







目录
概述
资源管理对于数据库来说是非常重要的,它可以对不同的用户进行资源控制,来保证数据库对于物理资源的合理使用。
当前的ClickHouse系统的资源管理方面主要分为三个方面:
- 资源使用追踪机制;
- 资源隔离机制;
- 资源使用配额(Quota)机制。
接下来我将展开介绍一下ClickHouse在这三个方面的功能设计实现。
资源使用追踪机制
ClickHouse的资源使用都是从查询thread级别就开始进行追踪,主要的相关代码在 ThreadStatus 类中。每个查询线程都会有一个thread local的ThreadStatus对象,ThreadStatus对象中包含了对内存使用追踪的 MemoryTracker、profile cpu time的埋点对象 ProfileEvents、以及监控thread 热点线程栈的 QueryProfiler。
/** Encapsulates all per-thread info (ProfileEvents, MemoryTracker, query_id, query context, etc.).* The object must be created in thread function and destroyed in the same thread before the exit.* It is accessed through thread-local pointer.** This object should be used only via "CurrentThread", see CurrentThread.h*/class ThreadStatus : public boost::noncopyable{public:ThreadStatus();~ThreadStatus();/// Linux's PID (or TGID) (the same id is shown by ps util)const UInt64 thread_id = 0;/// Also called "nice" value. If it was changed to non-zero (when attaching query) - will be reset to zero when query is detached.Int32 os_thread_priority = 0;/// TODO: merge them into common entityProfileEvents::Counters performance_counters{VariableContext::Thread};MemoryTracker memory_tracker{VariableContext::Thread};// CPU and Real time query profilersstd::unique_ptr<QueryProfilerReal> query_profiler_real;std::unique_ptr<QueryProfilerCpu> query_profiler_cpu;......}
MemoryTracker
ClickHouse数据库中有很多不同level的MemoryTracker,包括线程级别、查询级别、用户级别、server级别,这些MemoryTracker会通过parent指针组织成一个树形结构,把内存申请释放信息层层反馈上去。
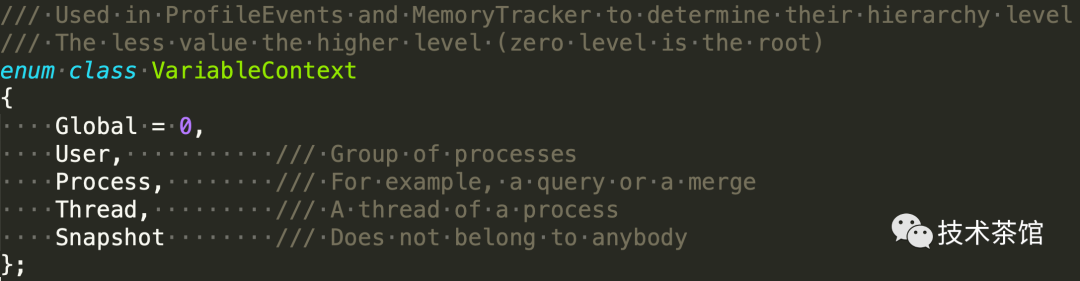
MemoryTrack中还有额外的峰值信息(peak)统计,内存上限检查,一旦某个查询线程的申请内存请求在上层(查询级别、用户级别、server级别)MemoryTracker遇到超过限制错误,查询线程就会抛出OOM(Out Of Memory)异常导致查询退出。同时查询线程的MemoryTracker每申请一定量的内存都会统计出当前的工作栈,非常方便排查内存OOM(Out Of Memory)的原因。
ClickHouse的MPP计算引擎中每个查询的主线程都会有一个ThreadGroup对象,每个MPP引擎worker线程在启动时必须要attach到ThreadGroup上,在线程退出时detach,这保证了整个资源追踪链路的完整传递。
void PipelineExecutor::executeImpl(size_t num_threads){......for (size_t i = 0; i < num_threads; ++i){threads.emplace_back([this, thread_group, thread_num = i, num_threads]{/// ThreadStatus thread_status;setThreadName("QueryPipelineEx");if (thread_group)CurrentThread::attachTo(thread_group);SCOPE_EXIT(if (thread_group)CurrentThread::detachQueryIfNotDetached(););......});}......}
如何把CurrentThread::MemoryTracker hook到系统的内存申请释放上去?ClickHouse首先是重载了c++的new_delete operator,其次针对需要使用malloc的一些场景封装了特殊的Allocator同步内存申请释放。
文件所在路径: src/Common/new_delete.cpp/// newvoid * operator new(std::size_t size){Memory::trackMemory(size);return Memory::newImpl(size);}void * operator new[](std::size_t size){Memory::trackMemory(size);return Memory::newImpl(size);}void * operator new(std::size_t size, const std::nothrow_t &) noexcept{if (likely(Memory::trackMemoryNoExcept(size)))return Memory::newNoExept(size);return nullptr;}void * operator new[](std::size_t size, const std::nothrow_t &) noexcept{if (likely(Memory::trackMemoryNoExcept(size)))return