



1.1 概念
进程的定义:
1. 进程是程序的一次执行过程。
2. 进程是一个程序及其数据在处理机上顺序执行时所发生的活动。
3.进程是具有独立功能的程序在一个数据集合上运行的过程,它是系统进行资源分配和调度的一个独立单元。
但这样直接读概念并不有利于理解进程,我更愿意从进程的目的(为什么要这么设计)出发,理解进程。
1.2 如何理解进程
首先,我们要先知道程序是这么被加载到执行的:
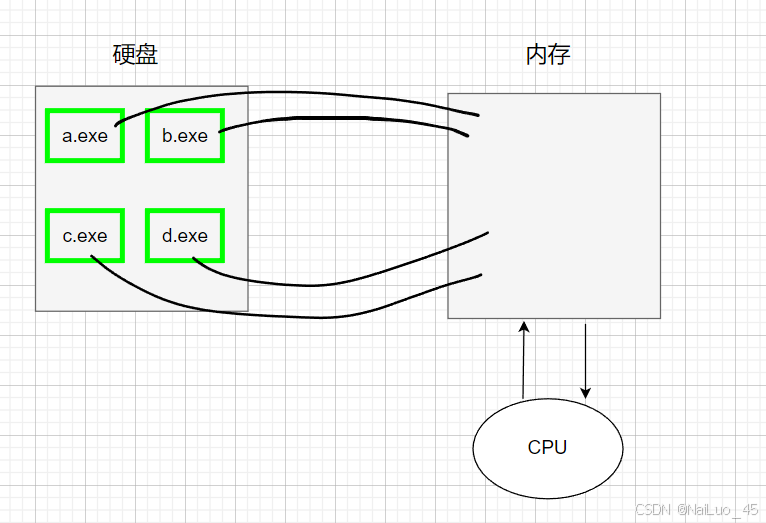
程序,本身是一个二进制文件,它会被操作系统加载(拷贝)到其他外设上,这个时候,我们需要注意几个基本事实:
1. 我们可以同时启动多个进程 -》将多个exe文件加载到内存
2. 那么操作系统就需要管理这些被加载到内存的程序
3. 这些运行的程序,就被成为进程,要管理他们,就要对他们进行先描述,再组织
至此,我们就理解了进程的目的(或者说意义,原因);但还不够,接下来要了解操作系统怎么描述进程,怎么组织?
1.2.1 描述进程
首先,操作系统基本都是用C语言写的,所以,描述进程就是用结构体struct,例如:
struct PCB
{
//状态
//优先级
//内存指针字段
//其他..
//struct PCB* next;
}
所以,当程序以二进制文件的形式加载进内存时,操作系统就会用这样的结构体对象去描述这些程序,每个程序都有一个对象;最后,这种数据结构,在操作系统的层面上,我们把它叫做PCB。全称:process ctrl block 进程控制块,也就是说,操作系统就是用进程控制块来描述进程的。
同时,我们也可以得出结论:
既然对象被创建来描述程序,那必然会开辟空间,也就是说,加载到内存里的程序比原来的程序大!
还没结束,描述完了还需要组织,PCB结构体里一般会有struct PCB* next 来指向下一个PCB对象,这样就把所有PCB以链表的形式管理起来了。
至此,就完成了转化:
对进程的管理 转化为 对PCB对象的管理
在操作上,对进程的管理 转化为 对链表的增删查改!
从代码的角度来看,进程 = 内核PCB对象 + 可执行程序; 更加全面的地说,
进程 = 内核数据结构 + 可执行程序
图解:
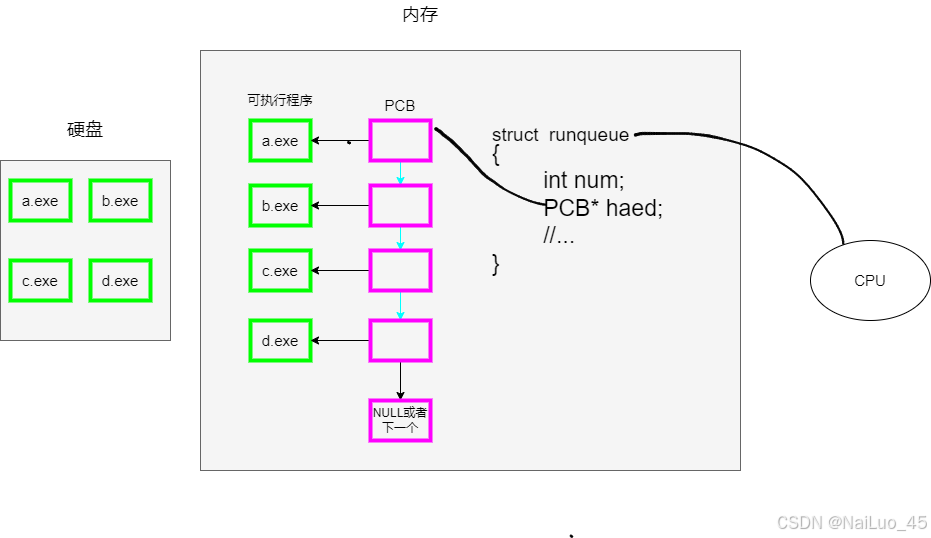
如图所示,CPU去调度可执行程序时,也不是直接去找可执行程序,操作系统会提过一个运行队列表,里面含有程序数量和指向以一个PCB对象的指针,当然还有不全部列出;CPU是去找PCB而不是程序!CPU是这样,操作系统也是这样,都不直接访问可执行程序。
总结:所有对进程的操作,都止与进程的PCB有关,而与进程的可执行程序无关!
1.2.2 内核数据结构
PCB是操作系统学科的叫法,Windows、Linux、MacOS也有,但不叫PCB;当然逻辑上都是先描述,再组织。这里以Linux系统的为例,来介绍内核数据结构。
这是早期版本(linux-2.6.11.12)源码中的task_struct ,Linux中的PCB叫做task_struct。
字段数量非常夸张:

2.1 查看进程
环境:腾讯云服务器提供的CentOS7,使用Xshell7进行连接!

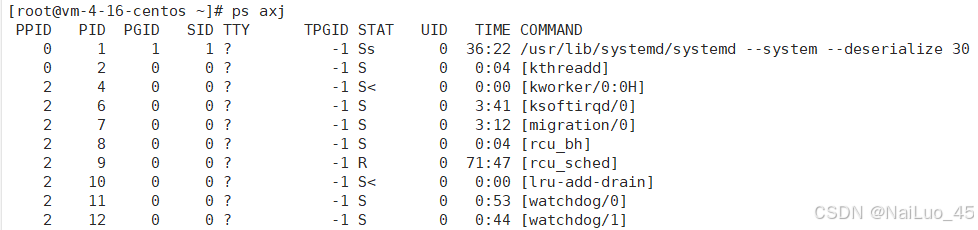
图中以列表显示出来的都是进程
其中,PID 是进程的标识符,就相当于一个人的身份证,是唯一的;PPID是该进程的父亲进程的PID,其余的后面再说明。
用代码来演示进程(环境:centOS7)
创建文件:
![]()
文件内容如下:
makefile:
myprocess:myprocess.c
gcc -o $@ $^ -std=c99
.PHONY:clean
clean:
rm -f myprocess
process.c:
#include <stdio.h>
#include <unistd.h>
int main()
{
while(1)
{
printf("I am a process!\n");
sleep(1);
}
return 0;
}
输入命令make,编译并生产可执行程序myprocess, ./myprocess运行程序;
复制会话,再另一个会话中输入ps axj | head -1 && ps axj |grep myprocess 查看进程
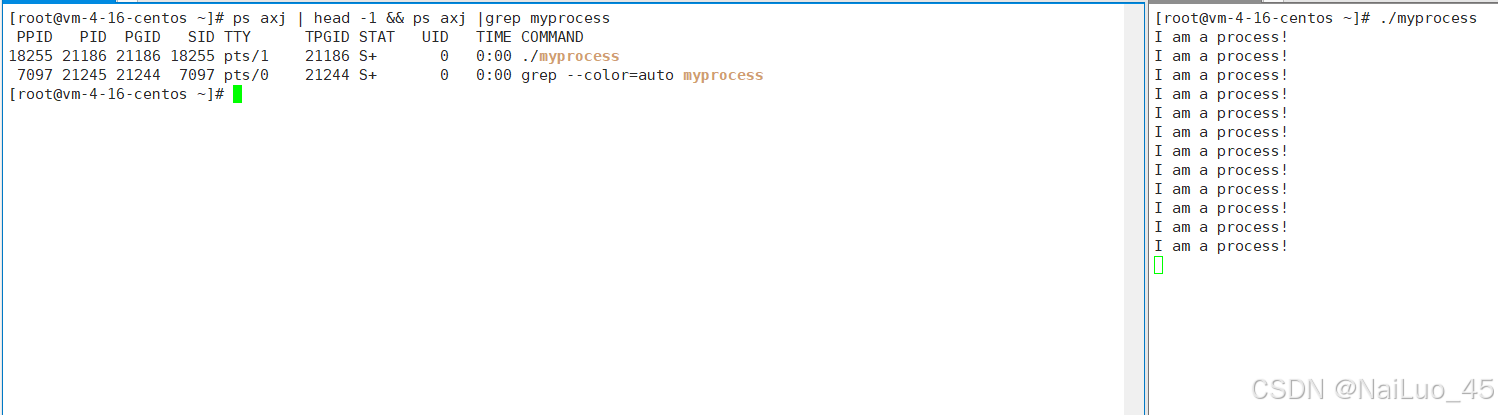
从图中观察发现,myprocess的确变成了进程,但是还有一个带有myprocess名称的进程,这其实是grep命令,它用来筛选出myprocess进程;从中也可以看出几乎所有命令都是进程。
这样观察进程还不够全面,进程不止会运行,还会退出等
输入命令 while :; do ps axj | head -1 && ps axj |grep myprocess | grep -v grep; sleep 1; done
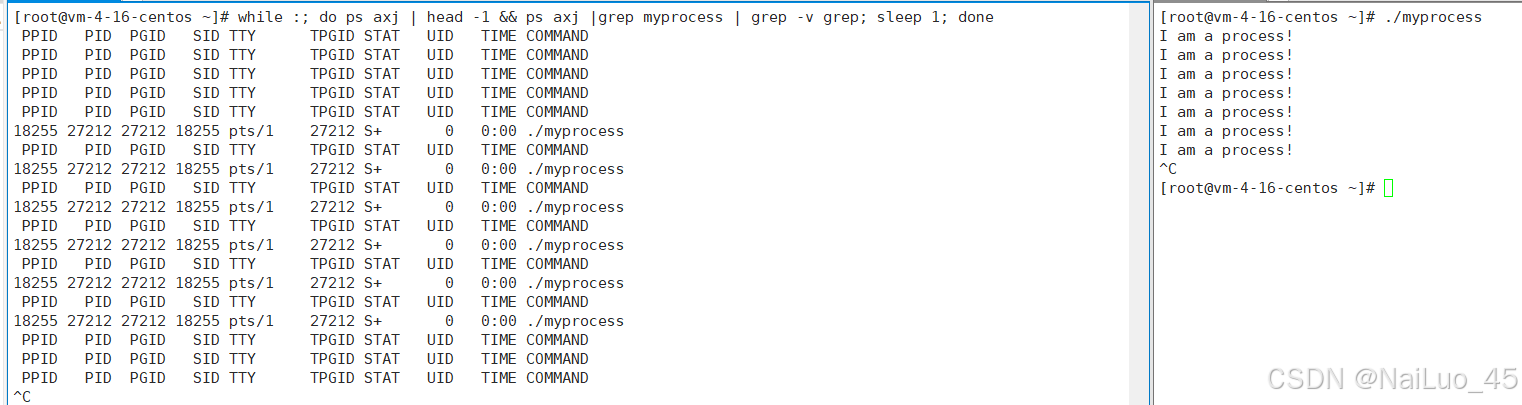
进程从无到有再无,进程是有生命的。
2.1.2 通过系统调用获取进程标示符
内核数据结构是操作系统管理,不可以让其他人直接访问,因此要访问进程的标识符,就要用系统调用接口。
C语言提供的接口是 getpid 和 getppid

