分类的方法(SVM)可以获得非常高的性能。
跨同构网络的预测精度。我们研究当源网络和目标网络是同构的,即相同类型的网络时,算法的性能如何。具体来说,我们将六个网络中的每一个划分为两个子网络,并将其中一个用作源网络,另一个用作目标网络。对于目标网络,我们再次考虑40%的标记信息,对于源网络,我们考虑所有的标记信息。
表五显示了通过跨同构网络学习来预测关系的准确性。同质转移实际上代表异质转移的上限。我们看到,我们的异构传输模型(TranFGHeter)的性能接近上限。
传输链路预测的偏差分析。从表一我们看到,对于一些网络,比如Epinions和Slashdot,正面关系(信任和朋友关系)的数量远远大于负面关系,而在其他一些网络,比如合著者和安然,情况则完全不同。我们进行了一个实验来研究不平衡的正/负关系如何影响传输链路预测的性能。图12显示了通过改变源网络中正/负实例的比率,对有向关系和无向(朋友和信任)关系的传输链路预测的结果。例如,从合著者到安然,#正/#负=2表示合著者网络中的正关系数是负关系数的两倍。具体来说,我们在合著者中固定了积极关系的数量,并随机抽取了一半的消极关系。我们看到预测性能对偏差问题不敏感。这证实了所提出的TranFG模型的有效性。

9.3.社会理论有什么帮助?
我们现在分析不同的社会理论(社会平衡、社会地位、结构洞、两步流(意见领袖)和强/弱关系)如何帮助预测社会关系。从第5节,我们看到社会理论在不同的网络上有相似的模式,可以用来连接不同的网络。同时,从图5到图10,我们也可以看到不同的网络之间还是有区别的。例如,在图6中,在MobileU上获得的概率不同于从其他两个网络获得的概率。在迁移学习中,迁移模型将决定不同学习任务的不同社会理论因素的权重。例如,在从合著者到移动的学习预测社会联系中,四个基于社会平衡的因素的学习权重分别为0.002248、0.000121、-0.001544和-0.000825,这表明前两个基于平衡结构的因素在两个网络之间具有正相关性,而其他两个基于不平衡结构的因素在两个网络之间具有负相关性。

图13。因素贡献分析。TranFG-SH表示我们的TranFG模型,忽略了基于结构的ole传递。TranFG-SB代表忽略基于结构平衡的转移。TranFG-OL代表忽略基于意见领袖的转移,而TranFG-SS代表忽略基于社会地位的转移
为了预测友谊,我们考虑了基于社会平衡和结构洞的转移,为了预测定向友谊,我们考虑了基于社会地位、意见领袖和强/弱关系的转移。在这里,我们检查了在我们的TranFG模型中定义的不同因素的贡献。图13显示了不同网络上的F1-Measure平均分数,该分数是通过预测友谊和定向关系的TranFG模型获得的。特别是,特兰夫-SB代表我们从我们的模型中去除了基于社会平衡的转移特征;转换-软件-语言表示我们删除了基于强/弱联系和意见领袖的转换功能;“全部”表示我们删除了所有传输功能。可以清楚地观察到,当忽略每个因素时,性能会下降。我们还可以看到,对于预测友谊,社会平衡比结构洞更有用,对于预测定向关系,意见领袖因素比强/弱关系和结构洞因素更重要。分析证实,通过结合不同的社会理论,我们的方法可以很好地工作(得到进一步的改进)。
基于社会平衡和结构洞的转移。我们对基于社会平衡和结构洞的转移如何通过改变目标网络中标记训练数据的百分比来提供帮助进行了深入分析,如图14所示。我们发现,在所有情况下,除了Slashdot到Epinions,当目标网络中的标记数据有限(≤50%)时,通过使用基于社会平衡和结构洞的转移可以获得明显的改善。事实上,在某些情况下,如斜线点的Epinions,在斜线点中只有10%的标记关系,我们的方法可以获得良好的性能(88%的F1分数)。没有转会,最好的表现也只有70%(SVM获得)。我们还发现,在大多数情况下,基于结构平衡的转移比基于结构洞的转移更有助于预测带有不同百分比标记关系的友谊。这一结果与因子贡献分析的结果一致。
