






点击左上方蓝字关注我们

AI Studio精品项目征集
AI Studio基于百度深度学习开源平台飞桨,为开发者免费提供功能强大的线上训练环境、云端超强GPU算力及存储资源。沉淀了90万+实训项目、5000+课时课程、90+场竞赛及7万+数据集,云集近100万AI开发者共同学习、交流、竞技与成长。
为扶持精品原创项目,帮助初中级开发者学习与实践,「AI Studio精品项目专栏」汇集近300名核心开发者,于学习、实战、比赛、趣味等多个方向贡献实训项目。
贡献精品项目可获得积分奖励兑换礼品,优质项目平台给予作者推荐曝光,还可以加入创作者核心群,进行技术交流、新产品体验,获取算力卡、节日礼品红包等,本季度还有罗技机械键盘、Apple Watch等超级福利,赶紧加入我们吧~
投稿地址:
https://aistudio.baidu.com/paddle/forum/topic/show/989159

PaddleNLP的小样本学习
进入正题~本期精品项目给大家带来PaddleNLP高Fork单篇项目:基于PaddleNLP的小样本学习策略库EFL实现中文科学文献学科分类。感谢作者Mr.郑先生_的投稿。
中国科学文献
学科分类数据集
该数据集是中文NLP定制的小样本学习测评基准:FewCLUE,9个场景的子数据集之一。共计有7979条数据,其中囊括67个类别的文献类别,这些类别来自于分别归属于13个大类,范围从社会科学到自然科学,文本为文献的中文摘要。
数据样例:

每一条数据有三个属性,从前往后分别是 id,sentence,label。其中label标签,Positive 表示正向,Negative 表示负向。
数据加载
PaddleNLP内置了 FewCLUE 数据集,可以直接用来进行训练、评估、预测。
# 安装最新版本的PaddleNLP!python -m pip install --upgrade paddlenlp==2.0.2 -i https://mirror.baidu.com/pypi/simple
from paddlenlp.datasets import load_dataset
# 通过指定 "fewclue" 和数据集名字 name="csldcp" 即可一键加载 FewCLUE 中的 csldcp 数据集train_ds, public_test_ds, test_ds = load_dataset("fewclue", name="csldcp", splits=("train_0", "test_public", "test"))
训练集、验证集和测试集的第一条数据
print(train_ds.data[0])# {'content': '为保证发动机在不同的转速时都具有最佳点火提前角,同时提高摩托车的防盗能力,提出一种基于转速匹配的点火提前角和防盗控制方法.利用磁电机脉冲计算发动机转速,线生调整点火信号的触发延迟时间,实现点火提前角的精确控制.根据转速信息,结合GSM和GPS对点火器进行远程点火使能控制,设计数字点火器实现对摩托车进行跟踪与定位,并给出点火器的软硬件结构和详细设计.台架测试和道路测试表明所设计的基于发动机转速的数字点火器点火提前角控制精确,点火性能好,防盗能力强、范围广.', 'label': '控制科学与工程', 'id': 805}print(public_test_ds.data[0])# {'content': '对黑龙江省东部五星Cu-Ni-Pt-Pd矿床的矿体和与成矿有关的镁铁质杂岩的PGE-Au以及铁族、亲铜元素的地球化学特征研究表明:它们均以亏损Cr、IPGE和富集Ni、Co、Cu、Pt和Pd(Pt<Pd)为特征,与成矿有关的镁铁质岩来自地幔部分熔融形成的玄武岩浆,岩浆(房)演化以结晶分离为主,伴随熔离作用.结合地质和岩相学特征,初步确定铜镍硫化物矿化在岩浆熔离作用的基础上产生,而铂钯矿化则主要发生在岩浆期后,以热液交代作用为主产生.因此,五星矿床是一个岩浆型铜镍硫化物和铂钯热液型复合的内生矿床.', 'label': '地质学/地质资源与地质工程', 'id': 0}print(test_ds.data[0])# {'id': 0, 'content': '金山金矿床是中国西天山地区一个大型浅成低温热液型金矿,矿体产出主要受各种断裂构造控制.在多年勘探工作的基础上,通过野外填图和大量的勘探线剖面分析,笔者总结出断裂构造活动经历了成矿前、热液成矿期和成矿后3期.断裂控矿基本规律是:北西向断裂总体控制矿床的分布位置,南北向断裂晚期活动造成叠加富集成矿,北东向断裂早期伴随中酸性岩脉活动,成矿后活动造成矿体断开和升降,东西向-北西西断裂早期伴随火山喷发活动,成矿后活动切断南北向矿体.同时还总结了矿区的找矿评价标志.'}
构建小样本学习器
小样本学习器是基于Entailment构建的。大型预训练语言模型(LMs)作为小样本学习器已经表现出了非凡的能力,然而,他们的成功在很大程度上取决于模型参数量的提升,这使得其训练,部署和服务具有挑战性。
在《Entailment as Few-Shot Learner》中,作者提出了一种新的方法,名为EFL(Entailment as Few-shot Learner),它可以将小的语言模型变成更好的小样本学习器。这种方法的关键思想是将潜在的NLP任务重新表述为一个entailment任务,然后只需用8个例子就可微调模型。
EFL方法可以:
与基于无监督的对比学习的数据增强方法自然结合;
容易扩展到多语言的小样本学习。
对18个标准的NLP任务进行的系统评估表明,这种方法将现有的各种SOTA几率学习方法提高了12%,并产生了与500倍大的模型(如GPT-3)具备竞争性的小样本性能。
EFL的训练源代码(部分):
class ErnieForSequenceClassification(ErniePretrainedModel): def __init__(self, ernie, num_classes=2, dropout=None): super(ErnieForSequenceClassification, self).__init__() self.num_classes = num_classes self.ernie = ernie # allow ernie to be config self.dropout = nn.Dropout(dropout if dropout is not None else self.ernie.config["hidden_dropout_prob"]) self.classifier = nn.Linear(self.ernie.config["hidden_size"], num_classes) self.apply(self.init_weights)
def forward(self, input_ids, token_type_ids=None, position_ids=None, attention_mask=None): _, pooled_output = self.ernie( input_ids, token_type_ids=token_type_ids, position_ids=position_ids, attention_mask=attention_mask)
