







终于考完试了,现在开始干活!
网站链接
Week 1
1.1 Train / Dev / Test sets
本节介绍train/dev/test sets,训练集、开发集(交叉验证集)、测试集
获得更好的参数要多做几次右图的圈圈:

之前数据不多的时代,分割比率是73开或者622开,现在只要1%左右就行了:
如果你有100万个样本 而只需要1万个用作开发集 1万个用作测试集 那么1万个只是100万个的百分之一 所以你的比例就是98/1/1% 我还看见过一些应用 这些应用中样本可能多于100万个 分割比率可能会变成99.5/0.25/0.25% 或者开发集占0.4% 测试集占0.1%
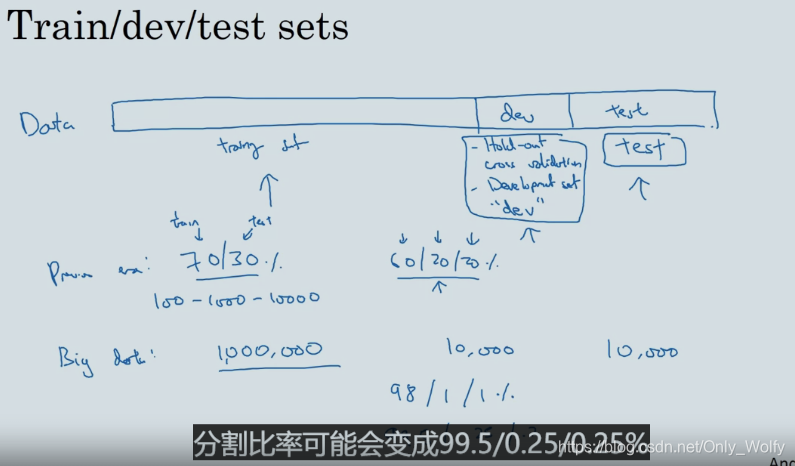
- 通常分为训练集、开发集(交叉验证集)和测试集,如果是只有两个的话,因为有不同的讲法,可能会把开发集讲成测试集。如果不需要无偏估计的话,可以不要测试集,当然通常还是分开三个集比较好。无偏估计以后会讲。
- 还有就是训练集与另外两个集针对的样例一定要对应。不然就会像打靶一样,训练的是a靶子,测试要求的却是b靶子,下面在网页上爬取的猫猫图和用户发送的猫猫图中辨认猫猫,其实是有偏差的,应该三个集的出处都一致,都是网页上的猫猫图或者是app上的猫猫图。

1.2 Bias / Variance
本节介绍偏差(bias)和方差(variancee):
训练出来的算法要避免高偏差和高方差,二维方便可视化,但是高纬度就不行了
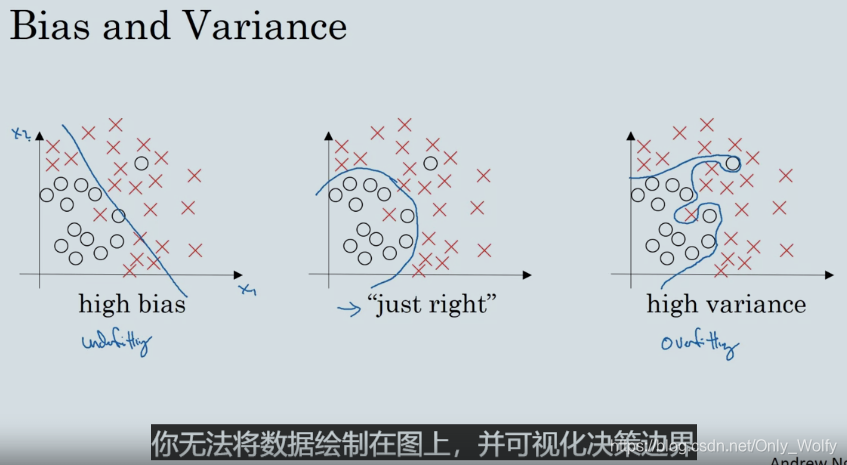
有无偏差和方差的4种情况。。。不知道怎么总结,大概就图那样吧,然后提到了贝叶斯误差(理想误差),如果贝叶斯误差非常高,表示人和任何系统都不能分类,这样需要用别的手段去分析,这里的判断是基于贝叶斯误差比较低且你的训练集和开发集都来自同一分布的假设下。

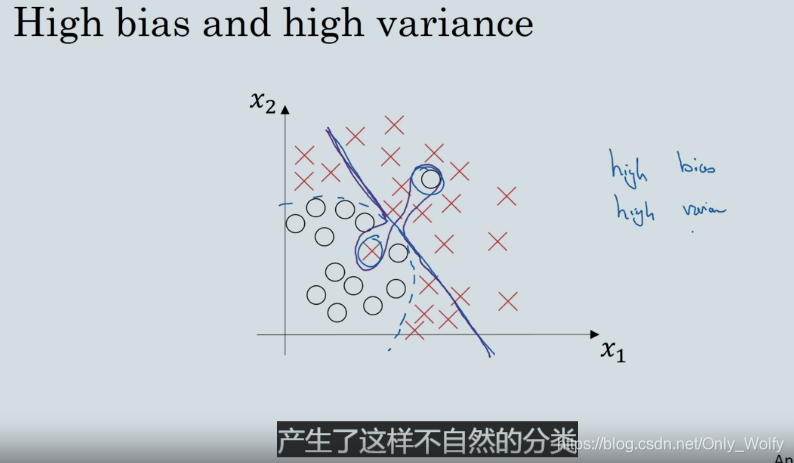
最后一个问题:高方差和高偏差的曲线长什么样?下图紫线就是高方差和高偏差的曲线,然后直线部分是高偏差,曲线部分是高方差,因为对于那两个点过拟合了。
1.3 Basic Recipe for Machine Learning
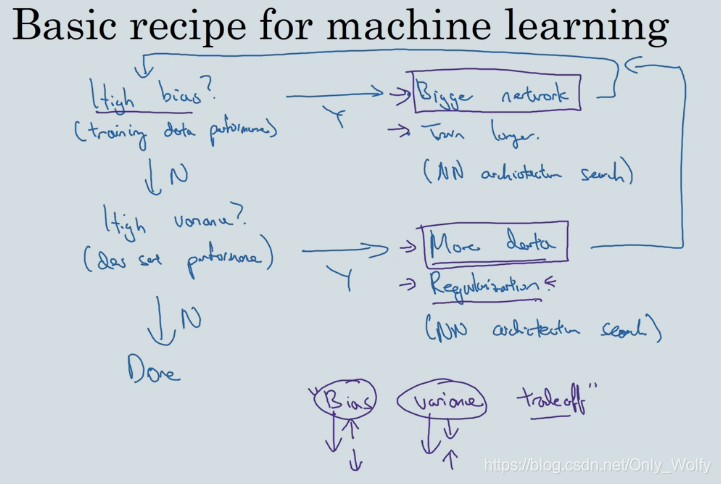
本节介绍如何防止过拟合和欠拟合,图上有对应的解决方案
High bias :模型连训练集都不能很好拟合
High variance : 不能拟合 dev set (开发集(交叉验证集))
下面是防止高偏差和高方差的流程,正则化(regularization)下面会讲。
在深度学习和大数据之前,高方差和高偏差会顾此失彼,现在不会了,正则化用于减小方差,是个很有用的办法 在正则化中存在一点点偏差与方差间的权衡 它可能会使偏差增加一点点 但在你的网络足够巨大时 增加得通常不会很多
1.4 Regularization
本节介绍正则化,因为解决过拟合(high variance)用“more data”的方法的话,有时候数据比较难找或者昂贵,这时候就需要用正则化。
加上了regularization的 J(w,b) :
其中后面那个
∣
∣
w
∣
∣
2
2
||w||^2_2
∣∣w∣∣22,上标2是平方的也是,下标2是L2范数的意思,因为lambda与Python的关键字冲突,所以用lambd代替

在神经网络中的写法:
然后因为一些线性代数中的神秘原因,那个w矩阵不叫L2范数,而叫矩阵的弗罗贝尼乌斯范数,使用角标F标记,
d
w
dw
dw变为原来的
d
w
dw
dw再加上
λ
m
w
[
l
]
\frac{λ}{m}w^{[l]}
mλw[l],其他不变,代入到
w
[
l
]
=
w
[
l
]
−
α
d
w
[
l
]
w^{[l]}=w^{[l]}-αdw^{[l]}
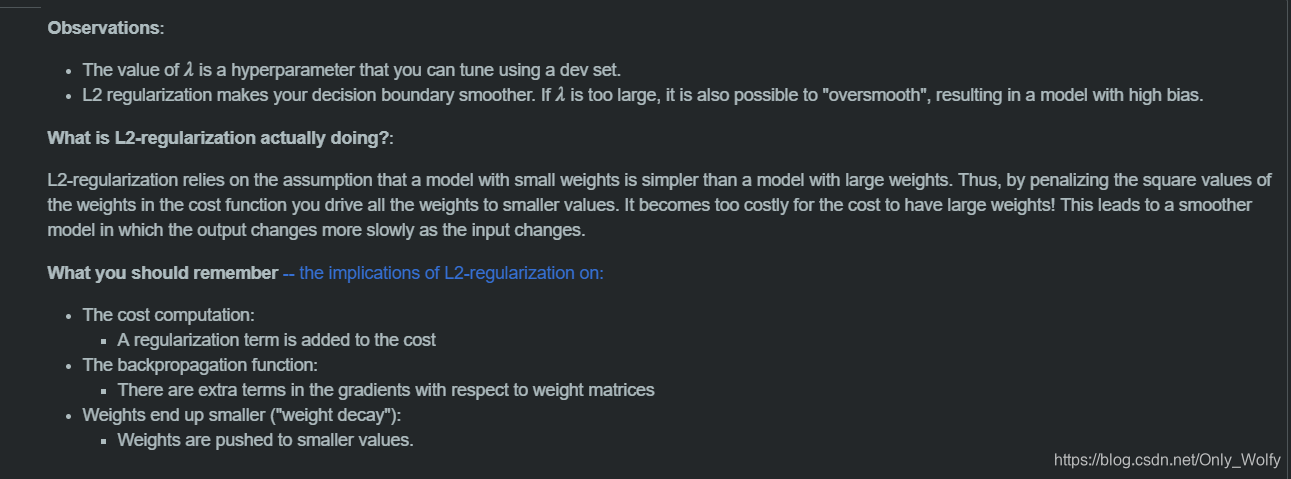
w[l]=w[l]−αdw[l]就是下面绿绿的公式,因此,无论矩阵w[l]是多少你都会让它减掉自己小小的一部分(变得稍小一点),所以L2范数正则化又被称为权重衰减

