








原文连接:https://mp.weixin.qq.com/s/vpAhZg8FEZJde4FreX-I_A
可通过原文获取论文电子资源。
文章目录
内容组织结构
Index Terms—Generative modeling, 3D representations, deep learning, unsupervised learning, 3D vision.
3 FUNDAMENTALS
3.1 Deep Generative Models
generative models can be divided into two main categories:
likelihood-based models :
- variational autoencoders (VAEs) [16],
- normalizing flows (N-Flows) [24],
- diffusion models (DDPMs) [17]
- energy-based models (EBMs) [48]
which are learned by maximizing the likelihood of the given data。
likelihood-free models:
- Generative Adversarial Networks (GANs) [15]
which are built on a two-player minmax game to find nash equilibrium. In the following
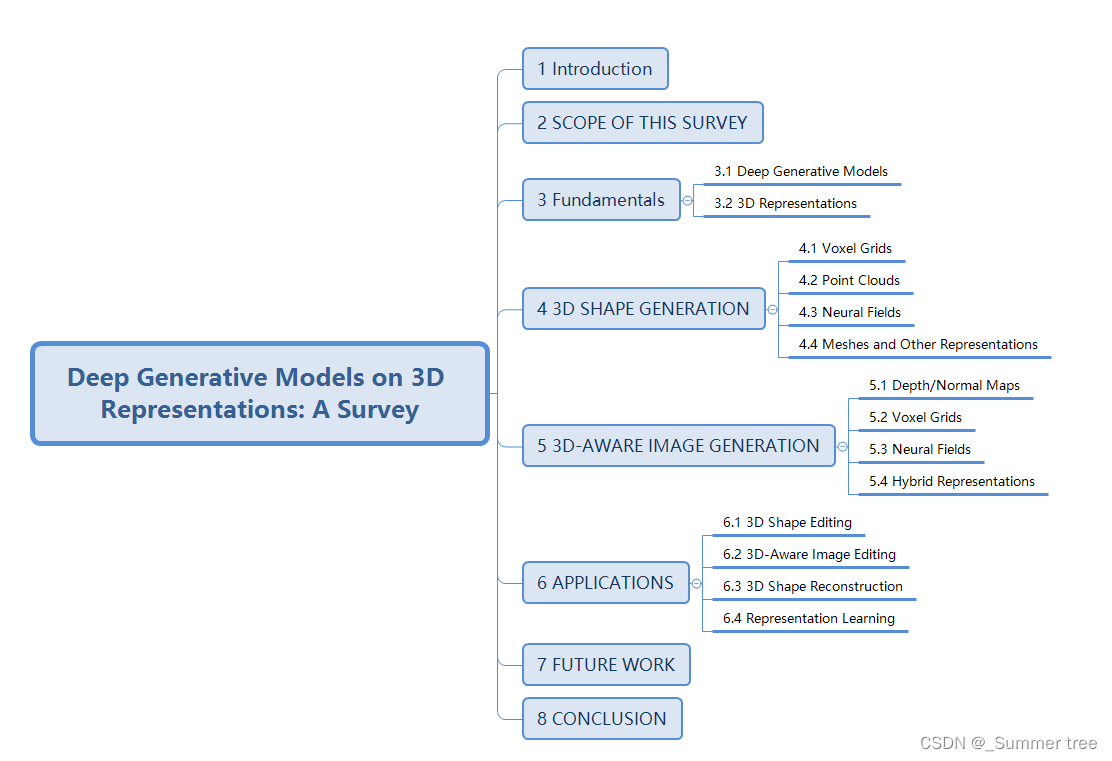
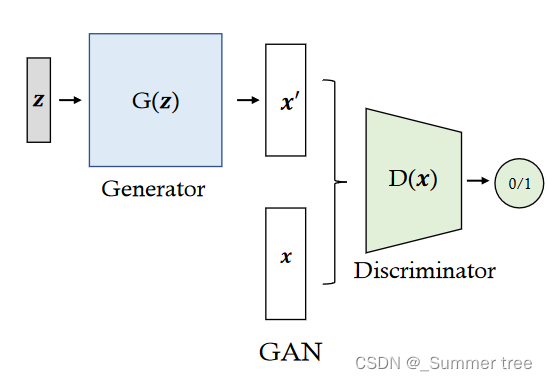
Generative Adversarial Networks.
