






USENIX年度会议(USENIX Annual Technical Conference)是计算机体系结构的顶级会议之一,每年举办一次。2011年ATC会议的最佳论文奖被来自赛门铁克的一篇论文摘得:Building a High-performance Deduplication System。最近几年关于重复数据删除的研究达到了高潮,2011年FAST的最佳论文是一篇来自微软的关于重复数据删除的论文。
1 引子
评价一个重复数据删除系统,有三个标准:重删率,可扩展性和吞吐率。重删率说明了这个系统能挖掘出多少重复的数据,这是重删系统的主要目标,没有重删率,重删系统就没有意义;可扩展性指的是重删系统能否扩展到超大规模的数据量,同时对性能不产生影响或影响很小;吞吐率指的是系统处理数据的速度,关系到备份窗口等性能指标,重删肯定会对吞吐率造成一定影响,优秀的重删系统应尽可能减少影响。这三个标准都很重要,同时优化其中两个比较容易,但同时优化三个标准就非常困难了。这篇文章就是按照这三个标准构建重删系统。
文章特别关注了重删系统的引用管理,这是被其它研究者忽略的问题。因为数据块是共享的,我们必须跟踪哪些文件引用了这个数据块,什么时候才能删除这个数据块。而且引用管理的开销和复杂性随着系统容量的增加而增加,根据作者部署重删产品的经验,引用管理的成本已经成为最大的瓶颈之一。
2 挑战
重删系统的索引是最难设计的,研究都集中在这一块。好的索引必须有高可扩展性、高吞吐率和高重删率,但是很难同时满足三个目标。比如实现完美重删率的系统,扩展到超大规模的数据量时吞吐率势必会下降(磁盘瓶颈问题),而要同时满足高可扩展性和高吞吐率,势必又要牺牲部分重删率。
引用管理必须追踪数据块的使用情况,并释放空闲数据块。除了可扩展性和吞吐率外,引用管理的可靠性也是一大挑战(关于重删可靠性的研究),面向产品的重删系统必须提供高可靠性。大多数重删系统忽略了引用管理的问题,少部分使用简单的引用计数。引用计数的可靠性很差,而且不可恢复。为了保证引用计数的一致性,需要复杂的事务回滚逻辑,而且根本没有办法去判断一个引用计数是否正确。另外,一旦数据块损坏了,因为引用计数不知道引用数据块的是哪些文件,没有办法进行恢复。为每个数据块维护一个引用链表,在可靠性和可恢复性方面表现更好,但是更新变长的引用链表的开销很大。还有一种办法是标记和清除,扫描系统里的所有文件,标记使用的数据块,释放未标记的数据块,这种方法可靠性最好,但是代价也最高。
在一个C/S结构的重删系统中,即时解决了索引和引用管理问题,端到端的性能仍然会受限于客户端。典型的客户端按照以下顺序执行:1)读取文件数据;2)分块和计算指纹;3)发送指纹到服务器,等待服务器的查询结果;4)发送服务器未查询到的数据块。这里就有三种类型的瓶颈,读取文件是I/O受限操作,计算指纹是CPU密集型操作,网络也非常可能成为全局性能瓶颈。
为了解决这些问题,作者提出了三种应对方法:
- 渐进式抽样索引;
- 分组的标记和清除;
- 模块化、流水线客户端。
3 原型设计
3.1设计目标和体系结构
当设计系统时,系统性能的目标有三:
- 可扩展性:可以存储和索引数千亿(hundreds of billions)个数据块。设平均块长4KB,则需存储超过400TB的数据,完整指纹索引超过2TB。
- 重删率:尽最大努力重删。如果系统资源有限,就牺牲少部分重删率换取速度和可扩展性。
- 吞吐率:接近磁盘裸读写速度。
为了验证想法的有效性,作者用C++和pthreads库实现了一个原型系统,体系结构如图1所示。
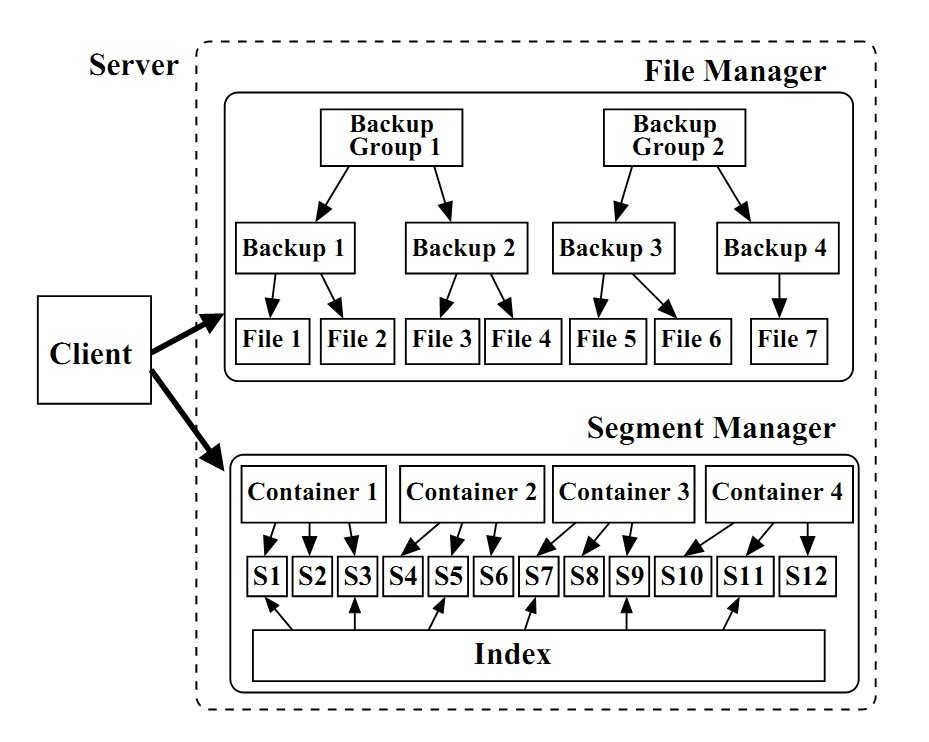
图1 客户端和重删服务器组件。重删服务器组件可以位于不同节点上。
服务器端由文件管理模块(File Manager,FM)和数据块管理模块(Segment Manager,SM)组成。FM使用三层结构管理存储在服务器上的文件:最底层是文件;中间是备份,代表一次备份作业;在顶层,多个备份构成一个备份组,引入备份组是为了粗粒度地跟踪系统中修改的文件,帮助引用管理。
SM负责存储和索引数据块。在磁盘上,数据块被组织成更大的存储单元——容器(container),每个容器的元数据记录了自己拥有的数据块的指纹。磁盘的读写都是以容器为单位的,将临近的数据块存储在同一个容器可以极大地提高吞吐率(这无疑是学习了DDFS)。SM还管理着一张索引。
客户端负责读取文件数据,分块和计算指纹,在查询了SM的索引后,将新的数据块发送至服务器。每备份完一个文件,FM就更新该文件的元数据。
3.2 渐进式抽样索引
保存完整的指纹索引很难达到高可扩展性,所以采取抽样的方法,每T个指纹抽样一个指纹,这样索引就缩小到原来的1/T。这么做导致索引的命中率也减到1/T,但是考虑一下数据流的局部性:如果上一次备份A和B是连续出现的,那么这一次备份A和B非常可能仍是连续出现的。如果我们每次命中抽样指纹,就将该抽样指纹所属的容器里的所有指纹读到缓存,那么接下来接收到的指纹虽然在索引未命中,但是大多数会出现在缓存中,这非常有效地提升了重删率。因此,抽样率是有下限的,至少得保证每个容器有一个抽样。
但是系统不可能一开始就用光所有存储容量,实际上需要索引的只是系统的已用存储容量,因此作者提出了渐进式抽样索引:根据当前系统已使用存储容量和可用内存计算抽样率。最开始抽样率设为1,当系统已使用容量不断上升,内存容量不能支持抽样率为1时,就将抽样率减半,比如丢弃取2的摸不为0的指纹。以此类推。
在实现时,索引和缓存都是用哈希表。索引用哈希表按固定大小的桶(bucket)进行划分,每个桶又包含了很多条目。其中2^b个桶用于哈希,每个条目记录一个抽样指纹(只需要记录一部分,因为指纹有b位被用来哈希)和所属容器的编号。剩下的桶用于冲突处理。