其中pid_t 是系统定义的类型,本质是C语言的int类型
运用到代码:
myprocess.c:
#include <stdio.h>
#include <unistd.h>
#include <sys/types.h>
int main()
{
while(1)
{
printf("I am a process! pid:%d ppid:%d\n", getpid(),getppid());
sleep(1);
}
return 0;
}
如法炮制再运行并监视:
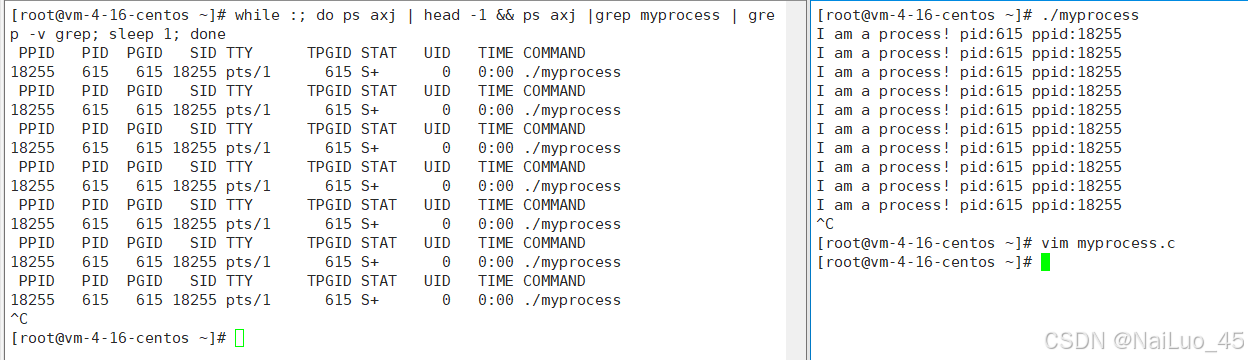
可以看到进程的pid为615,ppid为18255;一般在Linux,任何普通进程,都有他的父进程。
多次运行再结束进程,发现pid一直再变,而ppid不变;
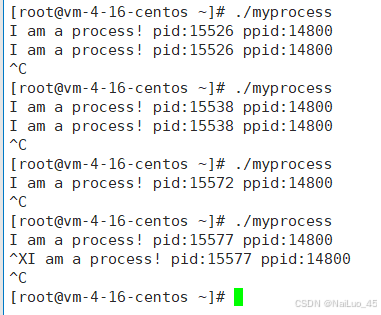
因为myprocess进程每次运行都是一个进程,而父进程,我们查看一下:
 是bash进程,一直都在,一直没变。
是bash进程,一直都在,一直没变。
2.2 通过系统调用创建进程-fork初识
fork的作用是创建一个进程
用man fork认识 fork:

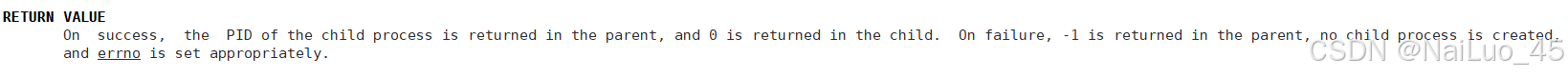
关于fork的返回值:
- 在父进程中,fork返回新创建子进程的进程ID;
- 在子进程中,fork返回0;
- 如果出现错误,fork返回一个负值;
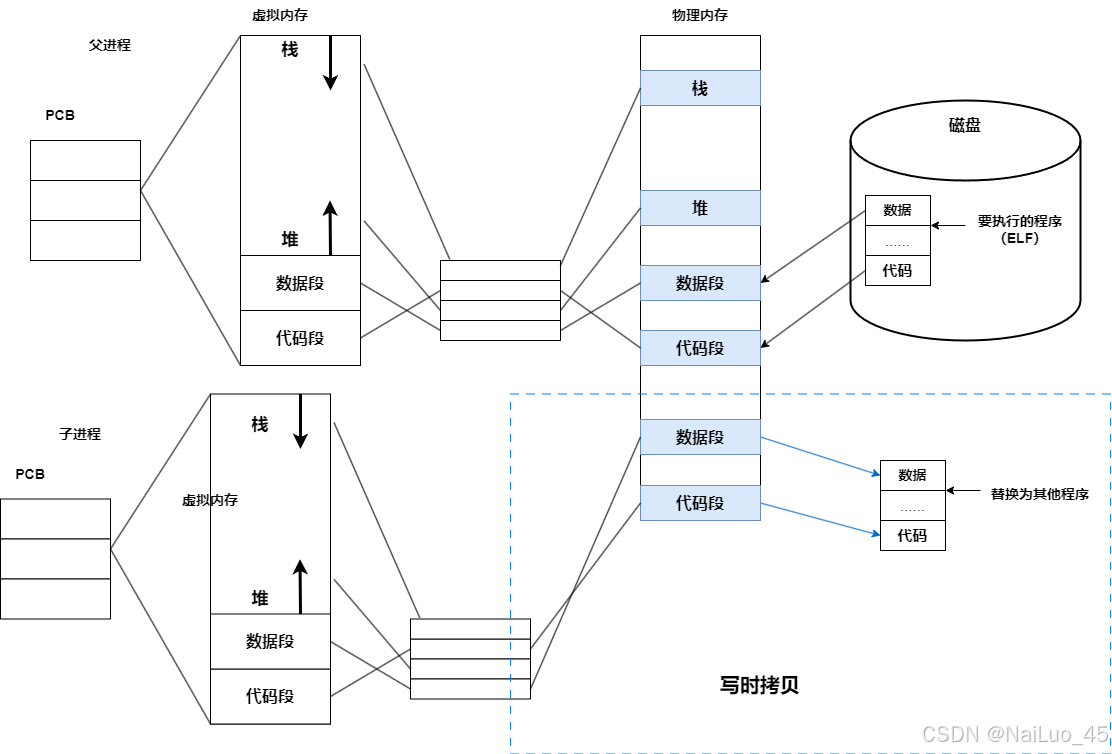
如果成功,fork就有两个返回值,为什么会有两个返回值?因为fork之后,会创建一个子进程,代码父子进程共享,数据各自开辟空间,私有一份(写时拷贝)。
例:
#include <stdio.h>
#include <unistd.h>
#include <sys/types.h>
int main()
{
printf("before fork: I am a prcess, pid: %d, ppid: %d\n", getpid(), getppid());
sleep(5);
printf("开始创建进程啦!\n");
sleep(1);
pid_t id = fork();
if(id < 0) return 1;
else if(id == 0)
{
// 子进程
while(1){
printf("after fork, 我是子进程: I am a prcess, pid: %d, ppid: %d, return id: %d\n", getpid(), getppid(), id);
sleep(1);
}
}
else{
// 父进程
while(1){
printf("after fork, 我是父进程: I am a prcess, pid: %d, ppid: %d, return id: %d\n", getpid(), getppid(), id);
sleep(1);
}
}
sleep(2);
return 0;
}
运行:
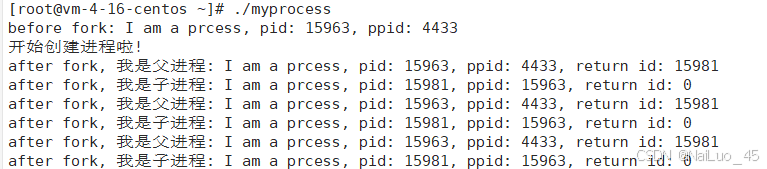
可以看到,fork()之后确实创建了子进程,也确实是两个进程在独立运行;而fork确实有两个返回值,给父进程返回子进程的pid,给子进程返回0;
图解:
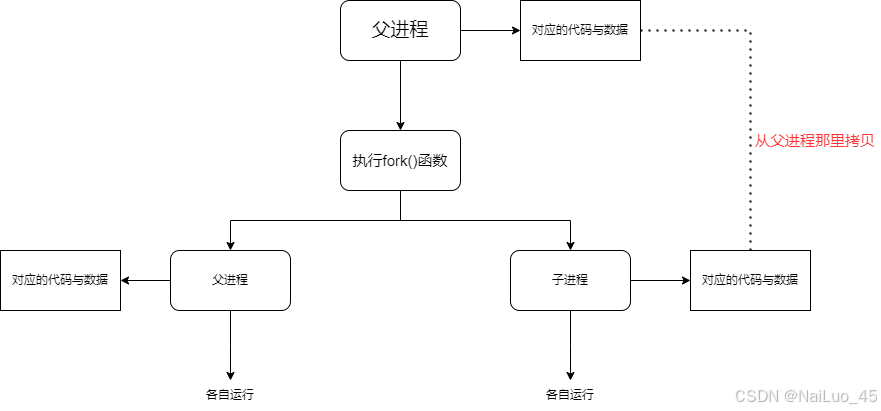
从图中可以看出进程是具有独立性的,进程之间独立运行,互不干扰,即使是fork创建后的子进程,运行先后也是看策略;进程创建时的拷贝其实不是直接拷贝。而是写时拷贝,这个之后解释。
fork函数给父进程返回子进程的PID,给子进程返回0,为什么?
一个父进程可以有多个子进程,但他需要PID这个唯一标识符识别;可子进程可以直接识别自己的父进程,不如传递自己是否创建成功。
fork为什么可以返回两次?
首先,fork创建了子进程,子进程拷贝父进程代码,它也有了fork;此时两进程并发执行,到return语句时,系统内核数据会根据当前进程的身份来决定返回的值。
id这个变量,怎么做到既等于0又大于0?
这个涉及到进程地址虚拟空间,之后会解释;现在可以理解为在Linux中,可以用同一个变量名,表示不同内存。
3.1 进程状态
3.1.1 进程有哪些状态
1.简单认识一下进程排队:
首先,进程不一定一直运行,即使在CPU上,可能要等待某种资源(比如等待键盘输入);
其次,排队排的是task_struct(内核数据结构);
最后,一个task_struct可以连入多种数据结构中;
具体如何实现?task_struct是像双链表那样连接,可当要去其他队列里,就不能这样连接了;这时候会有对于队列的结构体,task_struct中会有该队列的节点,通过节点访问task_struct(ask_struct可以进一步调用进程);这样,进程排队转化为对节点的排队。
图解:
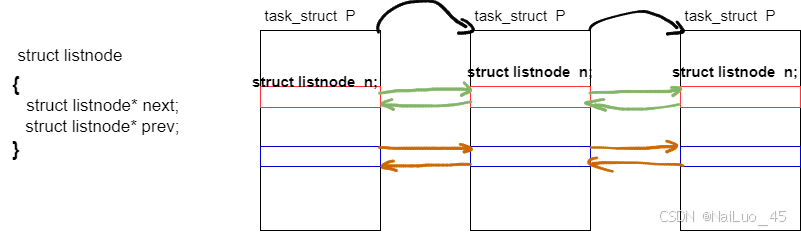
从图中可以看出,只需将代表不同队列的节点连起来,就实现了对进程的排序,而且队列之间互不干扰!
问题来了,顺序是保证了,怎么访问task_struct P? 可以用节点n的地址,减去n到task_struct起始地址的量(偏移量),就得到P的地址;
&n = &P + 偏移量
偏移量 = &n - &(task_struct*)0->n
&P = &n - 偏移量
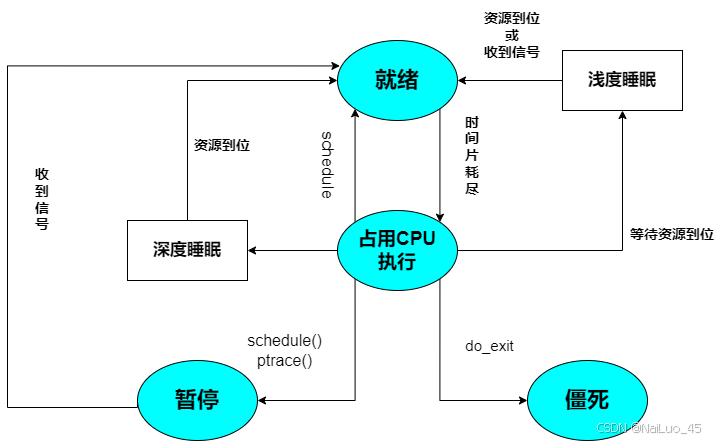
2.进程状态的描述:运行、阻塞,挂起
先理解状态本身。所谓的状态,本质就是一个在task_struct中的变量!
例:
#define Ready 1
#define Running 2
#define Block 3
task_struct
{
int status;
//......
}
状态的作用是什么?状态决定了进程的下一步的动作;Linux可能有多个进程都要根据状态进行下一步动作,这时候就要排队了。
此时,CPU会有一个运行队列,进程会按照上文的方式排起队来;处于这个队列的进程就属于运行队列。所以这个“R”状态,描述的是已经准备好随时被调用的进程。
对于阻塞状态,这里用操作系统管理硬件相关的设备的例子说明:
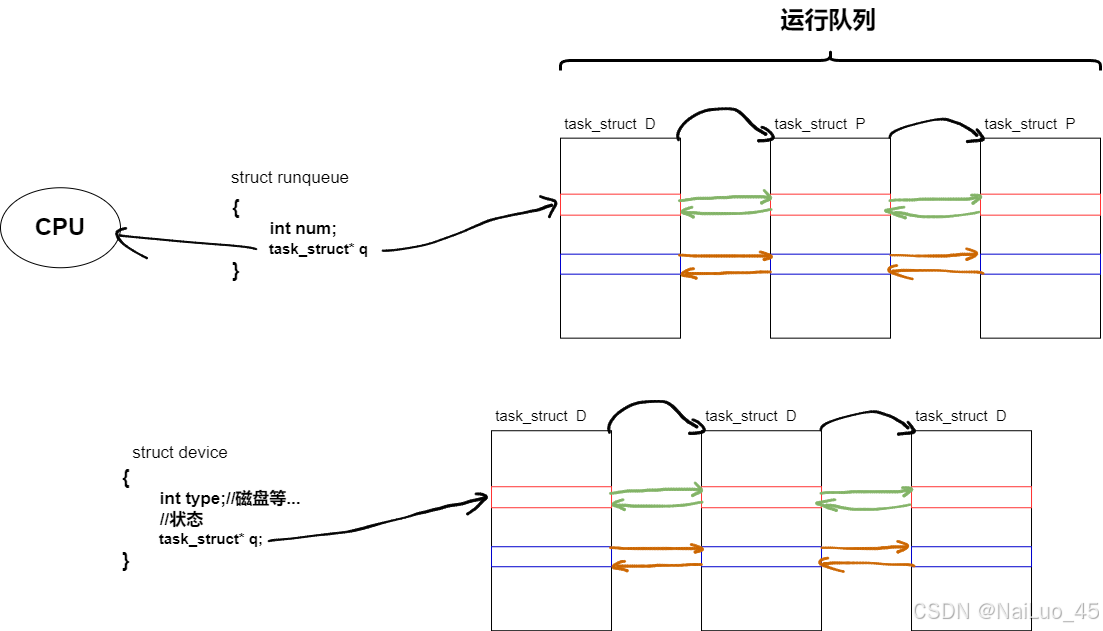
硬件设备也对应的PCB,也按照某种队列排序;假设,运行队列里的D对象被调度,但是需要等待硬件操作(比如等待键盘输入),但是它现在是运行状态,不可能不做事占着CPU;此时操作系统就会把它变成阻塞状态,同时回到硬件PCB队列中;如果硬件操作完成,操作系统再把它重新放进运行队列中,再把状态改为运行状态。(你可能会觉得这样以来回,这个进程运行会变慢,其实不然,CPU调度非常快,没有影响)
挂起状态:
挂起状态有一个前提,计算机资源非常吃紧;此时操作系统为了利用资源,会把未处于运行状态的进程的代码与数据放到磁盘里;等到该进程需要运行时再从磁盘中取出来。
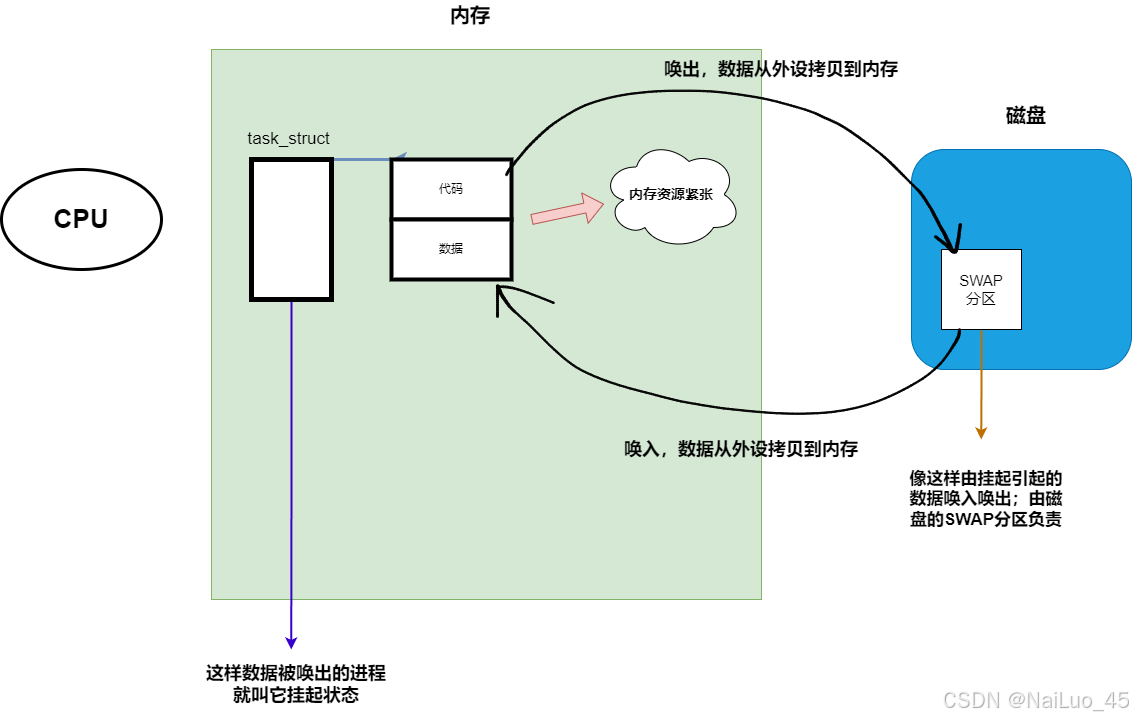
注:
进程的PCB不会因挂起被释放;
把一个进程加载到内存,优先加载它的PCB而不是代码和数据 ;
SWAP区一般和内存一样大,可以自己调节大小;但是,SWAP分区的数据交互本质是数据拷贝,太大会影响计算机速度;
3.Linux下的进程状态:
/*
* The task state array is a strange "bitmap" of
* reasons to sleep. Thus "running" is zero, and
* you can test for combinations of others with
* simple bit tests.
*/
static const char *task_state_array[] = {
"R (running)", /* 0 */
"S (sleeping)", /* 1 */
"D (disk sleep)", /* 2 */
"T (stopped)", /* 4 */
"T (tracing stop)", /* 8 */
"Z (zombie)", /* 16 */
"X (dead)" /* 32 */
};
R 状态就是操作系统里的运行状态;
4.1 进程优先级
先区分一下优先级和权限的区别。优先级是决定使用资源的先后顺序;而权限是决定一个进程能做什么,能使用什么资源;
4.1.1基本概念
Linux系统中,进程优先级的本质就是数字,数字越小,优先级越高。
task_struct
{
//优先级
int PRI;
//....
}
4.1.2查看系统进程