在Slashdot到Epinions的情况下发现了不同的现象,其中所有方法都可以用10%的标记数据获得94%的F1分数。知识转移似乎没有帮助。经过彻底的调查,我们发现,简单地使用关系中定义的那些特征(详情参见附录)就可以获得高精度(约90%)。结构信息确实有所帮助,但获得的改进有限。


图15。通过改变目标网络中标记数据的百分比,预测有无基于地位、意见领袖和强/弱联系的转移的定向关系的性能。
基于社会地位、意见领袖和强/弱关系的转移。图15显示了对六个案例(Coauthor到Enron、MobileD到Enron、Enron到Coauthor 、MobileD到Coauthor 、Coauthor 到MobileD、Enron到MobileD)的直接关系的预测分析。在这里,我们重点测试基于社会地位、意见领袖和强关系的转移如何通过改变目标网络中标记关系的百分比来帮助预测关系的类型。几乎在所有情况下,TranFG模型都实现了一致的改进。唯一的例外是移动到合著者的情况,其中,当目标网络中的标记数据超过80%时,SVM在所有方法中工作得最好。可能有两个原因:第一个原因是移动网络小,限制了传输能力,第二个原因是目标网络中大比例的标记数据将为SVM学习一个好的分类模型提供统计上足够的数据。在所有其他情况下,基于社会理论的转移确实有所帮助。例如,当合著者网络中只有10%的标记顾问-被建议者关系,并且不考虑基于社会理论(地位、意见领袖和强/弱联系)的转移时,F1分数仅为30%。通过利用来自电子邮件网络(Enron)的基于地位和观点的领导转移,分数增加了一倍多(+60%)。随着从移动网络(MobileD)的转移,预测精度也显著提高(+50%)。此外,我们发现在不同比例的标记数据下,基于意见-领导的转移比基于社会地位的转移更有帮助,而基于意见-领导和社会地位的转移比基于强/弱关系的转移更有用。
9.4.主动学习性能
对于主动学习,在每个实验中,我们使用不同的主动学习算法在目标网络中选择一个比例τ的关系来查询它们的标签。我们将比例τ的范围从5%到50%,间隔为5%。在每一轮选择之后,我们应用所提出的TranFG模型来学习和预测目标网络中的关系类型。我们在每个数据集上进行了10次实验,并报告了平均F1分数。我们比较了以下主动学习算法:
—随机:随机选择目标网络中的关系进行查询。
—最大不确定性(MU):使用最大不确定性方法选择目标网络中最不确定的关系进行查询。
—最大代表度(MR):使用最大代表度方法选择目标网络中的关系进行查询。
—最大模型影响(MMI):它考虑与每个关系相关联的属性和网络信息,以主动选择目标网络中要查询的关系。
图2显示了不同算法在预测不同网络中的社会关系的四项任务中的主动学习性能。可以清楚地看到,主动学习算法显著提高了随机方法的性能。例如,对于预测从Epinions到Slashdot的社会联系,通过MMI策略的主动学习,仅使用目标网络中15%的标记关系(Slashdot)的性能已经接近使用目标网络中30%的标记关系的随机策略的性能。从结果也可以看出,网络信息确实有帮助。人机界面策略结合了与每个关系相关的属性和网络信息。平均而言,它比其他两种不考虑网络信息的策略(MU和MR)达到更好的性能(+2%)。
9.5.效率和可扩展性性能
我们首先评估所提出模型的学习算法的收敛性,然后测试其效率和可扩展性。

趋同分析。我们进行了一个关于循环信念传播迭代次数影响的实验。图16显示了学习算法的收敛性分析结果。我们在所有测试案例中看到,学习算法在不到100次迭代中收敛。在某些情况下(如Slashdot对MobileU和Coauthor对Enron),仅经过20次迭代,性能就变得稳定。这表明该学习算法是有效的,并且具有良好的收敛性。
