



 本文介绍了Shell脚本的基础知识,包括简单的脚本示例、调试工具bashdb的安装及使用方法、条件判断语句、循环结构、函数定义及调用方式,以及I/O重定向的应用。
本文介绍了Shell脚本的基础知识,包括简单的脚本示例、调试工具bashdb的安装及使用方法、条件判断语句、循环结构、函数定义及调用方式,以及I/O重定向的应用。
1、第一个shell 脚本
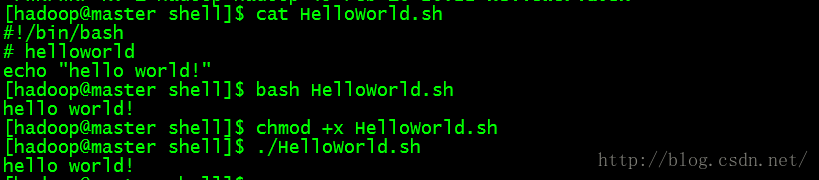
2、安装bashdb
第一步:下载适合自己bash version 的bashdb (https://sourceforge.net/projects/bashdb/files/bashdb/)
第二步:解压并进入解压后的目录
第三步:配置 ./configure
第四步:编译并安装 make && make install
注意:配置和编译安装要在root 用户在进行
第五步:验证 bashdb --debug

第六步:使用shell调试器bashdb
使用shell调试器bashdb,这是一个类似于GDB的调试工具,可以完成对shell脚本的断点设置,单步执行,变量观察等许多功能。
使用bashdb进行debug的常用命令
1.列出代码和查询代码类:
l 列出当前行以下的10行
- 列出正在执行的代码行的前面10行
. 回到正在执行的代码行
w 列出正在执行的代码行前后的代码
/pat/ 向后搜索pat
2.Debug控制类:
h 帮助
help 命令 得到命令的具体信息
q 退出bashdb
x 算数表达式 计算算数表达式的值,并显示出来
!!空格Shell命令 参数 执行shell命令
使用bashdb进行debug的常用命令(cont.)
控制脚本执行类:
n 执行下一条语句,遇到函数,不进入函数里面执行,将函数当作黑盒
s n 单步执行n次,遇到函数进入函数里面
b 行号n 在行号n处设置断点
d 行号n 撤销行号n处的断点
c 行号n 一直执行到行号n处
R 重新启动
Finish 执行到程序最后
cond n expr 条件断点
3、判断