1.5 Why regularization reduces overfitting?
下面介绍为啥正则化可以减少过拟合:
正则化是在J中加入的额外的惩罚项是用来防止权重过大:如果调整λ很大的话,相当于w会很小,接近于0,则有些点会对神经网络的影响很小,相当于被x掉了(左上角),这样的话,整个神经网络就会被削减,有点像深层的逻辑回归,这样的话,会从 high variance 变为 high bias ,然后肯定会有适合的λ使得 high variance 变为 just right 的图。

另一个例子是在tanh激活函数中,λ增加,则w减小,则z也会变小,所以tanh激活函数变成了类似线性的函数,然后之前知道了线性函数的堆砌也还是线性函数,所以就不能拟合那些很复杂的决策函数
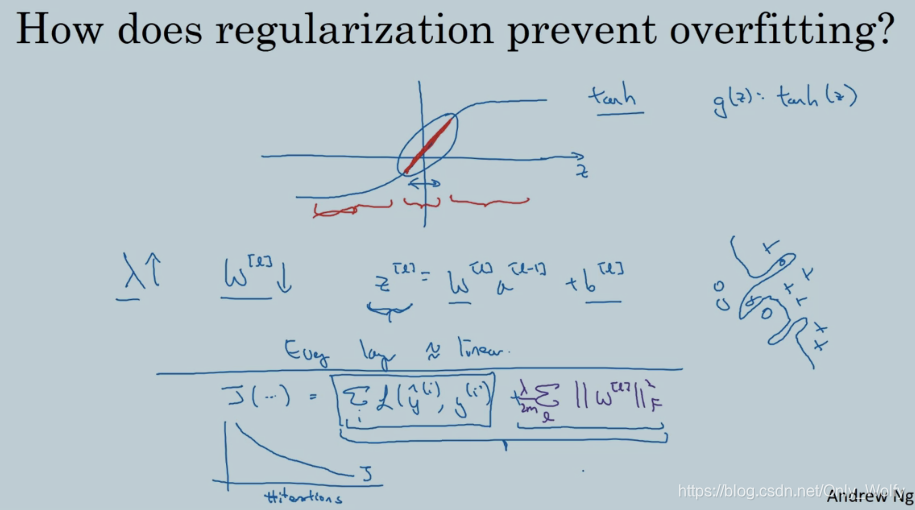
最后 如果你使用梯度下降方法 调试程序的一个步骤就是画出代价函数 J 关于 梯度下降的迭代次数的图像 可以看到的是每次迭代后代价函数 J 都会单调递减 。如果你实现了正则化部分 那么请记住 J 现在有了新的定义 如果你仍然使用原来定义的 J 就像这里的第一项 你可能看不到单调递减的函数图像 所以为了调试梯度下降程序请确保你画的图像 是利用这个新定义的J函数 它包含了这里第二个项
1.6 Dropout Regularization
除了L2正则化 另一种非常强大的正则化技术是 随机失活正则化(丢弃法 dropout) :
总体思路就是先建好一个神经网络,然后对于不同的训练样例(examples),随机保留和消除节点,这个跟前几天看到的何凯明的随机生成神经网络有点像,可能从中有些启发吧。
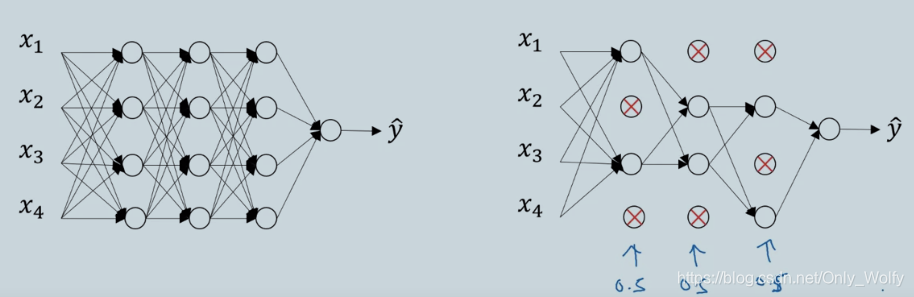
随机失活中,通常用反向随机失活(inverted dropout),代码如下:
先定义3层神经网络,然后定义keep.prob是指保留的概率,这里是0.8,就是保留丢失82开。然后d3就是保存选中的点的位置,点乘上a3就得出哪些点保留下来。
这里a3/=keep.prob是用来放大a3的,因为它能提供你所需要的大约20%的校正值,这样a3的期望值就不会被改变 。

注意在测试的时候(应该是指predict的时候吧?),你不需要 drop out 来让一些隐藏单元消失。因为你并不想让你的输出也是随机的,在测试阶段也使用随机失活算法,只会为预测增加噪声。(理论上来说可以用不同的随机失活的神经网络进行多次预测取并平均值,但是这个方法运算效率不高而且会得到几乎相同的预测结果)
而上一页的除以keep.prob运算就是使激活函数的期望输出也不会改变,测试过程可以不用加入额外的缩放操作。

1.7 Understanding Dropout
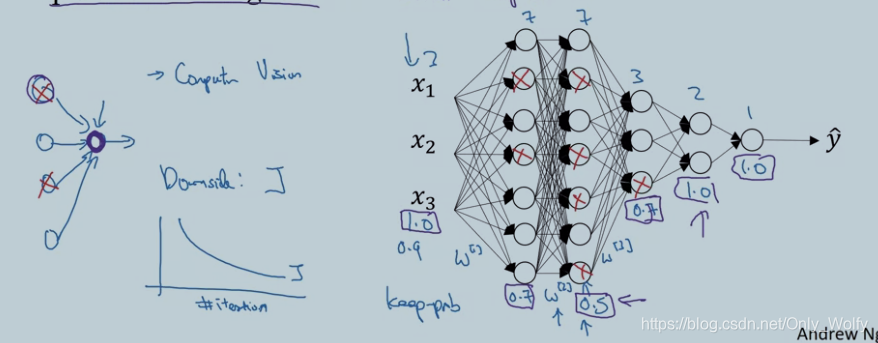
随机失活 (dropout) 这种从网络中随机敲除神经元的做法看起来有些疯狂 但是为什么用于正则化时它的表现这么好呢?上一节是说在更小的神经网络中计算而使用更小的神经网络就好像具有正则化效果。
我们从单一神经元的角度来看这个问题 比如这个点 它的任务就是 利用这些输入单元生成一个有意义的输出 而如果使用了dropout 这些输入会被随机的丢弃 有的时候这两个神经元会被丢弃 有的时候另一个神经元会被丢弃 因此 这就意味着 我用紫色圈起来的这个 它不能依赖于任何一个特征 因为每个都可能被随机丢弃 或者说它的每一个输入都可能随机失活 所以在特定的时候 【就不愿把所有的赌注 只放在这一个输入神经元上】 对吗? 因为任何一个输入都可能失活 所以我们也不愿把太多的权重放在某一个上 因此这个神经元将会更积极的使用这种方式 对于每个输入都给一个比较小的权重 而泛化这些权值 将有利于压缩这些权重的平方泛数 (平方和) 和L2正则化类似 使用dropout有助于 收缩权值以及防止过拟合 但是 更准确的来说 dropout应该被看作一种自适应形式而不是正则化 L2正则对不同权值的惩罚方式有所不同 这取决于被激活的乘方大小 总之来说 dropout能起到和L2正则类似的效果 只是针对不同的情况L2正则可以有少许的变化 所以适用面更广