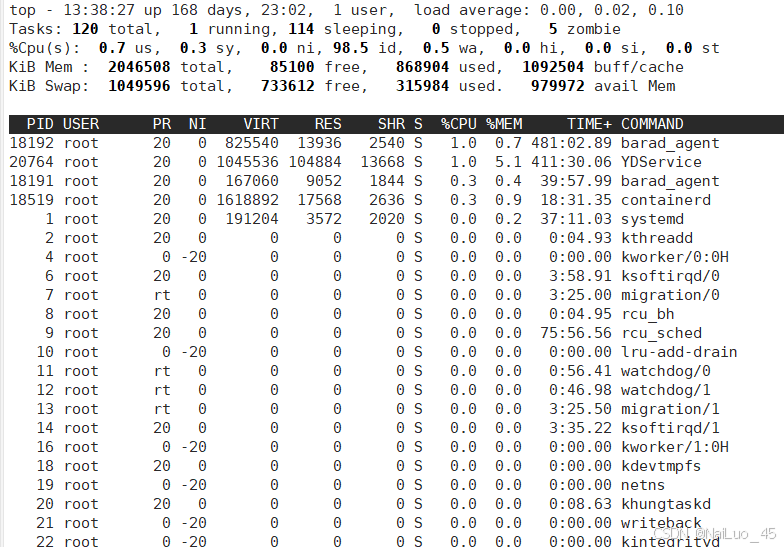
4.1.3查看进程优先级的命令
用top命令更改已存在进程的nice:
#include <stdio.h>
#include <unistd.h>
int main()
{
while(1)
{
printf("I am a process! pid:%d\n", getpid());
sleep(1);
}
return 0;
}
运行程序,输入ls -la,进程一开始PRI是80

用top, 再r,输入PID,先测上限,直接nice值改为100:
 可以看到,nice值修改为100,PRI实际上增加19,nice上限是19;
可以看到,nice值修改为100,PRI实际上增加19,nice上限是19;
如法炮制,nice值改-100,测下限:

可以看到,nice值修改为-100,PRI实际上减少20,nice下限是20;
所以nice的范围是[-20, 19]!
为什么要设置PRI的范围限制和nice值的范围限制呢?
操作系统分配资源要合理,不加限制的优先权,可能会出现进程一直享用资源或者一直无法享用资源的情况,可能会产生进程饥饿问题等!
4.1.4其他概念
4.2 Linux的调度与切换
概念准备:现代操作系统,都是基于时间片进行轮转执行的,进程再运行时,代码不一定全部执行完。
接下来,进一步了解进程是怎么切换的
4.2.1 进程切换
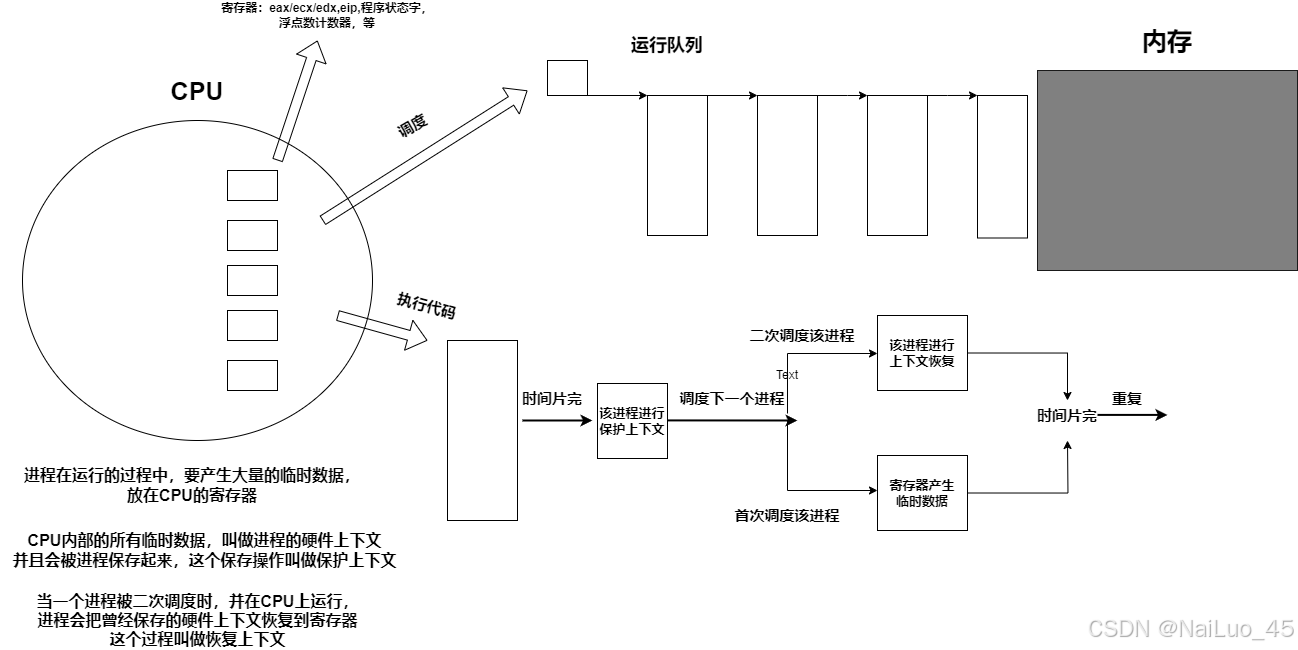
解释:
进程在CPU上运行时,寄存器上会产生临时数据,这个临时数据会被进程保存起来(拷贝方式);实际上,这个保存过程很复杂,但可以这样简化理解
时间片完,必须调度下一个进程进入CPU,这时候会进行判断,如果是首次调度该进程,寄存器产生新的临时数据(覆盖原来的);如果是二次调度该进程,则把数据恢复给寄存器。
注:
CPU内的寄存器只有一套;
寄存器内部保存的数据,可以有多套;
虽然寄存器数据放在了一个共享的CPU里,但是所有的数据,都是被进程私有的!
寄存器 != 寄存器的内容;
这就是进程切换的具体过程,看起来有点麻烦,但实际上非常快!
4.2.2 进程调度
研究进程调度,其实就是研究调度队列
用Linux2.6内核进程调度队列来说明,无关的字段被我省略:
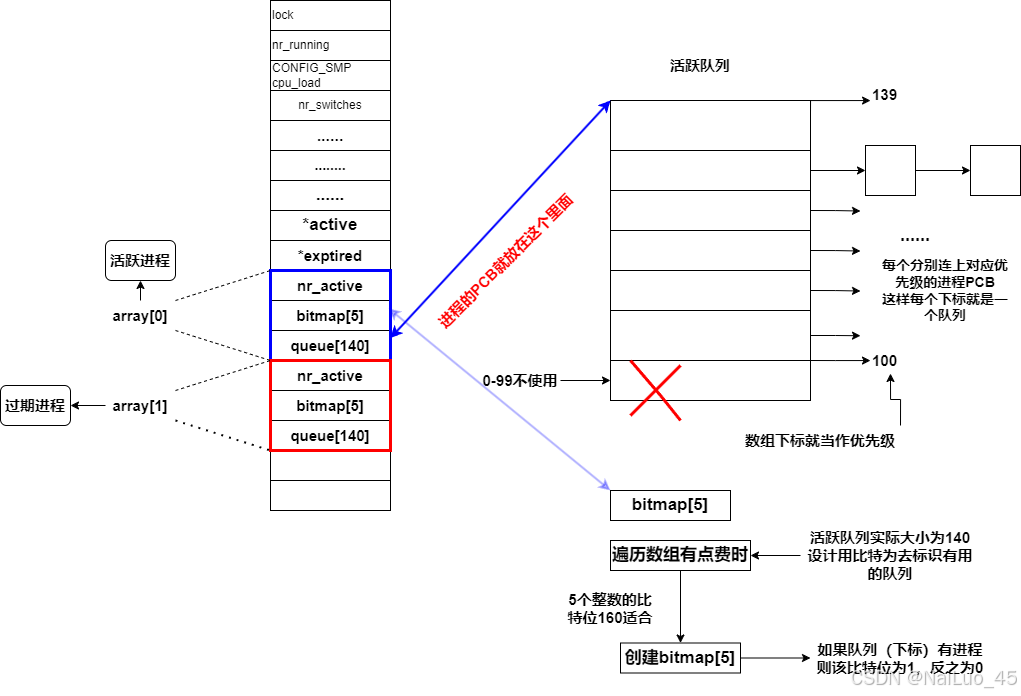
解释:
运行队列里有一个数组,大小为140,为了配合PRI的范围,只用100下标到139下标的内容;
每个下标的内容再指向进程的PCB,PCB直接再互相连接,这样每个下标就是PRI,下标对应的内容就是一个队列;
数组为task_struct类型,每一步的遍历消耗较大,而且要遍历40步;我们只关心一个下标的内容中有无队列,就把有“1”标记,没有用“0”标记;考虑到遍历的消耗要尽可能小,比特位最适合。所以用5个整数大小的比特位去标记每个下标的情况(运行对列数组共大小为140);用比特位去对应数组下标(具体由算法完成,类似哈希) ;这样去遍历比特位比遍历数组效率高了;
当然,还没完,如果一直有优先级高的进程“插队”,那么低优先级的进程不就一直等了吗?
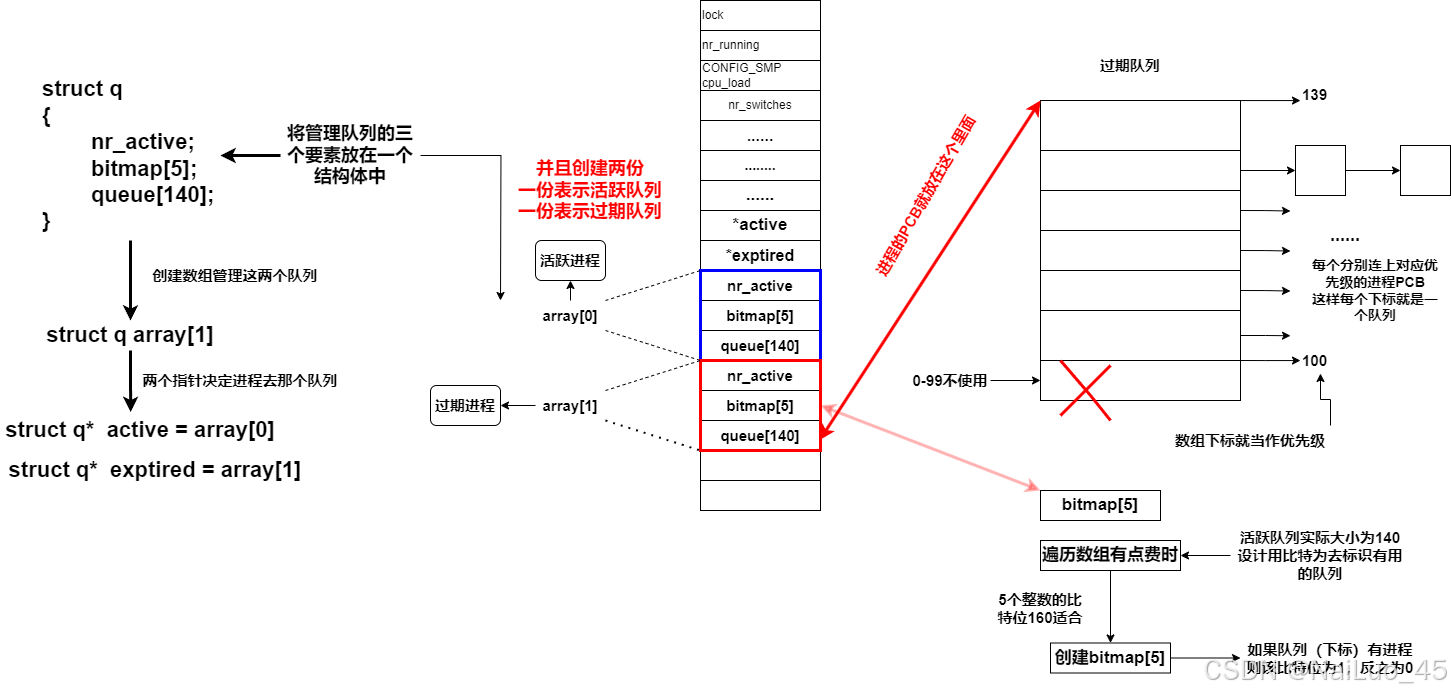
解释:
将队列描述并组织起来,创建两个队列,一个是活跃队列(上一张图),一个是过期队列(本图),这两个队列其实一模一样,没有区别。
再创建队列数组,用两个指针active和exptired来管理;
active指向的队列将为活跃队列,让活跃队列的进程运行,并且新来的进程无论优先级不能再进入这个队列;
exptired指向的队列将为过期队列,新来的运行状态队列就按照优先级进入这个队列;
CPU调度进程,active指向的队列,进程再不断减少;exptired指向的队列,进程不断增加;当时间片完,让exptired和active指向的内容交换;
重复次过程,就是进程调度!
5.1 环境变量
5.1.1 命令行参数
命令行为什么会显示一些系统信息?为什么看得懂命令?这关联到环境变量,但先来看看命令行参数。
#include <stdio.h>
int main(int argc, char* argv[])
{
int i = 0;
for(i = 0;argv[i];i++)
{
printf("argv[%d]: %s\n", i, argv[i]);
}
return 0;
}
argc 和 argv都是main函数自带的参数,不使用时一般不写;运行一下看看这些参数有什么用:
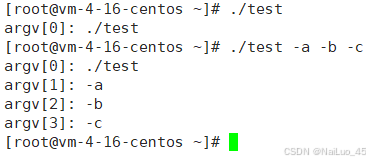
从图中可以观察到,命令解析被解析成了几段,存在argv中。(以空格切割字符)
这样做的目的是为了可以通过不同的选项,执行同一个程序的不同命令!
例:用下面代码模拟这个过程:(argv最后一个参数默认为NULL)
#include <stdio.h>
int main(int argc, char* argv[])
{
if(argc == 1)
{
printf("Usage: \n\t%s -[1|2|3]\n", argv[0]);
return 1;
}
if(argc > 2)
{
printf("最多一个选项!\n ");
}
else if(strcmp("-1", argv[1]) == 0)
{
printf("function 1\n");
}
else if(strcmp("-2", argv[1]) == 0)
{
printf("function 2\n");
}
else if(strcmp("-3", argv[1]) == 0)
{
printf("funtion 3\n");
}
else
printf("Unkonwn!\n");
return 0;
}