Memory::newNoExept(size);return nullptr;}/// delete/// C++17 std 21.6.2.1 (11)/// If a function without a size parameter is defined, the program should also define the corresponding function with a size parameter./// If a function with a size parameter is defined, the program shall also define the corresponding version without the size parameter./// cppreference:/// It's unspecified whether size-aware or size-unaware version is called when deleting objects of/// incomplete type and arrays of non-class and trivially-destructible class types.void operator delete(void * ptr) noexcept{Memory::untrackMemory(ptr);Memory::deleteImpl(ptr);}void operator delete[](void * ptr) noexcept{Memory::untrackMemory(ptr);Memory::deleteImpl(ptr);}void operator delete(void * ptr, std::size_t size) noexcept{Memory::untrackMemory(ptr, size);Memory::deleteSized(ptr, size);}void operator delete[](void * ptr, std::size_t size) noexcept{Memory::untrackMemory(ptr, size);Memory::deleteSized(ptr, size);}
Allocator相关的代码如下
文件所在路径: src/Common/Allocator.h/** Responsible for allocating / freeing memory. Used, for example, in PODArray, Arena.* Also used in hash tables.* The interface is different from std::allocator* - the presence of the method realloc, which for large chunks of memory uses mremap;* - passing the size into the `free` method;* - by the presence of the `alignment` argument;* - the possibility of zeroing memory (used in hash tables);* - random hint address for mmap* - mmap_threshold for using mmap less or more*/template <bool clear_memory_, bool mmap_populate>class Allocator{public:/// Allocate memory range.void * alloc(size_t size, size_t alignment = 0){checkSize(size);CurrentMemoryTracker::alloc(size);return allocNoTrack(size, alignment);}/// Free memory range.void free(void * buf, size_t size){checkSize(size);freeNoTrack(buf, size);CurrentMemoryTracker::free(size);}......}
为了解决内存追踪的性能问题,每个线程的内存申请释放会在thread local变量上进行积攒,最后以大块内存的形式同步给MemoryTracker。
/** Tracks memory consumption.* It throws an exception if amount of consumed memory become greater than certain limit.* The same memory tracker could be simultaneously used in different threads.*/class MemoryTracker{std::atomic<Int64> amount {0};std::atomic<Int64> peak {0};std::atomic<Int64> hard_limit {0};std::atomic<Int64> profiler_limit {0};Int64 profiler_step = 0;/// To test exception safety of calling code, memory tracker throws an exception on each memory allocation with specified probability.double fault_probability = 0;/// To randomly sample allocations and deallocations in trace_log.double sample_probability = 0;/// Singly-linked list. All information will be passed to subsequent memory trackers also (it allows to implement trackers hierarchy)./// In terms of tree nodes it is the list of parents. Lifetime of these trackers should "include" lifetime of current tracker.std::atomic<MemoryTracker *> parent {};/// You could specify custom metric to track memory usage.CurrentMetrics::Metric metric = CurrentMetrics::end();/// This description will be used as prefix into log messages (if isn't nullptr)std::atomic<const char *> description_ptr = nullptr;......}
