







Version-info list
- [v1] Going Deeper with Convolutions, 6.67% test error, http://arxiv.org/abs/1409.4842
- [v2] Batch Normalization: Accelerating Deep Network Training by Reducing Internal Covariate Shift, 4.8% test error, http://arxiv.org/abs/1502.03167
- [v3] Rethinking the Inception Architecture for Computer Vision, 3.5% test error, http://arxiv.org/abs/1512.00567
- [v4] Inception-v4, Inception-ResNet and the Impact of Residual Connections on Learning, 3.08% test error, http://arxiv.org/abs/1602.07261
Version-details
-
Inception-v1(22-layers)


Figure 1. Inception module


Figure 2. Inception-v1
-
Inception-v2(22-layers)
与Inception-v1相比,Inception-v2进行了如下的变化:
- 将所有的inception-module中的5x5的卷积操作用两个(串联)3x3的卷积代替;
- 卷积操作之后加入了BatchNormalization
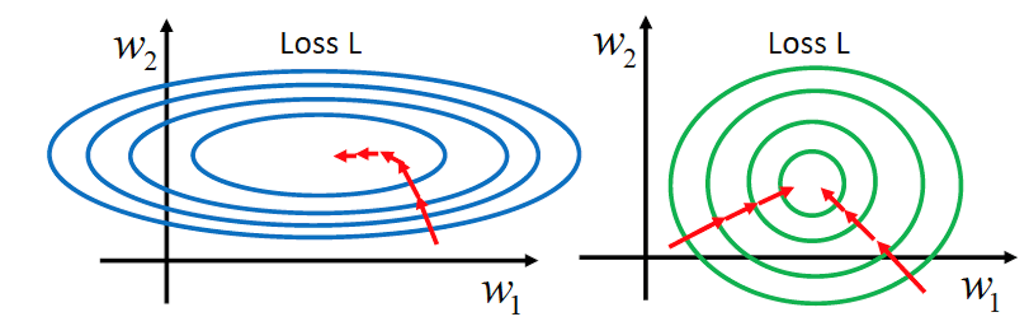
Figure 3. distribution without/with BN
Advantage of BN:
- Fix the distribution of X over time
- High learning rate can be used
-
Inception-v3(42-layers)
Inception-v3主要目的在于:1.减少网络参数、2.computational efficiency。文章给出了4条设计网络的建议:
- Avoid representational bottlenecks[不同的module之间,feature-dimension变化应该缓慢一些]
- Higher dimensional representations are easier to process locally within a network[在高维特征上处理局部信息更容易]
- Spatial aggregation can be done over lower dimensional embeddings[Yahoo]
- Balance the width and depth of the network
基于以上的四条原则,作者设计了如图4所示的三种不同的module,将他们应用在网络的不同阶段。

Figure 4. different Inception-module
网络结构:

















 792
792

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











