






点击上方“中兴开发者社区”,关注我们
每天读一篇一线开发者原创好文
译者:XTH
英文原文:https://www.codeproject.com/Articles/1197167/Random-Forest-Python
随机森林介绍
随机森林是一种在集成学习中很受欢迎的算法,可用于分类和回归。这意味着随机森林中包括多种决策树,并将每个决策树结果的平均值作为随机森林的最终输出。决策树有一些缺点,比如训练集的过拟合导至很高的差异性,不过这在随机森林中已经可以通过Bagging(Bootstrap Aggregating)的帮助解决。因为随机森林实际上是由多种不同的决策树组成的,所以我们最好先了解一下决策树算法,然后再学习随机森林的相关知识。
决策树:
决策树用树形图来查看各元素之间的关系,以尽可能的做出最好的决定。举个例子,现在我们知道有一个网球运动员,他会根据不同的天气条件来选择是否进行比赛。于是现在我们想知道:在第15天的时候他是否会进行比赛呢?
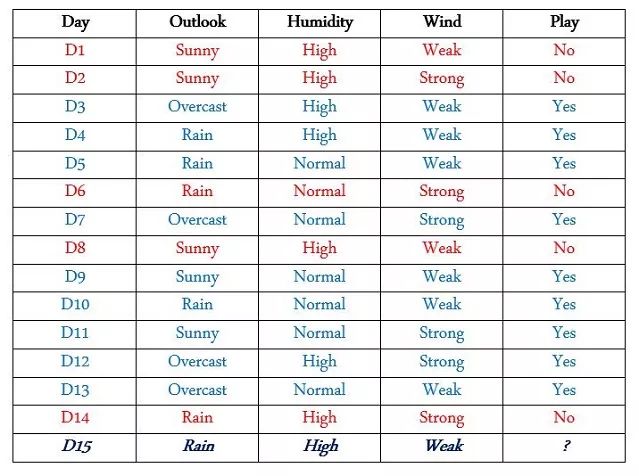
寻找“纯净”分支
这里有15天的数据,其中有9天他进行了比赛,5天没有比赛。你需要仔细观察表中提供的训练数据,其中包括多种特征及各不相同的特征值。我们需要找到哪些特征的特征值对结果的影响是相同的(在该特征值出现时,所有的PLAY = Yes/PLAY = No),或者换句话说,哪个值在表中始终与Play值的颜色相同。
“纯净”分支选择过程:
(Humidity = High For all days: (Play = Yes) | (Play = No)) No
(Humidity = Normal For all days: (Play = Yes) | (Play = No)) No
(Wind = Weak For all days: (Play = Yes) | (Play = No)) No
(Wind = Strong For all days: (Play = Yes) | (Play = No)) No
(Outlook = Rain For all days: (Play = Yes) | (Play = No)) No
(Outlook = Sunny For all days: (Play = Yes) | (Play = No)) No
(Outlook = Overcast For all days: (Play = Yes) | (Play = No)) Yes √
