







1.ZookeeperConsumer架构
ZookeeperConsumer类中consumer运行过程架构图:
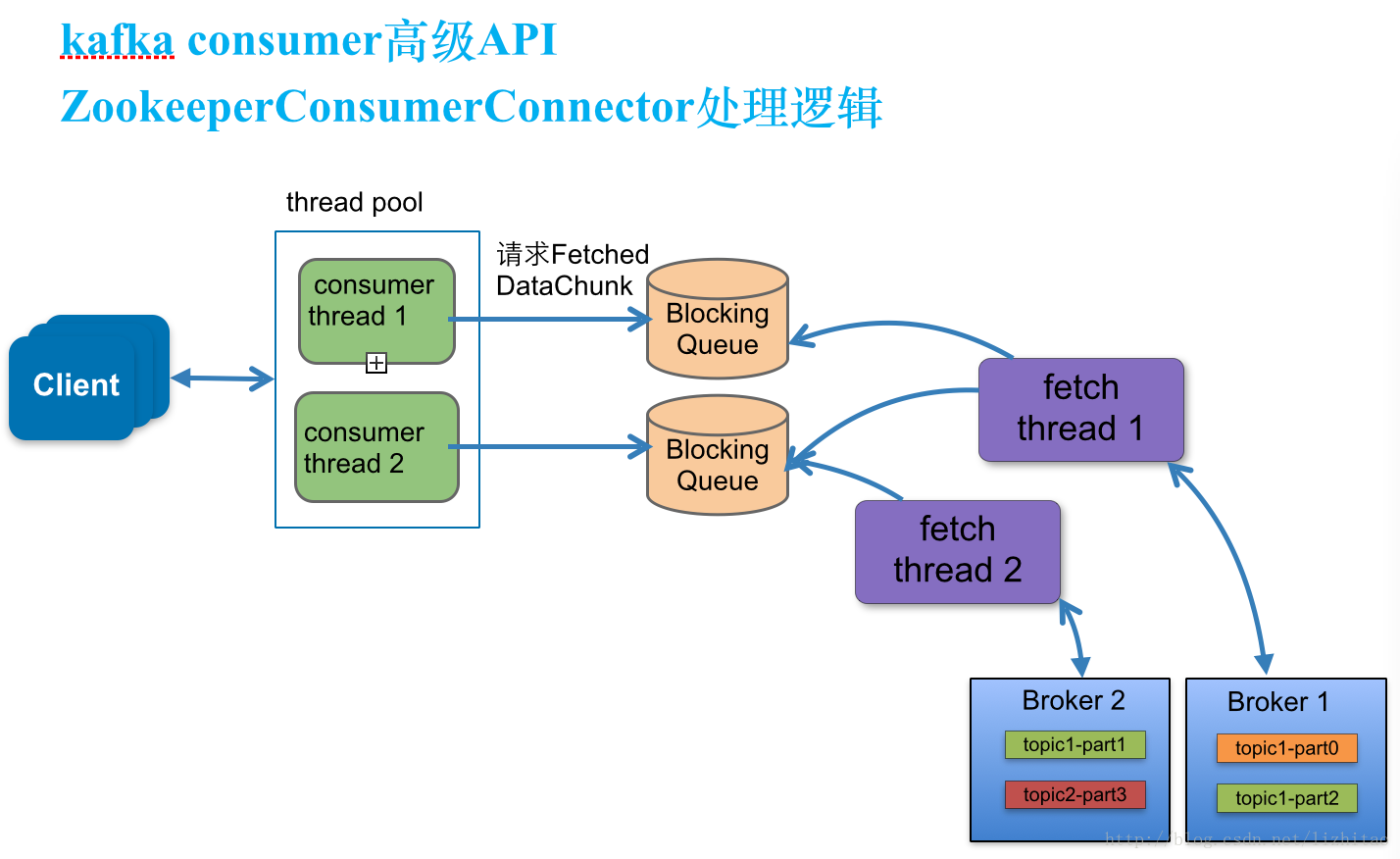
图1
过程分析:
2.消费者线程(consumer thread),队列,拉取线程(fetch thread)三者之间关系
每一个topic至少需要创建一个consumer thread,如果有多个partitions,则可以创建多个consumer thread线程,consumer thread>==partitions数量,否则会有consumer thread空闲。
部分代码示例如下:
ConsumerConnector consumer
consumer = kafka.consumer.Consumer.createJavaConsumerConnector(
createConsumerConfig());
Map<String, Integer> topicCountMap = new HashMap<String, Integer>();
topicCountMap.put("test-string-topic", new Integer(1)); //value表示consumer thread线程数量
Map<String, List<KafkaStream<byte[], byte[]>>> consumerMap = consumer.createMessageStreams(topicCountMap);
具体说明一下三者关系:
(1).topic的partitions分布规则
paritions是安装kafka brokerId有序分配的。
例如现在有三个node安装了kafka broker服务端程序,brokerId分别设置为1,2,3,现在准备一个topic为test-string-topic,并且分配12个partitons,此时partitions的kafka broker节点分布情况为 ,partitions索引编号为0,3,6,9等4个partitions在brokerId=1上,1,4,7,10在brokerId=2上,2,5,8,11在brokerId=3上。
创建consumer thread
consumer thread数量与BlockingQueue一一对应。
a.当consumer thread count=1时
此时有一个blockingQueue1,三个fetch thread线程,该topic分布在几个node上就有几个fetch thread,每个fetch thread会于kafka broker建立一个连接。3个fetch thread线程去拉取消息数据,最终放到blockingQueue1中,等待consumer thread来消费。
消费者线程,缓冲队列,partitions分布列表如下
| consumer线程 | Blocking Queue | partitions |
| consumer thread1 | blockingQueue1 | 0,1,2,3,4,5,6,7,8,9,10,11 |
fetch thread与partitions分布列表如下
| fetch线程 | partitions |
| fetch thread1 | 0,3,6,9 |
| fetch thread2 | 1,4,7,10 |
| fetch thread3 | 2,5,8,11 |
b. 当consumer thread count=2时
此时有consumerThread1和consumerThread2分别对应2个队列blockingQueue1,blockingQueue2,这2个消费者线程消费partitions依次为:0,1,2,3,4,5与6,7,8,9,10,11;消费者线程,缓冲队列,partitions分布列表如下