运行的时候每一层的留存率要设置,在担心会发生过拟合的层留存率要减少,不太担心过拟合的层留存率可以设定更高。一般输入和输出留存率是1.0,0.9也行,但一般不会是减半。
drop out有些缺点:
- 在交叉验证 (网格) 搜索时 会有更多的超参数 (运行会更费时) 另一个选择就是对一些层使用dropout (留存率相同) 而另一些不使用 这样的话 就只有一个超参数了
- 让代价函数J 变得不那么明确 因为每一次迭代 都有一些神经元随机失活 所以当你去检验梯度下降算法表现的时候 你会发现很难确定代价函数是否已经定义的足够好 (随着迭代 值不断变小) 这是因为你对代价函数J 的定义不明确 或者难以计算 因此就不能用绘图的方法去调试错误了 像这样的图 通常这个时候我会关闭dropout 把留存率设为1 然后再运行代码并确保代价函数J 是单调递减的 最后再打开dropout并期待 使用dropout的时候没有引入别的错误 我想,你需要使用其他方法 而不是类似这种画图的方法去确保你的代码 在使用dropout后梯度下降算法依然有效
另外注意只有过拟合的情况下才需要正则化。在CV领域,因为输入层向量维度非常大,因为要包含每个像素点的值,几乎不可能有足够的数据,所以通常要dropout,但是不是什么领域都需要dropout,它是一种正则化技术,目的是防止过拟合,所以除非算法已经过拟合,是不会考虑使用dropout的。
(PS具体操作看编程作业2)
1.8 Other regularization methods
另外一些规则化的方法:
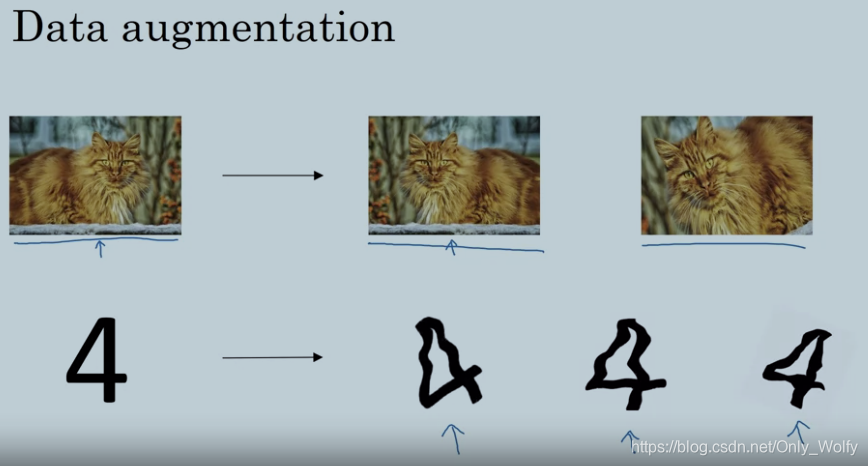
第一个增加数据,如果拿不到更多的数据,那么在有限的数据中,可以通过各种细微地调整(下面的4很扭曲但只是用来夸张而已)来增加数据量,这样处理,从图片获得的信息会少了,但也是可行的。
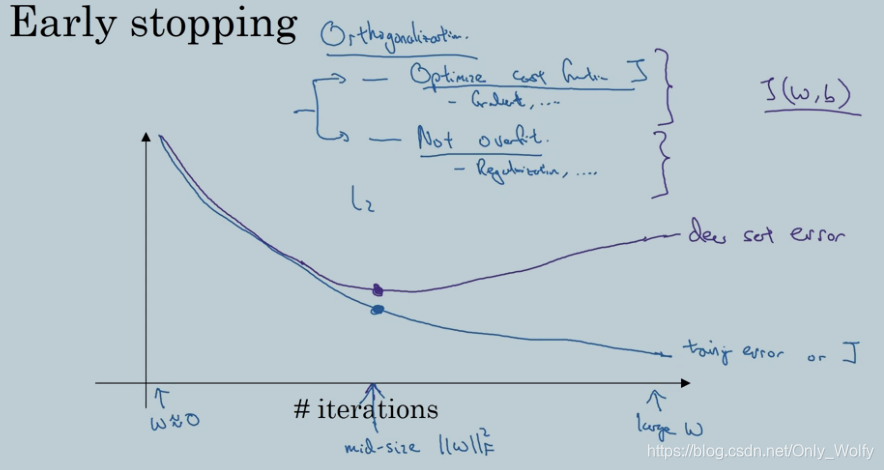
一个是early stopping,在 dev error 开始升高的附近结束训练,即选取的算法是开发集误差最小的。有个正交化(orthogonalization)的概念,即一个时间只考虑一个任务,比如让J(w,b)尽可能小,让神经网络不overfit,但是early stopping把两个任务结合了,无法分开解决这两个问题。
可以替代early stopping的是L2正则化,你可以尽可能久的训练神经网络,这样可以让超参数的搜索空间更易分解,也因此更易搜索,但这么做的缺点是你可能必须尝试大量的正则化参数λ的值,这使得计算代价很高。
而early stopping的优势是 只要运行一次梯度下降过程 你需要尝试小w值 中等w值和大w值 而不用尝试L2正则化中 超参数λ的一大堆值。
如果计算能力足够,L2正则化会更好。
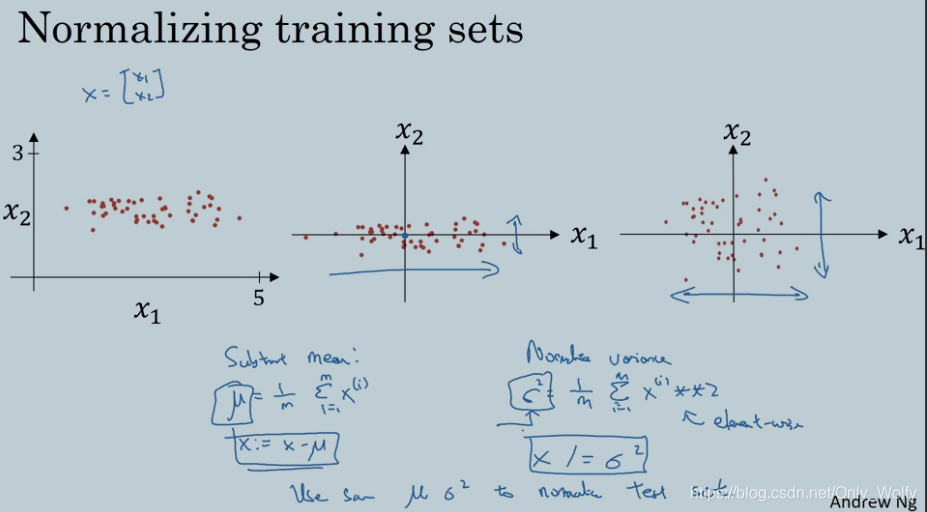
1.9 Normalizing inputs
归一化,公式都在下面了,中间是X-μ后的图形,右边是X/σ^2的图形
什么时候要用到归一化,一个是输入的
x
1
,
x
2
,
x
3
.
.
.
x_1,x_2,x_3...
x1,x2,x3... 之间差距比较大,比如 0~1,1~1000,下图是归一化前后 J 函数到达最小值的点的路线,可以看出归一化前弯弯曲曲走很多路,且它的 learning rate 要很小才能走到最优点,但右图可以用更长的步长。
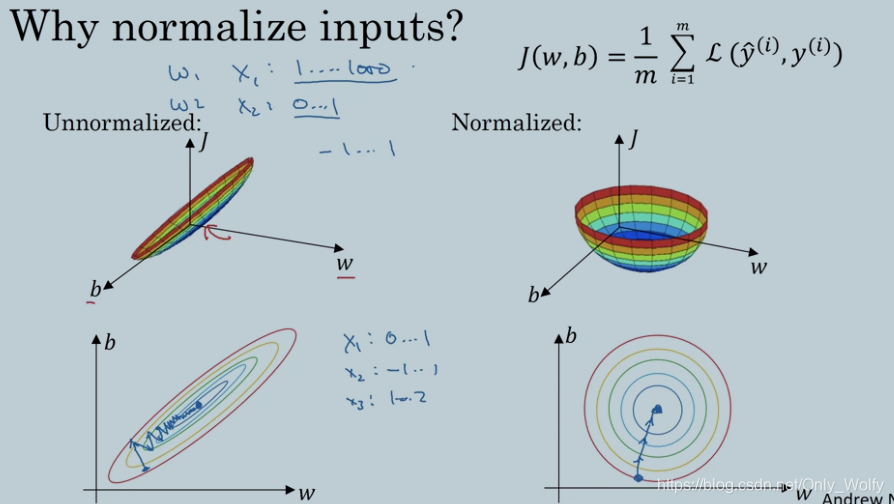
归一化几乎没啥坏处,所以不管有没有效都会用。
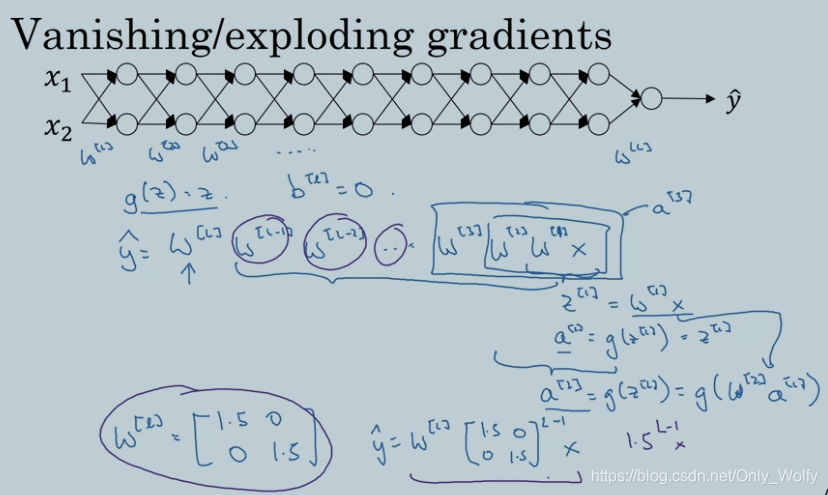
1.10 Vanishing / Exploding gradients
介绍梯度消失和梯度爆炸。
按照下图来说,y_hat 是有多个w点乘起来的,可以看到1.5的多次幂很大,这就会爆炸,同样的,如果选择为0.5,这样就会消失。爆炸的话。。。会不准吧,然后消失的话,梯度下降会很慢,走半天走不到最好的那个点,增加 learning rate 的也不行,因为这个w实在是太小了。
1.11 Weight Initialization for Deep Networks
解决梯度爆炸或消失的方法:就是w初始化的时候乘上个系数,紫框中那个,然后如果是relu的分子是2,如果是tanh的,分子是1会更好,然后也有别的定义式啥的。当然还有一些高级的什么超参数的调整不是很懂,具体看回视频吧。(Xavier Initialization 作业中经常用到)

1.12 Numerical approximation of gradients
如何检查梯度下降下降得对不对:
用下图的双边误差/双向微分(two-sided difference)来验证。

1.13 Gradient checking
用 θ 装 w 和 b ,用 dθ 装 dw 和 db:

计算 dθapprox(里面的eplison取值为10^-7)和自己公式求导出来的 dθ , 用check的公式计算,如果约等于10^-7,那么说明梯度下降做得不错,如果只有10^-3,说明可能出了问题,此时就得不断修改自己的代码,直到 check 为10^-7左右

1.14 Gradient Checking Implementation Notes
实行梯度检验时要注意的地方:
第4点因为dropout去除的点不稳定
第5点非常非常少见:
最后的这个内容有些微妙 虽然很少发生 但并不是没有可能 你对于梯度下降的使用是正确的 同时w和b在随机初始化的时候 是很接近0的数 但随着梯度下降的进行 w和b有所增大 也许你的反向传播算法 在w和b接近0的时候是正确的 但是当w和b变大的时候 算法精确度有所下降 所以虽然我不经常使用它 但是你可以尝试的一个方法是 在随机初始化的时候 运行梯度检验 然后训练网络一段时间 那么w和b 将会在0附近摇摆一段时间 即很小的随机初始值 在进行几次训练的迭代后 再运行梯度检验

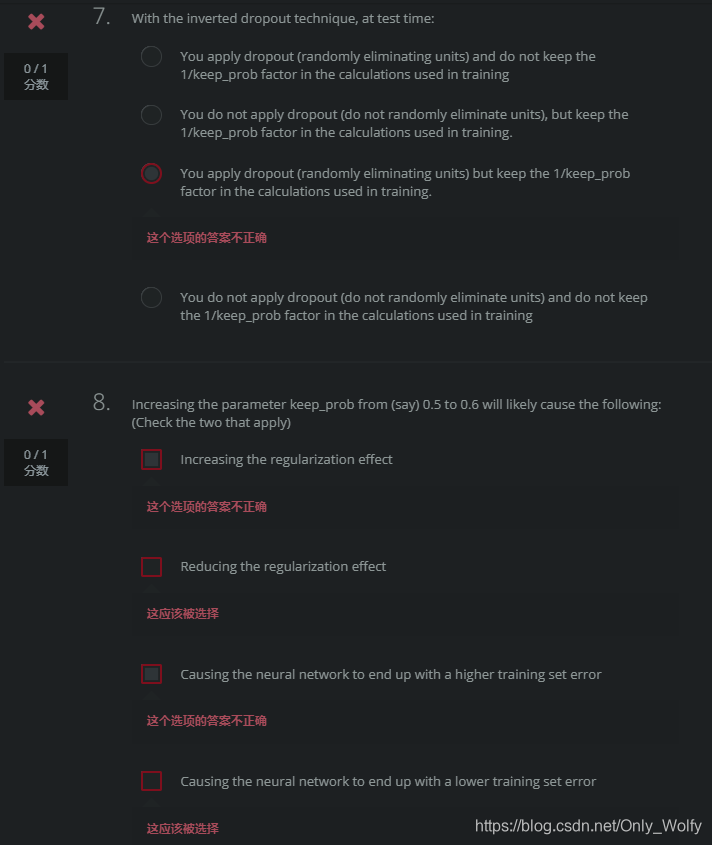
???