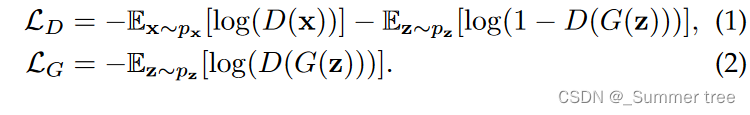
Variational Autoencoders
KL散度:
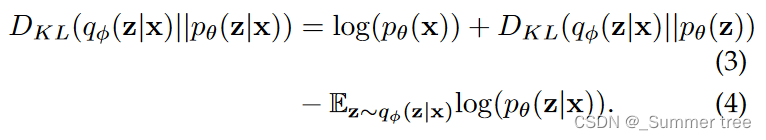
对数似然:
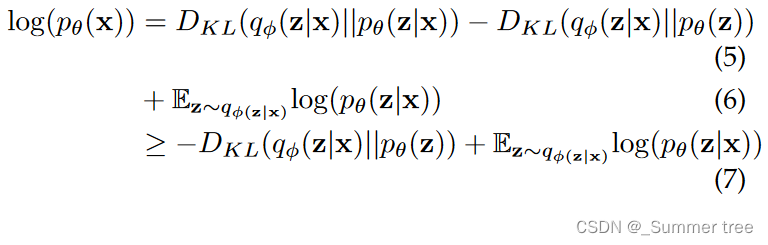
VAE loss:
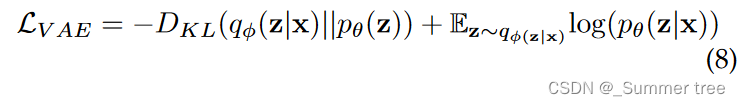
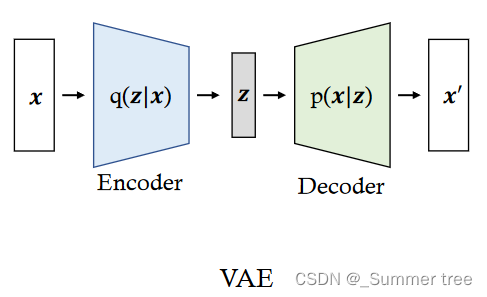
VAEs also suffer from the posterior collapse, where the learned latent space becomes uninformative to reconstruct the given data. Because of the injected noise and imperfect reconstruction, VAEs are more likely to synthesize much more blur samples than those coming from GANs.
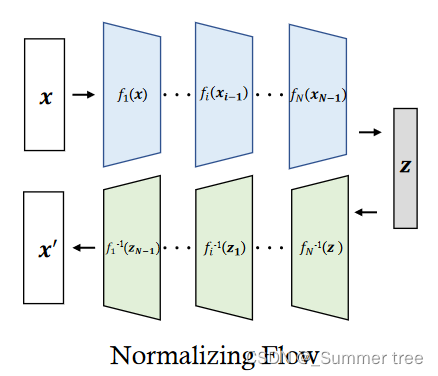
Normalizing Flows.
final output:
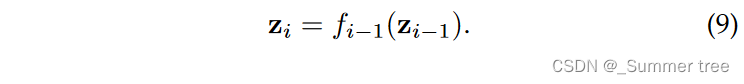
probability density function of the new variable zi:
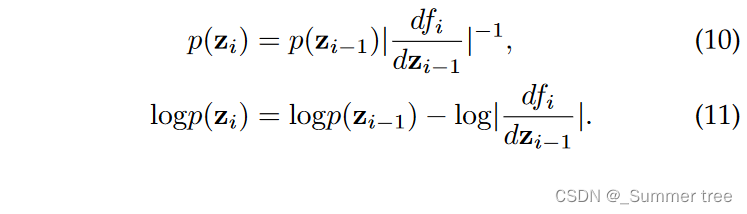
the density of final output zN after N transformations can be obtained by the following:
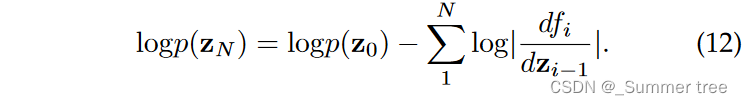
Diffusion Models
Diffusion models [17] is parameterized by a Markov chain, which gradually adds noise to the input data x0 by a noise schedule β1:T where T denotes the time steps. Theoretically, when T → ∞, xT is a normal Gaussian distribution.
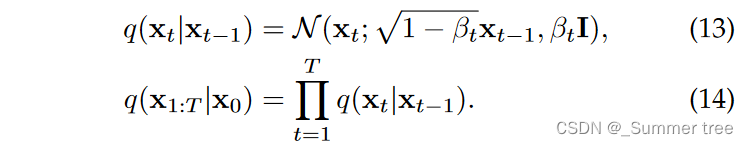
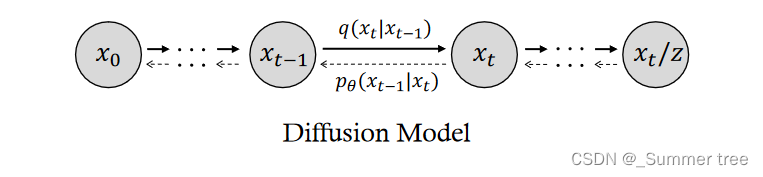
Because of the intractable long Makov chain, diffusion can synthesize high-quality data and is trained in a stable manner. However, it is expensive to infer new samples, and the sampling process is slower than GANs and VAEs.
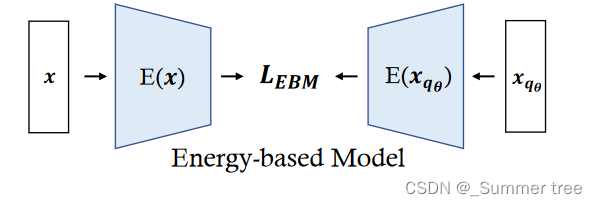
Energy-based model.
