







聚类算法学习
接着上一个博客的学习,这篇对改进算法kernel K-means进行了整理记录。
**第二节 核空间聚类学习**
前言
物以类聚,人以群分。
以下为学习笔记整理
一、kernel是什么?
相信刚接触核空间思想的小伙伴,在搜索帖子学习的过程中,脑海里不止一次会想到“Kernel is a shit!!!”,但是但是但是,核空间太厉害了好吗,它确确实实是低维空间映射到高维的核武器。“kernel方法是一类用于模式分析或识别的算法,其最知名的使用是在支持向量机(SVM)。模式分析的一般任务是在一般类型的数据(例如序列,文本文档,点集,向量,图像等)中找到并研究一般类型的关系(例如聚类,排名,主成分,相关性,分类)图表等)。内核方法将数据映射到更高维的空间,希望在这个更高维的空间中,数据可以变得更容易分离或更好的结构化。对这种映射的形式也没有约束,这甚至可能导致无限维空间。然而,这种映射函数几乎不需要计算的,所以可以说成是在低维空间计算高维空间内积的一个工具。”------一段高大上的介绍。
下面通俗的讲一下什么是kernel:
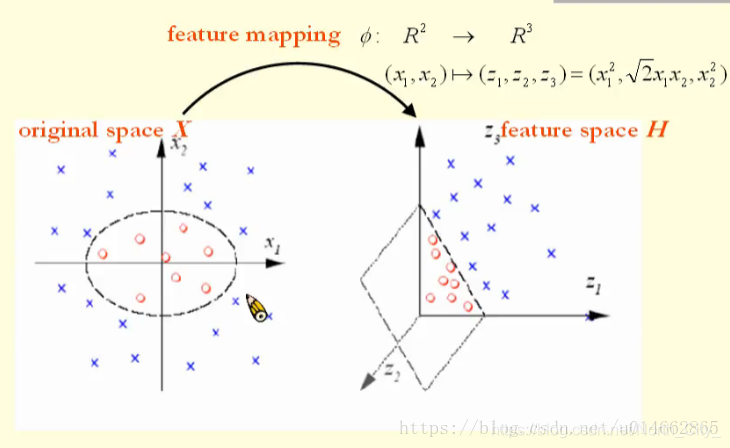
如图所示,左面的图为为原空间,右面的图为映射后的空间,从图中可以看出来,左面图不能线性分割,而右面的图要用一个超平面就可以分割开,原空间点左边为(x1,x2),经过某个函数或者某种计算方法,转化为特征空间上点坐标为(z1,z2,z3),所以说将低维空间转化到高维空间大概率可以对其中的点进行线性分割。
这样,我们第一步就理解了,就是在低维空间上的点通过某一函数转化为高维空间上,更有助于线性分类。
映射关系通常不好找,因此借助核函数来避免这个映射关系。上图所使用的核函数为

即内积平方,为什么对应的映射是这样呢,这里可以验证:

目前我还是存在一些困惑,有待进一步理解学习。
首先核函数的选取非常的困难,所举的例子由于数据的特殊性,较容易选择对应的核函数。
在机器学习中常用的核函数,一般有这么几类,也就是LibSVM中自带的这几类:
1)线性:

2)多项式:

3)Radial basis function(RBF径向基函数):

4)Sigmoid:

更多关于核函数的整理可以参见
https://www.cnblogs.com/infinite-h/p/10723853.html
更详细关于内积解释可以参见
https://www.cnblogs.com/damin1909/p/12955240.html
二、核聚类学习
1.问题描述
首先生成上述图片类似的线性不可分的人工数据集
更新了比前一个更方便的K-means算法(可以实现三维聚类和效果显示)
核函数分别实现了多项式核和高斯核
关于高斯核的解释强烈推荐这篇博客:
https://blog.csdn.net/weixin_42137700/article/details/86756365
2.代码实现
(完整源码可评论我分享)
首先生成人工数据集
def get_data():
fig = plt.figure()
x, y1 = make_circles(n_samples=100, factor=0.1, noise=0.1)
plt.scatter(x[:, 0], x[:, 1], marker=' 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章















 2万+
2万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