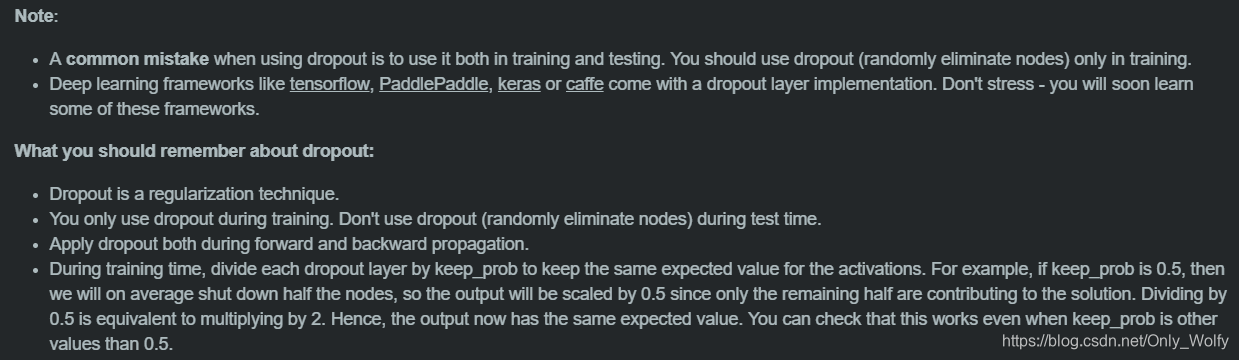
不要在测试的时候,用dropout,而且不要保留在training时候的1/keep_prob
only use dropout during training. Don’t use dropout (randomly eliminate nodes) during test time.
only during training time, divide each dropout layer by keep_prob to keep the same expected value for the activations.
编程作业1
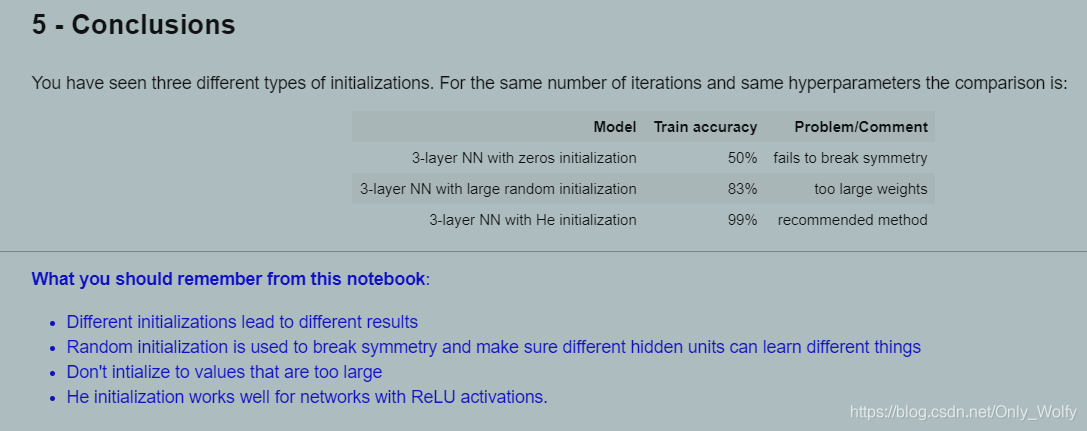
在相同条件下用不同的初始化方法,得到的train accuracy天差地别,对于ReLU激活的,推荐使用 He initialization 与它相似的是(Xavier initialization,不过适用的激活函数是啥忘了),然后不建议使用把w全0化的初始化方法,然后随机数不要太大

编程作业2
L2 正则化 注意事项等等
dropout 注意事项等等
dropout 心得:
-
记得 fp 和 bp 的时候都要用dropout,然后fp的时候 /keep_prob 是因为:假设keep_prob 是0.5,然后就是打开了0.5,关闭了0.5嘛,因此剩下的一半的点 /keep_prob ,也就是 x2 ,意思就是扶持那消失了0.5的点,保持原来的输出(可以认为是保留的点把消失了的点的力也出了,一个顶2个),其他 keep_prob 值同理
-
keep_prob 的意思是保留的意思,比如0.8就是保留80%的点(概率上)。因此作业2中的 forward propagation 是 D1<keep_prob 时为0,一开始写了>,就是没有理解好
-
然后 fp 要 /keep_prob,在 bp 过程中也要 /keep_prob,因为两个要一致:
During forward propagation, you had divided A1 by keep_prob. In backpropagation, you’ll therefore have to divide dA1 by keep_prob again (the calculus interpretation is that if A[1]A[1] is scaled by keep_prob, then its derivative dA[1]dA[1] is also scaled by the same keep_prob).
总结,注意正则化会让你的weights变小,在1.5第二个图中得知w变小,z变小,然后tanh可以变成近似线性的样子,线性堆砌也是线性的,所以过拟合会降下来。
*编程作业3
最后gradient_check_n做得模模糊糊的,梳理一下
因为theta(θ)不再是标量,所以用一个叫parameters的字典(dictionary)来存放,他的vector形态叫做values,然后这个theta是w和b的reshape(存放w和b的信息),字典和vector用 xxx_to_xxx 函数来转化
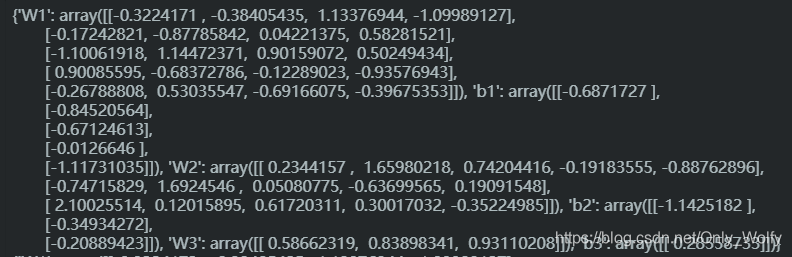
这个是字典形式:print(parameters)

这个是vector形式:print(parameters_values)
代码部分:首先parameters_values是把parameters从字典变为vector,因为有+有-,所以要np.copy备份一份values,然后这个values是个vector嘛,也就是个向量,行或列其中一个是一维的,所以thetaplus[i][0]就是个数字而已,这里的一个theta表示的是一个w或者是b,然后step2,θ+ε,就是thetaplus[i][0]+=ε,然后J(θ+ε)就是把 thetaplus 传过去,用print(vector_to_dictionary(thetaplus)) 可以对比字典形式的thetaplus和没有plus的theta(就是变量parameters),可以发现只有W1的第一个变了,多了ε,就达到了我们的目的:得到θ+ε并且求出J(θ+ε),再重复一下,这里θ其实是w或b,所以 i 要走num_parameters遍,把所有的数字都测一遍。
最后得出 gradapprox 然后跟神经网络跑出来的 grad 做对比就知道有没有写错。
Week 2
2.1 Mini-batch gradient descent
mini batch ,m=5,000,000,划分5000个batch,那么一个batch就是1000个x,设 t 为第 t 个 batch ,比如 x{1} 就是第一个batch,就是 x(1) 到 x(1000)

mini-batch的算法:
用mini-batch梯度下降法遍历一次训练集(m=5,000,000),因为被分割成5000个小的batch,所以进行了5000次梯度下降,如果是普通的,即batch梯度下降法,遍历一次训练集(m=5,000,000),那么只能做一个梯度下降。
然后要注意one iteration和one epoch的区别,one iteration就是t,one epoch就是这里的5000个iteration,mini和不mini一个iteration的数据量是不同的,但是一个epoch是相同的,也是喂了m个数据。
其实就是把训练集拆分出来了而已,更好地利用数据,数学游戏。

2.2 Understanding mini-batch gradient descent
mini和不mini的cost下降图片的区别
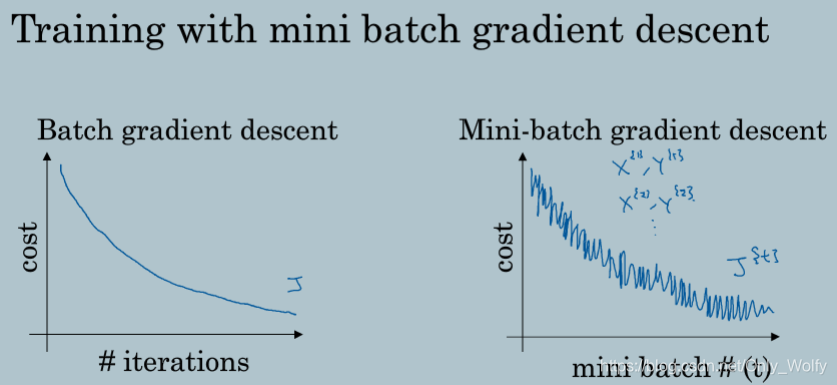
随机梯度下降和mini-batch和batch的对比,紫线绿线和蓝线