效率。在不同的数据集上训练TranFG模型需要大约1到45分钟(例如,在Slashdot和Epinions网络上学习需要42分钟)。所提出的TranFG模型的效率是可以接受的,因为在大多数测试用例中训练TranFG模型可以在几分钟内完成。最耗时的情况是在Epinions网络上训练传输模型,该网络由131,828个节点和841,372个关系组成。模型学习仍然可以在不到1小时内完成。表六列出了在不同网络上培训TranFG模型时的效率表现。为了将社会平衡和社会地位纳入TranFG模型,我们需要计算源网络和目标网络中的所有三合会。我们设计了一个有效的算法,它在关系的数量上是线性的。该算法需要1到12分钟来枚举六个网络的所有三元组。该算法可在线获得。
可扩展性。图3显示了TranFG模型的分布式学习算法的可伸缩性。它给出了使用不同数量的计算机节点(2、4、6、8、10、12、14、16核)时分布式算法的运行时间和加速比。加速曲线接近开始时的完美线。虽然由于通信成本的原因,当内核数量增加时,加速比不可避免地会降低,但平均来说,它可以在12个内核的情况下实现9倍的加速比。请注意,加速性能取决于源网络和目标网络的结构。比如Slashdot到Epinions的加速性能比Coauthor到MobileD的加速性能好。这是因为加速性能取决于图形分区,而图形分区与网络结构密切相关。
我们进一步验证了分布式学习是否会损害预测精度。图17显示了分布式学习如何影响预测精度性能(F1分数)。我们看到,与单机上模型学习的性能(在图17中称为“完美”)相比,采用分布式学习的TranFG模型的性能仅略有下降。通过在16个内核上使用TranFG模型进行分布式学习,就F1分数而言,平均准确率仅下降0.8%。我们还通过将图随机划分为M个子图来评估分布式学习的性能。与我们通过METIS(根据最小割理论)分割图形的方法相比,随机策略导致预测精度下降(在16个内核上学习时下降约10%)。这证实了分布式学习设计的有效性。

10.相关工作
推断社会关系。推断社会关系是社会网络分析中的一个重要问题。李奔-诺埃尔等人[2007]提出了一种无监督的链接预测方法。他们研究了不同的算法,发现Katz算法可以达到最好的性能。向等人[2010]开发了一种潜在变量模型,以根据交互活动和用户相似性来估计关系强度。仰泳等人[2011]提出了一种有监督的随机行走算法来估计社会关系的强度。Leskovec等人[2010a]采用逻辑回归模型预测在线社交网络中的积极和消极关系。霍普克罗夫特等人[2011]研究了在动态网络中可以预测互惠关系形成的程度。然而,大多数现有的工作侧重于预测和推荐社交网络中的未知关系,而忽略了关系的类型。
有几部关于推断社会关系含义的著作。Diehl等人[2007]试图通过学习一个排序函数来识别经理-下属关系。王等人[2010]提出了一种无监督的概率模型,用于从出版网络中挖掘顾问-被顾问关系。克兰德尔等人[2010]研究了从时间和空间的共存中推断人与人之间友谊的问题。Eagle等人[2009]展示了在手机数据中发现的几种模式,并试图使用这些模式来推断友谊网络。然而,这些算法主要集中在特定的领域,而我们的模型是通用的,可以应用于不同的领域。更重要的是,我们的工作迈出了整合社会理论的第一步,以推断跨异构网络的社会联系。庄等人[2012]提出了一个在单个网络中推断社会关系的学习框架,并提出了一种主动学习方法。我们提出的主动学习算法与庄等人[2012]提出的相似。主要区别在于,我们在两个不同的网络中考虑这个问题,而庄等人[2012]在单个网络中考虑主动学习问题。在我们之前的工作[唐等2012]中,我们研究了跨异构网络推断社会联系的问题。在这项工作中,我们从以下几个方面进行扩展。首先,我们进一步研究强/弱联系假说如何影响不同类型社会的形成。其次,我们给出了基于社会理论的迁移特征的更详细的定义。第三,我们在一个新的数据集MobileD上评估所提出的模型,我们的目标是推断移动用户之间的管理者-下属关系。最后,我们提出并比较了在同构网络中推断社会关系的准确性和模型的效率。