Energy-based models leverages the energy function to explicitly model the probability distribution of data. It is built upon a fundemental idea that any probability function can be transformed from a energy function by dividing its volume:
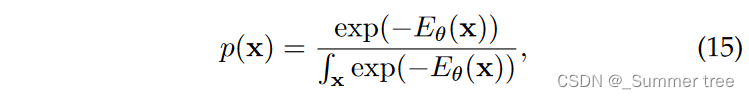
Obviously, data points with high likelihood have a low energy, while data points with low likelihood have a high energy.
Contrastive divergence is proposed to alleviate the optimization difficulty by compare the likelihood gradient on p(x) and randomly sampled data of energy distribution qθ (x):
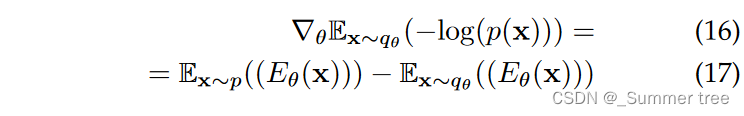
The energy distribution qθ(x) is approximated by Markov Chain Monte Carlo (MCMC) process.
3.2 3D Representations
An overview of 3D representations is available in Fig. 2.
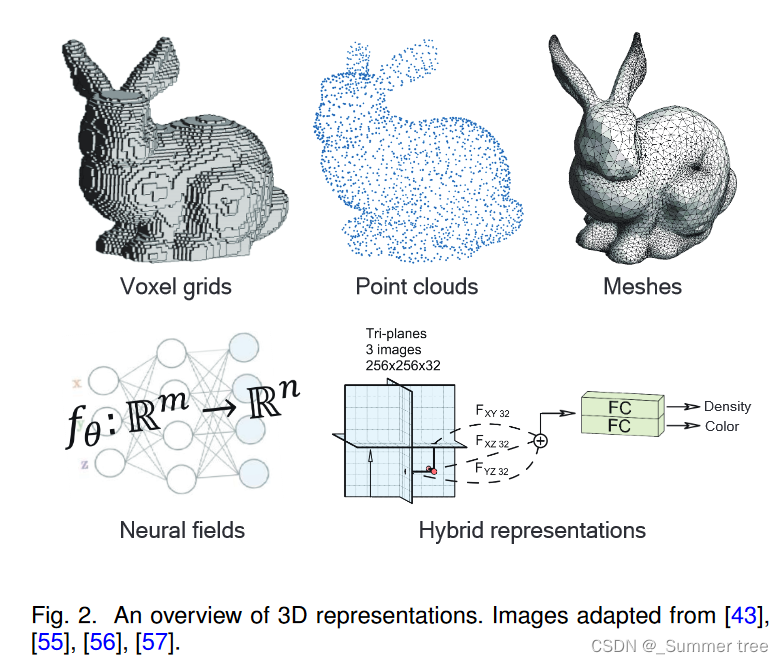
Voxel grids
Voxels are Euclidean-structured data that are regularly placed in 3D space, which is similar to pixels in 2D space. To represent 3D shapes, voxels can store the geometry occupancies [35], [36], volume densities [58], [59], or signed distance values [60].
voxel grids are often used as the network output in the task of 3D reconstruction [61].
Voxel grids also have many applications in rendering tasks.
Multi-plane image (MPI) [37] can be seen as a type of voxel grid, which divides the 3D space into a few depth planes and defines rgb-alpha images at these depth planes. Since they reduce the number of voxels along the depth dimension, MPI-based methods save the computational cost to some extent.
Point clouds
A point cloud is an unordered collection of points in 3D space (Depth and normal maps can be considered as a special case of point cloud representation). It can be seen as discretized samples of a 3D shape surface. Point clouds are the direct outputs of depth sensors, so they are very popular in 3D scene understanding tasks. Although they are convenient to obtain, the irregularity of point clouds makes them difficult to be processed with existing neural networks that are for regular grid data (e.g., images).
the underlying 3D shape could be represented by many different point clouds due to the sampling variations.
To synthesize images with point clouds, a naive way is storing colors on points and rendering point clouds using the point splatting.
Meshes
Polygonal meshes are non-Euclidean data that represent shape surfaces with a collection of vertices, edges and faces. In contrast to voxels, meshes only model scene surfaces and thus are more compact. Compared with point clouds, meshes provide the connectivity of surface points that models the point relationship. Because of these advantages, polygonal meshes are widely used in traditional computer graphics applications, such as geometry processing, animation, and rendering. However, applying deep neural networks to meshes is more challenging than to point clouds because mesh edges need to be taken into consideration in addition to vertices.
In the rendering pipeline of traditional computer graphics, both software and hardware have been heavily optimized for rendering meshes.
Neural fields
A neural field is a continuous neural implicit representation and represents scenes or objects fully or partially with a neural network. For each position in 3D space, the neural network maps its related features (e.g., coordinate) to the attributes (e.g., an RGB value).
compared to the aforementioned representations, only the parameters of the neural network are required to store, resulting in lower memory consumption compared to other representations.