还有个问题是mini-batch的size,推荐是2的次幂,一般是64~512,1024也行,需要多次尝试找到更好的

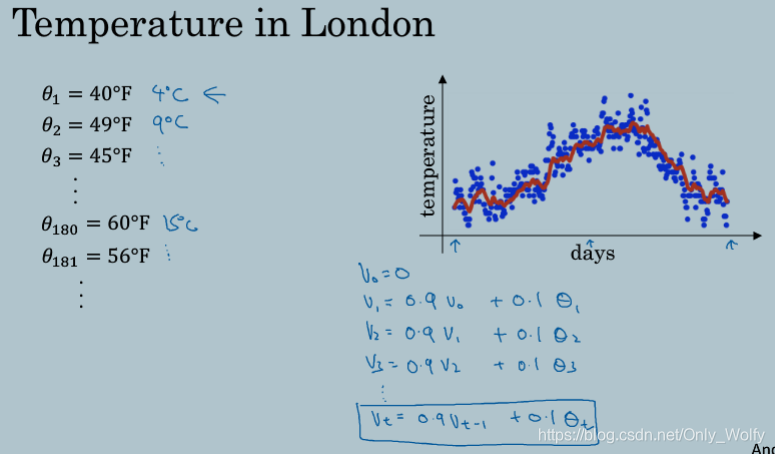
2.3 Exponentially weighted averages
介绍指数加权(移动)平均值。
计算365天的温度。v就是温度的局部平均值/移动平均值,然后计算公式如下:
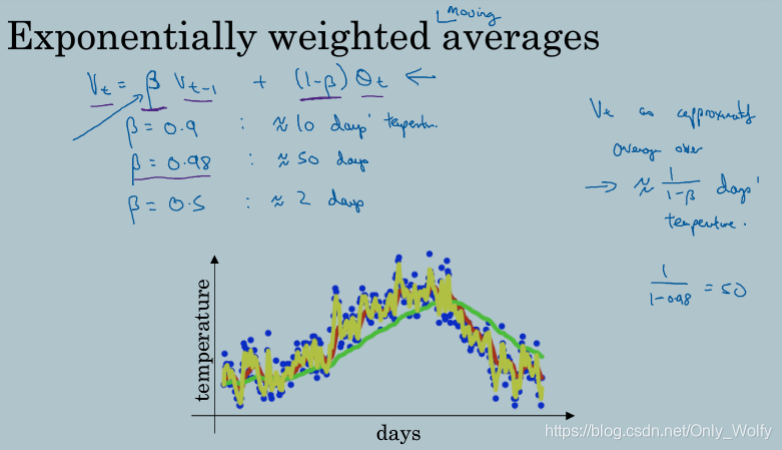
根据 β 的不同,右边就是 1/(1-β) days 就是vt相当于这些days的平均,看得出来β越小,平均天数就越小,就是黄色那条,β越大,0.98那条,就是50days,就是绿色那一条,因为参平均的days太多,所以会出现一定延迟,0.9就是红色那条,刚刚好。
2.4 Understanding exponentially weighted averages
理解这个指数加权平均的意义,就把v100展开,然后看到在0.9^10的时候只占0.35,相当于 1/e ,相当于v100的大部分数值由前10天组成,然后设 (1-epsilon) = β,然后
(
1
−
e
p
s
i
l
o
n
)
1
/
e
p
s
i
l
o
n
=
1
e
(1-epsilon)^{1/epsilon}=\frac{1}{e}
(1−epsilon)1/epsilon=e1,然后当β=0.98的时候,相当于大概平均了 1/epsilon = 50 天的数据。这个东西只是个大概,来辅助理解的,不是真正的推导。
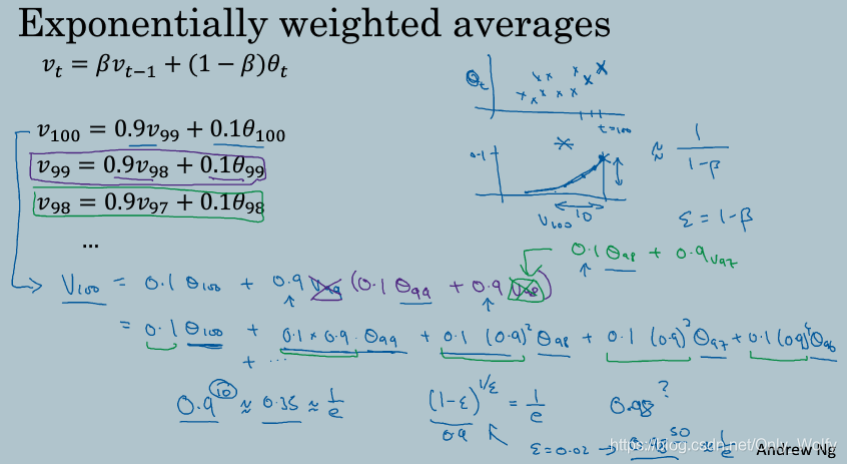
写成代码的形式只需要一个参就够了,所以很节约空间而且就一行代码。
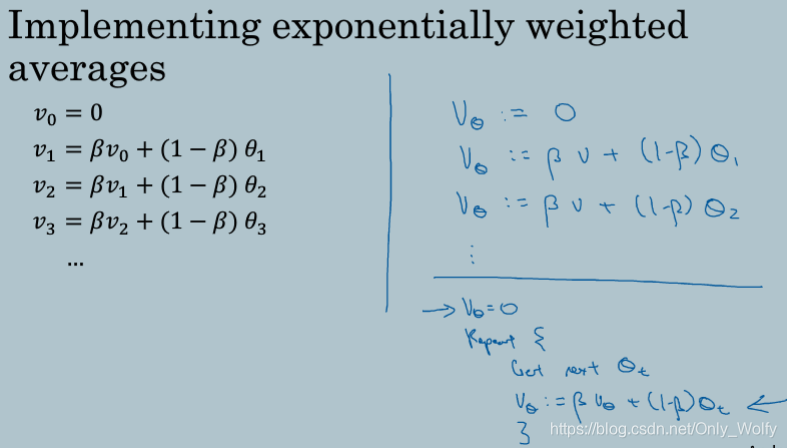
2.5 Bias correction in exponentially weighted averages
偏差修正,可以让平均数运算更准确。
β = 0.98 的时候正常应该是绿线,但是实际是得到的是紫线。
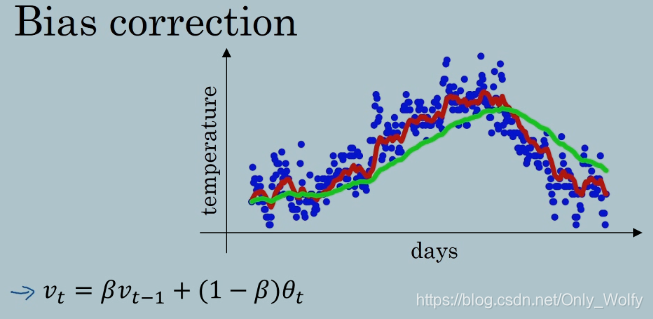
可以看出估算初期处理得不是很好,因为 v0 = 0,v1 = 0.98v0 + 0.02θ1 = 0.02θ1,v2=0.0196θ1+0.02θ2,差距比较大。
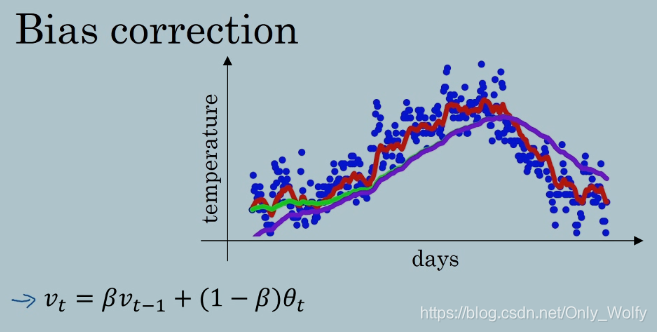
因此我们选择除以一个系数,来修正偏差,当t比较大时,分母几乎为1,说明后面就不太需要修正了。 偏差修正可以帮你尽早做出更好的估计,不过一般不会这么做。看看下一节就知道了
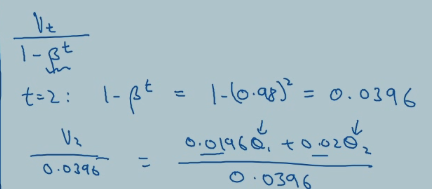
2.6 Gradient descent with momentum
momentum,动量梯度下降法,就是用到2.3、2.4里面的公式,具体如下。
比如图中要到达红色点,没有momentum的时候是蓝色线,我们希望纵轴摆动的幅度减少,横轴摆动的幅度增加,达到红色线那种效果。加了momentum后,算法在前几次取平均的时候,发现纵轴的均值近似于0,因此纵轴的动量就会很小,而横轴方向上所有微分都指向横轴方向,所以横轴的均值很大,算法几次迭代后,最终纵轴摆动变小,横轴摆动增大,就成了红色线。
还有一种解释是像小球滚到碗里面一样,微分给了一个加速度,(1-β)db就是加速度,因为β小于1,所以βVdb就是摩擦力(注意这个Vdb其实是Vd(b-1),因为这里只用了一个变量),所以球不会无限加速,原来的梯度下降则是独立的,这里球可以向下滚获得动量。

习题补充:
β 的大小影响着加速度和摩擦力,我们可以从天数的角度来看
如果 β 比较大的话,就是平均的天数比较多(2.3节 相当于 1/(1-β)天),然后参考得多,曲线就比较平滑,而且反应变慢,像2.3节的绿线。
如果 β 比较小的话,就曲线会震荡多些,但还是没有普通的梯度下降震荡得多,因为momentum多多少少会参考之前的平均值,而普通的梯度下降则不会,是独立的。
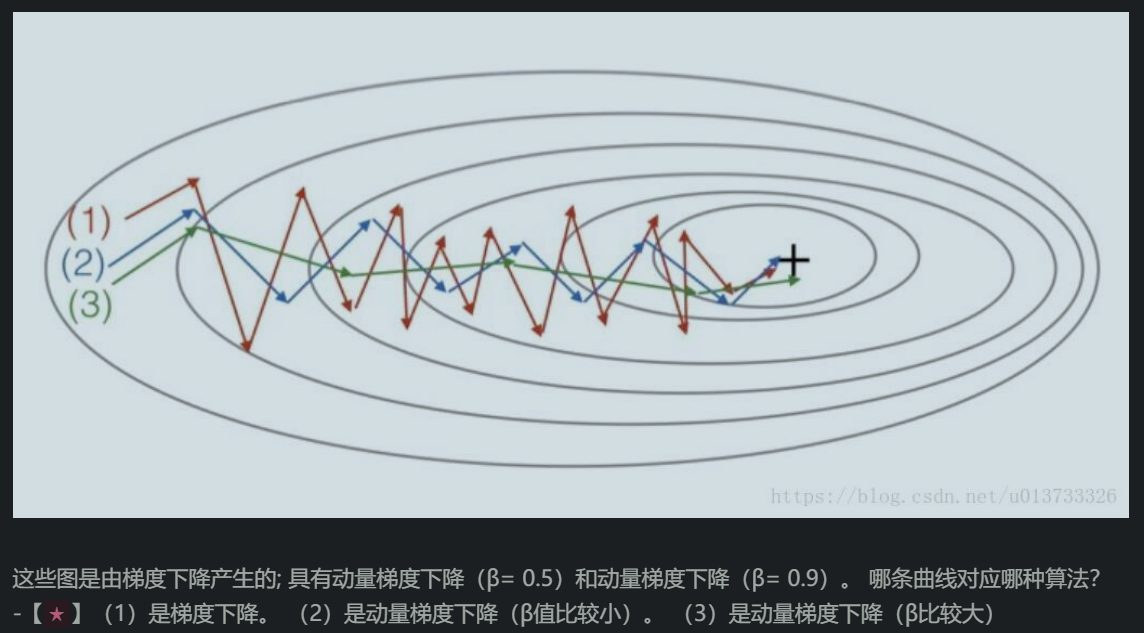
β通常为0.9,很鲁棒。然后上一节讲的偏差修正通常不用。momentum还有另一种写法,不过不太好。

2.7 RMSprop
介绍RMSprop,感觉和momentum差不多,这里纵轴叫b,横轴叫w,实际上比一定,只是为了讲课方便区分唯一。并且注意平方是(dw)的平方,db同理。
例子中W的方向上 我们希望学习速率较快 而在垂直方向上 即例子中b的方向上 我们希望降低垂直方向上的振荡 对于S_dW和S_db这两项 我们希望S_dW相对较小 因此这里除以的是一个较小的数 而S_db相对较大 因此这里除以的是一个较大的数 这样就可以减缓垂直方向上的更新 实际上 如果你看一下导数 就会发现垂直方向上的导数要比水平方向上的更大 所以在b方向上的斜率很大 对于这样的导数 db很大 而dW相对较小 因为函数在垂直方向 即b方向的斜率 要比w方向 也就是比水平方向更陡 所以 db的平方会相对较大 因此S_db会相对较大 相比之下dW会比较小 或者说dW的平方会较小 所以S_dW会较小 结果是 垂直方向上的更新量 会除以一个较大的数 这有助于减弱振荡 而水平方向上的更新量会除以一个较小的数 使用RMSprop的效果就是使你的更新 会更像这样 在垂直方向上的振荡更小 而在水平方向可以一直走下去
大概就是说,原公式是没有分母那个的,现在加了分母,除以一个数,这个数如果是针对w的,因为w没有b这么陡,所以dw就比db相对小,然后分母相对小的话,整个就会增大,就是让w变得更快。b同理,因为比w要陡,所以db相对较大,我们把它摆在分母上就希望减弱它的震荡。
最后为了分母不为0,会加上一个很小的epsilon,常取为1e-8.

