







论文总结: I can see what you see.
这是一篇2008年发表于Nature neuroscience上的短文,主要总结了关于重构的研究进展。论文重点介绍了当年日本团队的研究成果。即《Visual Image Reconstruction from Human Brain Activity using a Combination of Multiscale Local Image Decoders》。这个日本团队使用由对比度定义的图像作为刺激,在刺激的过程中收集早期视觉区V1、V2和V3的fMRI信号,然后构建一个重构模型来拟合这些数据,如图1。模型可以分为两个阶段,第一个阶段是使用体素反应的线性组合来预测刺激中一系列局部区域的对比度。这个技术能够很好地工作,因为早期视觉区域独立的体素能够可靠地反应空间感受野的对比度,这是有以往研究支持的。第二个阶段中,该模型和并这些局部区域的对比度为一张图像,并用这张图来表示被试所看到的图像。这个模型具有两个特色,第一个特色是采用局部图像重叠的方式来合成一张预测图像,这个方法可以看出不同局部图像对与合成图像的作用大小;第二个特色是使用了多尺度方法提高了重构性能,因为不同的体素包含了不同的尺度信息(例如,关联视觉感受掩外围的体素比感受野中心的体素包含的空间区域更大,因此外围体素具有更多的关于较大尺度的信息)。
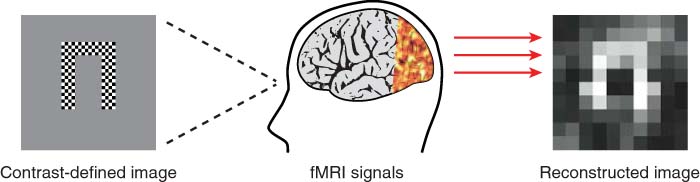
图1
可以看出,这个日本团队的研究是建立在视觉刺激和大脑活动的系统映射的研究基础之上的。而近年(2008年)来关于这方面的研究可以在图2中显示出来。虽然这个日本团队的研究成果令人印象深刻,但依然还有改进之处,一个是进一步提高重构精度,这可以在使用更高级的视觉功能区域或使用信噪比更高空间分辨率更高的fMRI技术实现。另一个改进之处是提高重构图像的空间分辨率,该研究目前只能预测10×10的人工网格图像,却不能预测分辨率更高的图像甚至自然图像。如果要重构自然图像,很可能需要研究新的解码技术并更好地理解自然图像的统计结构。
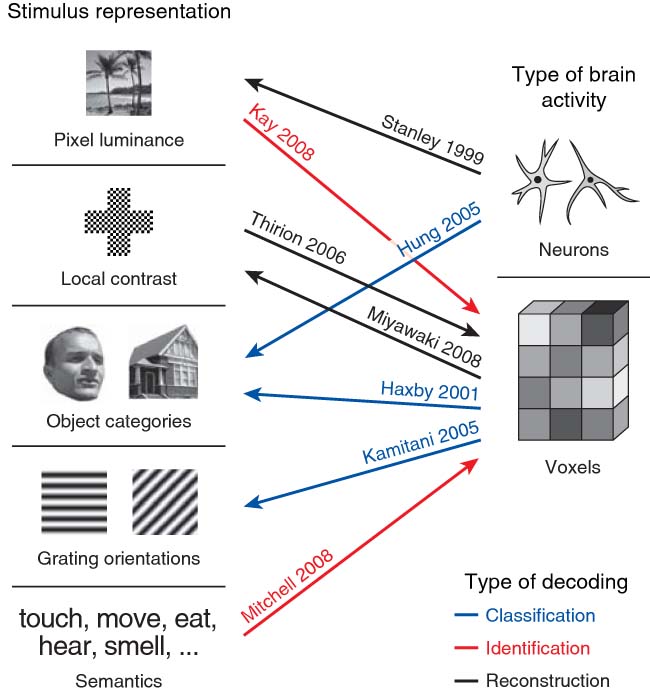
图2
大脑解码具有很多潜在的应用,例如使用运动皮质的神经活动控制假肢,视觉想象和梦的重构。如果视觉想象和做梦这些主观的知觉状态和由视觉刺激引发的知觉状态相似,那么使用日本团队的研究重构它们就是有可能的。最近的研究表明可能不久以后就可以重构人类的主观知觉了。
更多的细节,请参考原文。
文献原文地址:http://www.nature.com/neuro/journal/v12/n3/full/nn0309-245.html














 3万+
3万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