当然,命令具体的解析方式要根据具体需要。
5.1.2 基本概念


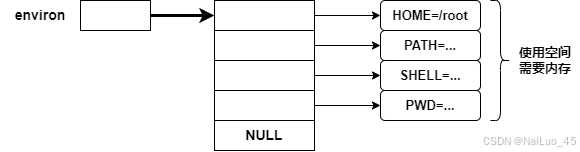
每个程序都会收到一张环境表,环境表是一个字符指针数组,每个指针指向一个以’\0’结尾的环境字符串。
总结:
定义变量的本质,其实是开辟空间
操作系统的环境变量,本质是系统自己开辟的空间,然后给它命名和内容
5.1.3 特性
环境变量具有全局属性,可以子进程继承
用下面代码来演示:
#include <stdio.h>
#include <stdlib.h>
int main()
{
char * env = getenv("MYENV");
if(env)
{
printf("%s\n", env);
}
return 0;
}
首先,先不给父进程导出环境变量MYENV(这里的父进程指的是bash),直接运行;
![]()
没有输出,说明没有继承环境变量,因为父进程没有MYENV;输入export MYENV="hello world",再运行:
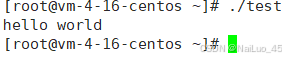
子进程继承了父进程的环境变量
注:
使用export VAR=value;不仅会在当前shell中设置该变量,还会导到子进程的环境中。
VAR=value;仅在当前Shell可用,不影响子进程。
5.1.4 代码获取和设置环境变量
#include <stdio.h>
int main(int argc, char *argv[], char *env[])
{
int i = 0;
for(; env[i]; i++){
printf("%s\n", env[i]);
}
return 0;
}
运行结果:

2.通过第三方变量environ获取
#include <stdio.h>
int main(int argc, char *argv[])
{
extern char **environ;
int i = 0;
for(; environ[i]; i++){
printf("%s\n", environ[i]);
}
return 0;
}
运行结果:

3.通过系统调用获取或设置环境变量
#include <stdio.h>
#include <stdlib.h>
int main()
{
printf("%s\n", getenv("PATH"));
return 0;
}
运行结果:

6.1 进程地址空间
研究背景:32位平台
6.1.1 程序地址空间
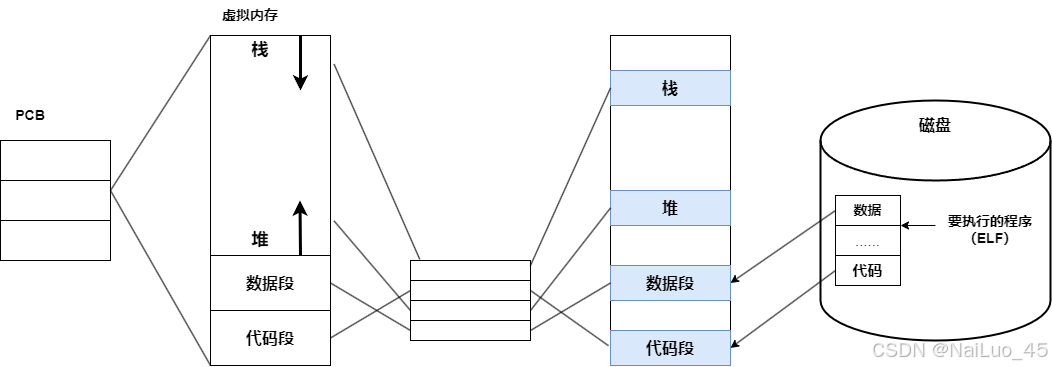
为了更好地理解进程地址空间,先来回顾一下程序地址空间。
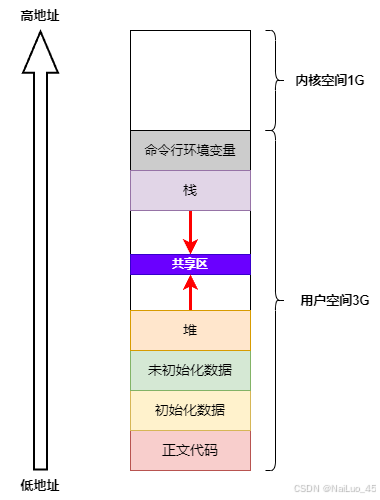
学习C语言应该看过这张图,了解过栈,堆等。
可是我们对他并不理解!
用代码进行更深的理解:
#include <stdio.h>
#include <stdlib.h>
#include <unistd.h>
int g_val = 0;
int main()
{
pid_t id = fork();
if(id < 0)
{
perror("fork");
return 0;
}
else if(id == 0)
{ //child
printf("child[%d], g_val: %d , &g_val: %p\n", getpid(), g_val, &g_val);
}
else
{ //parent
printf("parent[%d], g_val: %d, &g_val: %p\n", getpid(), g_val, &g_val);
}
sleep(1);
return 0;
}
运行结果:(结果与环境相关,观察现象即可)
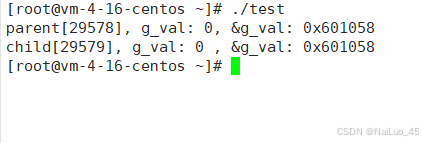
#include <stdio.h>
#include <stdlib.h>
#include <unistd.h>
int g_val = 0;
int main()
{
pid_t id = fork();
if(id < 0)
{
perror("fork");
return 0;
}
else if(id == 0)
{ //child
g_val = 100;//子进程肯定先跑完,也就是子进程先修改,完成之后,父进程再读取
printf("child[%d], g_val: %d , &g_val: %p\n", getpid(), g_val, &g_val);
}
else
{ //parent
printf("parent[%d], g_val: %d, &g_val: %p\n", getpid(), g_val, &g_val);
}
sleep(1);
return 0;
}
运行结果:
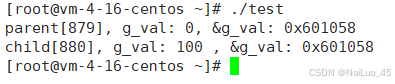
6.1.2 进程地址空间
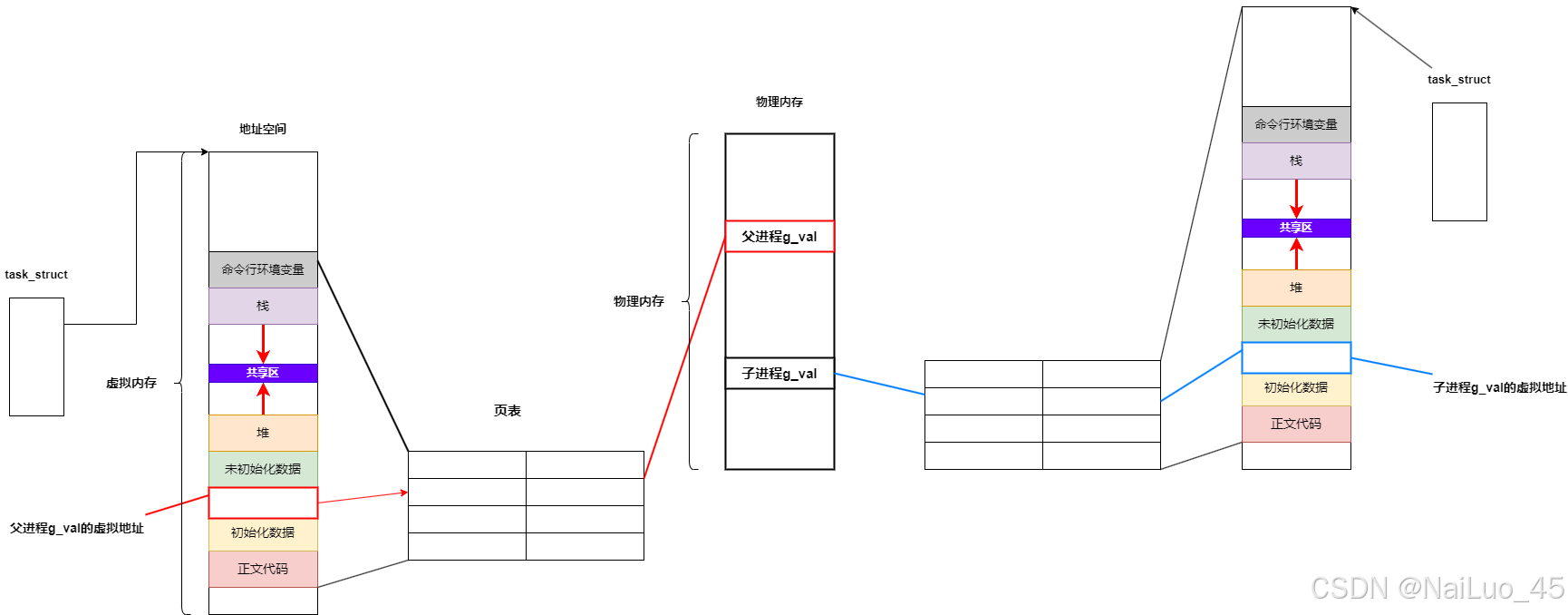
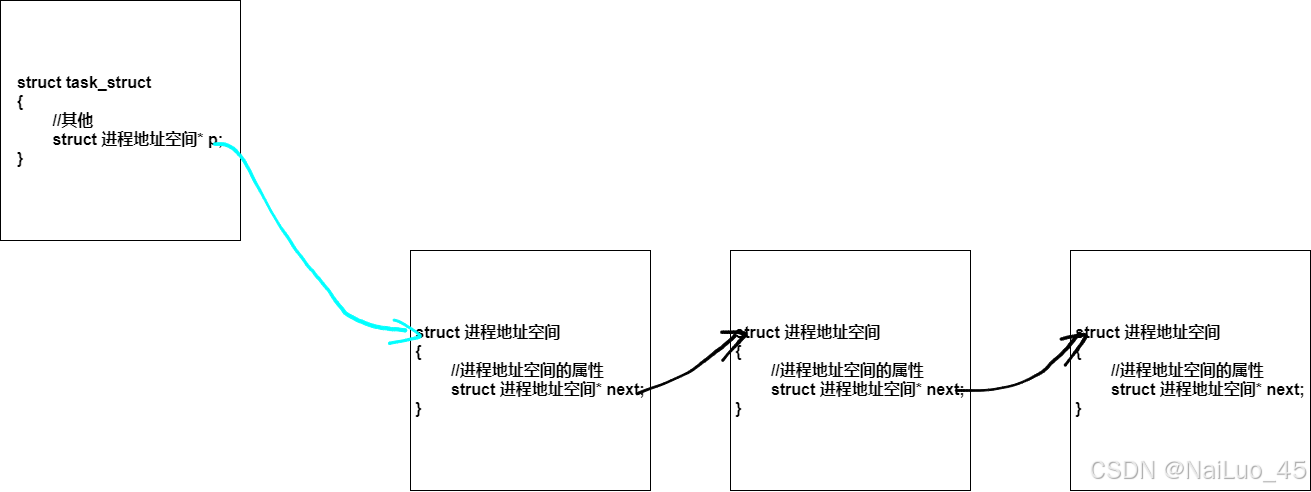
所以,进程地址空间就是数据结构对象“连接”在一起,对进程地址空间的管理就变成了对“链表”的管理;
那么进程怎么知道哪个空间是自己的?进程的PCB会有一个指针指向对应的空间;
2.如何理解进程地址空间的属性
从上面的图中,可以看到栈、堆等字段,本质是区域划分!
所以,在计算机中设计地址空间,必有这样的字段:
struct XXX
{
int code_start, code_end;
int stack_start,stack_end;
//...
}
其次,学习语言时,我们都遇到过越界访问的问题;所以区域划分,还具有判断是否越界和进行改变范围的属性。
linux-2.6.11.12中进程地址空间结构体示例:
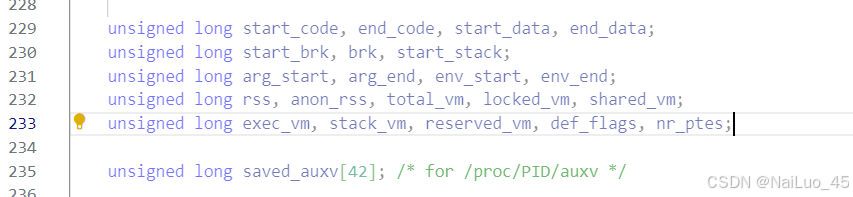
区域划分并不是单纯划分空间,它表示区域内的各个地址,都可以使用!
地址空间不具备对代码和数据的保存能力!需要在物理内存上保存!
操作系统会提供页表,将地址空间上的地址转化到物理内存中!
CPU中的有一个叫MMU的硬件,当CPU的指令需要访问物理内存时,它就会只直接访问页表;而且是通过物理内存访问页表;虚拟地址基本是给用户看的,操作系统给内部的基本都是物理内存。
3.地址空间和页表
为什么要有地址空间和页表这种组合,来访问物理内存,为什么不直接访问物理内存?
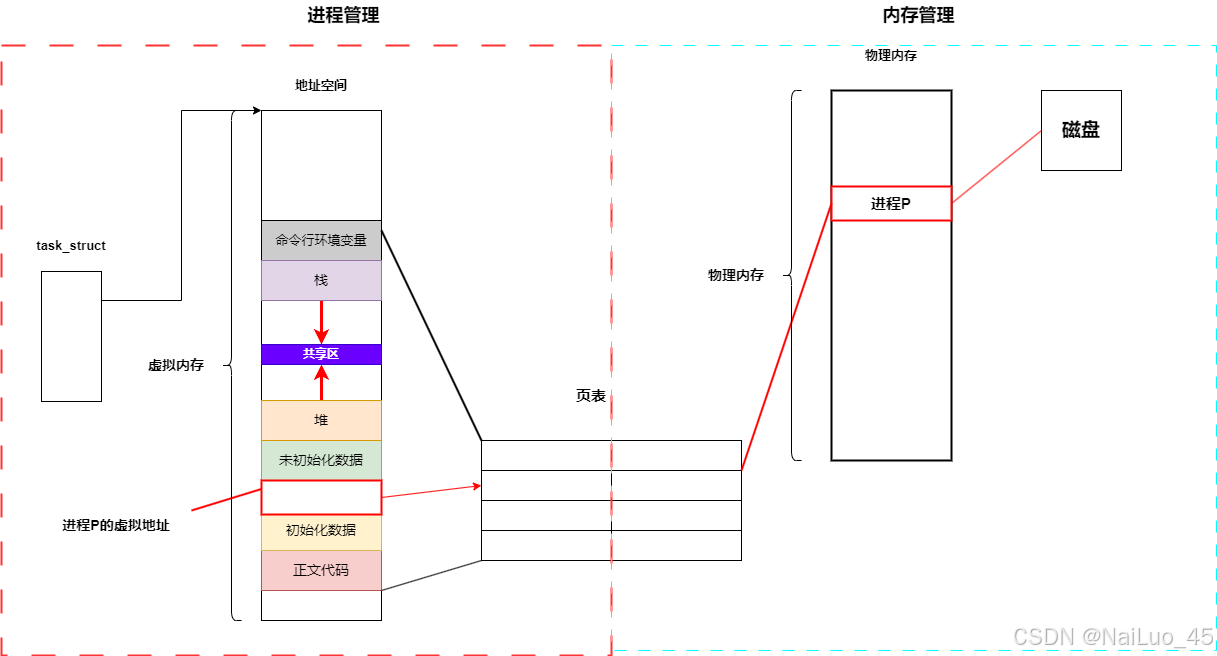
a. 将物理内存从无序变有序,让进程以统一的视角看待内存;
有了页表,物理内存可以随意储存,即使不连续也因为页表的存在而不影响进程;
b. 将进程管理和内存管理解耦合
有了页表加地址空间,进程和内存可以做到互不干扰!
这两点也方便操作系统的设计
c. 地址空间和页表是保护内存安全的重要手段
拦截非法访问等。
4.解释内存申请
现在,我们可以解释内存的申请了。
首先操作系统一定要为效率和资源使用率负责!所以:
申请内存,不一定使用,申请的内存是虚拟内存 ;如果使用,开辟物理内存建立映射,判断合法后允许使用;
好处:1.充分保证内存的使用率;2.提高new或malloc的速度
7.1 进程控制
1.进程创建
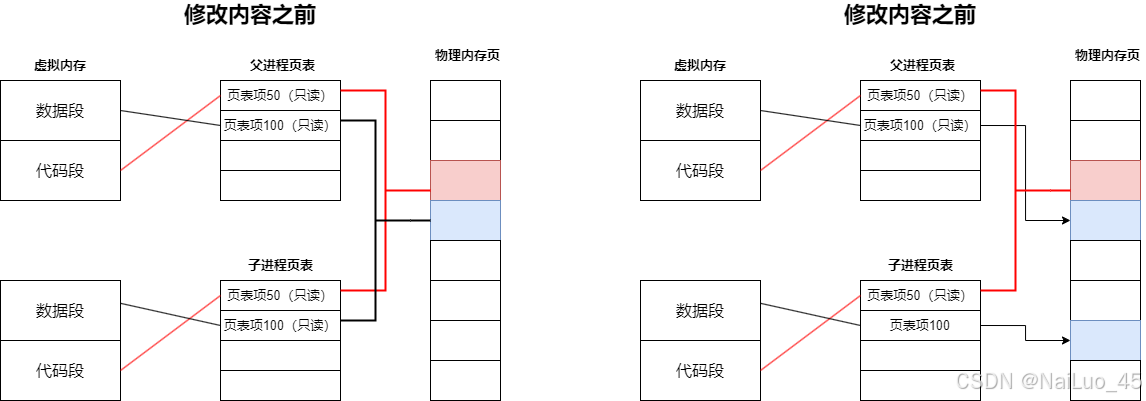
解释:
父进程创建了子进程,此时父子都不写入,数据代码共享;子进程进行数据写入,拷贝一份父进程的数据,重新建立映射关系,页表权限修改。
为什么要写时拷贝?(终极目的是提高效率和资源利用率)
(1). 创建子进程时,数据不一定会被用到;即使要用,可能也不是立刻使用;
(2). 先拷贝一份再修改,为了进程的独立性。
页表是有权限限制的,比如在C语言中,尝试对字符串常量进行修改,就会经过写时拷贝;可是,页表映射的条目,权限是只读,不让你修改。
2. 进程终止
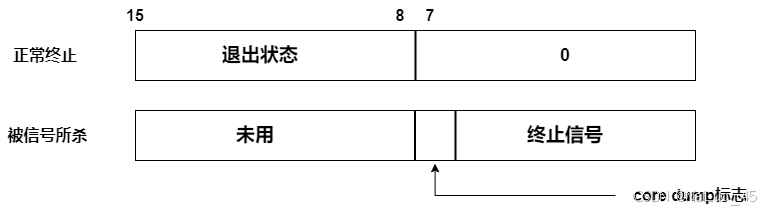
进程终止也就是进程退出,退出时会有退出码;
对于一个进程而言,mian函数的返回值,叫做进程的退出码;其他函数的退出,仅仅表示函数调用完毕;想知道函数执行情况,一般使用函数的返回值。
退出码:
一般情况下,退出码为0,表示进程执行成功;
非0,表示失败;一般用不同的数字表示不同的失败原因,这种退出码也被叫做错误码。
设计这些退出码就是为了知道进程执行的情况,所以所有退出码应该有对应的信息。
错误码转化为错误信息:
(1)使用语言和系统自带的方法转化
例如:C语言的strerror函数