2.8 Adam optimization algorithm
很多优化算法都不能适用于不同的神经网络,这里介绍的Adam、RMSprop和momentum都能适用于不同的神经网络。
Adam优化算法:结合RMSprop和momentum
momentum用β_1,RMSProp用β_2
用Adam的时候要用修正偏差
接的分母要加上epsilon

超参数 α 需要经常被调整(tune),来去看看哪个更好。然后β1和β2一般很少调整。下面是建议的取值。最后是Adam的含义
Adam代表自适应矩估计(Adaptive Moment Estimation) β1代表这个导数的平均值 被称为第一阶的矩 β2被用于计算平方数的 指数加权平均 也被称为第二阶矩 以上就是Adam这个命名的由来

2.9 Learning rate decay
衰减率学习公式:
衰减率decay_rate 和
α
0
α_0
α0 是另一需要调整的超参数
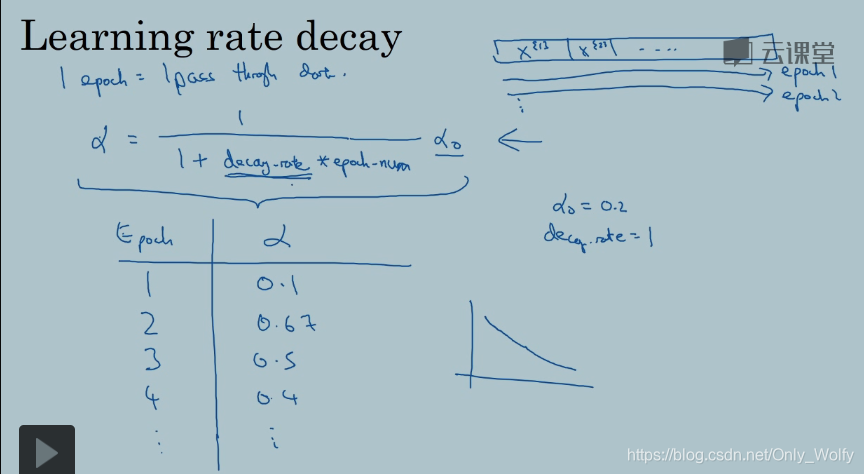
还有别的衰减率公式,t 是mini-batch的 t,还有手动控制 α 的

如果你现在在想 哇 这有那么多的超参数 那我该如何在这么多不同的选项当中做出选择? 我想说 现在不用担心这个 下周 我们将对系统性地选择超参数 进行更多讨论 对我来说 学习率衰减通常位于 我尝试的事情中比较靠后的位置 设置一个固定数值的阿尔法 还要使它优化得良好 对结果是会有巨大的影响的 学习率衰减的确是有帮助的 有时它可以真正帮助加速训练 但是它还是在我尝试的办法中比较靠后的一顶 但下个星期 我们谈到超参数优化时 你会看到更多系统性来地安排所有的超参数的方式 以及如何有效地在当中搜索 那这些就是学习率衰减的内容
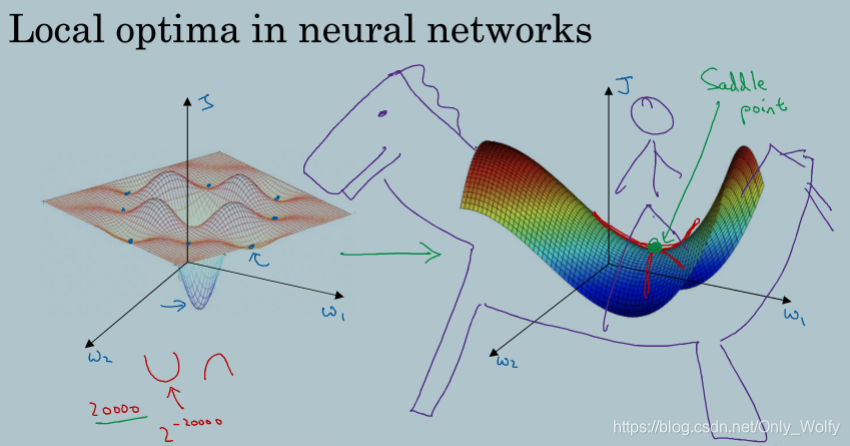
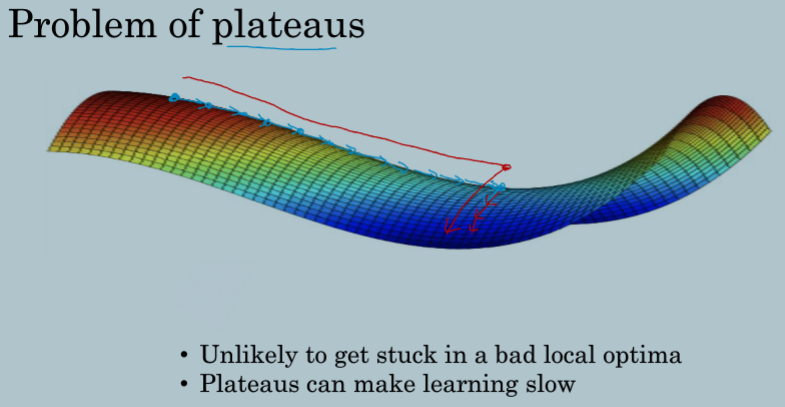
2.10 The problem of local optima
不必害怕神经网络走到糟糕的局部最优点,因为在高纬度、很多参数、较大的神经网络上,更有可能走到鞍点。怕走到最差的局部最优点是因为比较熟悉低纬的图形,但现在大都是高纬度的。我们更多面临的问题是在鞍点上如何更快地走到局部最优点,用Adam等。
编程作业

momentum 注意事项:

注意Adam是要bias correction的,偏差修正的。

最后是用的mini-batch来做,呃,数据的投喂,然后可以去看一下代码。
然后比较了3中update parameters,更新参数(w和b)的方法,有普通的梯度下降(gd),momentum 和 Adam

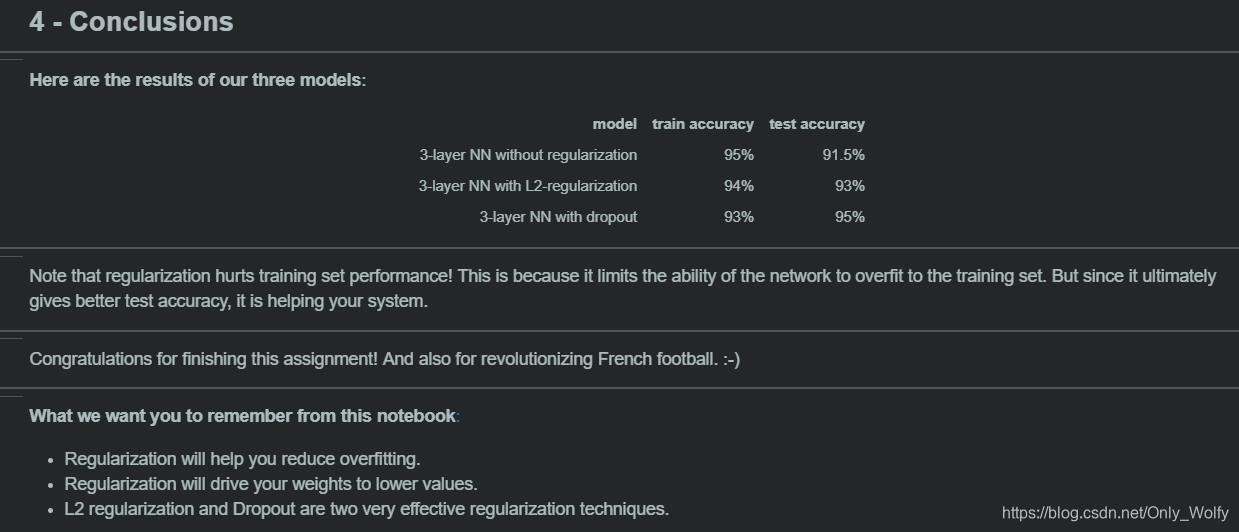
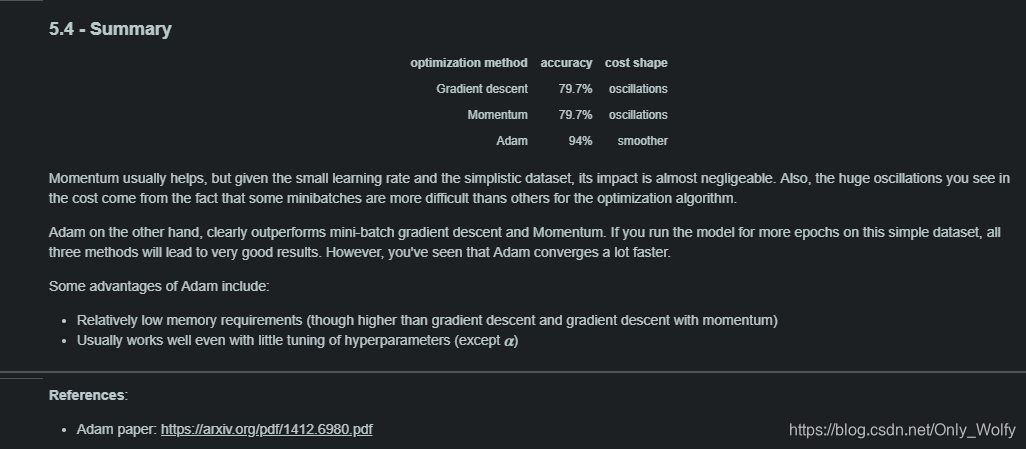
最后比较了他们的准确率,没想到Adam比momentum好这么多,而momentum 却和普通的梯度下降(gd)差不多,看来还是 Adam 好啊。
然后momentum这里不起作用是因为数据比较少(mini-batch),所以效果不明显,不过如果投喂多次epochs的话,三个模型也会表现得很好,不过 Adam 还是会收敛得快很多,综上 Adam 最好。
Week 3
(最后一周!!!)
3.1 Tuning process
如何选择各种超参数
下面ng觉得α最重要,刺激是紫框和黄框,然后没框住那些基本不动,当然也可以有别的想法。