ProfileEvents
ProfileEvents顾名思义,是监控系统的profile信息,覆盖的信息非常广,所有信息都是通过代码埋点进行收集统计。它的追踪链路和MemoryTracker一样,也是通过树状结构组织层层追踪。其中和cpu time相关的核心指标包括以下
/// Total (wall clock) time spent in processing (queries and other tasks) threads (not that this is a sum).extern const Event RealTimeMicroseconds;/// Total time spent in processing (queries and other tasks) threads executing CPU instructions in user space. This include time CPU pipeline was stalled due to cache misses, branch mispredictions, hyper-threading, etc.extern const Event UserTimeMicroseconds;/// Total time spent in processing (queries and other tasks) threads executing CPU instructions in OS kernel space. This include time CPU pipeline was stalled due to cache misses, branch mispredictions, hyper-threading, etc.extern const Event SystemTimeMicroseconds;extern const Event SoftPageFaults;extern const Event HardPageFaults;/// Total time a thread spent waiting for a result of IO operation, from the OS point of view. This is real IO that doesn't include page cache.extern const Event OSIOWaitMicroseconds;/// Total time a thread was ready for execution but waiting to be scheduled by OS, from the OS point of view.extern const Event OSCPUWaitMicroseconds;/// CPU time spent seen by OS. Does not include involuntary waits due to virtualization.extern const Event OSCPUVirtualTimeMicroseconds;/// Number of bytes read from disks or block devices. Doesn't include bytes read from page cache. May include excessive data due to block size, readahead, etc.extern const Event OSReadBytes;/// Number of bytes written to disks or block devices. Doesn't include bytes that are in page cache dirty pages. May not include data that was written by OS asynchronously.extern const Event OSWriteBytes;/// Number of bytes read from filesystem, including page cache.extern const Event OSReadChars;/// Number of bytes written to filesystem, including page cache.extern const Event OSWriteChars;
以上这些信息都是从linux系统中直接采集。采集没有固定的频率,系统在查询计算的过程中每处理完一个Block的数据就会依据距离上次采集的时间间隔决定是否采集最新数据。
#if defined(__linux__)#include <linux/taskstats.h>#elsestruct taskstats {};#endif/** Implement ProfileEvents with statistics about resource consumption of the current thread.*/namespace ProfileEvents{extern const Event RealTimeMicroseconds;extern const Event UserTimeMicroseconds;extern const Event SystemTimeMicroseconds;extern const Event SoftPageFaults;extern const Event HardPageFaults;extern const Event VoluntaryContextSwitches;extern const Event InvoluntaryContextSwitches;#if defined(__linux__)extern const Event OSIOWaitMicroseconds;extern const Event OSCPUWaitMicroseconds;extern const Event