链接预测。我们的工作与链接预测相关,链接预测是社交网络的核心任务之一。基于所采用的学习方法,现有的关于链路预测的工作可以大致分为两类:无监督链路预测和有监督链路预测。我们回顾了每个类别的代表性方法,并强调了现有工作和我们的努力之间的差异。无监督的链接预测通常根据直觉为潜在的链接分配分数,即一对中的用户越相似,他们链接的可能性就越大。考虑了用户的各种相似性度量,例如Adamic和Adar度量[Adamic和Adar 2001],优先附件[纽曼2001],和Katz度量[Katz 1953]。无监督链接预测的调查可以在李奔-诺埃尔和克莱因伯格[2007]中找到。这些工作大多使用一些宏观特征来研究链接预测任务,但是没有考虑社会效应,例如社会平衡效应。最近,Lichtenwalter等人[2010]设计了一种基于流的链路预测方法。也有一些使用监督方法来预测社交网络中的链接的工作,例如仰泳和莱斯科维奇[2011],董等人[2012],以及莱斯科维奇等人[2010a]。张等人[2013]研究了跨对齐异构社交网络的新用户的链接预测问题。董等人[2015]研究了耦合网络中的链路预测问题,其中一个(源)网络的结构信息以及该网络与另一个(目标)网络之间的相互作用是可用的,目标是预测目标网络中缺失的链路。
现有的关于链接预测的工作和我们的工作之间的主要区别在于,现有的工作主要集中在一个单一的网络上,而我们提出的模型将社会理论(如结构平衡、结构洞和社会地位)结合到一个迁移学习框架中,可以应用于不同的领域。
社会行为分析。另一类相关工作是社会行为分析。谭等人[2010]研究了社会行为如何在动态社会网络中演化,并提出了一个时变因子图模型来建模和预测用户的社会行为。唐和刘[2011]开发了一个框架,用于通过跨异构网络的学习来分类社会关系的类型。社会关系的类型是特定的,他们不考虑学习一个通用的模型来推断不同网络之间的社会关系。Yang等人[2010]研究了Twitter网络中的转发行为。用户之间的转发行为与社会关系密切相关。强烈的社会联系可能会导致更高的转发可能性。谭等人[2011]调查了用户之间不同类型的关系如何影响用户意见的变化。他们发现,通过整合社会关系,可以显著提高用户级情感分析的性能。张等[2015]提出了一种将不同网络连接在一起的方法COSNET,Yang等[2015]提出了一种从不同数据集寻找匹配实体的方法。董等[2015]试图推断用户在企业传播网络中的社会地位,研究富人“俱乐部”现象然而,所有这些工作都没有考虑推断跨多个不同网络的社会联系。另一个相关的研究课题是关系学习[Getoor和Taskar 2007]。关系学习关注的是当对象或实体以关系的形式出现时的分类问题。还开发了许多用于关系数据中链接预测的监督方法[Taskar等人,2003]。在本文中,我们将关系学习问题扩展到迁移学习情境,并利用社会理论来加强关系学习。
迁移学习。我们的工作也与迁移学习有关,它旨在将知识从一个源域转移到一个相关的目标域。迁移学习中的两个主要问题是“迁移什么”和“什么时候迁移”[潘和李安2010]。通过从源域中选择实例以便在目标域中重用,已经提出了许多方法[戴等人,2007b高等2008;廖等,2005;石等[2008]。还进行了许多工作来在不同的域之间传递特征。例如,Argyriou和Evgeniu[2006]提出了一种为多个相关任务学习共享低维表示的方法。布利泽等人[2006]提出了一种结构对应学习(SCL)方法来诱导两个领域之间的特征对应。其他作品有曹等[2010],耶巴拉[2004],李等[2007],安藤和张[2005]。有一些关于跨异构特征空间传递知识的工作[凌等2008]。例如,戴等人[2008]提出了翻译学习,它可以跨两个完全不同的领域传递标记信息。Argyriou等人[2008]提出了一种在外部环境中解决分类问题的算法。与现有作品相比,这部作品在以下几个方面有所不同。首先,大多数现有的工作只考虑同构网络(源网络和目标网络是同一类型的),而我们问题中研究的网络却有很大的不同,它们甚至可能没有任何重叠的属性特征。第二,我们将基于社会理论的特征结合到迁移学习框架中,而现有的方法主要关注如何找到不同领域的共享属性。
