







岭回归
问题
在标准方程法里,我们推导出了求解回归系数的一个公式
w
=
(
X
T
X
)
−
1
X
T
y
w=(X^TX)^{-1}X^Ty
w=(XTX)−1XTy
这个公式一看就知道是有问题的,当
X
T
X
X^TX
XTX不是满秩的时候,不就求不了逆了吗?
若 X T X X^T X XTX不是满秩,也就是说明特征值中存在向量共线。
特征向量共线会带来另一个问题:过拟合。
就是说你画出的曲线弯弯扭扭,过于复杂,稍微改变一点参数的值,变化就很大。
这个其实好理解,说白了就是你就那么一点儿数据,还整一大堆特征,比如X是三行五列,三个数据,五个特征。
学过线性代数的都知道,那 X T X X^T X XTX是必不可能满秩的。
还整5个参数,就肯定过于复杂了,也就过拟合了。
那解决过拟合问题有什么办法吗?
- 减少特征:你就这么点数据,不适合建一个复杂的模型,把一些特征砍了吧
- 增加数据量:数据越多,模型当然越复杂,就配得上这么多的特征了
- 正则化
正则化
J ( θ 0 , θ 1 , … , θ n ) = 1 2 m ∑ i = 1 m ( y i − h θ ( x i ) ) 2 J(\theta_0,\theta_1,…,\theta_n) = \frac{1}{2m}\sum_{i=1}^{m}{(y^i-h_\theta(x^i))^2} J(θ0,θ1,…,θn)=2m1i=1∑m(yi−hθ(xi))2
代价函数原来是长这样的,我们的目的一直都是找到一个向量 θ \theta θ是的J达到最小。
上文说到,如果存在共线问题,那么就容易出现过拟合。
怎么避免呢?就是使J的大小不完全由残差(y-h)决定,我们把代价函数改成这样
J
(
θ
0
,
θ
1
,
…
,
θ
n
)
=
1
2
m
(
∑
i
=
1
m
(
y
i
−
h
θ
(
x
i
)
)
2
+
λ
∑
i
=
1
m
θ
i
2
)
J(\theta_0,\theta_1,…,\theta_n) = \frac{1}{2m}(\sum_{i=1}^{m}{(y^i-h_\theta(x^i))^2}+\lambda\sum_{i=1}^m\theta_i^2)
J(θ0,θ1,…,θn)=2m1(i=1∑m(yi−hθ(xi))2+λi=1∑mθi2)
这样一来J就不完全由残差决定,削弱了最小二乘法的作用。
岭回归的公式推导
上面得到了一个新的代价函数,我们还是要让它最小,当然还是求导,令其为0,解方程。
上回的标准方程法我们推出
0
−
X
T
y
−
X
T
y
+
2
X
T
X
θ
=
0
0-X^Ty-X^Ty+2X^TX\theta=0
0−XTy−XTy+2XTXθ=0
这回还是一样,无非后面再加一项
λ
∑
i
=
1
m
θ
i
2
=
λ
θ
T
θ
\lambda\sum_{i=1}^m\theta_i^2=\lambda\theta^T\theta
λi=1∑mθi2=λθTθ
∂ λ θ T θ ∂ θ = 2 λ θ \frac{\partial \lambda\theta^T\theta}{\partial \theta}=2\lambda\theta ∂θ∂λθTθ=2λθ
所以
0
−
X
T
y
−
X
T
y
+
2
X
T
X
θ
+
2
λ
θ
=
0
0-X^Ty-X^Ty+2X^TX\theta+2\lambda\theta=0
0−XTy−XTy+2XTXθ+2λθ=0
解得
θ
=
(
X
T
X
−
λ
E
)
−
1
X
T
y
\theta=(X^TX-\lambda E)^{-1}X^Ty
θ=(XTX−λE)−1XTy
此时我们发现,若
X
T
X
X^TX
XTX不满秩的话,没关系,
(
X
T
X
−
λ
E
)
−
1
(X^TX-\lambda E)^{-1}
(XTX−λE)−1一定是满秩的。
我们称 λ \lambda λ为岭系数
难就难在这个岭系数的选取上,如果选的太大,欠拟合,选的太小,过拟合。可以使用交叉验证的办法来选取一个最合适的系数。
python代码
#encoding:utf-8
import numpy as np
from sklearn import linear_model
# 读取数据
data = np.genfromtxt("../data/longley.csv",delimiter=',')
x_data = data[1:,2:]
y_data = data[1:,1]
# 创建模型
# 生成50个备选的岭系数
alphas2test = np.linspace(0.001,1)
# 用交叉验证法找最合适的岭系数
model = linear_model.RidgeCV(alphas=alphas2test,store_cv_values = True)
model.fit(x_data, y_data)
# 查看岭系数
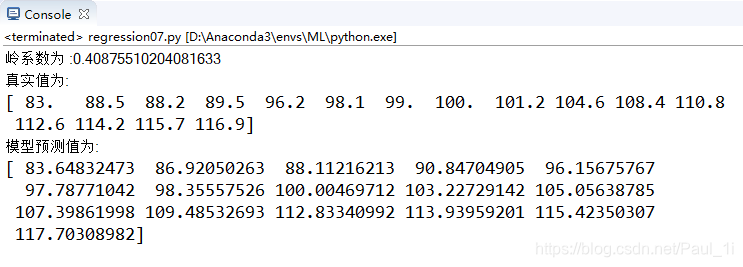
print("岭系数为 :{0}".format(model.alpha_))
print("模型真实值为: ")
print(y_data)
print("模型预测值为:")
print(model.predict(x_data))














 3068
3068











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









