







原文链接:http://blog.csdn.net/qq403977698/article/details/50433273
简介
Storm有4个调度器(defaultScheduler/IsolationScheduler/MultitenantScheduler/RAS),Jstorm只有一个调度器,但是其拥有4种模式(defaultScheduler/IsolationScheduler/User-defined Scheduler/The last Scheduler),JStorm的调度模式需要在用ConfigExtension进行配置。
默认调度算法(Default scheduler algorithm)
Jstorm的default scheduler不仅仅像Storm那样实现了随机的资源分配,更考虑了稳定性,资源利用以及性能。
1.稳定性
均匀的将每个组件(spout/bolt)的线程(并行度)分配到集群中的各个节点。Jstorm会尽可能的将同一个组件的线程分配到不同的节点及worker上以减少同质竞争(同一个组件线程做的是一样的事情,比如可能都是cup密集型,那么放到不同节点就能提供效率,更好的利用资源)。
举个例子,一个集群有三个节点,node-A有3个worker,node-B有2个worker,node-C有一个worker。当用户提交一个topology(该topology需要4个worker,1个spout(X),一个bolt(Y),spout/bolt各占2个进程)。初始时:在Storm与Jstorm是一样的。
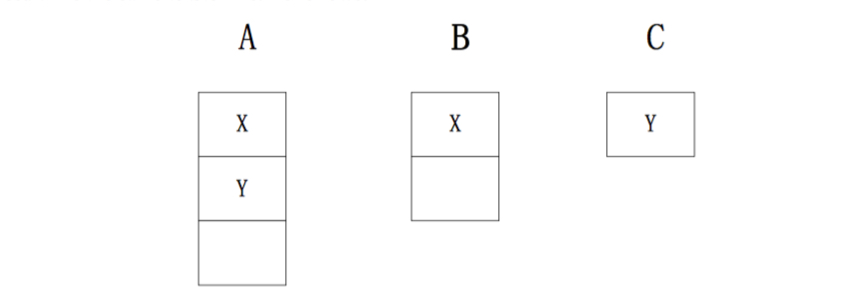
这时,如果node-C挂掉了,那么node-C中的worker必须要重写分配。如果是Storm的默认分配记过如下:
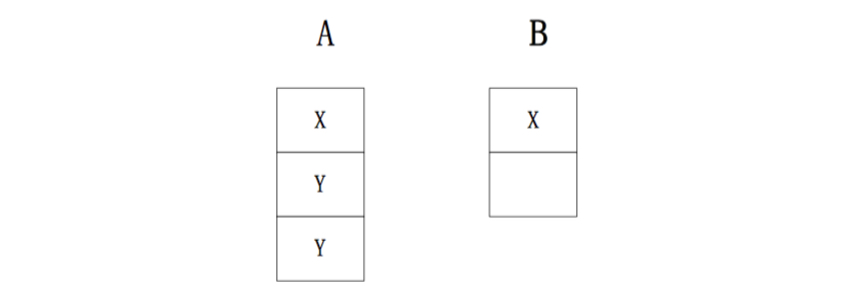
如果是Jstorm的默认调度来进行分配的化,结果如下:
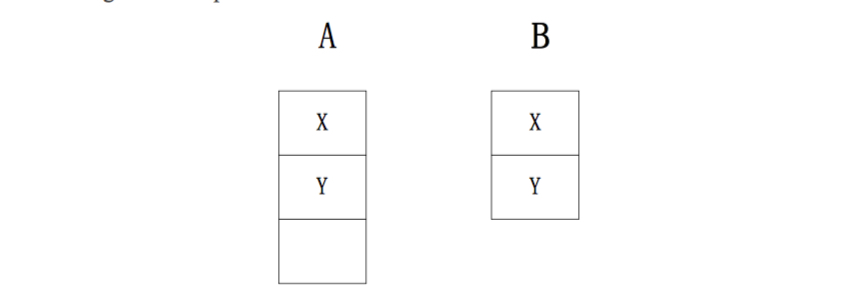
显然,JStorm的默认调度算法比Storm的更加优秀。
2.负载均衡
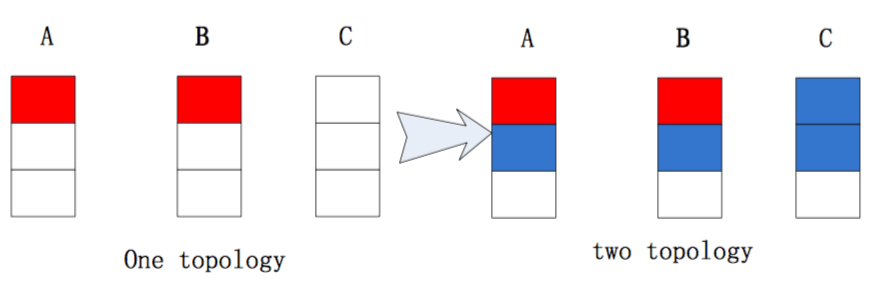
Jstorm尽量保证每个worker所分得的线程数基本一致,并且worker在各个supervisors之间也尽量分配的均匀。例如,一个集群有3个节点,node-A有3个worker,noder-B有3个woker,node-C与3个woker。用户先提交了一个需要2个woker的topology,然后,又提交了一个需要4个worker的topology。
如果是Storm的默认调度算法来分配这两个topology,结果如下:
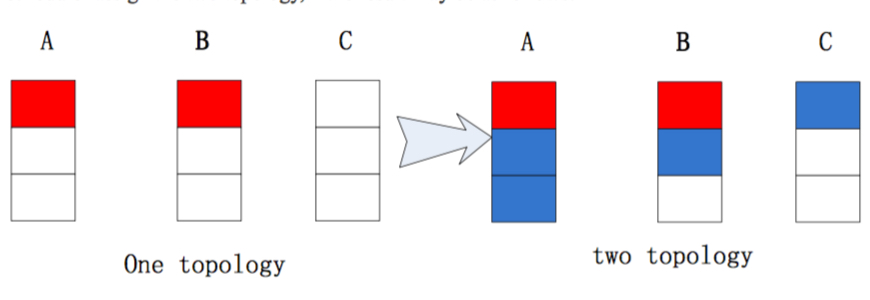
显然可以看出,这个分配是不均匀的。。而Jstorm的默认分配就能得到一个均匀的结果:
3.性能
Jstorm会试图将两个需要通讯的线程尽量放在一个worker中来减少网络的传输。例如:一个集群中有2个节点,node-A有2个worker,node-B有2个worker。当用户提交一个topology(需要2个worker,1个spout(X),2个bolt(Y、Z),三个组件各一个线程)。整个topology的数据流为X->Y->Z。如果Storm的默认调度算法来分配,可能的结果为:
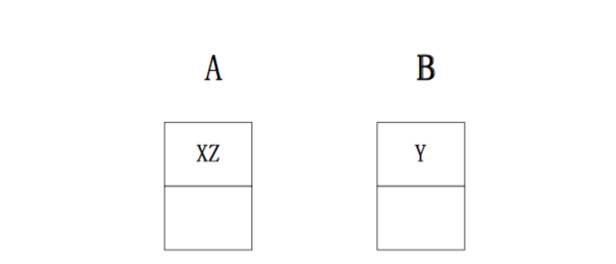
显然中间需要网络间传输,而JStorm的分配就能避免这个问题:
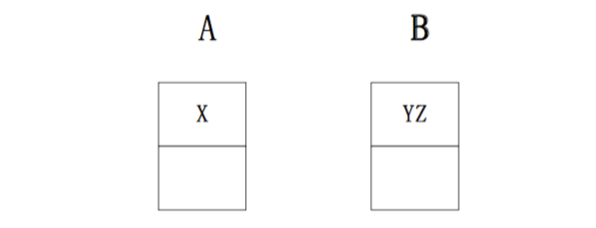
这里Y与Z的通讯是进程间通讯。在进程间通讯,消息不需要序列与反序列化。这样会极大的提高效率。
想要(稳定性/性能/平衡)都同时满足是很困难的。Jstorm对于重要性排序是:稳定性>性能>负债均衡。
高级特性
JStorm具有一些高级特性,我们可以通过配置topology来使用这些功能。
1.IsolationScheduler
与Storm一样,JStorm也有IsolationScheduler。在storm中用户可以配置Nimbus来隔离特定的topology,决定分配多少机器给这些隔离的topology,配置项为Nimbus上的storm.yaml文件中的isolation.scheduler.machines。在隔离的topology分配好之后,那些没有被隔离的就使用剩下的机器。由于Jstorm将IsolationScheduler整合进了DefaultScheduler中,所以,在Jstorm中,我们需要在topology中进行配置,而不是在storm.yaml中。
2.User-defined Assignment Scheduler
顾名思义,用户通过这个可以自己定义分配方式。下面来看看一些需要自己定义分配方式的场景:
a.将Spout与bolt放到一个worker中来达到替代DRPC的目的
spoutA->bolt1->bolt2->resultbolt
我们可以把spoutA与resultbolt放到一个woker中,这样resultbolt的结果就能直接返回给spoutA。
b.将上下游的组件放在一起,避免网络传输。
c.强制将一个组件运行分配到一个特定的机器上。
例如,我们可以将一个操作数据库的组件强制分配到数据库所在的机器上,或者,将需要读kafka数据的组件放到kafka所在的机器上。
d.强制一个组件的不同线程运行在不同的机器中。
当然,用户也可以选择只对部分worker与线程进行自定义分配,那么其他还是使用默认的分配方式。
3.The Last Assignment Scheduler
为什么会有这么个奇怪的分配方式呢,这个分配就是很简单的,与上一次用一样的分布方式。
假设,你上了一个topology,然后,过了一段时间,你re-submit/restart这个topology,这时,如果与上次的分配方式不一样,topology上一次运行在各个节点留下的数据就没用了,而如果采用与上一次一样的分配方式,那么这些数据就能够得到重用。
当然,如果出现一个节点挂了,那么这个节点的woker的重新分配就是默认的分配方式了。















 3002
3002

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