To render an image from a neural field, there are two streams of techniques:
- surface rendering
- volume rendering.
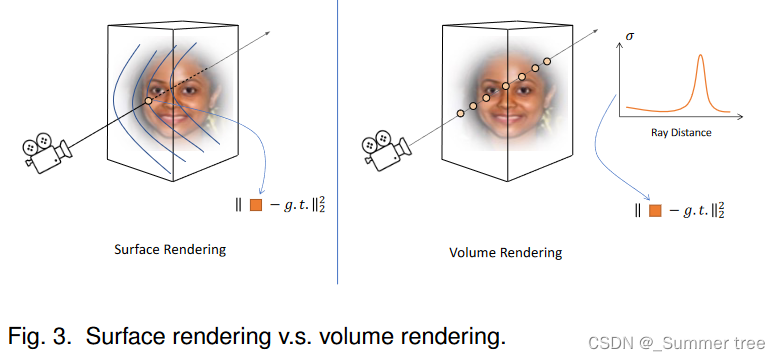
Surface rendering [146], [147] employs an implicit differentiable renderer that first shoots viewing rays and finds the intersection points with the surface, as shown in Fig. 3.
Though surface rendering based methods exhibit good performance on representing 3D objects and rendering 2D images, perpixel object masks and careful initialization are required by most of them to help optimize to a valid surface. The reason is that surface rendering only provides gradient at the raysurface intersection points and makes the network hard to optimize.
Volume rendering [69], in contrast, is based on ray casting and samples multiple points along each ray, which is shown in Fig. 3. It has shown great power in modeling complex scenes.
For each camera ray with origin o and direction d, the observed color is:
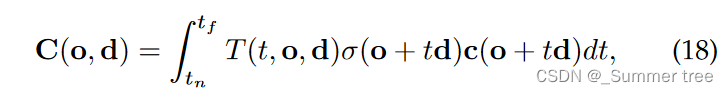
The accumulated transmittance value T is defined as follows:
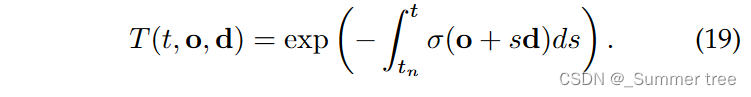
Hybrid representation.
Most of the hybrid representations focus on the combination of explicit and implicit representations. Explicit representations provide explicit control over the geometry. On the other hand, they are restricted by the resolution and topology. Implicit representations enable modeling complex geometry and topology with relatively small memory consumption. However, they are usually parameterized with MLP layers and output the attribute for each coordinate, suffering from small receptive fields. Thus, they are difficult to give explicit supervision on surfaces and hard to optimize. Researchers leverage the advantages of each type of representations to make up for the shortcomings of the other type of representations.
Hybrid representations seek to maximize the benefits of utilizing various representations. Hence, they are attracting more and more attention.
4 3D SHAPE GENERATION
Tab. 1 summarizes the representative methods on 3D shape generation.
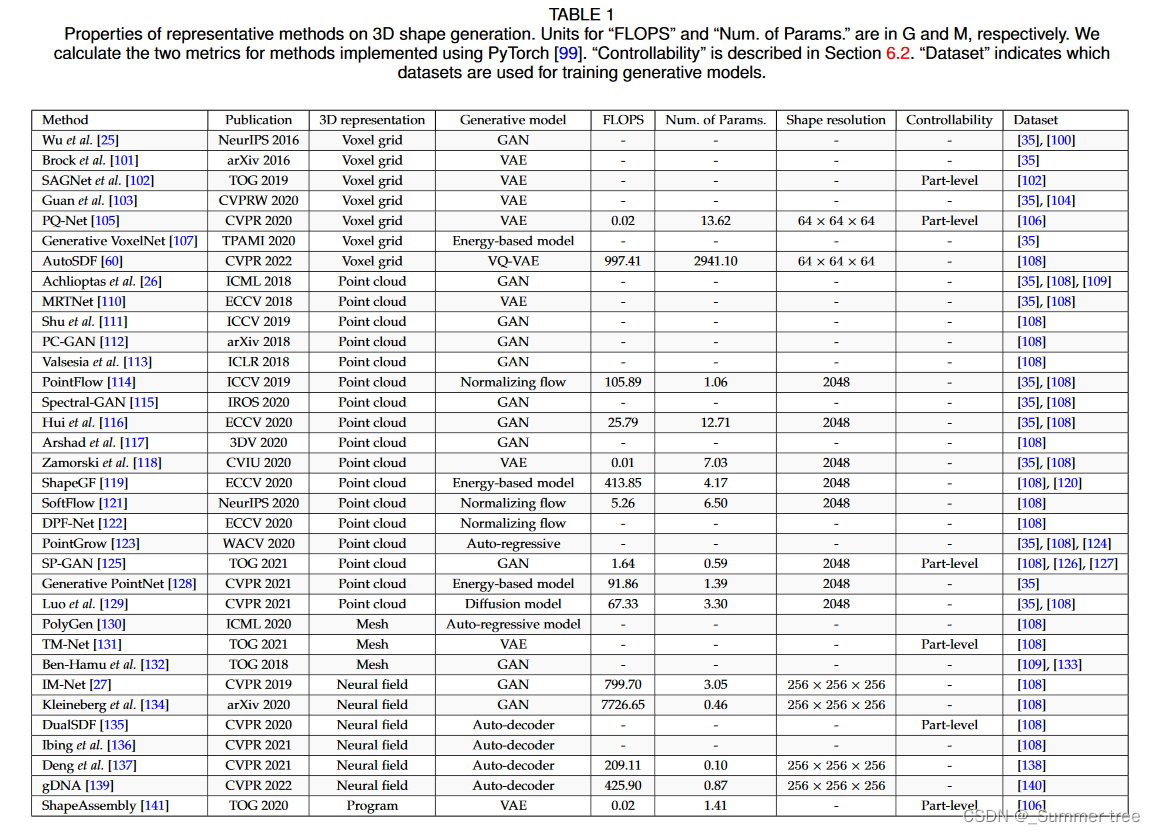
4.1 Voxel Grids
