







本文转载自:http://blog.csdn.net/baiwfg2/article/details/38701495 尊重原创
以前碰到过文件编码问题,但都没太在意。最近在win7下写一个C++程序时,转移到linux下表现怪异,调试个半天发现竟然是文件编码问题!于是想花点时间好好总结一下关于文件编码格式的基本概念。这东西长时间没搞就容易忘,这也方便以后再来查询。
首先,关于字符编码的基本概念可以参考百度百科:http://baike.baidu.com/view/1204863.htm?fr=aladdin,当然我不清楚有多少正确性,不过我还是稍微总结了一些,最后再添加一个我自己的示例,若有误请见谅!
ASCII
ASCII码于1961年提出,用于在不同计算机硬件和软件系统中实现数据传输标准化,在大多数的小型机和全部的个人计算机都使用此码。ASCII码划分为两个集合:128个字符的标准ASCII码和附加的128个字符的扩展ASCII码。标准ASCII码为7位,扩展为8位。扩展的8位码官方标准叫:ISO-8859-1,也叫Latin-1编码。
ANSI(MBCS)
为了扩充ASCII编码,以用于显示本国的语言,不同的国家和地区制定了不同的标准,由此产生了 GB2312, BIG5, JIS 等各自的编码标准。这些使用2个字节来代表一个字符的各种汉字延伸编码方式,称为ANSI编码,又称为”MBCS(Multi-Bytes Character Set,多字节字符集)”。在简体中文系统下,ANSI编码代表GB2312编码,在日文操作系统下,ANSI 编码代表 JIS 编码,所以在中文 windows下要转码成gb2312,gbk只需要把文本保存为ANSI编码即可。不同ANSI编码之间互不兼容,导致了unicode码的诞生。
我国的编码
GB2312,1980年颁布,有区码、位码、存储码之分
GBK,兼容GB2312,添加了繁体字
GB18030,增加了更多字符
BIG5,台湾、香港地区使用,也叫大五码
UNICODE
统一了全世界的所有字符,可分为UCS-2(对应UTF-16)和UCS-4(对应UTF-32),有大小端之分,如”A”的Unicode编码为6500,而BigEndian Unicode编码为0065,编码效率不高
UTF
为了提高UNICODE编码效率,就出现了UTF码,变长字节。UTF-8兼容ASCII,UTF-16不兼容ASCII。
UCS-2与UTF-8字节流之间的对应
UCS-2编码(16进制) UTF-8 字节流(二进制)
0000 - 007F 0xxxxxxx
0080 - 07FF 110xxxxx10xxxxxx
0800 - FFFF 1110xxxx10xxxxxx 10xxxxxx
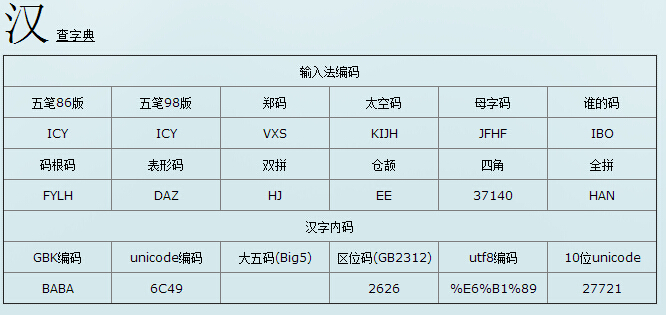
例如“汉”字的Unicode编码是6C49。6C49在0800-FFFF之间,所以肯定要用3字节模板了:1110xxxx10xxxxxx 10xxxxxx。将6C49写成二进制是:0110 110001 001001,用这个比特流依次代替模板中的x,得到:11100110 10110001 10001001,即E6 B1 89。可见UTF-8是变长的,将Unicode编码为0000-0007F的字符,用单个字节来表示; 0080-007FF的字符用两个字节表示;0800-FFFF的字符用3字节表示。因为目前为止Unicode-16规范没有指定FFFF以上的字符,所以UTF-8最多是使用3个字节来表示一个字符。
字节序
UTF-8以字节为编码单元,没有字节序的问题。UTF-16以两个字节为编码单元,在解释一个UTF-16文本前,首先要弄清楚每个编码单元的字节序。例如收到一个“奎”的Unicode编码是594E,“乙”的Unicode编码是4E59。如果我们收到UTF-16字节流“594E”,那么这是“奎”还是“乙”?
