




RecIS:Sparse to Dense,统一推荐模型训练框架的革命性突破
随着大模型时代的到来,推荐系统正经历着前所未有的技术变革。阿里巴巴团队推出的RecIS框架,成功解决了PyTorch生态中大规模稀疏训练与密集计算统一的技术难题,实现了训练吞吐量高达2倍的性能提升。本文将深入解析这一突破性框架的核心技术与实践价值。
论文标题:RecIS: Sparse to Dense, A Unified Training Framework for Recommendation Models
来源:arXiv:2509.20883 + https://arxiv.org/abs/2509.20883
PS: 整理了LLM、量化投资、机器学习方向的学习资料,关注同名公众号 「 AI极客熊 」 即刻免费解锁
文章核心
研究背景
现代推荐系统正在经历由数据量和计算能力扩展驱动的范式转变。在数据层面,这不仅包括扩展用户行为序列长度,还包括显著增加训练样本规模;在计算层面,正从传统MLP架构向基于Transformer的模型过渡,后者为大规模序列数据提供了卓越的可扩展性和表示能力。这种转变催生了大规模稀疏-密集混合架构,成为先进推荐系统事实上的标准框架。
研究问题
- 生态系统分裂:工业级推荐系统长期依赖TensorFlow,因其对大规模嵌入表、分布式训练和生产稳定性的成熟支持;而研究社区越来越青睐PyTorch,因其动态计算图、丰富生态系统以及与多模态和大语言模型的无缝集成
- 建模挑战:几乎所有前沿大模型的首次官方或社区实现都基于PyTorch,但PyTorch缺乏对稀疏建模的原生支持
- 系统挑战:大模型的PyTorch生态系统拥有完整的AI基础设施,但稀疏组件引入了新问题,如IO瓶颈、并发灾难和内存带宽限制
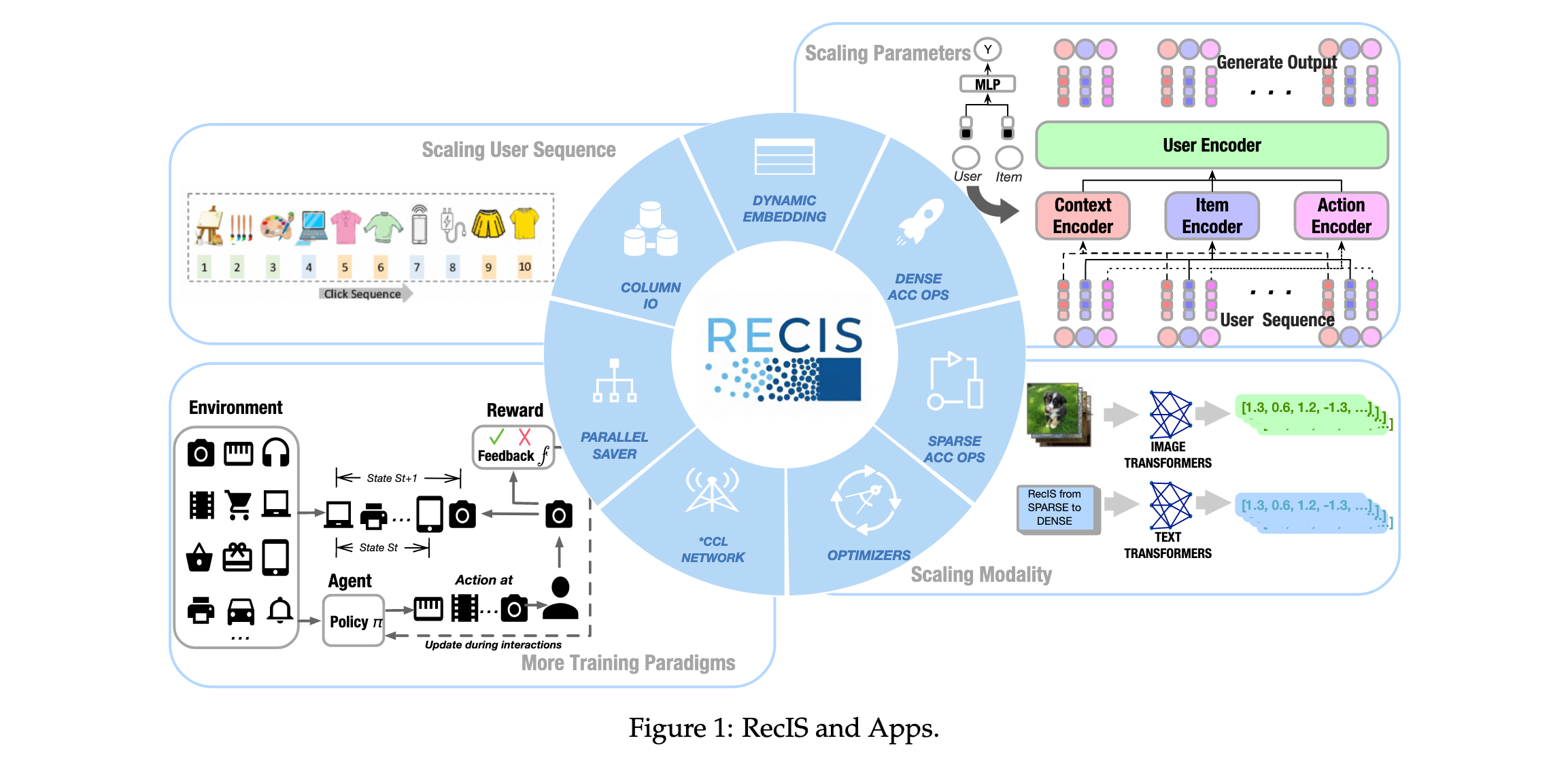
主要贡献
- 生产就绪的PyTorch统一稀疏-密集训练框架:提出RecIS框架,支持大规模稀疏训练,同时与现代大模型生态系统无缝集成。与TorchRec相比,该框架强调工业就绪性,支持无冲突嵌入、高效IO和稀疏处理
- 以内存为中心的性能建模:建立MBU(Model Bandwidth Utilization)作为推荐系统的第一类指标,类似于大模型中的MFU(Model FLOPS Utilization),为评估和优化系统效率提供了原则性方法