研究早期,比如只有2个超参数,要选25个,就会以网格的形式选,其实这样的话,对于超参数1,其实就选了5个不同的点,超参数2也是。但如果是随机取25个点的话,超参数1和超参数2就有25个不同的数值。
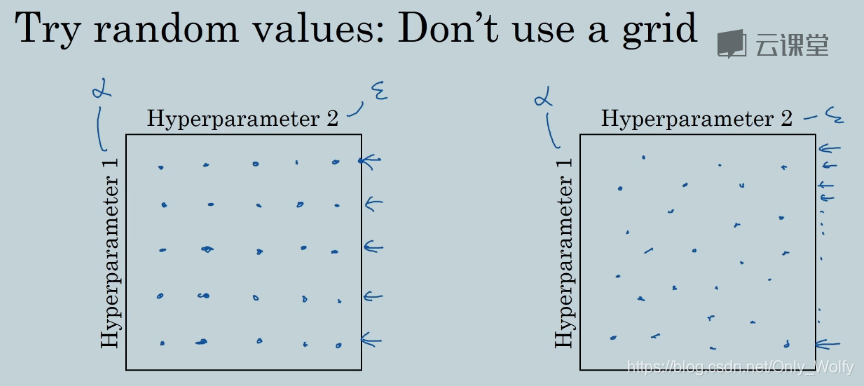
然后选了25个之后,我们会发现一个地区的点表现得比较好,于是缩小范围在那个地区继续随机选点,这样就从粗到细地搜索。

3.2 Using an appropriate scale to pick hyperparameters
为超参数选择合适的范围。随机的时候要注意约束随机的范围。

然后随机的范围很大的话,会造成随机的资源不平均。比如 α 取值为 [0.0001,1],很大概率随机出来的数是 [0.1,1],这样会有偏差。然后我们需要把这个数轴平均分配,按照0.001、0.001、0.01、0.1、1分配,然后在每个段中平均取点,这样会更平均。
做法是先设定左边为
1
0
a
10^a
10a,右边为
1
0
b
10^b
10b,那么设置一个 r 随机的是 [a,b]。然后 α 的取值就是
1
0
r
10^r
10r。这里因为是每10倍划分一次,所以是涉及到了对数 log 的运算 / 思想。

3.3 Hyperparameters tuning in practice: Pandas vs. Caviar
超参数调试实践:熊猫照料法 vs. 鱼子放养法
首先我们建议在一段时间内要重新评估一下超参数,看要不要调整,因为一些数据等因素会变。

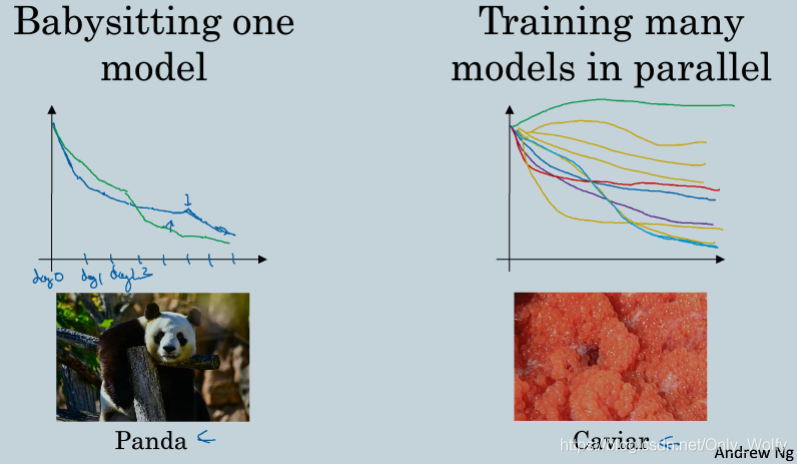
有两种调整超参数的方式:熊猫照料法 和 鱼子放养法。
一个是左图,每一天根据现有情况来调整超参数,就像熊猫孩子很少,照看一个,不过熊猫一生也可以有几个孩子,因此在两三周后可以建立一个新的模型(孩子),来继续照看。
另一个是右图,在同一天用不同的超参数选择方案,然后一起开始跑数据,跑到一定天数后看哪个方案更好。
自己拥有的计算资源决定了用哪种方式调整超参数,如果有足够的计算机去平行试验许多模型,那么绝对是鱼子放养法更好
但是在某些应用领域 例如在线广告设置 以及计算机视觉识别 都有海量的数据和大量的模型需要去训练 而同时训练大量模型是极其困难的事情 看到很多研究小组更喜欢使用熊猫模式 这实际上是由行业性质所决定的
3.4 Normalizing activations in a network
Batch Norm:Batch归一化
在之前logistic回归中用到了归一化输入同样的,归一化可以用在神经网络中。归一化有的归的是a,有的归的是z,实践中通常归的是z。
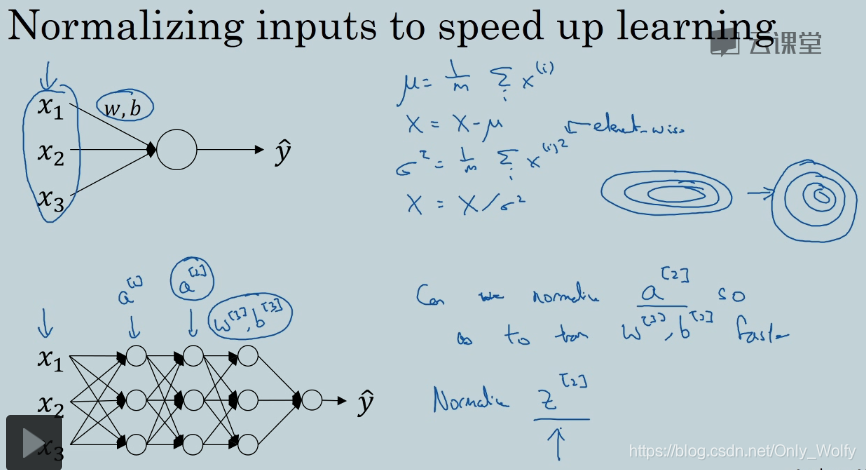
公式如下,这里 γ 和 β 可以是 If 下面那些式子(由Znorm得来),也可以自己调整,比如不想均值为0,方差为1,不想值在sigmoid函数中总是在线性部分,也想让他们在非线性部分,这时候就需要调整。

3.5 Fitting Batch Norm into a neural network
Batch Norm 在神经网络的具体流程:
要注意的是 Batch Norm 的 β 和 Adam、momentum 的 β 不同,但是论文里面都用了 β 这里方便看论文。
然后 Batch Norm 接下来的 update parameters 也可以用 Adam 等,也可配合 mini-batch 使用
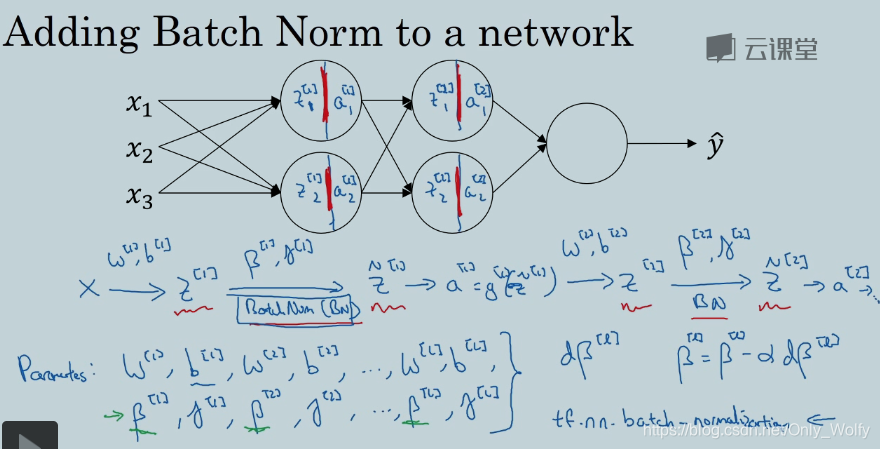
注意,如果用 Batch Norm,可以消掉 b,或者变为0。因为归一化是满足均值为0,方差为1,然后通过参数 β 和 γ 来重新调整,所以z中的bl可以消去,由z~中的β来调整偏移量。
because Batch Norm zeroes out the mean of these ZL values in the layer, there’s no point having this parameter b l b^l bl
最后注意一下维度是多少。

mini-batch + Batch Norm (+Adam等参数更新优化)神经网络的总体流程:

3.6 Why does Batch Norm work?
再讲讲为什么 BN 有用(也许可以看看论文?毕竟我有)
有点懒得解释了,看看标题链接的视频和论文吧
本节网易云课堂链接
3.7 Batch Norm at test time
在测试的时候,因为这里是mini-batch,然后对所有的batch得出μ和σ,然后得出z~,当然也有别的方法得出 γ 和 β