讨论。总的来说,本文所解决的问题不同于传统的推断社会关系和链接预测的研究。主要区别在于,我们研究的是跨不同网络的链路预测问题。我们在这一领域的另一个更重要的贡献是,我们系统地研究了各种社会理论(例如,社会平衡、社会地位、结构洞、两步流动和强/弱联系),并设计了一种有原则的方法来将这些社会理论结合到一个概率图形模型中。从该方法的角度来看,所提出的解决方案与概率图模型和迁移学习有关。所提出的框架TranFG本身是基于因子图模型开发的[Kschischang等人,2001],学习算法是基于部分标记因子图的算法[Tang等人,2011]。我们的贡献是扩展这个模型来处理传输链路预测问题。根本的挑战是,没有共同的特征可以用来将知识从源网络转移到目标网络,这使得直接将现有的转移学习方法应用于该任务是不可行的。TranFG通过利用不同网络的共同属性(基于所研究的社会理论),提供了一种连接两个不同网络的优雅方式。学习框架是为了保证一个公共财产被信任来传递知识的可能性有多大。据我们所知,这是第一次尝试使用社会理论研究跨异构网络的传输链路预测问题。
11.结论和未来工作
在本文中,我们研究了跨异构网络推断社会关系类型的问题。更准确地说,我们研究如何通过利用来自源网络的信息,在只有少量标记关系的目标网络中准确推断社会关系。我们将问题公式化,并提出一个基于转移的因子图模型。该模型将社会理论融入半监督学习框架,用于从源网络传递监督信息,以帮助推断目标网络中的社会联系。为了进一步改进所提出的模型,我们提出了几种主动学习算法和一种分布式学习算法。我们在六个不同的网络上评估了所提出的模型。我们表明,与几种替代方法相比,所提出的模型可以显著提高跨不同网络推断社会关系的性能。通过主动学习,我们可以进一步获得准确性性能的显著提高。模型的学习算法也可以很容易地分配。例如,通过分布式学习,我们可以获得12个内核的9倍加速。通过对六种不同类型网络的观察分析,我们的研究还揭示了几个有趣的现象。
该框架有许多潜在的应用。例如,最近我们应用该框架帮助两家公司从移动数据和银行交易数据中挖掘社会关系。从移动数据中,我们试图推断家庭和同事关系,这可以帮助移动公司推荐个性化服务。从银行交易数据中,我们试图推断两个银行账户之间的关系类型。这对帮助银行寻找新客户非常有用。到目前为止,获得的结果是很有希望的。
推断社会关系的一般问题代表了社会网络分析中一个有趣的研究方向。这项工作有许多潜在的未来方向。首先,其他一些社会理论可以进一步探索和验证,以分析不同类型的社会关系的形成。接下来,有意思的是进一步研究如何增量学习所提出的模型,以便我们可以在学习过程中直接涉及在线用户交互。另一个潜在的问题是利用推断社会关系的结果来帮助处理信息过载的问题。例如,在Facebook或Twitter上,我们可能会关注成千上万的朋友,但坦率地说,我们无法维护所有的朋友。谁在我们的核心圈子里?基于这项工作的结果,我们可以进一步研究如何为每个社交用户识别核心圈子。它也有许多基于社会关系分析结果的实际应用。例如,我们可以使用推断的社会联系来帮助社会网络中的信息推荐。根据社会影响理论,用户与不同社会关系的联系会从不同方面对他或她的行为产生非常不同的影响。




















 3802
3802











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