OSCPUVirtualTimeMicroseconds;extern const Event OSReadChars;extern const Event OSWriteChars;extern const Event OSReadBytes;extern const Event OSWriteBytes;extern const Event PerfCpuCycles;extern const Event PerfInstructions;extern const Event PerfCacheReferences;extern const Event PerfCacheMisses;extern const Event PerfBranchInstructions;extern const Event PerfBranchMisses;extern const Event PerfBusCycles;extern const Event PerfStalledCyclesFrontend;extern const Event PerfStalledCyclesBackend;extern const Event PerfRefCpuCycles;extern const Event PerfCpuClock;extern const Event PerfTaskClock;extern const Event PerfContextSwitches;extern const Event PerfCpuMigrations;extern const Event PerfAlignmentFaults;extern const Event PerfEmulationFaults;extern const Event PerfMinEnabledTime;extern const Event PerfMinEnabledRunningTime;extern const Event PerfDataTLBReferences;extern const Event PerfDataTLBMisses;extern const Event PerfInstructionTLBReferences;extern const Event PerfInstructionTLBMisses;extern const Event PerfLocalMemoryReferences;extern const Event PerfLocalMemoryMisses;#endif
QueryProfiler
QueryProfiler的核心功能是抓取查询线程的热点栈,ClickHouse通过对线程设置timer_create和自定义的signal_handler让worker线程定时收到SIGUSR信号量记录自己当前所处的栈,这种方法是可以抓到所有被lock block或者sleep的线程栈的。
除了以上三种线程级别的trace&profile机制,ClickHouse还有一套server级别的Metrics统计,也是通过代码埋点记录系统中所有Metrics的瞬时值。ClickHouse底层的这套trace&profile手段保障了用户可以很方便地从系统硬件层面去定位查询的性能瓶颈点或者OOM原因,所有的metrics, trace, profile信息都有对象的system_log系统表可以追溯历史。
举个例子
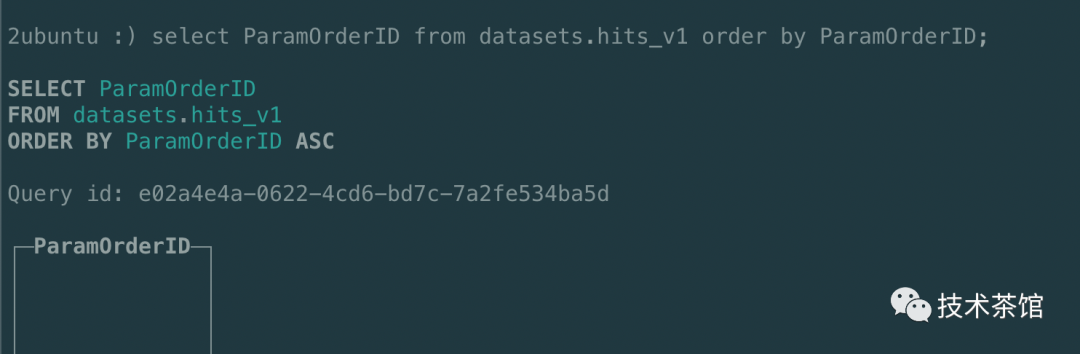
测试案例
SELECT ParamOrderIDFROM datasets.hits_v1ORDER BY ParamOrderID ASC
查看比较耗CPU的堆栈信息的语句
SELECTcount(),arrayStringConcat(arrayMap(x -> concat(demangle(addressToSymbol(x)), '\n ', addressToLine(x)), trace), '\n') AS symFROM system.trace_logWHERE query_id = 'e02a4e4a-0622-4cd6-bd7c-7a2fe534ba5d'GROUP BY traceORDER BY count() DESC \G
结果如下所示
Query id: e3290cf2-81ac-4745-8ae6-c1cd249a615dRow 1:──────count(): 1sym: DB::ColumnString::permute(DB::PODArray<unsigned long, 4096ul, Allocator<false, false>, 15ul, 16ul> const&, unsigned long) const/usr/lib/debug/usr/bin/clickhouseDB::sortBlock(DB::Block&, std::__1::vector<DB::SortColumnDescription, std::__1::allocator<DB::SortColumnDescription> > const&, unsigned long)/usr/lib/debug/usr/bin/clickhouseDB::PartialSortingTransform::transform(DB::Chunk&)/usr/lib/debug/usr/bin/clickhouseDB::ISimpleTransform::transform(DB::Chunk&, DB::Chunk&)/usr/lib/debug/usr/bin/clickhouseDB::ISimpleTransform::work()/usr/lib/debug/usr/bin/clickhousestd::__1::__function::__func<DB::PipelineExecutor::addJob(DB::ExecutingGraph::Node*)::$_0, std::__1::allocator<DB::PipelineExecutor::addJob(DB::ExecutingGraph::Node*)::$_0>, void ()>::operator()()/usr/lib/debug/usr/bin/clickhouseDB::PipelineExecutor::executeStepImpl(unsigned long, unsigned long, std::__1::atomic<bool>*)/usr/lib/debug/usr/bin/clickhousestd::__1::__function::__func<ThreadFromGlobalPool::ThreadFromGlobalPool<DB::PipelineExecutor::executeImpl(unsigned