Voxel grids are usually seen as images in the 3D space. To represent 3D shapes, voxels could store the geometry occupancy, signed distance values or density values, which are implicit surface representations that define the shape surface as a level-set function. Thanks to the regularity of its data structure, voxel grid is one of the earliest representations being used in deep learning techniques for 3D vision tasks, such as 3D classification [35], [36], [101], 3D object detection [157], [158], and 3D segmentation [159], [160].
Wu et al. [25] adopt the architecture of generative adversarial networks to process 3D voxel grids.
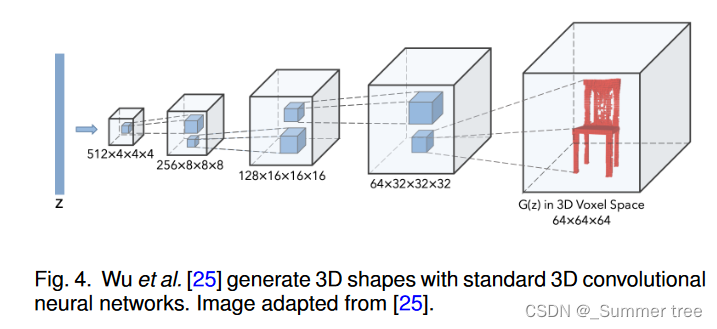
[101] attempts to train a variational auto-encoder to model the shape distribution, as shown in Fig. 5.

Voxel grids like 2D images, are in a euclidean structure, which works well with 3D CNNs. However, the voxel grid consumes much computation cost because the number of voxel elements grows cubically with resolution and quickly become intractable already at low resolutions. In contrast, octree for voxel can reduce a lot of computation, but due to its non-grid structure, it cannot be processed by neural network very efficiently.
4.2 Point Clouds
Since point clouds are direct outputs of depth scanners, they are a popular representation in scene understanding tasks. Modeling data priors of certain point cloud datasets with generative models facilitates downstream computer vision tasks [112], [164]. In contrast to voxel grids, point clouds are an explicit surface representation and directly characterize shape properties, which has two advantages. First, deep neural networks usually process point clouds with fewer GPU memory. Second, they are suitable to some generative models, such as normalizing flows and diffusion models. Despite the two advantages, the irregularity of point clouds makes networks difficult to analyze and generate them.
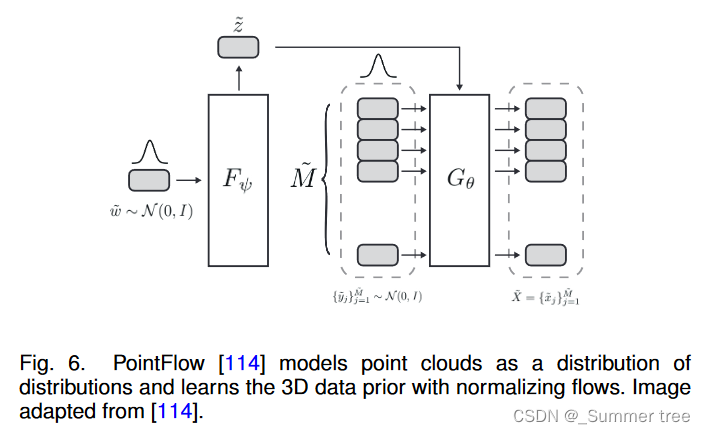
PointFlow [114] models point clouds as a distribution of distributions and introduces a normalizing flow model to generate point clouds. Fig. 6 presents its pipeline.
