







https://www.cnblogs.com/saixing/p/6730201.html
https://blog.csdn.net/okiwilldoit/article/details/81738782
【云服务器的负载均衡】https://cloud.tencent.com/document/product/214/5411
负载均衡的策略分为应用服务器和分布式缓存集群两种适应场景。
为什么这么分呢?简单的说,应用服务器只需要转发请求就可以了。但分布式缓存集群,比如redis、Memcached等,更多的是需要再次读取数据的。也正是因为这样,当新加入一台机器后,要尽量对整个集群的影响小。
1、应用服务器
NO.1—— Random 随机
这是最简单的一种,使用随机数来决定转发到哪台机器上。
优点:简单使用,不需要额外的配置和算法。
缺点:随机数的特点是在数据量大到一定量时才能保证均衡,所以如果请求量有限的话,可能会达不到均衡负载的要求。
NO.2—— Round Robin 轮询
这个也很简单,请求到达后,依次转发,不偏不向。每个服务器的请求数量很平均。
缺点:当集群中服务器硬件配置不同、性能差别大时,无法区别对待。引出下面的算法。
NO.3—— 随机轮询
所谓随机轮询,就是将随机法和轮询法结合起来,在轮询节点时,随机选择一个节点作为开始位置index,此后每次选择下一个节点来处理请求,即(index+1)%size。
这种方式只是在选择第一个节点用了随机方法,其他与轮询法无异,缺点跟轮询一样。
NO.4—— Weighted Round Robin 加权轮询
这种算法的出现就是为了解决简单轮询策略中的不足。在实际项目中,经常会遇到这样的情况。
比如有5台机器,两台新买入的性能等各方面都特别好,剩下三台老古董。这时候我们设置一个权重,让新机器接收更多的请求。物尽其用、能者多劳嘛!
这种情况下,“均衡“就比较相对了,也没必要做到百分百的平均。
Nginx的负载均衡默认算法是加权轮询算法。
Nginx负载均衡算法简介
有三个节点{a, b, c},他们的权重分别是{a=5, b=1, c=1}。发送7次请求,a会被分配5次,b会被分配1次,c会被分配1次。
一般的算法可能是:
1、轮训所有节点,找到一个最大权重节点;
2、选中的节点权重-1;
3、直到减到0,恢复该节点原始权重,继续轮询;
这样的算法看起来简单,最终效果是:{a, a, a, a, a, b, c},即前5次可能选中的都是a,这可能造成权重大的服务器造成过大压力的同时,小权重服务器还很闲。
Nginx的加权轮询算法将保持选择的平滑性,希望达到的效果可能是{a, b, a, a, c, a, a},即尽可能均匀的分摊节点,节点分配不再是连续的。
Nginx加权轮询算法
1、概念解释,每个节点有三个权重变量,分别是:
(1) weight: 约定权重,即在配置文件或初始化时约定好的每个节点的权重。
(2) effectiveWeight: 有效权重,初始化为weight。
在通讯过程中发现节点异常,则-1;
之后再次选取本节点,调用成功一次则+1,直达恢复到weight;
此变量的作用主要是节点异常,降低其权重。
(3) currentWeight: 节点当前权重,初始化为0。
2、算法逻辑
(1) 轮询所有节点,计算当前状态下所有节点的effectiveWeight之和totalWeight;
(2) currentWeight = currentWeight + effectiveWeight; 选出所有节点中currentWeight中最大的一个节点作为选中节点;
(3) 选中节点的currentWeight = currentWeight - totalWeight;