用于缓存的哈希表也同样被划分为桶,但是使用不同的冲突处理方式,因为索引考虑的是准确性,而缓存考虑的是效率。当桶Q发生冲突(满了),缓存用哈希表可以使用三种逐出策略:1)立即逐出。认为所有与Q相关的容器都被逐出了,并清空Q。这种逐出策略很快,但是同时逐出了多个容器(假逐出,除了Q中的条目外,这些容器的其它指纹都还在缓存中)2)根据阀值逐出。也是清空Q,但是设置一个阀值,当容器中一定比例的指纹被移除后,才认为该容器被逐出了。当阀值很高时,可能降低重删率,因为即使很多指纹已经被移除了,该容器仍然没有被逐出,所以也就不能再次预取。3)LRU。逐出最近最少使用的容器,如果Q的空间没有得到释放,就继续执行LRU。这种办法重删率最高,但是代价也最高。默认使用的是立即逐出策略,这能获得较好的重删率,同时仅比阀值逐出慢一点。
3.3 分组标记和清除
引用管理的挑战是同时保证可靠性和速度。标记和清除办法很可靠,但是可扩展性很差,因为需要访问系统的每一个文件。所以作者提出了分组标记和清除(GMS),避免在标记时访问每一个文件和在清除时访问每一个容器。因此GMS的效率和系统规模无关,只和变化多少有关。GMS主要的工作在FM,FM监控着系统的文件、备份和备份组,文件和备份的创建和内容是用户控制的。而备份组完全是由FM创建和管理的,当备份很小时,就将多个小备份聚合成一个备份组。FM会跟踪每一个备份组的变化,GMS的过程过程如下:
- 标记已变化的备份组。每个备份组都有一张位图(比如,Group1的位图是G1),记录了它引用了哪些容器的哪些块,对于修改了的备份组,需要重新计算位图。如图2所示,假设自上一次执行GMS以来,FM的记录显示Group1删除了一些文件,Group2没有变化,Group3新增了一些文件。所以我们只需要访问Group1和Group3里的文件,遍历这些文件后,重新计算G1和G3。图2中,重新计算后的Group1的结果G1显示,容器1和容器2和Group1有关,容器2和容器5和Group3有关。
- 添加受影响的容器到清除列表。只有被删除了文件的备份组使用的容器才需要被清理。图2中,Group1删除了一些文件,而且和容器1和容器2有关,所以将这两个容器放入清除列表。
- 合并,清除,释放空间。对于每一个在清除列表中的容器,利用位图得到所有和它们相关的备份组,然后合并这些备份组的标记结果(除了重新计算的G1和G3,其它的标记结果都沿用上次的计算结果),比如Group1和Group3都使用了容器2,所以合并它们的位图,就可以知道容器2中哪些块是可以释放的了。

图2 GMS示意图
可以看出,GMS的好处是可以利用未修改的备份组的旧位图(如G2),避免了标记阶段访问所有的文件。通过扫描执行了删除操作的备份组,GMS知道哪些容器涉及到删除操作,因此只需要清扫一部分容器。GMS的缺点是粒度比较粗糙,即时备份组只修改了一个文件,也要遍历备份组的所有文件。
