









摘要
上一章讨论了我们为什么要做PhxSQL和为什么这样做PhxSQL。这里我们主要谈谈为什么不做某些特性。舍得舍得,有舍才有得。CAP告诉我们只能三选二,俗话告诉我们天下没有免费的午餐。每个特性除了自身提供的功能,也有其代价。为了保证强一致的线性一致性、高可用、serializable级别事务隔离、完全兼容MySQL、和最小侵入MySQL,PhxSQL放弃了一些特性。
正文
7. Why Not?
7.1. 为什么不支持多写?
多写想想就很诱人。多写可以充分利用每台机器写时需要的资源。例如某些写操作可能非常耗费CPU,多写可以把写操作分散在各台机器上,充分利用各个机器的CPU资源,极大提高写入的性能。多写使得换主没有存在的必要,也就没有换主时可能存在的不可写时间窗问题。多写还使得客户端可以就近写入,减少跨数据中心写入带来的网络延迟。
多写有两种:大家熟知的分shard或者组,各shard或者组间并行写入,以Google Spanner[8]为典型代表;在shard或者组内并行,以Galera和MySQL Group Replication为代表。
7.1.1. 组间多写
组间多写是把数据分成多个不相交的shard,每个组的机器负责一个shard 。当一个事务涉及的数据(读集合和或写集合)都在某个组时,这种事务称为本地事务。当一个事务涉及的数据分布在超过一个组时,这种事务称为分布式事务。
本地事务可以在本组独立执行,组之间不需要任何通信。为了减少事务冲突带来的性能降低,一般都是由组内leader执行本地事务,通过Paxos等一致性协议保证组内机器的数据一致[8]。各个组间并行执行本地事务,可以极大提高本地型事务的写性能。
组间多写最大的阻碍是分布式事务,而分布式事务是非常昂贵的。在SQL的模型中,为了实现read repeatable级别的事务隔离,事务管理器需要检查两个并发事务的写数据集是否冲突;为了达到serializable级别的事务隔离,事务管理器需要检查两个并发事务的读数据集和写事务集是否冲突[10]。这一般通过严格两阶段锁(strict two-phase locking,严格2PL)和/或者多版本并发控制MVCC实现。当这些数据集跨组时,就涉及到跨组的机器通信。
一个组同时遇到本地事务和分布式事务时,在本组需要根据事务的隔离级别,由事务管理器仲裁执行。
以Google Spanner为例,一个涉及两个机器组(Spanner中的组是指Paxos组)事务就需要在coordinator leader和non-coordinator-participant leader之间两次通信,前者组内还涉及一次Paxos写操作,后者组内再加两次Paxos写操作[8,Sec. 4.2.1 Read-Write Transactions]。当跨机房部署时,机器之间的网络延迟使得通信代价更加高昂。Spanner为了减少这种昂贵的跨组事务,要求所有数据都必须有Primary key,并且其它数据尽量挂接在Primary key下面,使得事务尽量在一个组内、且由组内leader执行。
7.1.2. 组内多主多写
组内多主多写时每个机器都有完整的数据,但这份数据分成不相交的逻辑集合,每个机器负责一个集合的写入。这台机器称为这个集合的主机,这个集合称为这个主机负责的数据,其它机器称为这个集合的备机。客户端将写操作发到所涉及数据的主机,由主机通过atomic broadcast原子广播将更新请求发送给组内所有的机器,包括主机本身[9]。Galera和MySQL Group Replication都是采用这种方法。

图 3:组内多主多写架构[9]
原子广播具有3个特性:
i) 如果一台机器执行一条消息所带的更新命令,那么所有的其它机器都执行这条命令(delivered)。这里“执行”指的是原子广播层将消息交给上层,真实的执行时刻由上层决定。在数据库中,这个上层一般是并发事务管理器,它决定这些消息的真实执行顺序。