- 端到端性能优化:通过突破IO Bound、内存Bound和计算Bound,在大规模推荐任务上实现高达2倍的训练吞吐量提升
- 向后兼容性和部署:框架支持加载TensorFlow检查点和优化器,允许平滑迁移。已在多个生产任务中部署,包括搜索排名和广告定位等,在效率和模型准确性方面都带来了显著改进
方法论精要
RecIS(Recommendation Intelligent System)框架在PyTorch生态系统中创建统一的稀疏-密集训练框架,将TensorFlow稀疏组件优势与PyTorch大模型技术优势相结合。
系统架构设计
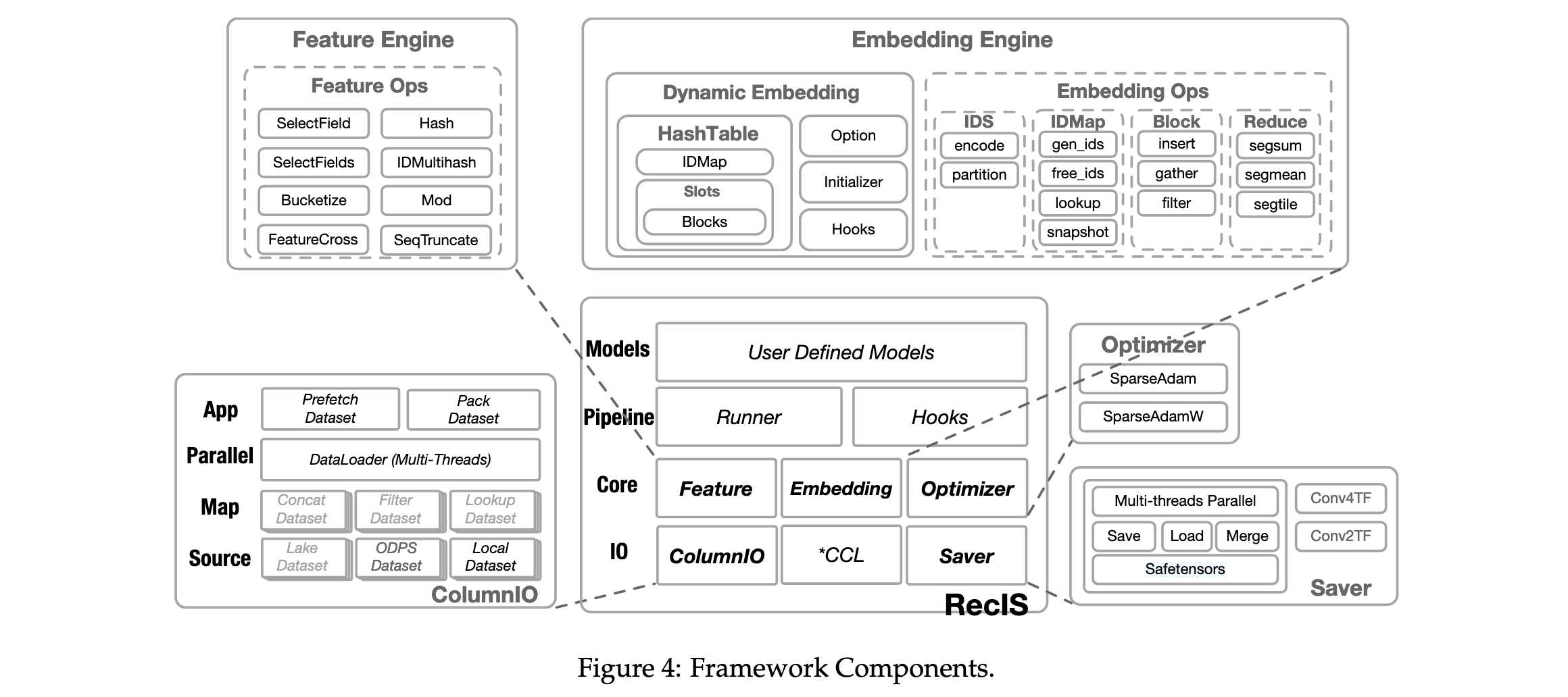
RecIS框架提供多个核心组件支持工业级稀疏训练:
ColumnIO组件:以分片方式高效读取多列样本,支持多种数据类型结构,批级静态表和秒级实时流表。
Feature Engine组件:支持特征预处理,包括特征转换、离散化、序列处理和特征交叉。
EmbeddingEngine组件:使用KV存储方法提供可扩展无冲突嵌入表,支持淘汰过时特征和高效计算。