GMS的位图提供了粗粒度的引用列表。当数据块损坏了,可以利用位图快速找出哪个备份组引用了此数据块,进而只需要扫描此备份组的文件,避免了扫描全部文件。找到文件后就可以修复数据块了。
3.4 客户端-服务器的交互
如果客户端不能快速地向服务器发送数据,服务器再快也没有用。因此,客户端被设计成事件驱动、流水线,利用了RPC协议。实现RPC时,消息传递机制分为TCP(远程)和IPC(本地)。为了满足性能要求,用TCP实现的RPC协议会保持多个TCP连接,为了减少来回的开销和提高吞吐率,所有的RPC请求都是异步的。图3显示了客户端流水线的结构。
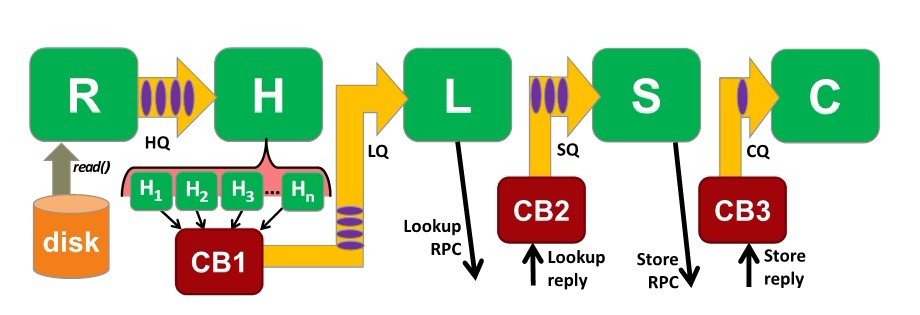
图3 客户端的流水线,包含五个主要线程和四个队列
首先,读线程R负责从磁盘读取数据,然后将请求加入HQ队列(hash queue)。哈希线程H从HQ队列中读取请求,然后对数据进行分块和计算指纹,计算指纹是比较耗时的操作,因此采用多个哈希进程,当一个数据块的指纹计算完毕时,回调函数CB1就将请求加入查询队列LQ(lookup queue)。
查询线程L从LQ读取请求,向服务器发起一个查询RPC请求,注意这是批处理的,每256个指纹一次请求。回调函数CB2接收服务器的查询结果,如果有指纹在服务器没有找到,CB2将请求加入存储队列SQ。
存储线程S从SQ中读取请求,并且将数据发送给服务器。CB3接收来自服务器的确定消息,并且将最后的请求加入关闭队列CQ(close queue)。
最后关闭线程C从CQ中读取请求,计算文件的元数据,并更新FM。
客户端的几个队列可以帮助我们观察系统的行为。比如,系统计算哈希很慢的话,队列HQ经常是满的;如果网络环境很差,LQ和SQ就会经常是满的。
4 评价
作者的实验环境是8核的至强E5450,32GB内存,12块磁盘组成的24TB的RAID0。数据集有两个,一个是合成数据集,包括几个3GB的文件,内部没有重复数据;另一个是现实数据集,包括四个虚拟机镜像文件,虚拟机是重复数据删除的主要应用领域之一,VM0安装了Windows XP,VM1在VM0基础上打了补丁,VM2在VM1上安装了杀毒软件,VM3在VM2基础上安装了几个应用软件。系统使用1/101的抽样率,4KB的块长。对于合成数据集,用了25GB的内存索引12.3亿个指纹,相当于存储了1240亿个指纹和500TB的数据。
4.1 吞吐率
4.1.1 备份吞吐率
作者分别测试了无重复数据和完全重复数据的吞吐率。如图4所示,横坐标是并发的备份数量,纵坐标是聚合吞吐率。测试数据集包括多个3GB的文件,一共768GB。
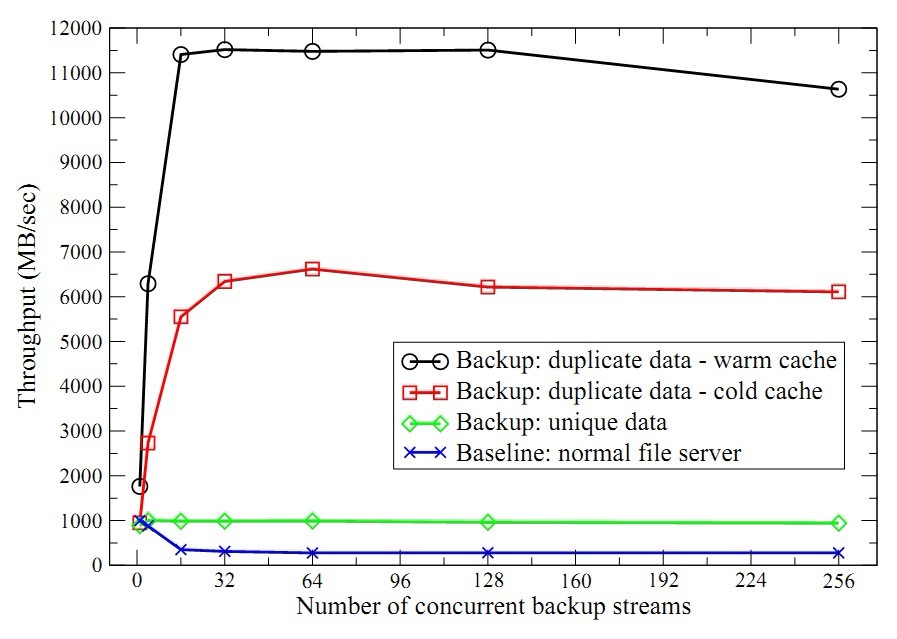
图4 合成数据集的聚合吞吐率,X轴是并发备份数。