| consumer线程 | Blocking Queue | partitions |
| consumer thread1 | blockingQueue1 | 0,1,2,3,4,5 |
| consumer thread2 | blockingQueue2 | 6,7,8,9,10,11 |
fetch thread与partitions分布列表如下
| fetch线程 | partitions |
| fetch thread1 | 0,3,6,9 |
| fetch thread2 | 1,4,7,10 |
| fetch thread3 | 2,5,8,11 |
c. 当consumer thread count=4时
消费者线程,缓冲队列,partitions分布列表如下
| consumer线程 | Blocking Queue | partitions |
| consumer thread1 | blockingQueue1 | 0,1,2 |
| consumer thread2 | blockingQueue2 | 3,4,5 |
| consumer thread3 | blockingQueue3 | 6,7,8 |
| consumer thread4 | blockingQueue4 | 9,10,11 |
fetch thread与partitions分布列表如下
同上
同理当消费线程consumer thread count=n,都是安装上述分布规则来处理的。
3.consumer消息线程以及队列创建逻辑
运用ZookeeperConsumerConnector类创建多线程并行消费测试类,ConsumerGroupExample类初始化,调用createMessageStreams方法,实际是在consume方法处理的逻辑,创建KafkaStream,以及阻塞队列(LinkedBlockingQueue),KafkaStream与队列个数一一对应,消费者线程数量决定阻塞队列的个数。
registerConsumerInZK()方法:设置消费者组,注册消费者信息consumerIdString到zookeeper上。
consumerIdString产生规则部分代码如下:
kafka zookeeper注册模型结构或存储结构如下:
说明:目前把kafka中绝大部分存储模型都列表出来了,当前还有少量不常使用的,暂时还没有列举,后续会加上。
consumer初始化逻辑处理:
1.实例化并注册loadBalancerListener监听,ZKRebalancerListener监听consumerIdString状态变化
触发consumer reblance条件如下几个:
ZKRebalancerListener:当/kafka01/consumer/[consumer-group]/ids子节点变化时,会触发
ZKTopicPartitionChangeListener:当该topic的partitions发生变化时,会触发。
val topicPath = "/kafka01/brokers/topics" + "/" + "topic-1"
zkClient.subscribeDataChanges(topicPath, topicPartitionChangeListener)
原文:http://blog.csdn.net/lizhitao/article/details/38458631















 5205
5205

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