ii) 所有机器以相同的顺序执行命令。
iii) 如果一台机器成功广播了一条消息,那么最终所有机器都将执行这条消息。
使用原子广播后,事务的生命周期从prepare->committed/aborted改变为prepare->committing->committed/aborted。
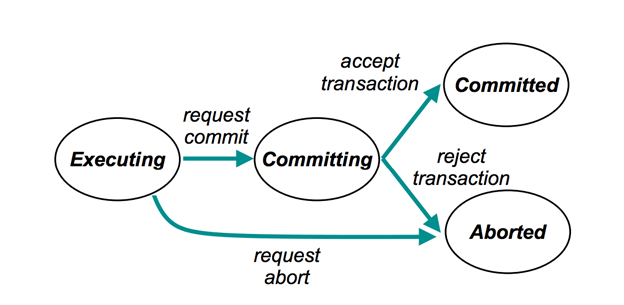
图 4:事务生命周期状态转换[9]
当一个事务只涉及到一个集合的数据时,称为本地事务,由这个集合的主机的本地事务管理器先使用本地严格2PL仲裁,然后将committing状态的事务通过原子广播发给其它备机。
当一个事务涉及到多于一个集合的数据时,称为复合事务(complex transaction)。这个事务所涉及的某个数据集合的主机将committing事务状态,包括读集合(如果需要serializable级别隔离。这里的一个小优化是采用dummy row减少可能极其庞大的读集合[10])、写集合、以及committing状态,通过原子广播发给全组进行仲裁。Galera和MySQL Group Replication都只是校验写集合,因此不支持serializable级别事务隔离[18]。
每台机器都可以通过本地事务状态和原子广播收到的消息,独立判定committing事务最终是提交还是终止。这种判定由原子广播的特性保证全局一致。
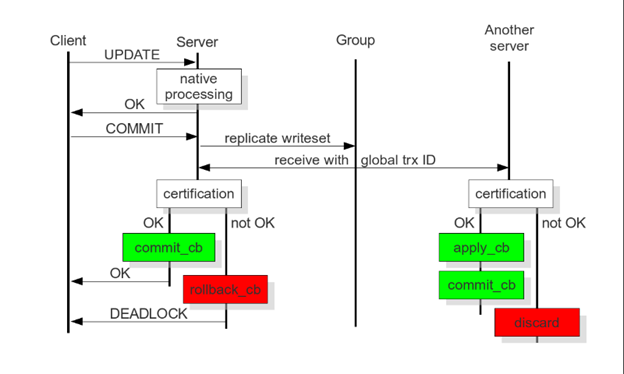
图 5:Deferred Update Replication和Certification-based Replication事务执行时序[11]
强调一下:在机器通过原子广播进行数据同步时,事务的最终结果不能在广播前决定,而是在执行这条消息依赖的前置消息及这条消息后才能决定。这称为Deferred Update Replication[9][14]推迟的更新复制或者Certification-based Replication[11]。这里有个重要特点需要注意:只有收到一条消息的所有前置消息后,这条消息和所有未执行的前置消息才能由事务管理器并发执行。因此,这里引入了一定的串行化。
原子广播的突出优点是在低延迟局域网有很高的吞吐率。
但同时原子广播有不小的按机器个数放大的网络延迟,在非低延迟网络会显著放大网络延迟。MySQL Group Replication使用的Corosync[16]、Galera[15]默认使用的gcomm和支持的Spread[17]都是基于Totem[13]这个成员管理和原子广播协议。
Totem是个为低延迟局域网设计的协议。在Totem中,所有机器组成一个环(ring)。无论一台机器是否需要广播,令牌(token)在机器之间都按照环顺序传递。只有拿到令牌的机器才可以进行广播,即发出提交事务请求。因此在下一台机器收到上一台机器令牌的网络延迟期间,整个系统处于等待状态。为了保证Safe Order Delivery,消息(实际是regular token,不是regular message)需要在环中循环两圈,才能知道是否可以执行,因此,消息延迟是(4f+3)*RTT/2,其中(2f+1)是机器的数目、f表示容错的机器数。
在一个典型的两地三中心部署中,这导致一次事务写操作延迟极其高昂。例如一地两中心的网络延迟一般可以控制在2ms(单向),上海-深圳间网络延迟一般是15ms(单向),则一次事务写操作的网络延迟是64ms!在两地三中心的配置中,PhxSQL的主和一个备一般分别在一地的两中心,另一个在异地。在通常情况下,master的Paxos一次写入只需一个accept,并且只等最快的备机返回。这时PhxSQL的写延迟只有4ms!
