







#读取文件
temp = pd.read_excel(r'E:\ETL_soft\python\bool.xlsx')
#返回几行数据记录
temp[:6]
#新生成一列
temp['tip_pct']=temp['tip']/temp['total_bill']
temp[:6]
#根据分组选出最高的5个tip_pct值
def top(temp,n=5,column='tip_pct'):
return temp.sort_index(by=column)[-n:]
top(temp,n=6)
#根据分组选出最高的5个tip_pct值
def top(temp,n=5,column='tip_pct'):
return temp.sort_values(by=column)[:n]
top(temp,n=6)
#分组应用top函数
temp.groupby('smoker').apply(top)
#排序,按照某个字段
attr = temp.sort_values(by=['tip','total_bill'],ascending=False)
print(attr)
#创建字段,用eval函数
df.eval('new = 气温 + 湿度',inplace = True)
df
#查询对应的数据集
df.query('气温 > 30')
df
#多组分区
df.eval('''
new4 = 1 + 湿度
new5 = 气温 + 湿度
new6 = 气温/湿度''',inplace = True)
df
#删除对应的列名
df.drop(df.columns[x], axis=1, inplace=True)
#变量grouped是一个GroupBy对象,它实际上还没有进行任何计算,
#只是含有一些有关分组键df['values1']的中间数据而已,
#然后我们可以调用GroupBy的mean方法来计算分组平均值:
grouped = demos['values1'].groupby(demos['key1'])
grouped
grouped.mean()
#values1值和平均值按照key1,key2进行分组计算
means = demos['values1'].groupby([demos['key1'], demos['key2']]).mean()
means
#通过两个键对数据进行了分组,得到的Series具有一个层次化索引(由唯一的键对组成):
means.unstack()
#分组键中的任何缺失值都会被排除在结果之外
demos.groupby(['key1', 'key2']).size()
#遍历成字段
for name, group in demos.groupby('key1'):
print(name)
print(group)#制造随机数
frame=pd.DataFrame({'data1':np.random.randn(1000),
'data2': np.random.randn(1000)})
#frame[:5]
frame.head()
#分区分桶
#长度相等的桶:区间大小相等 cut
#大小相等的桶:数据点数量相等qcut
#将数据frame数据表中字段为data1切分成4等分,传给了factor
factor=pd.cut(frame.data1,4)
#返回的是对应的数据在哪个区间
factor[:10]
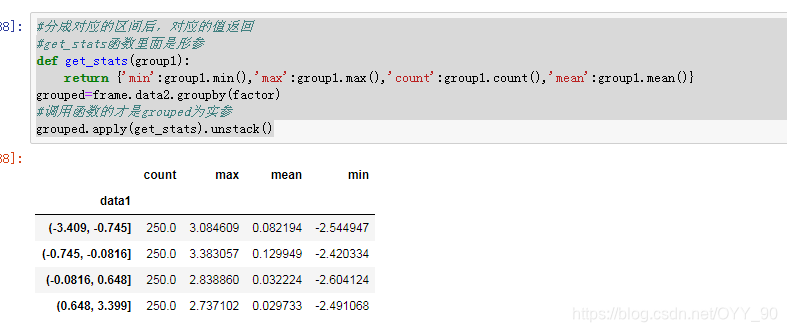
#分成对应的区间后,对应的值返回
#get_stats函数里面是形参
def get_stats(group1):
return {'min':group1.min(),'max':group1.max(),'count':group1.count(),'mean':group1.mean()}
grouped=frame.data2.groupby(factor)
#调用函数的才是grouped为实参
grouped.apply(get_stats).unstack()
factor=pd.qcut(frame.data1,4)
factor[:10]
grouping=pd.qcut(frame.data1,10,labels=False)#label=false即可只获取分位数的编号
grouped=frame.data2.groupby(grouping)
grouped.apply(get_stats).unstack()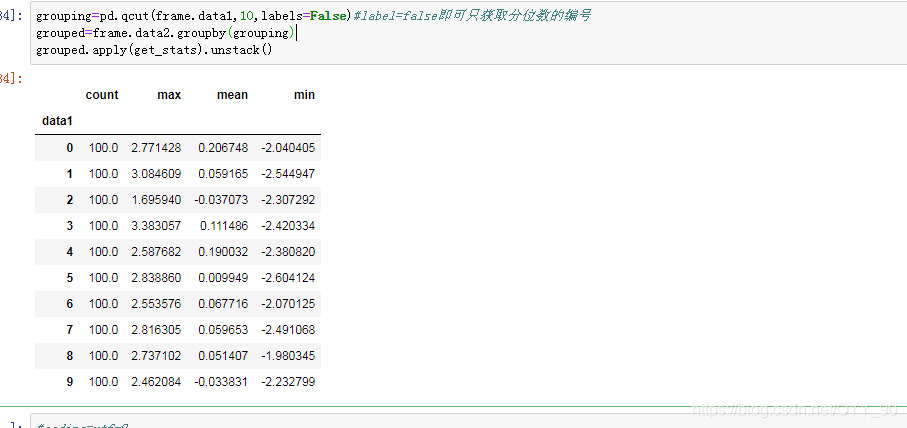














 3116
3116











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