3.1 if判断结构
[hadoop@master shell]$ vi t1.sh
echo "B"
#!/bin/bash
echo -n "input:"
read SCORE
if [ "$SCORE" -lt 60 ]; then
echo "C"
fi
if [ "$SCORE" -lt 80 -a "$SCORE" -ge 60 ]; then
echo "B"
fi
if [ "$SCORE" -ge 80 ]; then
echo "A"
fi3.2 if/else 判断结构
[hadoop@master shell]$ vi t2.sh
#!/bin/bash
FILE01=~/shell/t1.sh
FILE02=/home/hadoop/shell/t3.sh
if [ -e $FILE01 ]; then
echo "$FILE01 EXISTS"
else
echo "$FILE01 NOT EXISTS"
fi
if [ -e $FILE02 ]; then
echo "$FILE02 EXISTS"
else
echo "$FILE02 NOT EXISTS"
fi3.3 if/elif/else
[hadoop@master shell]$ vi t3.sh
1 #!/bin/bash
2 echo -n "input:"
3 read SCORE
4
5 if [ "$SCORE" -lt 60 ]; then
6 echo "C"
7 else
8 if [ "$SCORE" -ge 60 -a "$SCORE" -lt 80 ]; then
9 echo "B"
10 else
11 if [ "$SCORE" -ge 80 ]; then
12 echo "A"
13 fi
14 fi
15 fi3.4 case
[hadoop@master shell]$ vi t4.sh
1 #!/etc/bash
2 OS=`uname -s`
3 case "$OS" in
4 FreeBSD) echo "FreeBSD" ;;
5 SunOS) echo "Solaris" ;;
6 Darwin) echo "Mac OSX" ;;
7 Linux) echo "Linux" ;;
8 Minix) echo "Minix" ;;
9 *) echo "Failed" ;;
10 esac[hadoop@master shell]$ vi t5.sh
1 #!/bin/bash
2 read -p "give me a word:" input
3 case $input in
4 *[[:lower:]]*) echo -en "L" ;;
5 *[[:upper:]]*) echo -en "U" ;;
6 *[[:digit:]]*) echo -en "N" ;;
7 *) echo "unknow" ;;
8 esac4、循环
4.1 带列表的for循环
[hadoop@master shell]$ vi t6.sh
1 #!/bin/bash
2 fruits="apple orange banana pear"
3 for F in ${fruits}
4 do
5 echo "$F"
6 done
7 echo "no more"[hadoop@master shell]$ vi t7.sh
1 #!/bin/bash
2 sum=0
3 for v in {1..5}
4 do
5 let "sum+=v"
6 done
7 echo "$sum"
8
9 sum=0
10 #for v in `seq 1 10`
11 for v in $(seq 1 10)
12 do
13 let "sum+=v"
14 done
15 echo "$sum"
~[hadoop@master shell]$ vi t8.sh
1 #!/etc/bash
2 for v in `ls`
3 do
4 #echo "$v"
5 ls -l $v
6 done
4.2 while按行读取
# awk就是把文件逐行的读入,以空格为默认分隔符将每行切片,切开的部分再进行各种分析处理。
[hadoop@master shell]$ vi t1.sh
1 #!/bin/bash
2 cat stu_info.txt | while read LINE
3 do
4 NAME=`echo $LINE | awk '{print $1}'`
5 AGE=`echo $LINE | awk '{print $2}'`
6 SEX=`echo $LINE | awk '{print $3}'`
7 echo "my name is $NAME, I am $AGE years old, I am a $SEX"
8 done
# way1
while ((1))
do
echo "study study study"
done
# way 2
while true
do
echo "linux linux linux"
done
# way 3
while :
do
echo "shell shell shell"
done
[hadoop@master shell]$ vi t3.sh
1 #!/bin/bash
2 i=1
3 while [[ "$i" -le "9" ]]
4 do
5 j="$i"
6 while [[ "$j" -le "9" ]]
7 do
8 let "multi=$i*$j"
9 echo -n "$i*$j=$multi "
10 let "j+=1"
11 done
12 echo
13 let "i+=1"
14 done[hadoop@master shell]$ vi t4.sh
1 #!/bin/bash
2 for ((i=1; i<=9; i++))
3 do
4 for ((j=1; j<=9; j++))
5 do
6 if [[ $j -le $i ]]; then
7 let "multi=$i*$j"
8 echo -n "$i*$j=$multi "
9 else
10 break
11 fi
12 done
13 echo
14 done
[hadoop@master shell]$ vi t5.sh
1 #!/bin/bash
2 for ((i=1; i<=100; i++))
3 do
4 for ((j=2; j<i; j++))
5 do
6 if !(($i%$j)); then
7 continue 2
8 fi
9 done
10 echo -n "$i "
11 done
12 echo5 函数
5.1 位置参数
[hadoop@master shell]$ vi t6.sh
1 #!/bin/bash
2 function multi(){
3 let "RESULT=$1*$2"
4 echo $RESULT
5 }
6 multi $1 $25.2 指定脚本位置参数值
# 一旦使用set设置了传入参数的之,脚本将忽略运行时传入的位置参数
[hadoop@master shell]$ vi t7.sh
1 #!/bin/bash
2 set a b c d
3 COUNT=1
4 for i in $@
5 do
6 echo "\$$COUNT IS $i"
7 let "COUNT++"
8 done5.3 移动位置参数
shift 将位置参数整体向左移动 x 个位置
[hadoop@master shell]$ vi t8.sh
1 #!/bin/bash
2 until [ $# -eq 0 ]
3 do
4 echo "\$1:$1 -> total: $#"
5 shift
6 done5.4 递归函数
我们可以这样理解汉诺塔问题:要将A上的n个盘子按照要求移动到C上,我们可以想到:先将上边的 n-1 个盘子移动到B上,再将A上剩余的最大的盘子移动到C上,然后将B上所有的盘子移动到C上
[hadoop@master shell]$ vi t9.sh
1 #!/bin/bash
2 function hanoi() {
3 local num=$1
4 if [ "$num" -eq "1" ]; then
5 echo "move $2 -> $4"
6 else
7 hanoi $((num-1)) $2 $4 $3
8 echo "move $2 -> $4"
9 hanoi $((num-1)) $3 $2 $4
10 fi
11 }
12
13 hanoi 4 A B C
~6 I/O 重定向
6.1 标准输出覆盖重定向: >
6.2 标准输出追加重定向: >>
(输出的去向)
6.3 标识输出重定向: >&
标准输入(stdin)、标准输出(stdout)、标准错误输出(stderr)
eg:xxx > xxx.txt 2>&1
6.4 标准输入重定向: <
(输入的来源)
6.5 管道
将一个命令的输出作为另一个命令的输入



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