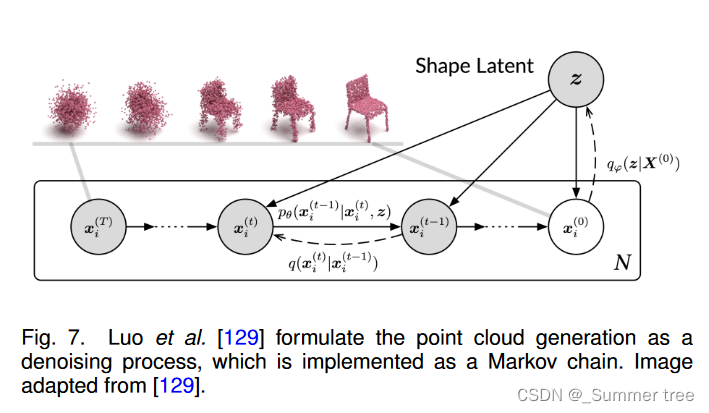
[129], [165] formulate the generation of point clouds as reverse diffusion process, which is in contrast to the diffusion process in non-equilibrium thermodynamics. Fig. 7 presents the diffusion process.
Point clouds have been adopted in many types of generative models to synthesize shapes. Although previous methods have achieved impressive performance on shape generation, the high-resolution shapes are still difficult to obtain. The reason is that high-resolution shapes requires many points for modeling, which will consume a large amount of GPU memory.
4.3 Neural Fields
Neural fields use neural networks to predict properties for any point in the 3D space. Most of them adopt MLP networks to parameterize 3D scenes and can model shapes of arbitrary spatial resolutions in theory, which is more memory efficient than voxel grids and point clouds. Although neural representations has superiority in the shape modeling, it is not straightforward to apply common generative models such as GANs on these representations, due to the lack of ground-truth data in neural representation format and the difficulty of processing neural representations with neural networks directly.
4.4 Meshes and Other Representations
Mesh is one of the most used representations in traditional computer graphics. It is also usually taken as the target object in many 3D modeling and editing softwares. Despite the mesh’s popularity in traditional applications, it is challenging to apply deep generative models to the mesh generation due to two factors. First, meshes are nonEuclidean data and cannot be directly processed by convolutional neural networks. Second, the mesh generation requires to synthesize meshes with plausible connections between mesh vertices, which is difficult to achieve.
5 3D-AWARE IMAGE GENERATION
The goal of 3D-aware image generation is to explicitly control the camera viewpoint when synthesizing images. 2D GAN-based models [217], [218], [219], [220], [221] achieve this goal by discovering a latent space direction corresponding to the viewpoint trajectory. Although they deliver impressive results, finding a reasonable direction in the latent space is not easy and usually cannot support the full control of the rendering viewpoint.
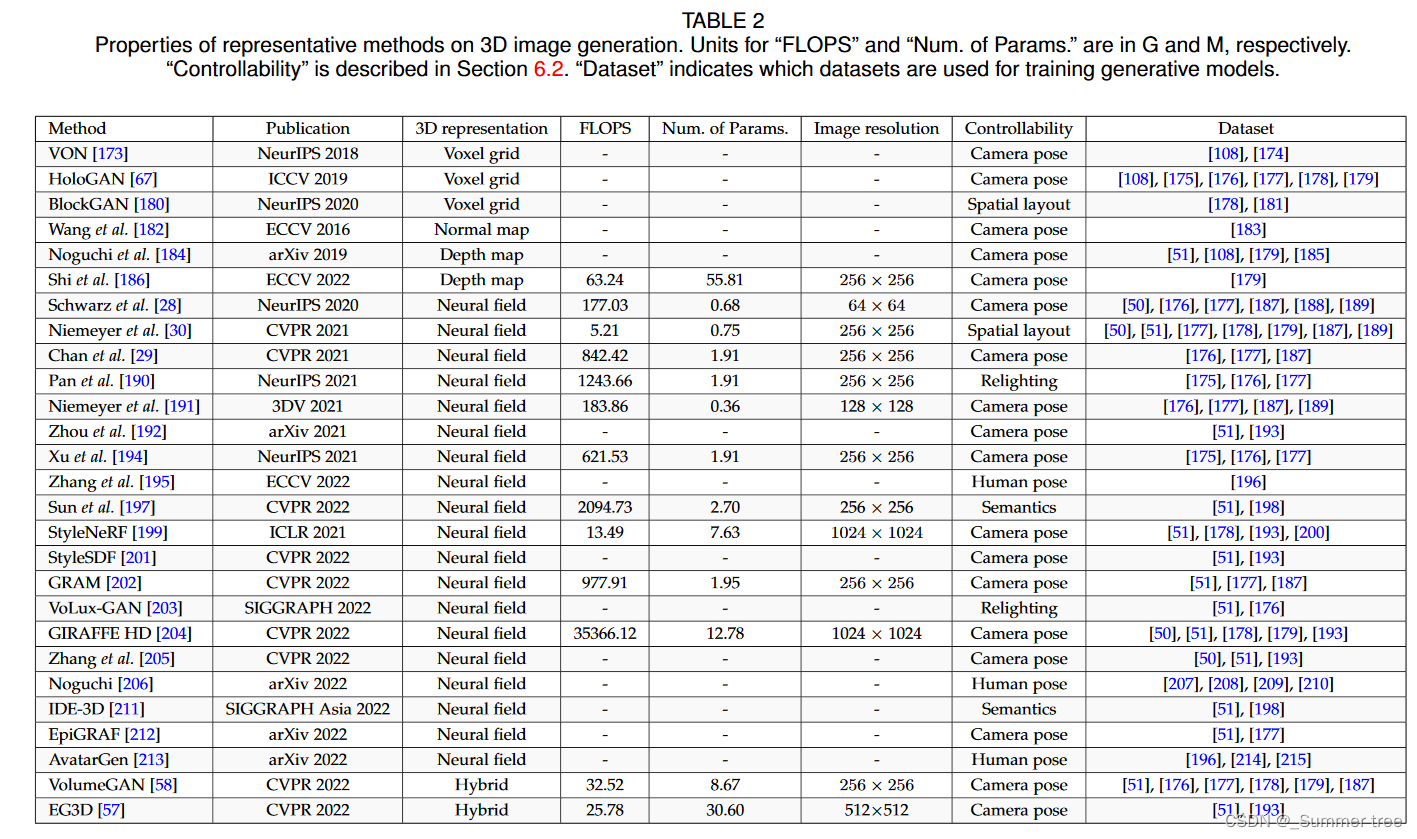
Representative methods on 3D-aware image generation are summarized in Tab. 2.
