









首先我们到官网下载tika的jar包
1.将jar包引入到项目中:

接下来我们就可以进行数据的读取
参考文件: http://www.yiibai.com/tika/tika_architecture.html
1.读取普通本文
- package cn.qblank.tika;
- import java.io.File;
- import org.apache.tika.Tika;
- /**
- * 获取普通文本的数据
- * 使用Tika facade 类从文件中提取文本
- * @author evan_qb
- */
- public class ReadText {
- public static void main(String[] args) throws Exception {
- File file = new File("D:/test/test.txt");
- Tika tika = new Tika();
- String content = tika.parseToString(file);
- content = new String(content.getBytes("ISO-8859-1"),"gbk");
- System.out.println("文件内容为:\n" + content);
- }
- }
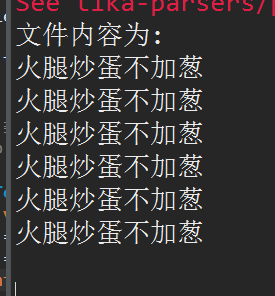
2.读取xml的数据
- package cn.qblank.tika;
- import java.io.File;
- import java.io.FileInputStream;
- import org.apache.tika.metadata.Metadata;
- import org.apache.tika.parser.ParseContext;
- import org.apache.tika.parser.xml.XMLParser;
- import org.apache.tika.sax.BodyContentHandler;
- /**
- * 读取xml文件
- * @author Administrator
- */
- public class ReaderXML {
- public static void main(String[] args) throws Exception{
- //检测文件类型
- BodyContentHandler handler = new BodyContentHandler();
- Metadata metadata = new Metadata();
- FileInputStream inputstream = new FileInputStream(new File("d:/test/contact.xml"));
- ParseContext pcontext = new ParseContext();
- //转换为xml
- XMLParser xmlparser = new XMLParser();
- xmlparser.parse(inputstream, handler, metadata, pcontext);
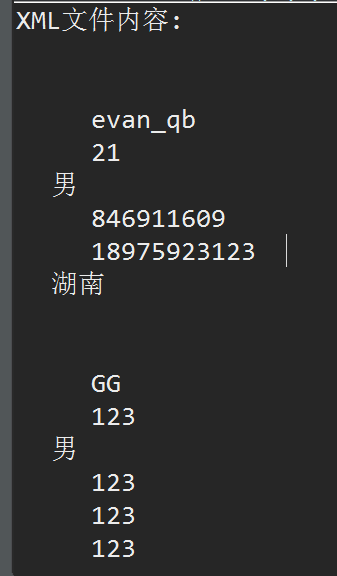
- System.out.println("XML文件内容:\n" + handler.toString());
- System.out.println("元数据内容:");
- String[] metadataNames = metadata.names();
- for(String name : metadataNames) {
- System.out.println(name + ": " + metadata.get(name));
- }
- }
- }
xml文件:
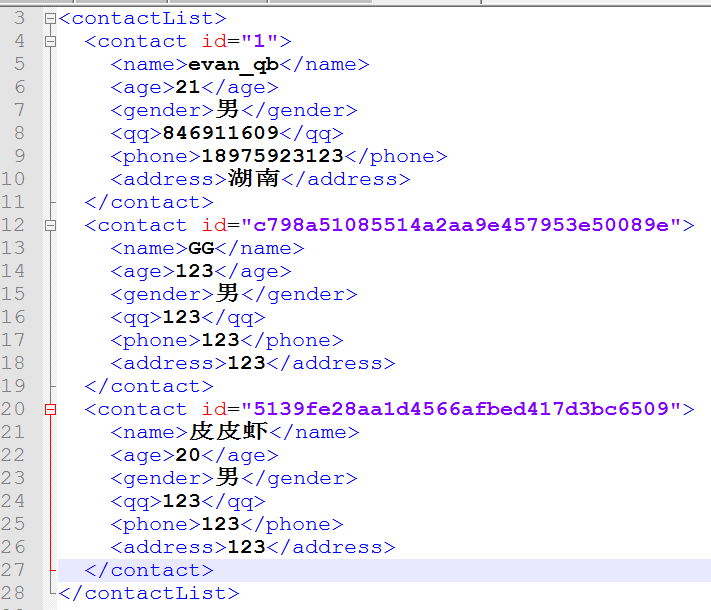
读取结果:
3.读取html
- package cn.qblank.tika;
- import java.io.File;
- import java.io.FileInputStream;
- import org.apache.tika.metadata.Metadata;
- import org.apache.tika.parser.ParseContext;
- import org.apache.tika.parser.html.HtmlParser;
- import org.apache.tika.sax.BodyContentHandler;
- /**
- * 获取HTML的数据
- * @author Administrator
- */
- public class ReaderXHTML {
- public static void main(String[] args) throws Exception {
- //检测html文件
- BodyContentHandler handler = new BodyContentHandler();
- Metadata metadata = new Metadata();
- FileInputStream inputstream = new FileInputStream(new File("D:/test/test1.html"));
- ParseContext pcontext = new ParseContext();
- //转换为HTML
- HtmlParser htmlparser = new HtmlParser();
- htmlparser.parse(inputstream, handler, metadata,pcontext);
- System.out.println("文档内容:\n" + handler.toString());
- System.out.println("元数据:");
- String[] metadataNames = metadata.names();
- for(String name : metadataNames) {
- System.out.println(name + ": " + metadata.get(name));
- }
- }
- }
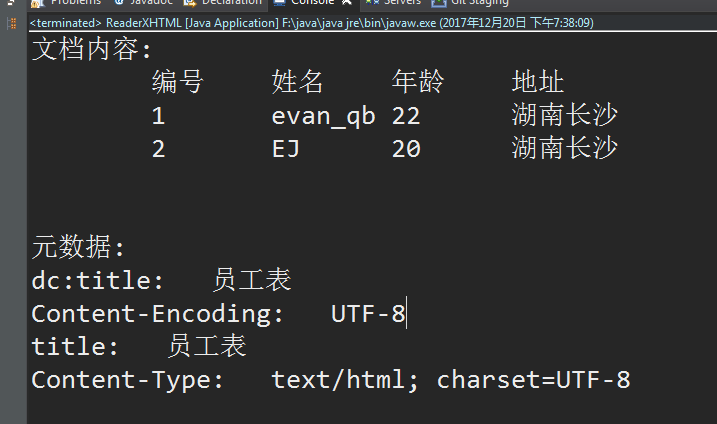
html文件如下:

读取结果如下:
4.读取Excel文档:
- package cn.qblank.tika;
- import java.io.File;
- import java.io.FileInputStream;
- import org.apache.tika.metadata.Metadata;
- import org.apache.tika.parser.ParseContext;
- import org.apache.tika.parser.microsoft.ooxml.OOXMLParser;
- import org.apache.tika.sax.BodyContentHandler;
- /**
- * tika入门:获取Excel文档的数据
- * @author evan_qb
- */
- public class ReaderSheet {
- public static void main(String[] args) throws Exception {
- //检测文件类型
- BodyContentHandler handler = new BodyContentHandler();
- Metadata metadata = new Metadata();
- FileInputStream inputstream = new FileInputStream(new File("d:/Writesheet.xlsx"));
- ParseContext pcontext = new ParseContext();
- //使用OOXMLParser转换器
- OOXMLParser msofficeparser = new OOXMLParser ();
- msofficeparser.parse(inputstream, handler, metadata,pcontext);
- System.out.println("数据内容:\n" + handler.toString());
- System.out.println("元数据:");
- String[] metadataNames = metadata.names();
- for(String name : metadataNames) {
- System.out.println(name + ": " + metadata.get(name) );
- }
- }
- }
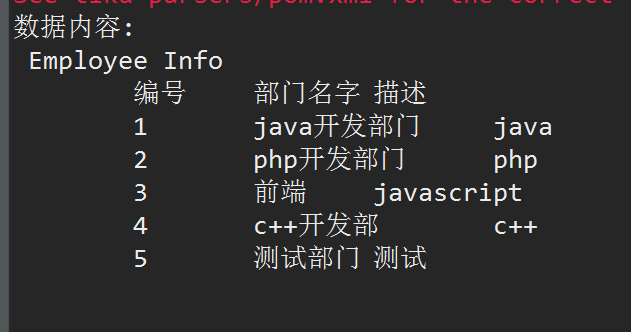
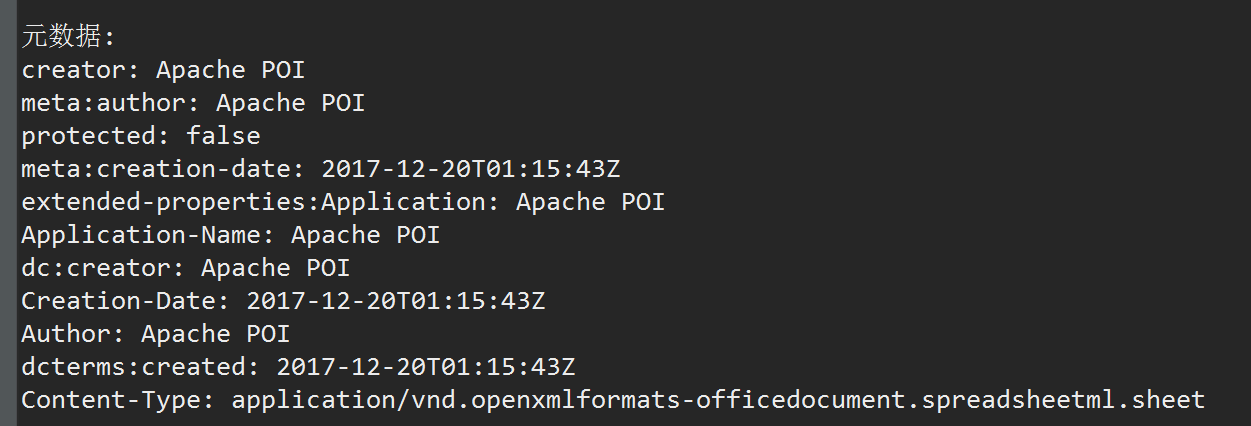
Excel数据:

读取数据:
装载自:http://blog.csdn.net/evan_qb/article/details/78856563















 1003
1003

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