相比Paxos这类协议,原子广播还有一个缺陷。当任意一台机器宕机或者网络中断时,Totem此时会超时,在踢掉宕机的机器、重新确定组成员之前,整个集群的消息停止执行,即写操作暂停。
对于read-only事务,只有去数据集合的主机读取、或者昂贵地读取原子广播Quorum台机器、或者使用类似Spanner的TrueTime[8]技术读取任一符合资格的机器,才能保证线性一致性。Galera节点间有延迟,并且只读事务在本地执行,不支持线性一致性[15]。如果MySQL Group Replication支持线性一致性,请不吝告知。
了解基于原子广播的组内多主多写模式的原理和优缺点后,使用多写模式还需要根据业务仔细划分数据集,尽量减少公共数据的使用,同时处理好自增key等细节问题,以减少事务间的跨机冲突。
PhxSQL建立在开源的PhxPaxos基础上,感兴趣的读者可以用PhxPaxos方便实现原子广播插件,加载到MySQL中,从而支持多写。
如果不要read repeatable或者serializable级别隔离的事务,例如简单的key-value操作,同时通过lease机制保证线性一致性,是可以做到高效率多写的。但这就违反了PhxSQL完全兼容MySQL和最小侵入MySQL的原则。
7.2. 为什么不支持分库分表?
分库分表也是个诱人的选择:可以平行无限扩展读写性能。分库分表就是分组,上个小节已经讨论了分布式事务的高昂成本。另外,为了保证完全兼容MySQL、支持全局事务和serializable级别事务隔离,不大改MySQL就支持sharding是非常困难的。大改又违反了“最小侵入MySQL”原则,并且可能引入新的不兼容性。在应用不要求全局事务和serializable级别事务隔离情况下,感兴趣的读者可以把PhxSQL作为一容错的MySQL模块,在上层构建支持分库分表的系统。因为PhxSQL本身的容错性,这样做比在MySQL基础上直接构建要简单,无需关心每个sharding本身的出错。如果以后有需求,PhxSQL团队也可能基于PhxSQL开发一个分库分表的新产品。当然,这个产品难以提供PhxSQL级别的兼容性。
7.3. 为什么这么纠结于serializable级别事务隔离性,read repeatable级别很多时候已经够用了啊?
我们在设计原则中已经提到,为了完全兼容MySQL。我们认为一项好的技术是一项方便用户的技术,提供符合用户直觉预期、不用看太多注意事项的技术是我们的温柔。我们很诚恳,也是为了方便用户。我们不想说PhxSQL完全兼容MySQL,然后在不起眼的地方blabla列出好几页蝇头小字的例外。事实上,对于关键业务来说,serializable是必要的、read repeatable是不足的。read repeatable有个令人讨厌的write-skew异常[12]。
举个例子。小薇在一个银行有两张信用卡,分别是A和B。银行给这两张卡总的信用额度是2000,即A透支的额度和B透支的额度相加必须不大于2000:A+B<=2000。
两个账户的扣款函数用事务执行分别是:
A账户扣款函数:
sub_A(amount_a):
begin transaction
if (A+B+amount_a <= 2000)
{ A += amount_a }
Commit
B账户扣款函数:
sub_B(amount_b):
begin transaction
if (A+B+amount_b <= 2000)
{ B += amount_b }
commit
假定现在A1000,B500。如果小薇是个黑客,同时用A账户消费400和B账户消费300,即amount_a == 400,amount_b == 300。那么这个数据库会发生什么事情呢?
如果是read repeatable级别隔离,sub_a和sub_b都会同时成功!最后A和B账户的透支额分别是A=1000+400=1400,B=500+300=800,总的透支额A+B=1400+800=2200>2000,超过了银行授予的额度!如果不是信用卡的两笔小消费,而是两笔大额转账,那么银行怎么办?
如果是serializable级别隔离,则sub_a和sub_b只有一个成功。具体分析有兴趣的读者可以自己完成。
7.4. 为什么不把显著提升MySQL性能作为一个主要目标?