第一次备份合成数据集,所有数据都是新的,此时系统的压力在磁盘和网络。前面提到吞吐率的目标就是达到磁盘的裸写性能,所以首先测试系统磁盘的裸性能作为性能的基准,即蓝线。实际上就是直接将合成数据集写入文件系统。对于单个备份作业,吞吐率达到1GB/s,但是备份作业增多时,吞吐率迅速下降到300MB/s。这是竞争磁盘导致的开销。而使用原型系统备份合成数据集,性能稳定在950MB/s,这是因为原型系统以容器为单位访问磁盘,减少了磁盘的并发访问。
第二次备份该合成数据集,所有的数据都是重复的,此时系统的压力在索引和磁盘预取。如图所示(红线),随着并发增多性能稳步上升,最终达到6.6GB/s,之后系统受限于磁盘预取操作。为了验证瓶颈是磁盘预取,作者第三次备份该数据集,此时很多指纹已经在缓存中,因此减少了磁盘预取。图4的白线显示性能得到到11.5MB/s,这就验证了磁盘预取是瓶颈。
表1 端到端吞吐率,单位MB/s

上面测试的是服务器的性能,接下来测试了端到端的性能。如表1所示,第一列表示分配给指纹计算的核,并且同样是备份三次。客户端是16核至强E5520处理器,32GB内存。第一次备份,超过4核以后性能就没有提升了,这是因为网络带宽只有10Gbps,第二、三次备份不用传输数据,所以不受带宽限制了。
测试结果显示,当数据集只有少量重复数据,系统性能达到或超过了文件系统吞吐率,这说明了原型系统能更好地组织数据;当数据集有大量重复数据,多个备份作业最大化了容器预取的吞吐率,因此改善了聚合吞吐率。而系统的限制主要是硬件,包括磁盘、CPU和网络,而软件唯一的限制是pthread锁。
4.1.2 引用更新吞吐率

图5 当系统存储空间很空或接近满负荷时,备份和删除操作的更新引用的时间。
删除操作设计的引用更新是很少测试的性能指标,图5的横坐标是操作涉及的数据量,纵坐标是时间。图中显示时间随着操作数据量的增加而线性增加,和系统的负荷没有关系。斜率就是引用更新的吞吐率,达到了3.2GB/s。和文件系统相比,删除操作比较慢,这是数据共享必然的代价。
4.1.3 恢复吞吐率
重删的论文都在讨论备份速度,而忽略了恢复的速度。这可能是因为恢复速度通常慢一些,而正确性的最重要的。对于单个恢复作业,吞吐率大概1GB/s,多恢复作业则下降到430MB/s。
4.2 重删率
采用抽样以后,解决了性能问题,然而能达到多少重删率确是得怀疑的。重删率主要取决于预取的有效性(强烈依赖于局部性,对于局部性不强的数据集,重删率折扣)。
对于合成数据集,备份三次,理想的重删率是100%,而原型系统可以达到97%(这里重删率的计算方式是用理想消耗的存储空间除以实际消耗的存储空间)。因为抽样率是1/101,所以每个容器的头100个指纹可能会丢失。
表2 连续备份虚拟机数据集的重删率
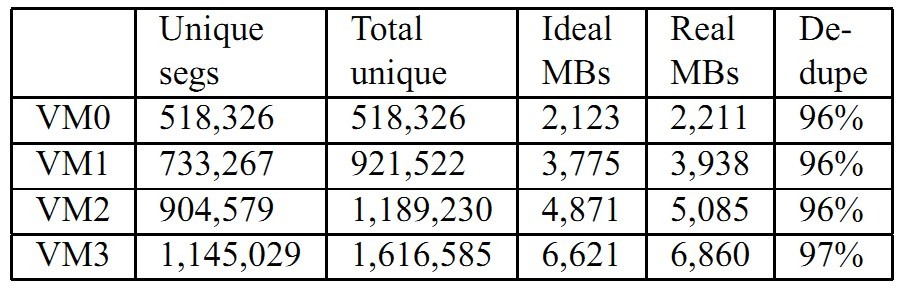
对于虚拟机数据集,表2显示了连续备份VM0、VM1、VM2、VM3的重删率。VM0有518 326个4KB的数据块,消耗了2 211MB的容量,重删率96%。接着备份VM1,引入了403 196个数据块,重删率是96%。类似的,接着备份VM2和VM3分别达到96%和97%重删率。