所以我们的运动员总是在"outlook = overcast"(D3,D7,D12,D13)时参加比赛,所以我们应该将"outlook"这个特征作为我们的根节点,并从其开始继续寻找分支。接下来我们寻找特征"Outlook = Sunny"(D1,D2,D8,D9,D11)条件下的“纯净”分支,查看"humidity"和"wind"的哪个特征值对应的play值全部相同,然后将其作为接下来的分支。通过观察,只有"Humidity = High"满足了条件。
1. Sunny: D1, D2, D8 & (Humidity = High) (Play = No)
2. Sunny: D9, D11 & (Humidity = Normal) (Play = Yes)
所以我们通过寻找“纯净”值,确定了下一个分支是"Humidity",接下来我们再来确定"Outlook = Rain"(D4,D5,D6,D10,D14)情况下的分支。
1. Rain: D4, D5, D10 & (Wind = Weak) (Play = Yes)
2. Rain: D6, D14 & (Wind = Strong) (Play = no)
由此,我们可以得到决策树:
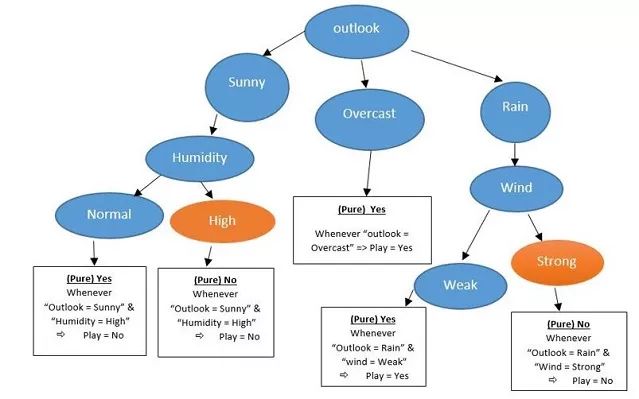
现在,我们可以清楚的看到图表和决策树的对比:
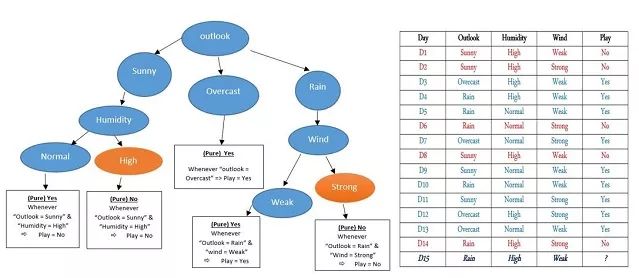
所以,为了推测D15他是否出战比赛,我们首先考虑"Outlook = Rain",下一步通过右侧分支,检查"Wind = Weak"的情况,于是我们到达了最底层,并得到了“Yes”的答案,他将会在D15出战比赛。
(补充:过拟合的定义;在下面的图中,正如你所看到的,我们在每个节点不断选择,直到得到“纯净”的结果。举个例子来说,在所有的叶子节点上,“Play”的值只能全部是yes或no。如果将一个“纯净”的数据集完美的分割,则通过决策树选择的准确率将达到100%。这意味着每一个叶节点只有一个特定值。越多的分割会会使我们得到更精确地结果和更大的决策树,因为在分割的过程中决策树会不断地增长。当决策树增大到与数据集相同时,就发生了“过拟合”。过拟合意味着算法只能适应特殊的数据,而不能应用到更多的测试数据。可通过对决策树进行剪枝以避免或解决过拟合问题,以某种方式将不太适合未来测试数据的分支移除,然后查看移除操作对结果产生的影响。)
选择过程:
[ If (“outlook = Sunny” & “Humidity = Normal” all of “Play = Yes”) ]
[ If (“outlook = Rain” & “wind = weak” all of “Play = Yes”) ]
