







贝叶斯判别规则是把某特征矢量(x) 落入某类集群的条件概率当成分类判别函数(概率判别函数),x落入某集群的条件概率最大的类为X的类别,这种判决规则就是贝叶斯判别规则。贝叶斯判别规则是以错分概率或风险最小为准则的判别规则。
这是百度百科的解释,乍一看,有点不清楚,其实就是用贝叶斯公式,判别他属于某一个类别的概率。
贝叶斯公式
P(A∩B) = P(A) P(B|A) = P(B) P(A|B)
在此公式为:
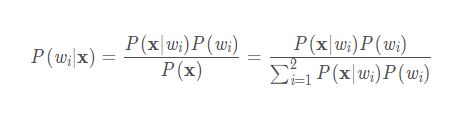
P(W|X)即为后验概率。
P(X|W),统计在W类中,发生X的概率,可以从概率密度函数理解
P(W)为先验概率,即不管其他的条件,统计出每个类发生的概率,可以是经验,也可以根据类别的个数比,比如去或者不去这个概率可能是一样的都为0.5,又比如人得癌症的概率,医学统计每一万个人中才会有一个人得癌症(好像是),所以根据经验,概率为万分之一,而不可能为二分之一
一般讨论
G1,G2为两个p维的总体,密度分别为f1(x),f2(x)
各总体的先验概率为p1=P(G1),p2=P(G2) ,p1+p2=1
样本X=(x1,x2,x3 …,xp),属于G1,G2的后验概率为:
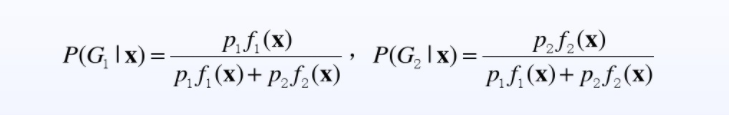
由于分母都是一样的,所以比较大小的话,只比较分子就可以。

两正态总体的贝叶斯判别
讨论两个分类的情况,并且这两个分类服从正态分布的总体
那么密度函数就为正态分布的概率密度函数
注意这里不是一维。两分类,对于每一个分类都可能有很多个特征,所以这里是协方差。
公式里p就是特征数,p如果等于1,那么协方差就变成方差,式子就是一维的概率密度函数。
图1
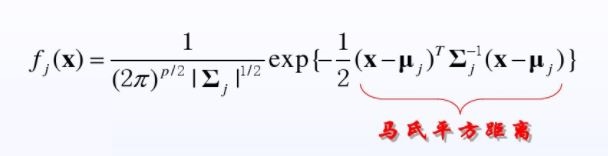
上面说过,分母一样,分子比较大小,那么前面的分子:
图2

注意大小相反,计算出来比较的是最小值。
对于两分类问题,比较d(x)的大小,那么当d1(x)和d2(x)相等的时候,就是他们的分离边界。
我们令d1(x) = d2(x)。
图3

- 由于这个式子左边是马氏距离,如果非黄色部分不看(假设协方差相等和先验概率相等,那么后面为常数),那么他就是距离判别分析。
- 假设两个类别的协方差相等,那么黄色部分的二次型展开以后,d1和d2二次项系数相等,可以消去,这时候就是线性判别分析。只含有一次项。
- 如果两个类别的协方差不相等,那么左边黄色部分是一个二次型,展开以后有二次项不能消去,那么就是非线性判别分析。
所以从贝叶斯角度理解这三种判别分析,也很简单明了。
问题:
那么首先就有个问题,判断协方差矩阵的相等问题,我搜了很多资料,但都没有把这个问题说的很详细,所以我也是一知半解,我们知道对于方差的检验有方差齐性检验,方法很多,但是对于协方差,包括在Python中都我都没有找到这种检验的方法。
但是在spss中有一个box’M检验,可以给出协方差等同性的概率值。这方面的资料的确太少。
在本文的最后会给出这种协方差检验的函数,至于为什么,我也是照着公式写的,不知道为什么。
下面分类讨论,主要讨论的是协方差相等时的算法,协方差不相等时,算法差不多,就不过于赘述
两总体协方差矩阵相同时
图4

因为d(x)与原判别大小相反,并且图2中有一个 -1/2的系数,
-1/2(d2(x)-d1(x)) = w2(x)-w1(x) 得到:
d2(x)-d1(x) =2( w1(x)-w2(x) )
而这个w(x)与原判别大小相同,所以我们用w(x)来计算,并且可以看出w(x)是线性的。
注意:由于协方差相等,所以用联合协方差带入计算,减的时候很多都可以消去,所以可以转换成w(x),而协方差不相等的时候就不能转换,也不能用w(x)计算。之所以用w(x)计算,是因为可以计算斜率和截距比较方便,因为一眼就看出他是线性的。
公式中黄色之外的 ln|Σ| 是行列式的对数,因为协方差相等,所以减的时候消去了。
举个例子
import numpy as np
import pandas as pd
import seaborn as sns
import matplotlib.pyplot as plt
sns.set(font="Simhei")
sns.set_style("darkgrid")
from sklearn.datasets import make_classification
x,y = make_classification(n_samples=500,n_features=2,n_informative=1, n_redundant=0, n_classes=2, n_clusters_per_class=1)
plt.scatter(x[:,0],x[:,1],c=y,cmap=plt.cm.BrBG_r)
用函数生成两类随机的点,只有两个类别。但是他们太正规了,我们稍微旋转一下。
x1 = x.dot(np.array([[10,2],[1,2]]))
plt.scatter(x1[:,0],x1[:,1],c=y,cmap=plt.cm.BrBG)
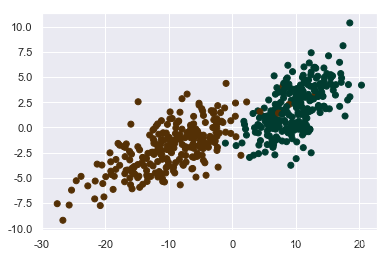
可以看出有很多的重合点,不用管它,现实里也不会有那么完美的数据。
这个分类是1和0,1是
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章















 2万+
2万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