5.1 Depth/Normal Maps
Depth and normal maps are easily accessible representations that partially reveal the geometry of 3D scenes or objects. Since they only show the geometry from one side, they are usually referred to as 2.5D representations instead. Depth and normal maps can be involved in image generation with ease (i.e., processed by 2D convolutional neural network rather than 3D architectures) as they share the similar data format as 2D image.
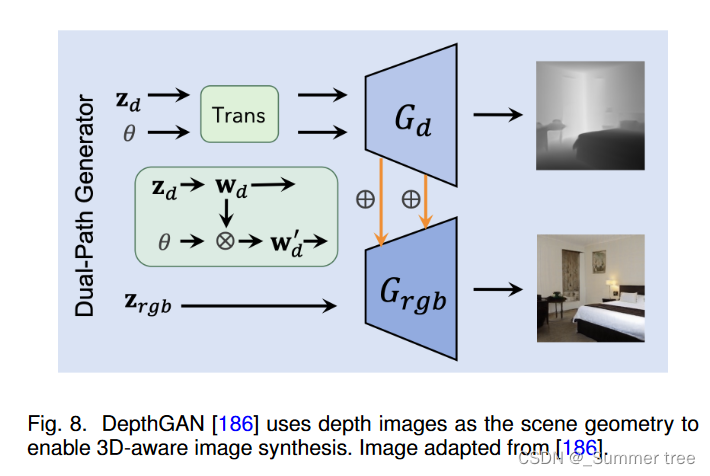
DepthGAN extracts intermediate features from the geometry path and injects them into the image path, as shown in Fig. 8.
5.2 Voxel Grids
There are generally two ways to synthesize images from voxel grids. The first way is using voxel grids to only represent 3D shapes, which are used to render depth maps to guide the image generation. The second way is embedding the geometry and appearance of scenes with voxel grids.
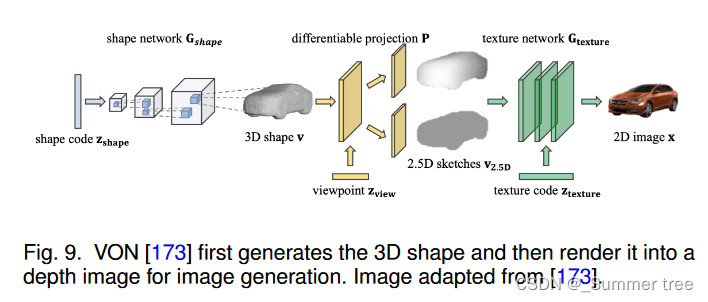
[173] and [224] are inspired from graphics rendering pipeline and decompose the image generation task into 3D shape generation and 2D image generation, which is illustrated in Fig. 9.
5.3 Neural Fields
Image synthesis methods based on neural fields generally adopt neural fields to implicitly represent the properties of each point in the 3D space, followed by a differentiable renderer to output an image under a specific viewpoint. Volume renderer [69] is the most commonly used renderer for 3D-aware image synthesis. Most of the methods use GANs to supervise the learning of neural fields.
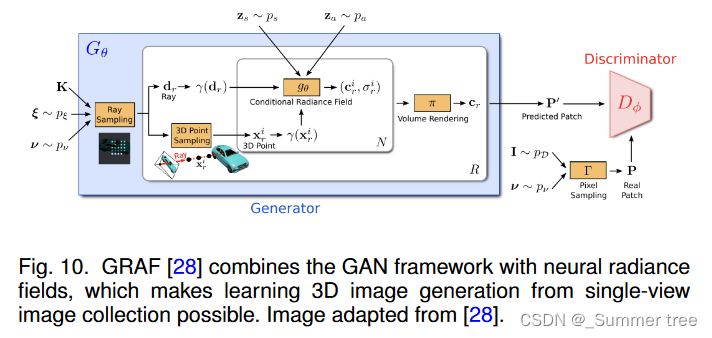
GRAF [28] firstly introduces the concept of generative neural radiance fields. As shown in Fig. 10, a MLPbased generator is conditioned on a shape noise and an appearance noise, and predicts the density and the color of points along each ray.