D15: “Outlook = Rain” & “Humidity=High” & “Wind=Weak”
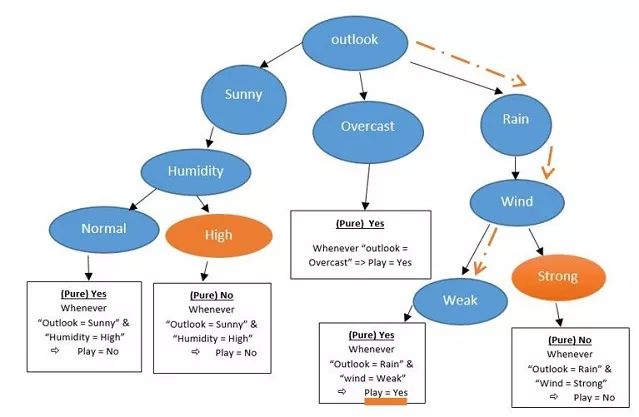
随机森林:
随机森林是一种集成学习方法,非常适合用于分类、回归等监督学习。在随机森林中,我们将数据集划分成多个小部分,然后将每部分作为独立的树,其结果对自身之外的其他树没有影响。随机森林获得训练数据并通过"Bagging = Bootstrap Aggregating"算法将其分割,该算法可通过避免过拟合和降低差异性来提高准确率。它一开始将数据集的60%划分为独立的决策树,30%作为重叠数据集。
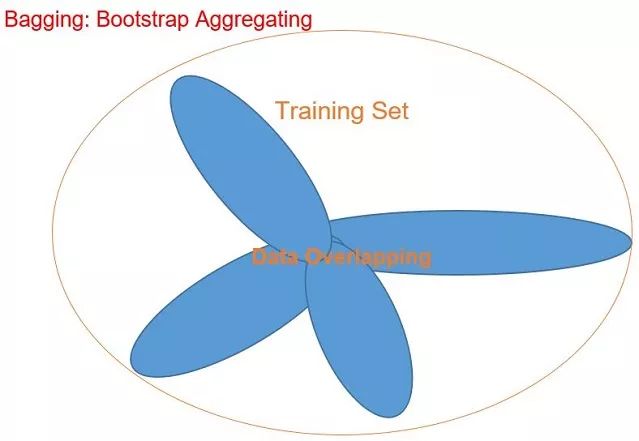
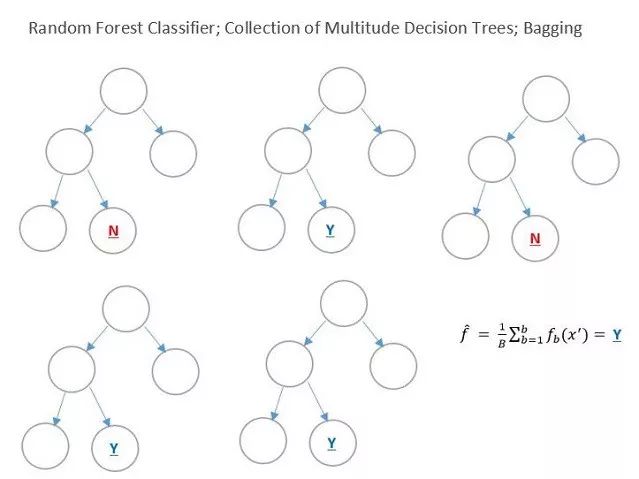
它将训练集分为不同的平衡决策树(60%用不同的数据,30%用重复数据),然后再计算每个决策树的结果,将其进行分解直至合适的情况(足以处理测试数据),在下面你可以看到,从决策树中我们得到了2个"NO"以及3个"YES",所以根据平均值,最后的答案是"YES"。
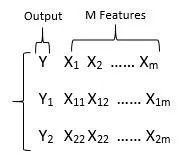
随机森林中的误差计算:有许多方案可以用来对随机森林进行优化。交叉验证可评估预测模型的结果对另外的独立测试数据实用性。如下图中的训练集,被分为输出"Y"与特征“X”:
Bootstrapping:
随机创建T树,每生成一个数据集随机抽样N次,生成T={T1,T2,T3,T4,T5}。
Out of Bag Error: 随机指定一个值,比如 j =(Xi,Yi),然后在所有树中查找j,会发现有些树不包含这个值(因为取样时没有包含全部数据),这些树的集合就是out-of-bag样例。
编程
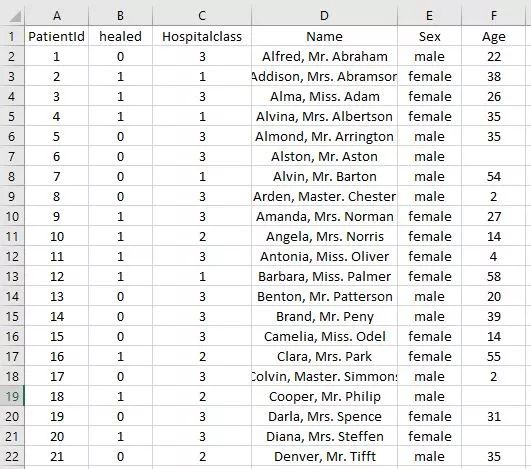
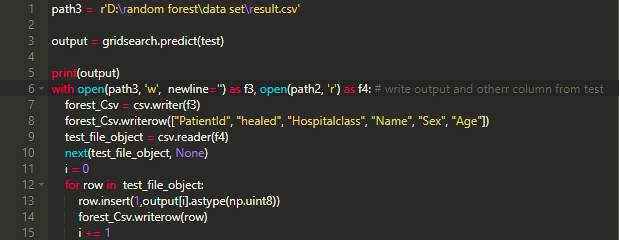
我已经准好备了训练用的数据集及测试集,以便通过python来练习随机森林。训练集是与病人相关的数据,其中我们可以知道他们的年龄、性别、医院等级、以及是否被治愈。在测试集中我们不知道病人是否被治愈,所以我们需要用随机森林来测试它,最后将结果写入result.csv,一个空的Excel文件。我将他们全部存储为csv格式,以便于使用python进行处理。
下载python:
如果你想轻松地使用舒适的IDE和专业的编辑器,而且省去复杂的库安装环节,你可以选择Anaconda&Spyder.
然后打开 Anaconda Navigator,选择"Spyder".
