










后缀是什么
然而如果单从字符串构造来讲任何
S[i…len[S]]⊂S(1⩽i⩽len[S])
S
[
i
…
l
e
n
[
S
]
]
⊂
S
(
1
⩽
i
⩽
l
e
n
[
S
]
)
均为字符串
S
S
的后缀。
后缀树
1 从Trie到后缀树的变化
在WikiEn上后缀树的定义如下Suffix Tree.
In computer science, a suffix tree (also called PAT tree or, in an earlier form, position tree) is a compressed trie containing all the suffixes of the given text as their keys and positions in the text as their values.
对串
S
S
的所有后缀进行树构造,例如”bananas”,就会得到下面的
Suffix Trie
Suffix Trie
.
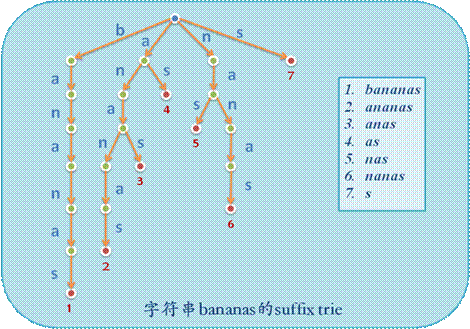
对
Suffix Trie
Suffix Trie
压缩就得到了
Suffix Compressed Trie
Suffix Compressed Trie
.