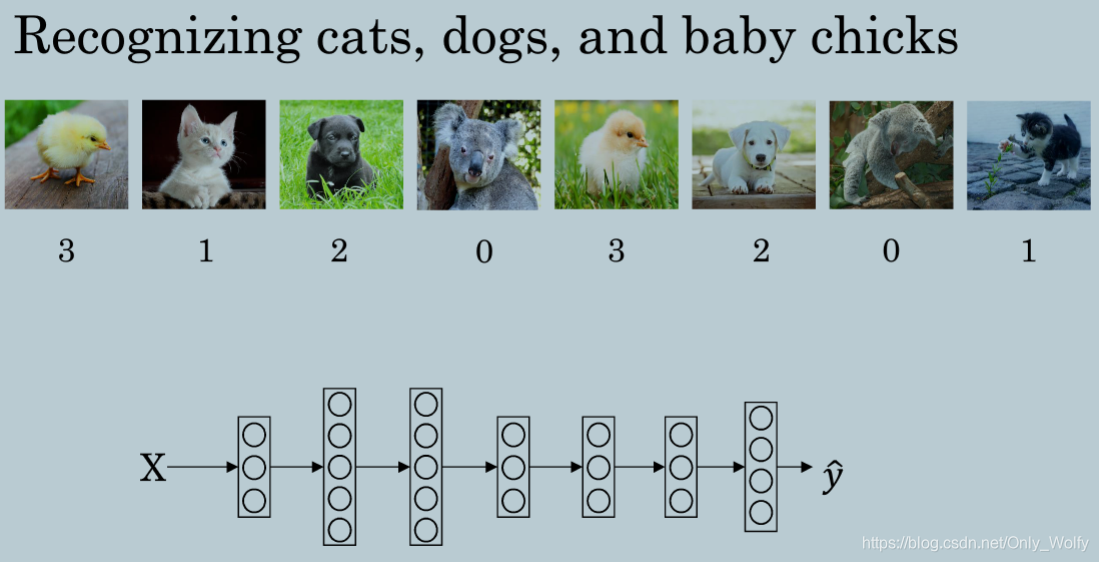
3.8 Softmax Regression
Softmax 用于多分类
思路就是看哪个点占所有点总概率之和最高,就是那个答案
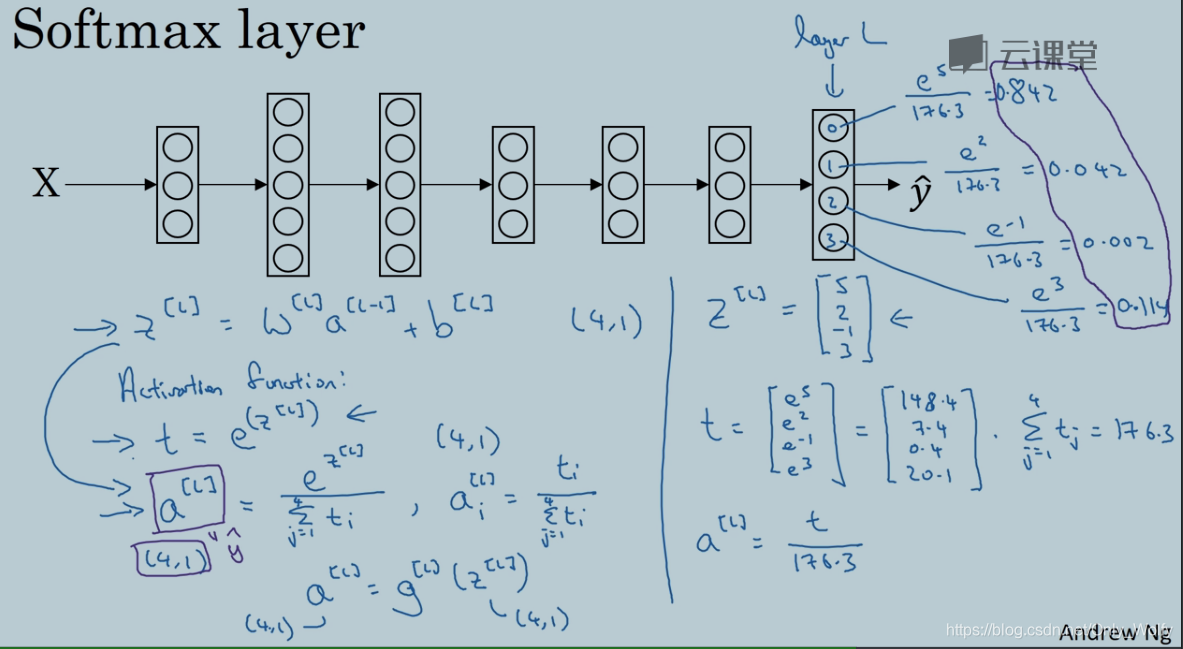
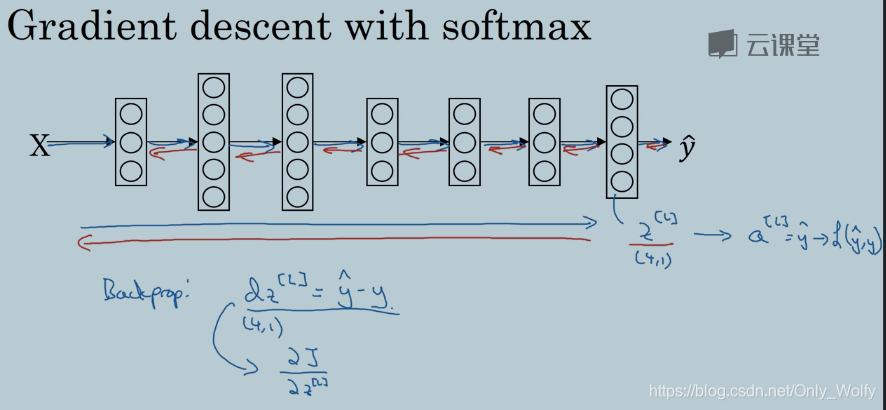
3.9 Training a softmax classifier
下面是实现的细节:

注意有一些框架,只要给出 forward propagation,就会给出 bp,然后 softmax 的
d
z
l
dz^l
dzl 如下
3.10 Deep learning frameworks
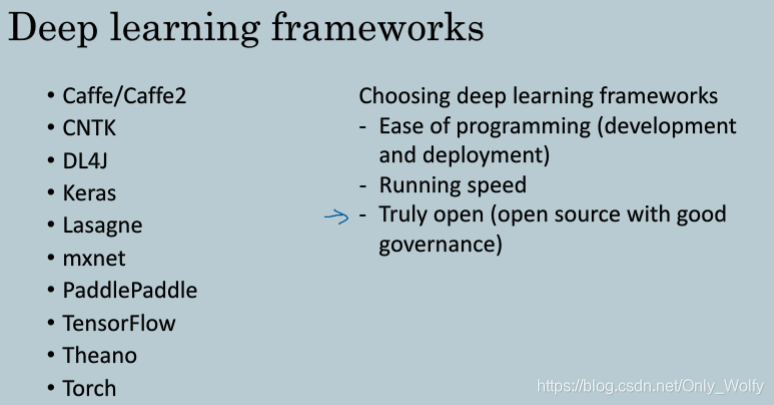
推荐的深度学习框架和选择框架时候要注意的点,有个点是:是否真正开源,有的开源框架过几年后公司不开源了,或者将一些功能移入私有的云服务中
有一个我会提醒你注意的地方是 你多信任这个框架在很长一段时间 会保持开源 而不是被单一公司所掌控 因为这样 即使现在它是开源的 在以后可能会因各种原因所关闭
3.11 TensorFlow
讲解了怎样用TensorFlow来弄一些东东
首先TensorFlow可以帮你实现反向传播,只要给他正向传播的式子和 learning_rate,因为在写 cost 式子的时候,如果里面有一个是tf.Variable,那么那些±*/平方等,就会重载成tf.add()等,右上角有个计算图,TF就是根据这个图来求出反向传播的导数。把 cost 和 learning_rate 赋值给 train,GradientDescentOptimizer这里是普通的梯度下降,可以换成Adam等等,然后运行session.run就可以跑了。
然后 x = tf.placeholder(…) 是说可以暂时保留X的值,并且之后可以传递值进去,下面的代码coefficients定义了个矩阵,feed_dict={x:coefficients}就是把coefficients的东西赋值给x,然后和train一起喂给session.run。这里有个使用例子就是运行mini-batch的时候,可以更换coefficients,然后神经网络的输入 x 也可以随之更换。
最后是 session = tf.Session() 及其下面两句话,这两句是用来定义训练啥的,然后右边的表达感觉更好,with在Python里面更容易清理,以防在执行这个内循环时出现错误或例外(不大懂,还没查with在Python里面的作用)

作业中的详细对比:

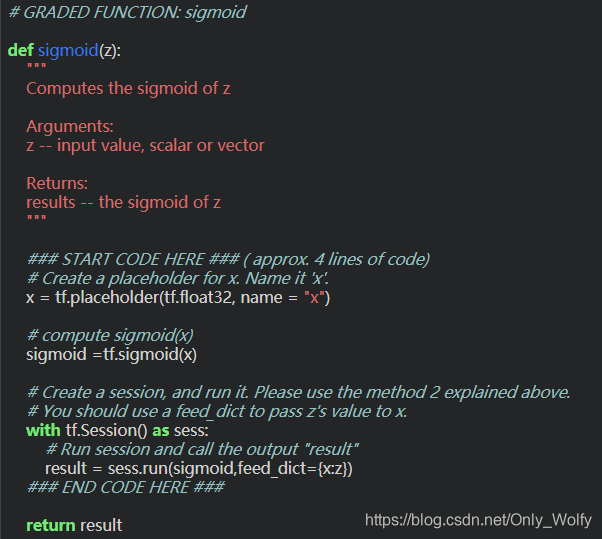
用法,用来输出sigmoid,注意feed_dict={x:z}就是把z传给x,用来更新x的值
测验

No. You can run deep learning programming languages from any machine with a CPU or a GPU, either locally or on the cloud.

编程作业
TensorFlow注意的地方,要建造一个session并运行session里面的操作才会生效。
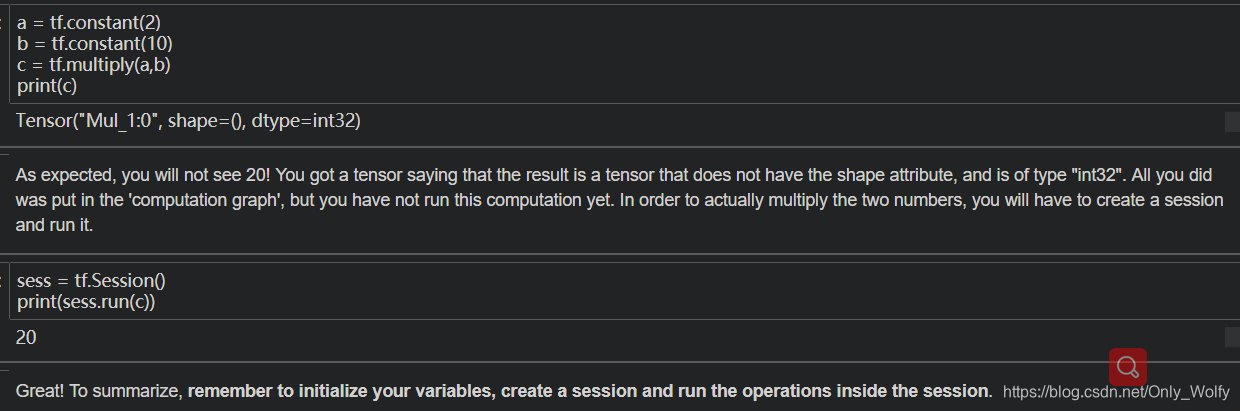
这里有个 sess.close(),运行第一遍是6,在运行一次会报错,然后上面的代码sess=tf.Session()要再运行一遍才行,或者直接删掉sess.close()














 293
293











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