开始编程前,先了解一些要点:
-
python是面向对象的
-
动态类型
-
有丰富的库资源
-
易读性
-
python是大小写敏感的
-
缩进对python很重要
使用python实现随机森林
第一步:导入重要的库,比如numpy、csv for I/O、sklearn

第二步:训练测试准备,读取数据并存储到数组
(注意,根据你的存储路径修改程序里的path.)
 第三步:删除与"PatientID"相关的第一列,因为在我们的算法中不需要它
第三步:删除与"PatientID"相关的第一列,因为在我们的算法中不需要它
 第四步:手动调整数据,将性别信息用整数值(0/1)来表示
第四步:手动调整数据,将性别信息用整数值(0/1)来表示
 第五步:调整数据
第五步:调整数据
因为治愈的病人都与年龄有直接的关系,所在在年龄还有一缺失实的数据,所以通过了解病人情况,比如“他/她年龄多大?”或者“她/他采用哪种称呼?”又或者是“他们曾经在哪种等级的医院治疗过?”。因此,首先提取他们的称呼(比如Miss/Mrs),再以此为根据,获取其它缺失信息。
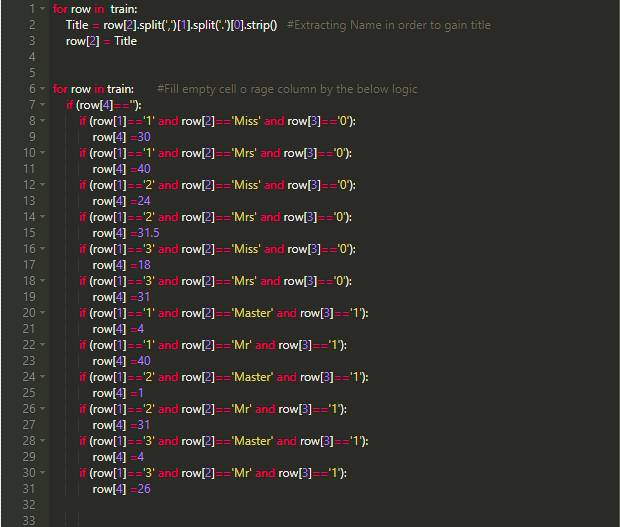
 第六步:删除无用的列
第六步:删除无用的列

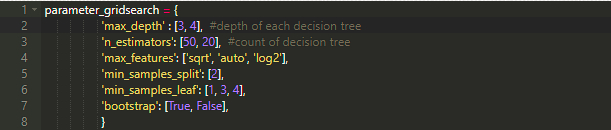
第七步:使用Grid Search对算法进行优化
max_depth:该参数决定了随机森林中每个决策树的最大深度,它从数组中获取不同的值,通过对最佳数值的考虑,我添加了两个值[3.4]
n_estimators : 该参数决定了应该创建多少决策树(为了更好的预测)
max_features : 在之前举例的训练集当中有四个特征值(1.Hospital Class, 2.name, 3.Sex, 4.Age),当我们想分隔节点时,需要选择对结果准确率有影响的一个或多个特征值。当该参数的值为auto时,意味着所有特征值都被选择。
min_samples_split : 该参数表示在创建新节点时有多少分支。
min_samples_leaf : 叶节点是没有孩子的最终节点,在每个决策树的最底部。
 第八步:随机森林分类
第八步:随机森林分类
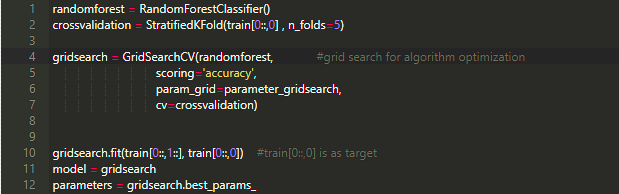 第九步:分数计算
第九步:分数计算
 第十步:将结果写入result.csv
第十步:将结果写入result.csv
总结
现在随机森林在数据科学家中非常受欢迎,它有良好的精确度及优化措施。它包括充足的用于数据导航的多种决策树。随机森林已经解决了决策树的过拟合问题。过拟合是因为在对数据集进行训练时为了尽可能完全的适应训练集,而导致的不能应用于其他训练数据的情况。随机森林使用 bagging 或 bootstrap aggregating 来将训练集分为不同的独立决策树,单独计算这些决策树的结果(不会互相影响),然后求平均值作为最终结果。最后,其对训练集中不同子集的决策树数量进行元估计的能力,可以提高预测的准确度以及更好的控制过拟合。














 2444
2444











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