这正是我们所定义的后缀树(
Suffix Tree
Suffix Tree
).
关于
Trie
Trie
树的应用,最优秀的表现就是在该树上进行的”KMP算法”,即ac自动机,一句话概括应该就是多字符串统计问题。
Trie
Trie
树的思想虽然简单却实用,有了它我们就可以设计很多关于字符串的算法。
从
Trie
Trie
到后缀树,亦是利用
Trie
Trie
对多字符串统计的性质完成对单个字符串的全面掌握——后缀树对单个字符串的所有后缀(包括该字符串本身自然是一个特殊的后缀,空字符串
ϵ
ϵ
(这里以
$
$
符号表示)也是一个特殊的后缀)。后缀树自然可以对所有的后缀进行暴力建树,但这就失去了对“该
Trie
Trie
上所有字符串都是同一个字符串的后缀”的信息的利用,利用上了这个信息后缀树才从
Trie
Trie
上脱胎换骨成为一种全新的数据结构。
§ § 2 后缀树构造法
作为字符串处理中具有重要地位的数据结构——后缀树,自然不会少有人参与其中的研究。
Ukkonen
Ukkonen
提出了完全基于内存的后缀树的线性构造,而这是我们今天讲述后缀树构造方法的主角,因为我们还是只是初涉这种数据结构而已_(:3」∠)_其他的方法可以是基于外存的,也可以是并行的,具体可以查看参考资料的第三个链接。
现在开始介绍
Ukkonen
Ukkonen
算法。
1.Ukkonen算法的特点
(1)时间复杂度
O(len[S])
O
(
l
e
n
[
S
]
)
,空间复杂度
O(len[S])
O
(
l
e
n
[
S
]
)
;
(2)在线算法,分步构造,即
T0=∅
T
0
=
∅
,且
Ti+1=A(Ti),A
T
i
+
1
=
A
(
T
i
)
,
A
是算法构造,
Ti
T
i
是在线构造下的隐式后缀树;
(3)隐式构造,即部分后缀会因为成为某些后缀的前缀而被隐藏起来(显式构造是通过增加一个新的字典字符,使所有后缀的包含性被破坏从而每一个后缀以叶节点结尾)。
2.Ukkonen算法的核心
设已有后缀树为
Ti
T
i
,
β
β
是
Ti
T
i
下可表示后缀.
运行法则1(隐式构造)β结束于叶子节点v:
运行法则1(隐式构造)
β
结
束
于
叶
子
节
点
v
:
那么更新的时候只需要把
v
v
的连边由更新为
(id(v),S[i+1])
(
i
d
(
v
)
,
S
[
i
+
1
]
)
运行法则2(分裂规则)β结束非终点路径,且β结束的位置不存在S[i+1]:
运行法则2(分裂规则)
β
结
束
非
终
点
路
径
,
且
β
结
束
的
位
置
不
存
在
S
[
i
+
1
]
:
那么更新的时候新建节点
v(i)
v
(
i
)
作为中继,并在其下面添加
v(i+1)
v
(
i
+
1
)
,给路径赋权
S[i+1]
S
[
i
+
1
]
。
运行法则3(懒惰规则)β结束非终点路径,且β结束的位置存在S[i+1]:
运行法则3(懒惰规则)
β
结
束
非
终
点
路
径
,
且
β
结
束
的
位
置
存
在
S
[
i
+
1
]
:
这时候我们什么都不做。
3.Ukkonen算法实现
我在这里并不打算做 Ukkonen Ukkonen 算法的解释,因为在后缀树一文中,其已经对后缀树构造做了图文并茂的阐述(虽然有人指出了这篇文章中有错误产生,推荐先看,然后倒回来看后缀树)!所以,读完他的博文以后,你可以再到回来看 Ukkonen Ukkonen 算法的具体实现(该算法来自于SPOJ LCS 最长公共子串 后缀自动机&后缀树(Ukkonen),我凭自己的理解做了注释(不好掌握啊…好在我们会更进一步掌握后缀数组和后缀自动机,后缀树只是辅助理解))。
struct Node
{
//new_node
static Node buf[],*bufp;
void *operator new(size_t){return bufp++;}
//suffixLink:后缀链接,ch:孩子指针
Node *suffixLink,*ch[28];
//l:左节点,r:右节点,len:边长
int l,r,len;
Node(){}
Node(int _l,int _r,int _len)
{
l=_l;r=_r;len=_len;
memset(ch,0,sizeof(ch));
}
}
//手写new
Node::buf[N<<2],*Node::bufp=buf,
*root,
//假的root后缀链接结点,活跃结点,剩余后缀数/活跃后缀长度
*rootSuffix,*active_node;int active_length=0;
char a[N*4];
//插入S[pos]=c
void insert(int pos,char c)
{
Node *curNode,*last=nullptr,*next;
int x=c-'a';
for(;;)
{
while(
//有子结点
(curNode=active_node->ch[a[pos-active_length]-'a'])&&
//active_length长于当前边
active_length>=curNode->r-curNode->l)
{
//在新结点上进行操作
active_length-=curNode->r-curNode->l;
active_node=curNode;
}
//隐式构造
if(active_node==rootSuffix||(curNode&&a[curNode->l+active_length]==c))
{
//如果存在本次insert新构造的结点则进行后缀链接
if(last)last->suffixLink=active_node;
//隐式插入后缀增长了
++active_length;
return ;
}
//分裂规则,因为由前面return短路的性质,这里隐含地包含了分裂规则所满足的情况
if(active_length)
{
//分裂出子结点
next=new Node(curNode->l,curNode->l+active_length,active_node->len+active_length);
curNode->l+=active_length;
next->ch[a[curNode->l]-'a']=curNode;
active_node->ch[a[next->l]-'a']=next;
//懒惰规则,由if的判断,当前是无活跃后缀的
}else next=active_node;
next->ch[x]=new Node(pos,INTMAX,0);
//如果存在本次insert新构造的节点则进行后缀链接
if(last)last->suffixLink=next;
last=next;
//沿着后缀链接更新
active_node=active_node->suffixLink;
}
}§ § 3后缀树的应用
先暂时列举,有时候可以回来把具体实现做了。
1.
S串对T的模式匹配(一次匹配所有T的个数);
S
串
对
T
的
模
式
匹
配
(
一
次
匹
配
所
有
T
的
个
数
)
;
2.
求S串的最长重复子串;
求
S
串
的
最
长
重
复
子
串
;
3.
两串S,T最长公共子串;
两
串
S
,
T
最
长
公
共
子
串
;
4.
单串S最长回文子串。
单
串
S
最
长
回
文
子
串
。
参考:
[0]Suffix tree - Wikipedia
[1]从Trie树(字典树)谈到后缀树
[2]后缀树
[3]离散数据集的后缀树构造方法
[4]On-line construction of suffix tree,Ukkonen
[5]后缀树构造方法讲义
[6]Ukkonen后缀树算法的真·清晰解释
[7]SPOJ LCS 最长公共子串 后缀自动机&后缀树(Ukkonen)
[8](论文主要内容翻译)后缀树的构造与实现–Ukkonen Algorithm














 5346
5346











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