Unicode规范中推荐的标记字节顺序的方法是BOM。BOM不是“Bill Of Material”的BOM表,而是Byte Order Mark。BOM是一个有点小聪明的想法:
在UCS编码中有一个叫做”ZERO WIDTH NO-BREAK SPACE“的字符,它的编码是FEFF。而FFFE在UCS中是不存在的字符,所以不应该出现在实际传输中。UCS规范建议我们在传输字节流前,先传输字符”ZERO WIDTH NO-BREAK SPACE”。
这样如果接收者收到FEFF,就表明这个字节流是Big-Endian的;如果收到FFFE,就表明这个字节流是Little-Endian的。因此字符”ZEROWIDTH NO-BREAK SPACE”又被称作BOM。
UTF-8不需要BOM来表明字节顺序,但可以用BOM来表明编码方式。字符”ZERO WIDTH NO-BREAK SPACE”的UTF-8编码是EF BB BF。所以如果接收者收到以EF BB BF开头的字节流,就知道这是UTF-8编码了。
不同的系统对BOM的支持
因为一些系统或程序不支持BOM,因此带有BOM的Unicode文件有时会带来一些问题。
- 1、JDK1.5以及之前的Reader都不能处理带有BOM的UTF-8编码的文件,解析这种格式的xml文件时,会抛出异常:Content is not allowed in prolog。
- 2、Linux/UNIX 并没有使用 BOM,因为它会破坏现有的 ASCII 文件的语法约定。
- 3、不同的编辑工具对BOM的处理也各不相同。使用Windows自带的记事本将文件保存为UTF-8编码的时候,记事本会自动在文件开头插入BOM(虽然BOM对UTF-8来说并不是必须的)。而其它很多编辑器用不用BOM是可以选择的。UTF-8、UTF-16都是如此。
-
软件如何决定文本的字符集与编码
(1)对于Unicode文本最标准的途径是检测文本最开头的几个字节。如:
开头字节 Charset/encoding EF BB BF UTF-8 FE FF UTF-16/UCS-2,big endian(UTF-16BE) FF FE UTF-16/UCS-2,little endian(UTF-16LE) FF FE 00 00 UTF-32/UCS-4,little endian. 00 00 FE FF UTF-32/UCS-4,big-endian(2)弹出一个对话框来请示用户。
然而MBCS文本(ANSI)没有这些位于开头的字符集标记,现在很多软件保存文本为Unicode时,可以选择是否保存这些位于开头的字符集标记。因此,软件不应该依赖于这种途径。这时,软件可以采取一种比较安全的方式来决定字符集及其编码,那就是弹出一个对话框来请示用户。
(3)采取自己“猜”的方法。
如果软件不想麻烦用户,或者它不方便向用户请示,那它只能采取自己“猜”的方法,软件可以根据整个文本的特征来猜测它可能属于哪个charset,这就很可能不准了。使用记事本打开那个“联通”文件就属于这种情况。(把原本属于ANSI编码的文件当成UTF-8处理,详细说明见:http://blog.csdn.net/omohe/archive/2007/05/29/1630186.aspx)win7平台测试示例
win7下创建一个文件tmp.txt,内容为:
a
汉
即一个ascii字符,一换行,再加一中文字符。
我们知道在中文windows系统中,默认ANSI即为GB系列的字符集,不妨将tmp.txt更名为tmp-ansi.txt。那怎么查呢?可用Emeditor打开它,在窗口右下角即可见所属字符集,如下图:很明显是GB2312字符集。那怎样看具体的编码呢?有几种方式:
1、进入网站http://bianma.supfree.net/,输入汉字即可得,如下图:
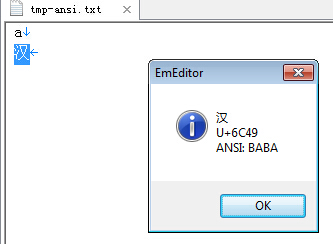
2、单击Emeditor菜单View→Character Code Value,即可显示,同时还显示了unicode编码,如下图:
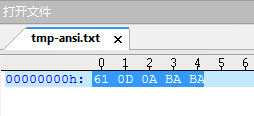
3、用ultraedit打开,快捷键ctrl+h,即可显示文件内容编码为:61 0D 0A BA BA,如下图:
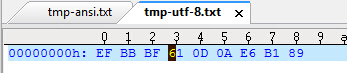
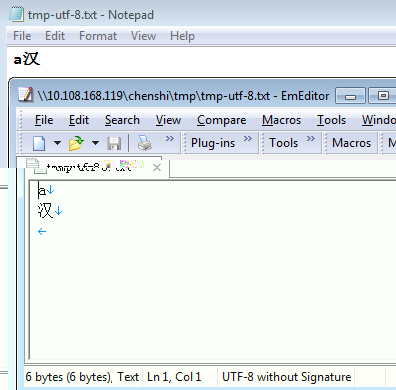
同理,当我们将tmp-ansi.txt用记事本另存为其它格式时(当然用Emeditor另存为的可选格式更多),也可用上述方式得到验证其unicode编码为:6C49,UTF-8编码为:E6 B1 89,如下图验证tmp-utf-8.txt(由记事本生成,默认带有BOM):
即带有签名的BOM:EF BB BF; ‘a’:61; CRLF:0D 0A; ‘汉’:E6 B1 89
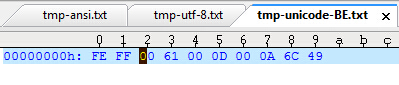
再来看另存为unicode big endian的情况:果然字节数多了!其BOM:FE FF; 接下来的每个字符为2个字节。当然若是小端的话,其BOM就是FF FE了
Linux平台测试示例
同理在Linux测试也差不多,只不过软件没了,用命令可看。创建文件tmp-utf-8,同样输入:a+换行+汉,执行命令:
od -x tmp-utf-8
将上述字节每两个反过来,即得:61 0a e6 b1 89 0a,不就是那utf-8编码吗,后面多了个换行 0a,不过我记得我没有加第二个换行,不知道为什么也有了
将上面文件tmp-utf-8转移到win7平台(方便起见,添加了扩展名.txt),分别用记事本和emeditor打开,如下图:
可见总共6个字节,在记事本中只有换行没有回车,emeditor显示为utf-8,无BOM。另外可知此文件并没有BOM,记事本为何还可以正确显示?说明记事本很可能采取了上面所说的”猜“的方法,猜出用utf-8方式来显示文件而非gbk方式
我们再进一步测试:将上述win7的tmp-ansi.txt,tmp-utf-8.txt,tmp-unicode-BE.txt转移到Linux下,观察其反应,结果发现用vim打开tmp-ansi.txt时,’汉’为乱码,vim解释为latin1,且用:set fileencoding=utf-8之后,也并不能修复,拿到win7下同样显示不正常; 当用vim打开tmp-unicode-BE.txt时,显示正常,fileencoding为utf-16; 当打开tmp-utf-8.txt时,显示正常,编码为utf-8。下图为显示不正常时的情况:
我想我那怪异的C++问题就是这样造成的,导致tinyxml解析混乱。
若此时我将tmp-ansi.txt再还原成latin1编码,虽在Linux上乱码,但在win7上还是会被解释成GB2312的。这也可理解,因为多字节为单元的字符解释成多个单一字节,并不会造成字节丢失,然后在合适的系统上就可正常显示。然而,GB2312编码并不与UTF-8兼容,所以哪怕转为UTF-8,也是乱码。可见要想跨平台,还得两边都得用UTF-8!


















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