基于以上算法,我们看一个例子:
这时有三个节点{a, b, c},权重分别是{a=4, b=2, c=1},共7次请求,初始currentWeight值为{0, 0, 0},每次分配后的结果如下:
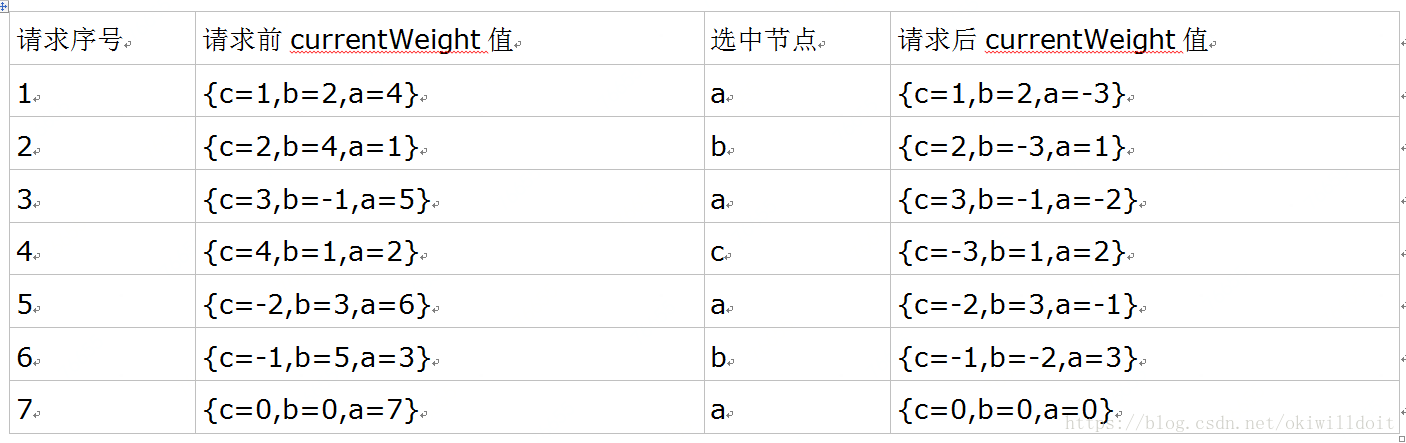
观察到七次调用选中的节点顺序为{a, b, a, c, a, b, a},a节点选中4次,b节点选中2次,c节点选中1次,算法保持了currentWeight值从初始值{c=0,b=0,a=0}到7次调用后又回到{c=0,b=0,a=0}。
参考文档为:https://www.cnblogs.com/markcd/p/8456870.html
NO.5—— Weighted Random 加权随机
加权随机法跟加权轮询法类似,根据后台服务器不同的配置和负载情况,配置不同的权重。
不同的是,它是按照权重来随机选取服务器的,而非顺序。
NO.6—— Least Connections 最少连接
这是最符合负载均衡算法的一个。需要记录每个应用服务器正在处理的连接数,然后将新来的请求转发到最少的那台上。
NO.7—— Latebcy-Aware
与方法6类似,该方法也是为了让性能强的机器处理更多的请求,只不过方法6使用的指标是连接数,而该方法用的请求服务器的往返延迟(RTT),动态地选择延迟最低的节点处理当前请求。该方法的计算延迟的具体实现可以用EWMA算法来实现,它使用滑动窗口来计算移动平均耗时。
Twitter的负载均衡算法基于这种思想,不过实现起来更加简单,即P2C算法。首先随机选取两个节点,在这两个节点中选择延迟低,或者连接数小的节点处理请求,这样兼顾了随机性,又兼顾了机器的性能,实现很简单。
具体参见:https://linkerd.io/1/features/load-balancing/
NO.7—— Source Hashing 源地址散列
根据请求的来源ip进行hash计算,然后对应到一个服务器上。之后所有来自这个ip的请求都由同一台服务器处理。
2、分布式缓存集群
好了,有了前面的基础,再看分布式缓存集群就简单多了。我们只需要多考虑两点就够了。
NO.1—— 取模
这是最简单但最不实用的一个。
以redis为例,假设我们有5台机器,要想取模肯定先得转换为数字,我们将一个请求的key转成数字(比如CRC16算法那),比如现在五个请求转换成的数字后对5取模分别为0、1、2、3、4,正好转发到五台机器上。
这时意外来了,其中一台宕机了,现在集群中还有4台。之后再来请求只能对4取模。问题就暴露出来了,那之前按照5取模的数据命中的机率大大降低了,相当于每宕机一台,之前存入的数据几乎都不能用了。
因此,不推荐此种做法。
NO.2—— 哈希
这种算法叫哈希有些笼统了,具体可以分为ip哈希和url哈希(类似原地址散列)。这里就不多说了。重点说下redis中的设计。
redis中引入了哈希槽来解决这一问题。16384个哈希槽,每次不再对集群中服务器的总数取模,而是16384这个固定的数字。然后将请求分发。这样就可以避免其中一台服务器宕机,原有数据无法命中的问题。
NO.3—— 一致性哈希
终于到重头戏了,不过有了前面的介绍,这个也就不难理解了。
一致性哈希在memcached中有使用,通过一个hash环来实现key到缓存服务器的映射。
这个环的长度为2^32,根据节点名称的hash值将缓存服务器节点放在这个hash环上。
详情见 下一篇文章














 232
232











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