long)::$_4>(DB::PipelineExecutor::executeImpl(unsigned long)::$_4&&)::'lambda'(), std::__1::allocator<ThreadFromGlobalPool::ThreadFromGlobalPool<DB::PipelineExecutor::executeImpl(unsigned long)::$_4>(DB::PipelineExecutor::executeImpl(unsigned long)::$_4&&)::'lambda'()>, void ()>::operator()()/usr/lib/debug/usr/bin/clickhouseThreadPoolImpl<std::__1::thread>::worker(std::__1::__list_iterator<std::__1::thread, void*>)/usr/lib/debug/usr/bin/clickhousevoid* std::__1::__thread_proxy<std::__1::tuple<std::__1::unique_ptr<std::__1::__thread_struct, std::__1::default_delete<std::__1::__thread_struct> >, void ThreadPoolImpl<std::__1::thread>::scheduleImpl<void>(std::__1::function<void ()>, int, std::__1::optional<unsigned long>)::'lambda1'()> >(void*)/usr/lib/debug/usr/bin/clickhousestart_thread/usr/lib/x86_64-linux-gnu/libpthread-2.31.soclone/usr/lib/x86_64-linux-gnu/libc-2.31.soRow 2:──────count(): 1sym: DB::ColumnString::compareAt(unsigned long, unsigned long, DB::IColumn const&, int) const/usr/lib/debug/usr/bin/clickhouseDB::Chunk DB::MergeSorter::mergeImpl<DB::SortingHeap<DB::SimpleSortCursor> >(DB::SortingHeap<DB::SimpleSortCursor>&)/usr/lib/debug/usr/bin/clickhouseDB::MergeSorter::read()/usr/lib/debug/usr/bin/clickhouseDB::MergeSortingTransform::generate()/usr/lib/debug/usr/bin/clickhouseDB::SortingTransform::work()/usr/lib/debug/usr/bin/clickhousestd::__1::__function::__func<DB::PipelineExecutor::addJob(DB::ExecutingGraph::Node*)::$_0, std::__1::allocator<DB::PipelineExecutor::addJob(DB::ExecutingGraph::Node*)::$_0>, void ()>::operator()()/usr/lib/debug/usr/bin/clickhouseDB::PipelineExecutor::executeStepImpl(unsigned long, unsigned long, std::__1::atomic<bool>*)/usr/lib/debug/usr/bin/clickhousestd::__1::__function::__func<ThreadFromGlobalPool::ThreadFromGlobalPool<DB::PipelineExecutor::executeImpl(unsigned long)::$_4>(DB::PipelineExecutor::executeImpl(unsigned long)::$_4&&)::'lambda'(), std::__1::allocator<ThreadFromGlobalPool::ThreadFromGlobalPool<DB::PipelineExecutor::executeImpl(unsigned long)::$_4>(DB::PipelineExecutor::executeImpl(unsigned long)::$_4&&)::'lambda'()>, void ()>::operator()()/usr/lib/debug/usr/bin/clickhouseThreadPoolImpl<std::__1::thread>::worker(std::__1::__list_iterator<std::__1::thread, void*>)/usr/lib/debug/usr/bin/clickhousevoid* std::__1::__thread_proxy<std::__1::tuple<std::__1::unique_ptr<std::__1::__thread_struct, std::__1::default_delete<std::__1::__thread_struct> >, void ThreadPoolImpl<std::__1::thread>::scheduleImpl<void>(std::__1::function<void ()>, int, std::__1::optional<unsigned long>)::'lambda1'()> >(void*)/usr/lib/debug/usr/bin/clickhousestart_thread/usr/lib/x86_64-linux-gnu/libpthread-2.31.soclone/usr/lib/x86_64-linux-gnu/libc-2.31.so2 rows in set. Elapsed: 0.006 sec. Processed 1.15 thousand rows, 223.13 KB (204.52 thousand rows/s., 39.72 MB/s.)