Saver组件:使用SafeTensors格式并行加载/保存模型参数。
Optimizer组件:包括SparseAdam和SparseAdamW,保持与TensorFlow兼容性。
Pipelines组件:封装训练工作流,支持多阶段训练、在线学习和多任务训练。
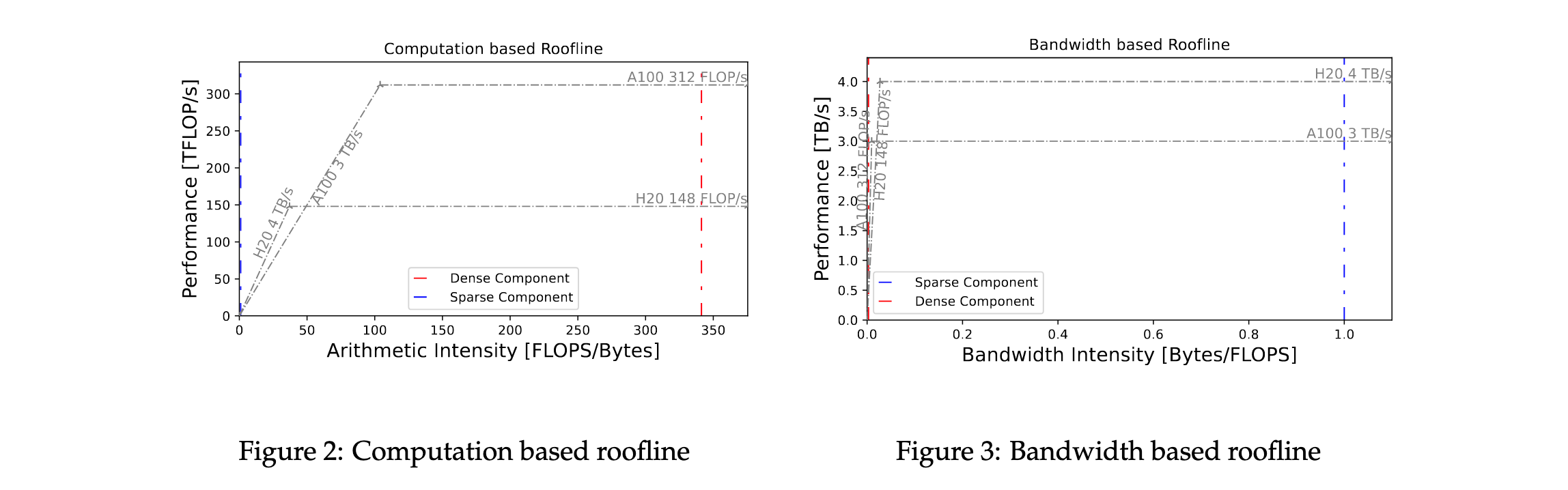
性能建模与优化理论
RecIS提出基于带宽的Roofline模型,专注于模型带宽利用率(MBU),为稀疏组件性能评估提供新方法。
三大突破性优化策略
突破IOBound:
- 列式存储格式消除行复制开销,提供零成本列选择
- 高并发和异步操作最大化I/O吞吐量
- GPU批处理充分利用GPU内存带宽
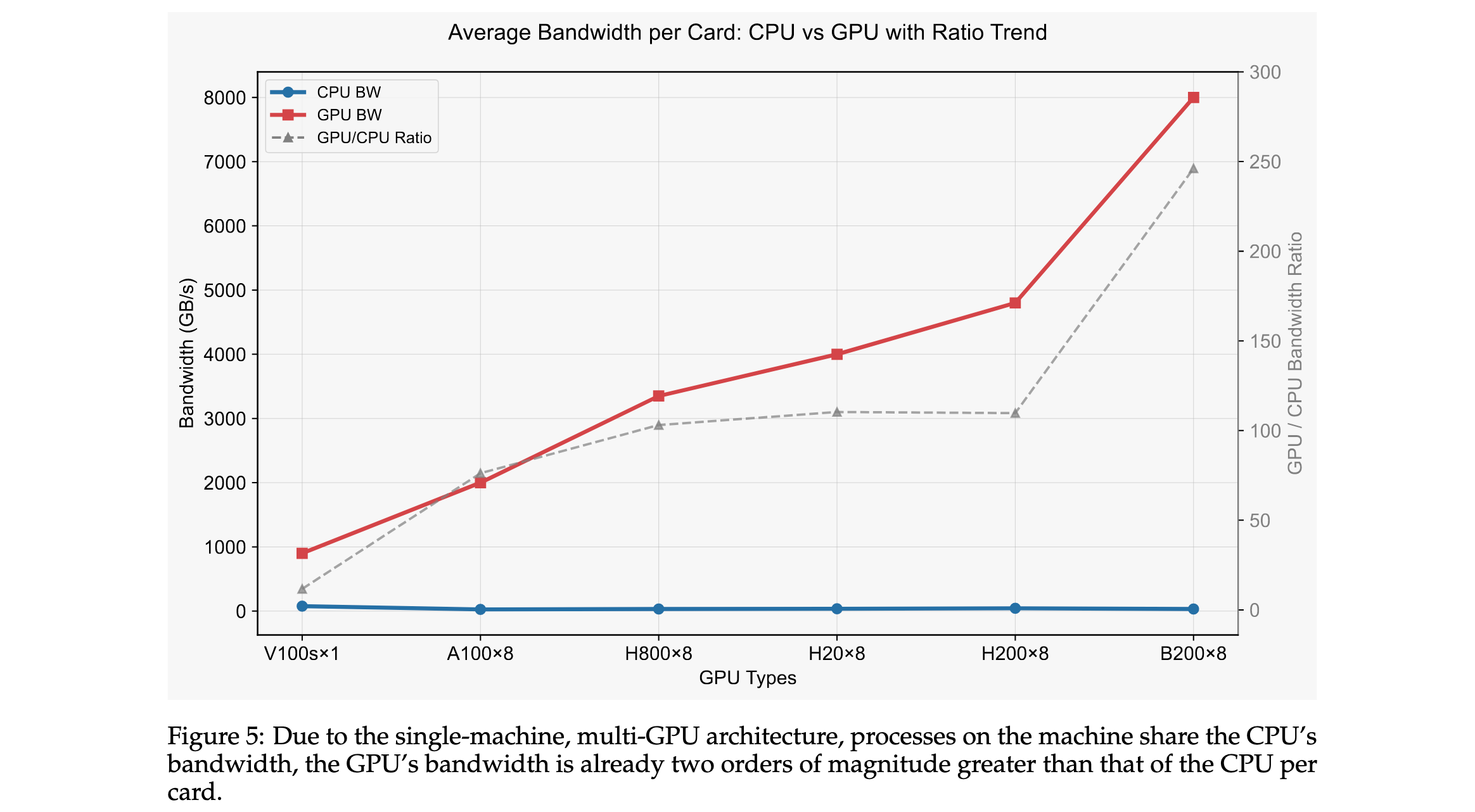
突破内存Bound:
- 转向GPU架构,利用GPU内存带宽优势
- 两层存储架构:IDMap(特征ID到偏移量映射)和Blocks(连续分片内存块)
- 负载均衡策略:参数聚合与分片、请求合并与分片、梯度更新
突破计算Bound:
- 混合精度训练:稀疏计算用FP32,密集注意力用FP16/BF16