5.4 Hybrid Representations
Implicit representations can optimize the whole 3D shape well from 2D multi-view observations via differentiable rendering.
EG3D [57], which is shown in Fig. 11, proposes to use tri-plane instead of voxel as the explicit representations.
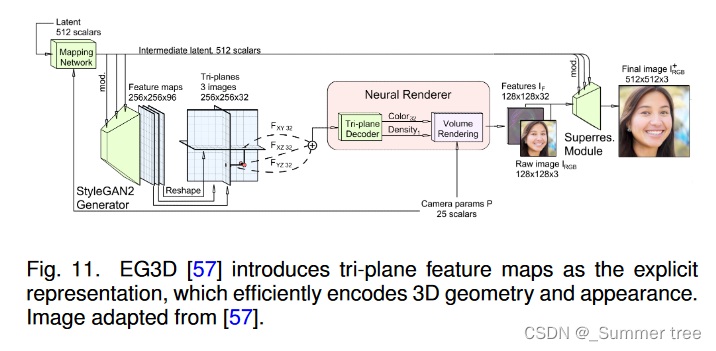
It has been shown that hybrid representations are effective in producing high-quality 3D-aware images and 3D shapes. Therefore, some following works [213], [242] also adopt tri-plane representation to achieve human synthesis. However, there is still space to improve, like training speed and strategy.
6 APPLICATIONS
The rise of 3D generative models has enabled many promising applications, as shown in Fig. 12. In this section, we discuss the applications of 3D generative models in terms of editing, reconstruction and representation learning.

6.1 3D Shape Editing
Many classical methods has for 3D shape editing, e.g., skeleton based deformation and cage based deformation. We refer to [243] for detailed survey of classical shape editing methods. In contrast to classical methods that directly edit the 3D shape, we focus on shape editing methods assisted by deep shape generative models.
3D space editing
- Several works edit shapes relying on user manipulation in the 3D shape space : Liu et al. [244]
- Instead of directly editing the voxel grids, a few methods study shape editing controlled by more compact representations, including sparse 3D points or bounding boxes [135], [136], [137], [245].
Latent code editing
Another set of methods updates the latent space of the generative model without user manipulation in the 3D space.
- Part-aware generative models naturally comes with part-level controllability [125], [166].
- Several methods explore shape editing guided by semantic labels or language descriptions [246], [247], [248].
6.2 3D-Aware Image Editing
As 3D-aware image generative models introduces physically meaningful 3D factors to the image formation process, the editing of 3D-aware image generative models can be categorized into two categories.
- One line of works edits the physically meaningful 3D factors,
- the other manipulates the latent code.
Physical factor editing
- All 3D-aware image synthesis methods allow users to control camera poses, resulting in 2D images of various viewpoints [28], [29], [57], [199], [201], [202].
- several methods [30], [180], [249] enable editing of object poses, inserting new objects by modeling the compositional nature of the scene.
- Re-lighting is also studied via disentangling the albedo, normal, and specular coefficients [194], [203], [238].
- several generative models for neural articulated radiance fields are proposed for human bodies [206], [213], [242], enabling shape manipulation driven by human skeletons.
Latent code editing
The latent code models all the other variations that are not captured by the physically meaningful 3D factors, e.g., object shape and appearance. One line of works allows for editing the global attributes of the generated contents. Several methods learn disentangled shape and appearance code for generative radiance fields, enabling independent interpolation of shape and appearance [28], [237].
6.3 3D Shape Reconstruction
Armotized inference
Generative models equipped with an encoder (e.g., VAE) naturally enables reconstructing 3D shapes from a given input. In contrast to standard 3D reconstruction that focus on one-to-one mapping from the input to the target 3D shape, generative methods allows for sampling many possible shapes from the posterior distribution.
This line of works is applicable to different types of input by switching the encoder.
Model inversion
Another line of methods leverages the inversion of generative models for reconstruction, typically requiring test-time optimization. Adopting an auto-decoder framework, a complete shape can be reconstructed from a partial observation via optimizing the latent code to match the partial observation [143], [252].
Note that by inverting 3D-aware generative models, camera poses can also be recovered, thus enabling category-level object pose estimation [254], [255].
6.4 Representation Learning
Another common application of generative models is to learn better representations for downstream tasks, e.g., classification or segmentation. Representation learning on point clouds has been demonstrated to be effective for model classification and semantic segmentation [26], [128], [256]. Generative models of voxel grids are also adopted for model classification, shape recovery and super-resolution [107].
7 FUTURE WORK
Here, we discuss promising future directions of 3D generative models.
-
Universality
-
Controllability
-
Efficiency
-
Training stability















 3743
3743











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