pooled_output = self.dropout(pooled_output) logits = self.classifier(pooled_output) return logits
从代码上可以看出,其核心内容还是Ernie,然后在最后加了一层全连接层,num_classes=2,也就是说EFL将 NLP Fine-tune 任务转换统一转换为 Entailment 2 分类任务。
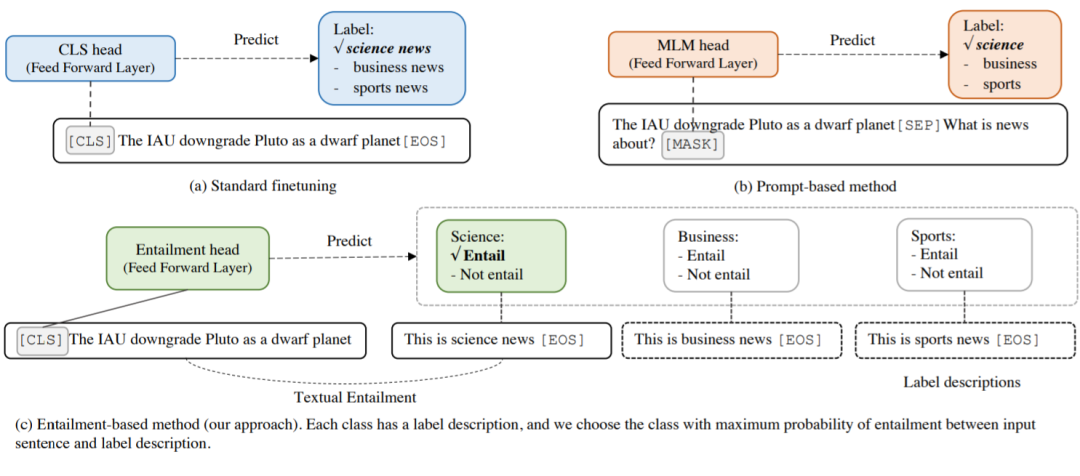
a、b、c子图分别代表分类问题的标准微调
基于提示的方法和使用基于Entailment的微调。
与基于提示的方法相比,这种方法的主要区别在于将任务重新定义为Entailment任务而不是“完形填空”,并设计细粒度的标签描述而不是单个任务描述。因此能在小样本场景下取得不错的效果。
模型训练
train.py参数含义说明:
task_name: FewCLUE 中的数据集名字
device: 使用 cpu/gpu 进行训练
negative_num: 负样本采样个数,对于多分类任务,负样本数量对效果影响很大。负样本数量参数取值范围为 [1, class_num - 1]
save_dir: 模型存储路径
batch_size:每个GPU/CPU的训练批大小
learning_rate:Adam的初始学习速率
epochs:要执行的训练总数
max_seq_length: 文本的最大截断长度
!python -u -m paddle.distributed.launch --gpus "0" \ work/train.py \ --task_name "csldcp" \ --device gpu \ --negative_num 66 \ --save_dir "./checkpoints" \ --batch_size 32 \ --learning_rate 1e-5 \ --epochs 2 \ --max_seq_length 512
模型效果评估
!python -u -m paddle.distributed.launch --gpus "0" \ work/predict.py \ --task_name "csldcp" \ --device gpu \ --init_from_ckpt "./checkpoints/model_2246/model_state.pdparams" \ --output_dir "./output" \ --batch_size 32 \ --max_seq_length 512
前10个预测结果查看:
{"id": 0, "label": "矿业工程"}{"id": 1, "label": "交通运输工程"}{"id": 2, "label": "畜牧学/兽医学"}{"id": 3, "label": "公共卫生与预防医学"}{"id": 4, "label": "心理学"}{"id": 5, "label": "核科学与技术"}{"id": 6, "label": "应用经济学"}{"id": 7, "label": "艺术学"}{"id": 8, "label": "口腔医学"}{"id": 9, "label": "机械工程"}
最后结果分析:
从结果上可以看出,“矿业工程”、“交通运输工程”、“核科学与技术”和“机械工程”这些偏理工科的学科,模型预测的效果比较好,其原因是这些学科分类比较明显,所以也很好区分;
但是,“口腔医学”属于门类复杂的学科,模型的预测效果较差,模型需要花更多的时间进行学习。
总结
在EFL中,因为是小样本学习,因此增加数据是非常有必要的,negative_num参数用来配置负样本采样个数,对于多分类任务,负样本数量对效果影响很大,负样本数量参数取值范围为 [1, class_num - 1],这个参数可以尽可能地大一些,这样模型的效果会好一些。
项目地址:
https://aistudio.baidu.com/aistudio/projectdetail/2117875
论文《Entailment as Few-Shot Learner》地址:
https://arxiv.org/pdf/2104.14690.pdf
今天的分享就先到这里啦,我们下次再见~~~
等等,又到了本次福利发放时间!
1.转发本条推文至朋友圈,点赞数最高的2位同学将获得定制保温杯一个。
2.转发本条推文至两个100人以上AI相关社群(非飞桨相关群),时间最早的2位同学将获得定制保温杯一个。二者不可同时获得哦~
截止时间:7月29日12点,大家记得把截图发给小助手,保温杯照片如下图~

快扫描下面的二维码添加小助手吧!

搜寻更多趣味项目,请点击“阅读原文”访问AI Studio官网。
飞桨(PaddlePaddle)以百度多年的深度学习技术研究和业务应用为基础,集深度学习核心训练和推理框架、基础模型库、端到端开发套件和丰富的工具组件于一体,是中国首个自主研发、功能丰富、开源开放的产业级深度学习平台。飞桨企业版针对企业级需求增强了相应特性,包含零门槛AI开发平台EasyDL和全功能AI开发平台BML。EasyDL主要面向中小企业,提供零门槛、预置丰富网络和模型、便捷高效的开发平台;BML是为大型企业提供的功能全面、可灵活定制和被深度集成的开发平台。
END



















 1467
1467

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