(2)自定义
例如:
enum{
success=0,
open_err,
malloc_err
};
const char* errorToDesc(int code)
{
switch(code)
{
case success:
return "success";
case open_err:
return "file open error";
case malloc_err:
return "malloc error";
default:
return "unknown error";
}
}
这种情况一般是进程收到了信号,信号也类似退出码,不同的信号有不同的编号,表示不同的异常原因。
所以,任何进程,我们可以用两个具体的数字来表明它的执行情况!
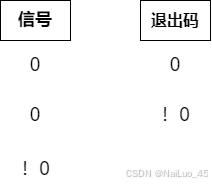
如果是非0信号,退出码就没有意义了
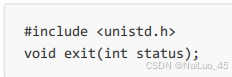

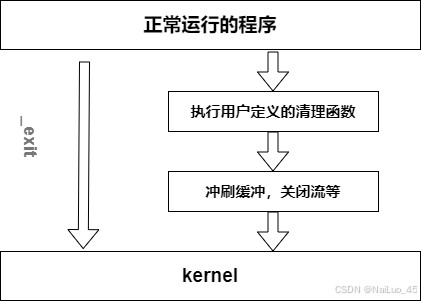
注:
这个缓冲区不是关于字符输出输入(printf)的缓冲区
3.进程等待

status 是一个输出型参数,该函数会在执行完后改变status以输出信息;
返回值,成功返回子进程pid,否则返回-1;
这里实际代码演示wait,着重将waitpid
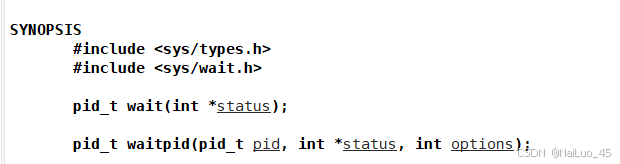
pid设置为-1,等待任意一个进程;设置一个PID,等到与PID相同的进程;
status与wait的用法一样;
options:可以选择等待方式,阻塞等待和非阻塞等待;
代码示例:
#include <stdio.h>
#include <stdlib.h>
#include <unistd.h>
#include <sys/types.h>
#include <sys/wait.h>
int main()
{
pid_t id = fork();
if(id == 0)
{
// child
int cnt = 5;
while(cnt)
{
printf("Child is running, pid: %d, ppid: %d\n", getpid(), getppid());
sleep(1);
cnt--;
}
exit(1);
}
int status = 0;
pid_t rid = waitpid(id, &status, 0); // 阻塞等待
if(rid > 0)
{
printf("wait success, rid: %d, status: %d\n", rid, status);
}
return 0;
}
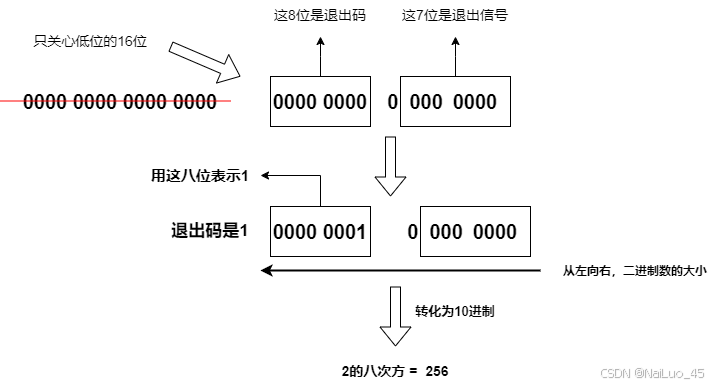
运行结果:

等待成功,也获取了子进程的信息,256,这其实就是1,一个数值转化问题:
阻塞等待:
当进程发出系统调用(如I/O操作)时,如果需要等待结果,操作系统会将该进程挂起,进入阻塞状态,直到等待的事件完成。这意味着进程在等待期间无法继续执行其他操作。
• 优点:实现简单,适合处理一些必须等待的操作。
• 缺点:进程在等待过程中无法做其他事,可能导致资源的浪费。
非阻塞等待:
进程发出系统调用时,立即返回而不阻塞进程,即使没有得到结果,进程也可以继续执行其他操作。进程通常需要以轮询(polling)或回调的方式反复检查事件是否完成。
• 优点:进程不必因为等待某个事件而被挂起,适合对实时性要求较高的场景。
• 缺点:实现相对复杂,轮询时可能增加系统负担。
总结来说,阻塞等待会使进程暂停直到事件完成,而非阻塞等待让进程能够继续处理其他任务,不必停下来等结果。
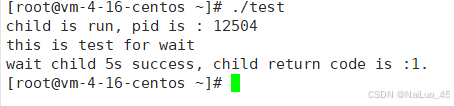
进程的阻塞等待方式:
#include <stdio.h>
#include <unistd.h>
#include <stdlib.h>
#include <sys/wait.h>
int main()
{
pid_t pid;
pid = fork();
if(pid < 0)
{
printf("%s fork error\n",__FUNCTION__);
return 1;
}
else if( pid == 0 )
{ //child
printf("child is run, pid is : %d\n",getpid());
sleep(5);
exit(257);
}
else
{
int status = 0;
pid_t ret = waitpid(-1, &status, 0);//阻塞式等待,等待5S
printf("this is test for wait\n");
if( WIFEXITED(status) && ret == pid )
{
printf("wait child 5s success, child return code is :%d.\n",WEXITSTATUS(status));
}
else
{
printf("wait child failed, return.\n");
return 1;
}
}
return 0;
}
非进程的阻塞等待方式:
#include <stdio.h>
#include <unistd.h>
#include <stdlib.h>
#include <sys/types.h>
#include <sys/wait.h>
#define NUM 5
typedef void(*func)(); //函数指针
func task_list[NUM];//任务列表
//////////任务
void PrintLog()
{
printf("this is a log print task!\n");
}
void PrintNet()
{
printf("this is a net print task!\n");
}
void PrintSave()
{
printf("this is a save print task!\n");
}
void InitTaskList()//初始化任务列表
{
task_list[0]=PrintLog;
task_list[1]=PrintNet;
task_list[2]=PrintSave;
task_list[3]=NULL;
}
void execute_task()
{
int i = 0;
for(i = 0; task_list[i];i++)
{
task_list[i]();
}
}
int main()
{
InitTaskList();
pid_t id = fork();
if(id == 0)
{
int cnt = 5;
while(cnt)
{
printf("I am a child! pid:%d, ppid:%d, cnt:%d\n", getpid(), getppid(),cnt);
while(1)
{
pid_t rid = waitpid(id,&status,WNOHANG);//非阻塞等待
if(rid>0)//等待成功且子进程退出
{
printf("wait success! rid:%d, exit_code:%d\n", rid, WEXITSTATUS(status));//取退出码
break;
}
else if(rid == 0)//等待成功但子进程还未退出
{
printf("child is runnung! do other things\n");
printf("###################### task ########################\n");
execute_task();
printf("###################### end ########################\n");
}
else//等待失败
{
perror("waitpid");
break;
}
sleep(1);
}
return 0;
}
运行结果:
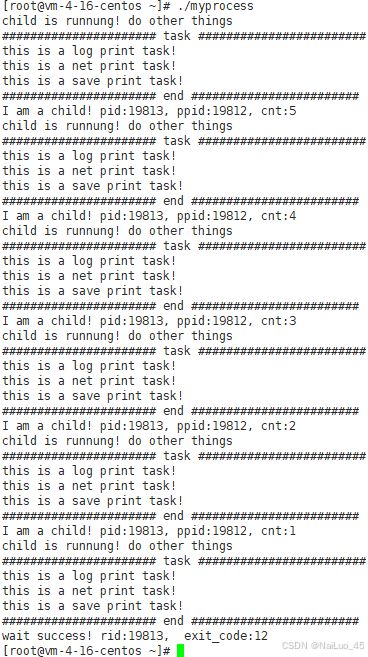
4.进程程序替换
把父子进程的关系考虑进程:
为什么要有程序替换这样的机制?因为我们想要程序可以执行不同的代码;
这个过程肯定需要操作系统的“同意”,所以程序替换一般需要系统调用,用对应的函数。
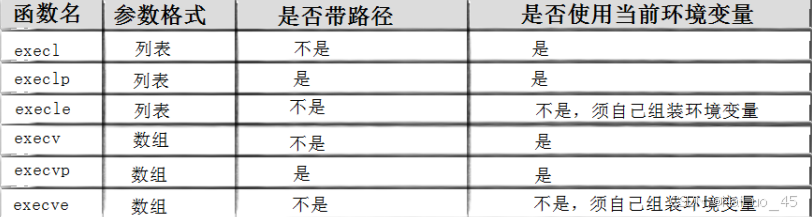
替换函数
其实有六种以exec开头的函数,统称exec函数 :

#include <stdio.h>
#include <unistd.h>
#include <stdlib.h>
#include <sys/types.h>
#include <sys/wait.h>
int main()
{
char* const env[]={
(char*)"PATH=/",
(char*)"HOME=xxx/ccc"
};
printf("I am a process! pid:%d\n", getpid());
//putenv("MYVAL=fffffff");//在继承来的环境变量上,再增加新的环境变量
pid_t id = fork();
if(id == 0)
{
//char* const argv[]=
//{
// (char*)"ls",
// (char*)"-a",
// (char*)"-l"
//
//};
sleep(3);
printf("exec start...\n");
//execl("/usr/bin/ls", "ls","-a","-l",NULL);//第一个字符是路径,后面是执行方式,最后必须以NULL结尾
//execl("/usr/bin/top", "top", NULL);
//execlp("ls", "ls","-a","-l",NULL);
//execv("/usr/bin/ls", argv);//第二个参数以传指针数组传递
//execvp("ls", argv);
//execl("./mytest", "mytest",NULL);//没有传递环境变量,子进程通过地址空间继承环境变量
//进程替换,不会替换环境变量数据
// execl("./mytest", "mytest", "-a","-b","-c",NULL);//调用另一个程序
//execl("/usr/bin/bash", "bash", "test.sh",NULL);//调用另一个程序
//execl("/usr/bin/python2.7", "python", "test.py",NULL);//调用另一个程序
execle("./mytest", "mytest",NULL, env);//给子进程设置全新的环境变量
//细节1:程序替换成功,exec*后续代码不再执行
//细节2:exec*只有失败返回值
//细节3:程序替换不会产生新进程
//细节4:创建一个进程,先创建pcb,地址空间,页表等
printf("exec end...\n");
exit(1);
}
pid_t rid = waitpid(id, NULL, 0);
if(rid > 0)
{
printf("wait success!\n");
}
return 0;
}
代码里的mytest.cc文件,已经其他语言的脚本:
mytest.cc:
#include <iostream>
using namespace std;
int main(int argc, char* argv[], char* env[])
{
for(int i = 0;env[i];i++)
{
printf("env[%d]: %s\n", i, env[i]);
}
//for(int i = 0; argv[i]; i++)
//{
// printf("argv[%d]: %s\n", i, argv[i]);
//}
cout<<"hello C++"<<endl;
cout<<"hello C++"<<endl;
cout<<"hello C++"<<endl;
return 0;
}
test.sh:
#! usr/bin/bash
echo "hello shell!!"
echo "hello shell!!"
echo "hello shell!!"
echo "hello shell!!"
echo "hello shell!!"
test.py:
#! /usr/bin/python2.7
print("hello python")
注:
细节1:程序替换成功,exec*后续代码不再执行
细节2:exec*只有失败返回值
细节3:程序替换不会产生新进程
细节4:创建一个进程,先创建pcb,地址空间,页表等
#include <stdio.h>
#include <stdlib.h>
#include <string.h>
#include <unistd.h>
#include <sys/types.h>
#include <sys/wait.h>
#define SIZE 1024
#define MAX_ARGC 64
#define SEP " "
char* argv[MAX_ARGC];
char pwd[SIZE];
char env[SIZE];
int exitcode = 0;
const char* UserName()
{
const char* name = getenv("USER");
if(name)
return name;
else
return "None";
}
const char* HostName()
{
const char* name = getenv("HOSTNAME");
if(name)
return name;
else
return "None";
}
char* Home()
{
char* name = getenv("HOME");
return name;
}
const char* CurrentWorkDir()
{
const char* name = getenv("PWD");
if(name)
return name;
else
return "None";
}
int Interactive(char out[], int size)
{
//输出命令提示符
printf("[%s@%s %s]$", UserName(), HostName(), CurrentWorkDir());
//获取命令字符
fgets(out, size, stdin);//使用fgets获取一行的字符
out[strlen(out)-1] = '\0';//处理换行字符
return strlen(out);
}
void Split(char in[])
{
int i = 0;
argv[i++] = strtok(in, SEP);
while(argv[i++] = strtok(NULL, SEP));//"=" 保证argv以NULL结尾
if(strcmp("ls", argv[0]) == 0)
{
//给ls命令加个显示颜色
argv[i-1] = (char*)"--color";
argv[i] = NULL;
}
}
int BuildInCmd()
{
int ret = 0;//0代表不是
//1. 判断是否为内键命令(1/0)
if(strcmp("cd", argv[0]) == 0)
{
//2.执行
ret = 1;
char* target = argv[1]; //考虑 cd "path"和cd的情况
if(!target)//target为空,路径变为家目录
target = Home();
chdir(target);//改变当前路径
//3.改变环境变量PWD
char temp[1024];
getcwd(temp,1024);//获取新的路径
snprintf(pwd,SIZE,"PWD=%s",temp);//把新路径写入环境变量
putenv(pwd);//导入环境变量
}
else if(strcmp("export",argv[0]) == 0)
{
ret = 1;
if(strcmp("export", argv[0]) == 0)
{
if(argv[1])
{
strcpy(env, argv[1]);//argv[1]指向命令行,会被下次命令覆盖
putenv(env);
}
}
}
else if(strcmp("echo", argv[0]) == 0)
{
ret = 1;
if(argv[1] == NULL)
{
printf("\n");
}
else if(argv[1][0] == '$')
{
if(argv[1][1] == '?')
{
printf("%d\n", exitcode);
exitcode = 0;
}
else
{
char* e = getenv(argv[1] + 1);
if(e)
printf("%s\n", e);
}
}
else
printf("%s\n", argv[1]);
}
return ret;
}
void Execute()
{
pid_t id = fork();
if(id == 0)
{
execvp(argv[0], argv);//选用execvp
exit(1);
}
int status = 0;
pid_t rid = waitpid(id,&status,0);
if(rid == id)
exitcode = WIFEXITED(status);
//printf("run done, rid:%d\n", rid);
}
int main()
{
while(1)
{
char commandline[SIZE];
//1. 打印命令行提示符,获取用户输入的命令字符串
int n = Interactive(commandline, SIZE);
if(n == 0) continue;
//printf("%s\n", commandline);//输出获取的命令
//2. 对命令行字符串进行切割
Split(commandline);
//3. 处理内键命令
n = BuildInCmd();
if(n) continue;
//4. 执行命令
Execute();
}
//int i = 0;
//for(i = 0;argv[i];i++)
//{
// printf("argv[%d]: %s", i, argv[i]);
//}
return 0;
}
注意处理内键命令!
感谢浏览!!!

















 5825
5825

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