事实上,PhxSQL已经显著提升了MySQL主备的写入性能。与semi-sync比,在测试环境中,PhxSQL的写入性能比semi-sync高16%到25%以上。读性能持平。这是在满足完全兼容MySQL和最小侵入MySQL原则下所能获得的结果。鉴于PhxSQL对MySQL的改动是如此之小,对性能有高要求的读者,可以方便地把PhxSQL中的MySQL换成其它高性能版本,获得更高性能。
7.5. 为什么编译时不支持C++11以下标准?
作为热爱新技术的码农,我们真的很喜欢C++11中期待已久、激动人心的新特性,例如极大增强的模板、lambda表达式、右值和move表达式、多线程内存模型等,这将C++带入了一个新的时代,大大提高了码农搬砖的速度、编码的正确性、和程序的性能。有了C++11,PhxSQL的开发效率提高了很多。
8. 与Galera及MySQL Group replication的比较
参见7.1.2小节。
结论
PhxSQL是一个完全兼容MySQL,提供与Zookeeper相同强一致性和可用性的MySQL集群。
感谢大家看完这么长的一篇文章。希望大家多阅读PhxSQL源码,多提技术性意见,甚至成为源码贡献者!
参考
-
M.P. Herlihy and J. M. Wing. Linearizability: a correctness condition for concurrent objects. ACM Transactions on Programming Languages and Systems (TOPLAS), Volume 12 Issue 3, July 1990, Pages 463-492.
-
L. Lamport. How to make a multiprocessor computer that correctly executes multiprocess programs. IEEE Trans. Computer. C-28,9 (Sept. 1979), 690-691.
-
P. Hunt, M. Konar, F. P. Junqueira, and B. Reed. ZooKeeper: wait-free coordination for Internet-scale systems. USENIXATC’10, 2010.
-
L. Lamport. Paxos Made Simple. ACM SIGACT News (Distributed Computing Column) 32, 4 (Whole Number 121, December 2001) 51-58.
-
D. Ongaro and J. Ousterhout. In search of an understandable consensus algorithm. USENIX ATC ’14, 2014.
-
B. M. Oki and B.H. Liskov. Viewstamped replication: a New primary copy method to support highly-available distributed systems. PODC’88, 8-17, 1988.
-
T. Chandra, R. Griesemer, and J. Redstone. Paxos made live – an engineering perspective. PODC’07, 2007.
-
J. C. Corbett, J. Dean, M. Epstein, and etc. Spanner: Google’s Globally-Distributed Database. OSDI’12, 2012.
-
F. Pedone, R. Guerraoui, and A. Schiper. The database state machine approach. Journal of Distributed and Parallel Databases and Technology, 14:71–98, 2002
-
V. Zuikeviciute and F. Pedone. Revisiting the database state machine approach. VLDB Workshop on Design, Implementation, and Deployment of Database Replication. 2005.
-
Certification-based Replication. Visited at 2016/9/5.
-
Snapshot isolation. Visited at 2016/9/5.
-
Y. Amir, L. E. Moser, P. M. Melliar-smith, D. A. Agarwal, and P. Ciarfella. The totem single ring ordering and membership protocol. ACM Transactions on Computer Systems. 13 (4): 311–342.
-
http://downloads.mysql.com/presentations/innovation-day-2016/Session_7_MySQL_Group_Replication_for_High_Availability.pdf. Visited at 2016/9/5.
-
Replication API. Visited at 2016/9/5.
-
Corosync by corosync. Visited at 2016/9/5.
-
http://www.spread.org/. Visited at 2016/9/5.
-
Isolation Levels. Visited at 2016/9/5
-
L. Lamport. Fast Paxos. Technical Report, MSR-TR-2005-112.
-
I. Moraru, D. G. Andersen, and M. Kaminsky. There is more consensus in egalitarian parliaments. SOSP’13, 2013.
OpenIMgithub开源地址:
https://github.com/OpenIMSDK/Open-IM-Server
OpenIM官网 : https://www.rentsoft.cn
OpenIM官方论坛: https://forum.rentsoft.cn/
更多技术文章:
开源OpenIM:高性能、可伸缩、易扩展的即时通讯架构
https://forum.rentsoft.cn/thread/3
【OpenIM原创】简单轻松入门 一文讲解WebRTC实现1对1音视频通信原理
https://forum.rentsoft.cn/thread/4














 136
136











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









