







正则化
机器学习的问题中,过拟合是一个很常见的问题。过拟合指的是只能拟合训练数据,但不能很好地拟合不包含在训练数据中的其他数据的状态。机器学习的目标是提高泛化能力,即便是没有包含在训练数据里的未观测数据,也希望模型可以进行正确的识别。我们可以制作复杂的、表现力强的模型但是相应地,抑制过拟合的技巧也很重要。
发生过拟合的原因,主要有以下两个。
1、模型拥有大量参数、表现力强。 2、训练数据少。
权值衰减
权值衰减是一直以来经常被使用的一种抑制过拟合的方法。该方法通过 在学习的过程中对大的权重进行惩罚,来抑制过拟合。很多过拟合原本就是 因为权重参数取值过大才发生的。
神经网络的学习目的是减小损失函数的值。这时,例如为 损失函数加上权重的平方范数(L2范数)。这样一来,就可以抑制权重变大。 用符号表示的话,如果将权重记为W,L2范数的权值衰减就是 ,然 后将这个 加到损失函数上。这里,λ是控制正则化强度的超参数。λ 设置得越大,对大的权重施加的惩罚就越重。此外,开头的 是用于 将 的求导结果变成λW的调整用常量。对于所有权重,权值衰减方法都会为损失函数加上 。因此,在求权 重梯度的计算中,要为之前的误差反向传播法的结果加上正则化项的导数λW。
L2范数相当于各个元素的平方和。用数学式表示的话,假设有权重 W = (w1,w 2,…,wn),则L2范数可用计算出来。除了L2范数,还有L1范数、L∞范数等。L1范数是各个元素的绝对值之和,相当于|w1| + |w2| + …+ |wn|。L∞范数也称为 Max范数,相当于各个元素的绝对值中最大的那一个。
Dropout
Dropout是一种在学习的过程中随机删除神经元的方法。训练时,随机选出隐藏层的神经元,然后将其删除。被删除的神经元不再进行信号的传递, 如图所示。训练时,每传递一次数据,就会随机选择要删除的神经元。 然后,测试时,虽然会传递所有的神经元信号,但是对于各个神经元的输出, 要乘上训练时的删除比例后再输出。
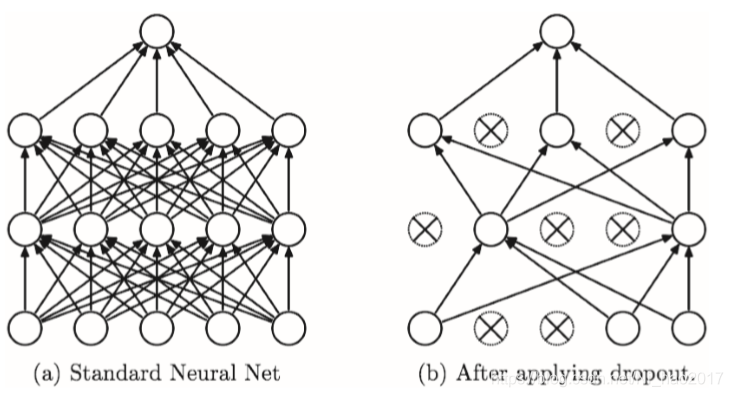
Dropout的概念图:左边是一般的神经网络,右边是应用了 Dropout的网络。Dropout通过随机选择并删除神经元,停止向前传递信号。
算法实现:
class Dropout:
def __init__(self, dropout_ratio=0.5):
self.dropout_ratio = dropout_ratio
self.mask = None
def forward(self, x, train_flg=True):
if train_flg:
self.mask = np.random.rand(*x.shape) > self.dropout_ratio
return x * self.mask
else:
return x * (1.0 - self.dropout_ratio)
def backward(self, dout):
return dout * self.mask














 3018
3018











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