4.3 可扩展性
为了测试系统的可扩展性,首先将系统存满数据(用掉95%),因为磁盘阵列容量只有24TB,所以只存储元数据。因为备份并不需要使用这些数据块,所以并不会影响正确性。之后重复前面提到的性能测试,这时数据也要存储。
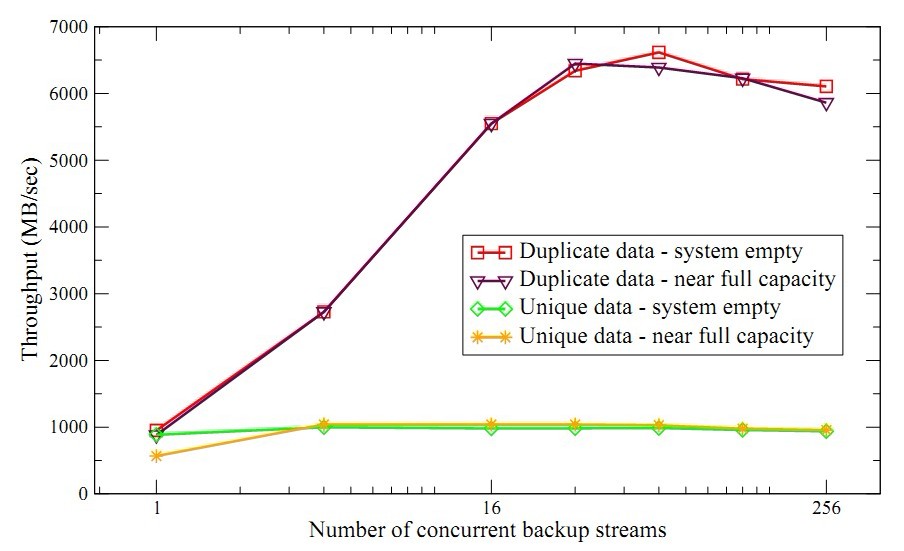
图6 可扩展性测试
图6是实验结果,横坐标是并发数,纵坐标是吞吐率。对于多备份流,系统的使用率对性能的影响微乎其微,当系统差不多满了,索引查询时间增加很少,主要的瓶颈仍是磁盘IO。
5 讨论
这篇文章能获得最佳论文奖,必有其独到之处,这也是为什么我要精读这篇文章。
重复数据删除技术至今没有一个统一的评价方法,各个研究者都有自己的实验方法,测试数据集。高校的研究者大多是自己实现原型系统,再用一些合成的数据集进行测试,这种实验的说服力就比较有限了。而企业有自己的商业化产品,第一手的实验数据,因此从企业出来的论文总是更受青睐一些,比如08年的DDFS。作者赛门铁克的背景肯定为其增光不少。
这篇文章是典型的基于备份数据流局部性的重删方案,关于利用局部性已经有不少文章出现,比如DDFS、Sparse Index等。DDFS实现的完美的重删,利用局部性来改善吞吐率,而Sparse Index和这篇文章有些像,都是进行抽样,愿意牺牲部分重删率,并依靠局部性来弥补重删率。因此,当局部性不强时(比如增量备份)DDFS损失的是吞吐率,而Sparse Index和本文损失的是重删率。
本文是强烈依赖局部性的,第一次全备份留下的容器是局部性很好的,但是不难发现,第二次、第三次乃至第N次备份新增加的容器的局部性却可能是很差的,因为对数据的修改可能离散分布在数据集里,因此离散的数据存储在一个容器里。当然这取决于数据集操作的特点,重复数据删除的表现非常依赖数据集的特点,很难从理论上建模分析,任何解决方案理论上都可以很容易构造一个不合适的数据集。这也是为什么企业的解决方案更受青睐,实践更重要!
文中抽样的一个亮点是渐进式的,在系统比较空闲时,其实是完美重删,只有当需要扩展到更高规模时,再逐渐增加抽样率。这无疑是个好想法,但是实验却没有去验证这个想法。
本文还提出了引用管理的解决方案,可靠性是实践中不可回避的问题。涉及可靠性应该是一大亮点吧,可靠性和重删应该是有一些矛盾的,可靠性总意味着一些冗余,而重删却是要消灭冗余。
关于客户端的流水线模型,目前越来越多的研究者注意到重删是一个各阶段冲突很少的技术,比较适合流水线作业,再配合现在的多核技术,对重删性能提升很大。
实验部分我认为做的不怎么好,数据集很简单,可以说高校也完全可以做出来。我认为对于修改比较频繁的数据集,文中的方案表现肯定是不够理想的。















 3186
3186

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