- 融合内核:如FlashAttention和FusedSoftmaxCrossEntropy
- ZeRO优化器跨GPU分片模型状态
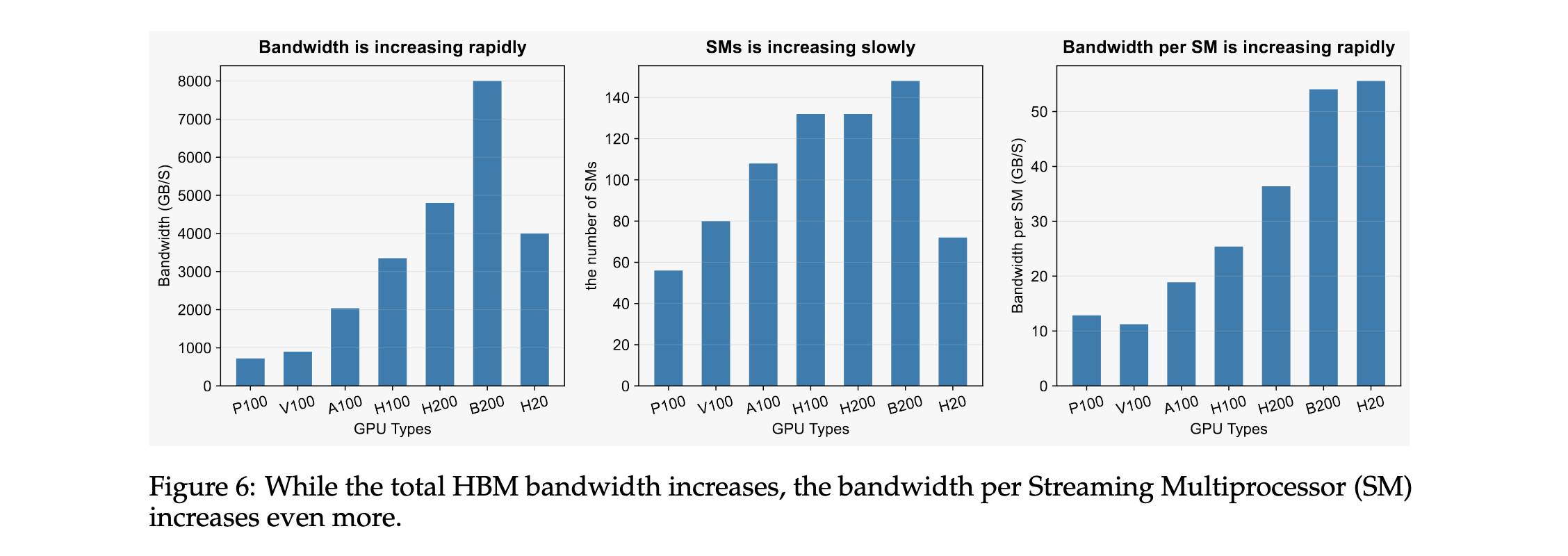
实验洞察
RecIS框架在操作器级别和端到端级别全面验证了其在稀疏-密集混合训练场景中的卓越性能。
operator级别性能评估
RecIS通过操作器融合、向量化内存访问和原子操作优化提高模型整体性能。关键操作器MBU对比结果:
- ids partition:RecIS 55.10% vs PyTorch 34.60%
- gather:RecIS 47.50% vs PyTorch 15.00%(3倍提升)
- scatter:RecIS 58.00% vs PyTorch 20.75%
- reduce easy:RecIS 13.75% vs PyTorch 2.75%
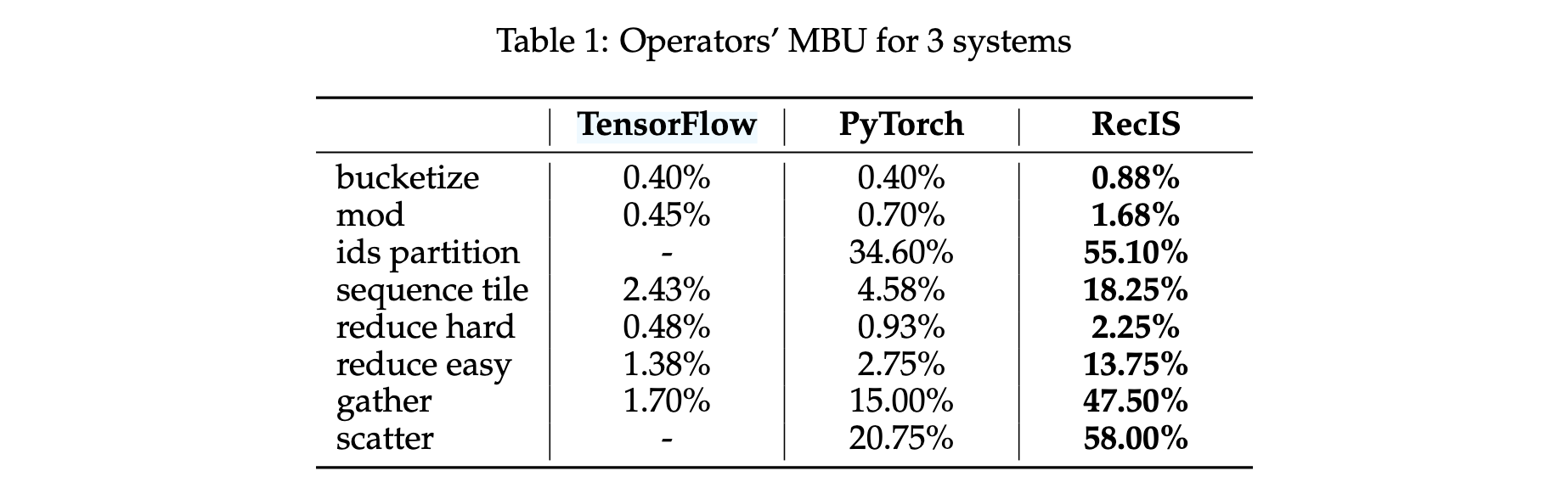
端到端性能评估
MSE模型(32张H20 GPU):
- 整体运行时间:RecIS为PyTorch的80%,TensorFlow的33%
- 稀疏计算时间:RecIS为PyTorch的72%,TensorFlow的30%
LMA模型(64张H20 GPU):
- LMA(16k):整体运行时间为TensorFlow的76%,稀疏计算时间为67%
- LMA(100k):TensorFlow无法处理,RecIS仍高效运行

生产环境应用效果
密集参数扩展:
- 相比TorchRec,每节点最大批处理大小增加200%
- 总体训练时间减少70%
- 5000万密集参数生成式排名模型部署后,同时提高点击率和转化率
用户序列扩展:
- 成功部署1M长度用户行为序列模型(100倍提升)
- 相比10k序列长度,CTR提高4.8%,训练成本降低50%
模态扩展:
- 通过集成大型通用基础模型与紧凑专家模块实现多模态理解
- 多个工业推荐场景A/B测试证明关键指标显著改进
RecIS框架在理论和实际应用中都展现了卓越性能,为推荐系统未来发展奠定坚实基础。



















 1804
1804

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