报错说明

如果出现上面的报错信息,则在当前命令行执行下面的命令。然后再次执行SQL。
set allow_introspection_functions=1;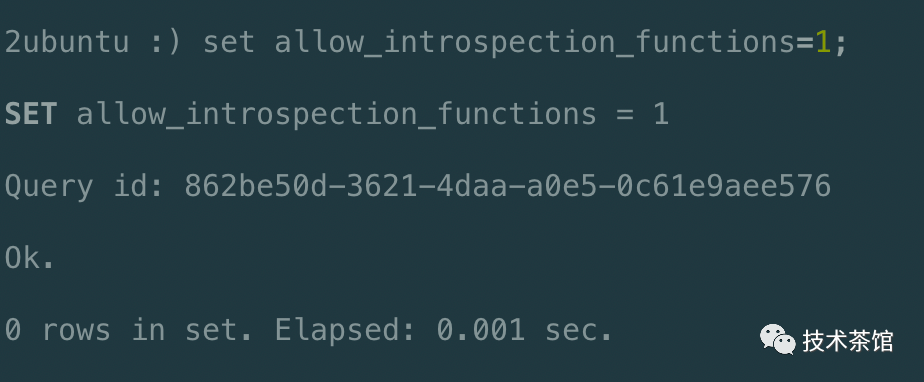
资源隔离机制
资源隔离需要关注的点包括内存、CPU、IO,目前ClickHouse在这三个方面都做了不同程度功能。
内存隔离
当前用户可以通过下面的属性去规划系统的内存资源使用做到用户级别的隔离。系统派发的子查询会突破用户的资源规划,所有的子查询都属于default用户,可能引起用户查询的内存超用。
- max_memory_usage(查询内存限制)
- max_memory_usage_for_user(用户的内存限制)
- max_memory_usage_for_all_queries(server的内存限制)
- max_concurrent_queries_for_user(用户并发限制)
- max_concurrent_queries(server并发限制)
CPU隔离
ClickHouse提供了Query级别的CPU优先级设置,当然也可以为不同用户的查询设置不同的优先级,有以下两种优先级参数:
/** Priority of the query.* 1 - the highest, higher value - lower priority;* 0 - do not use priorities.*/priority;/** Priority of the query.* 1 - the highest, higher value - lower priority;* 0 - do not use priorities.*/os_thread_priority;
IO隔离
ClickHouse目前在IO上没有做任何隔离限制,但是针对异步merge和查询都做了各自的IO限制,尽量避免IO打满。随着异步merge task数量增多,系统会开始限制后续单个merge task涉及到的Data Parts的disk size。在查询并行读取MergeTree data的时候,系统也会统计每个线程当前的IO吞吐,如果吞吐不达标则会反压读取线程,降低读取线程数缓解系统的IO压力,以上这些限制措施都是从局部来缓解问题的一个手段。
资源使用配额(Quota)机制
除了静态的资源隔离限制,ClickHouse内部还有一套允许在一段时间内限制资源使用情况。用户可以根据查询的用户或者Client IP对查询进行分组限流。限流和资源隔离不同,它是约束查询执行的配额,当前主要包括以下几种配额:
/** Quota for resources consumption for specific interval.* Used to limit resource usage by user.* Quota is applied "softly" - could be slightly exceed, because it is checked usually only on each block of processed data.* Accumulated values are not persisted and are lost on server restart.* Quota is local to server,* but for distributed queries, accumulated values for read rows and bytes* are collected from all participating servers and accumulated locally.*/struct Quota : public IAccessEntity{enum ResourceType{QUERIES, /// Number of queries.ERRORS, /// Number of queries with exceptions.RESULT_ROWS, /// Number of rows returned as result.RESULT_BYTES, /// Number of bytes returned as result.READ_ROWS, /// Number of rows read from tables.READ_BYTES, /// Number of bytes read from tables.EXECUTION_TIME, /// Total amount of query execution time in nanoseconds.MAX_RESOURCE_TYPE};......}
用户可以自定义规划自己的限流策略,防止系统的负载(IO、网络、CPU)被打爆,Quota限流可以认为是系统自我保护的手段。系统会根据查询的用户名、IP地址或者Quota Key Hint来为查询绑定对应的限流策略。计算引擎在算子之间传递Block时会检查当前Quota组内的流速是否过载,进而通过sleep查询线程来降低系统负载。
结论
本文主要讲述了关于ClickHouse数据库是如何管控物理资源的例如(内存资源、CPU资源、I/O资源等)和主要出现相关的资源问题我们如何通过系统表(system.trace_log)来进行问题定位。
参考资料
- https://zhuanlan.zhihu.com/p/340012422

分享大数据行业的一些前沿技术和手撕一些开源库的源代码
微信公众号名称:技术茶馆
微信公众号ID : Night_ZW














 869
869











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









