




 MapReduce是Hadoop的分布式运算编程框架,其核心思想包括Map阶段和Reduce阶段的并行处理。MapTask和ReduceTask分别负责数据的处理和结果聚合,数据通过Shuffle过程进行分区和排序。MapReduce编程模型包括Mapper和Reducer阶段,需遵循特定的编程规范,如继承特定接口、定义数据序列化类型等。Hadoop序列化机制紧凑、快速、可扩展且支持多语言交互。MapTask的并行度由数据切片和配置参数决定,影响处理速度。 CombineTextInputFormat适用于处理大量小文件,提高效率。
MapReduce是Hadoop的分布式运算编程框架,其核心思想包括Map阶段和Reduce阶段的并行处理。MapTask和ReduceTask分别负责数据的处理和结果聚合,数据通过Shuffle过程进行分区和排序。MapReduce编程模型包括Mapper和Reducer阶段,需遵循特定的编程规范,如继承特定接口、定义数据序列化类型等。Hadoop序列化机制紧凑、快速、可扩展且支持多语言交互。MapTask的并行度由数据切片和配置参数决定,影响处理速度。 CombineTextInputFormat适用于处理大量小文件,提高效率。
1. MapReduce概述:
MapReduce是一个分布 式运算程序的编程框架,是用户开发“ 基于Hadoop的
数据分析应用”的核心框架。
MapReduce核心功能是将用户编写的业务逻辑代码和自带默认组件整合成一个
完整的分布式运算程序,并发运行在一个Hadoop集群 上。
1.2 MapReduce优缺点
优点
- MapReduce易于编程
它简单的实现- -些接口,就可以完成一一个分布式程序,这个分布式程序可
以份布到大量廉价的PC机器上运行。也就是说你写一个分布式程序, 跟写
-一个简单的串行程序是一模一样的。就是因为这个特点使得MapReduce编
程变得非常流行。
2.良好的扩展性
当你的计算资源不能得到满足的时候,你可以通过简单的增加机器来扩展
它的计算能力。
3.高容错性
MapReduce设计的初衷就是使程序能够部署在廉价的PC机器上,这就要求
它具有很高的容错性。比如其中一台机器挂了,它可以把上面的计算任务
转移到另外一个节点上运行,不至于这个任务运行失败,而且这个过程不
需要人工参与,而完全是由Hadoop内部完成的。
4.适合PB级以上海量数据的离线处理
可以实现上千台服务器集群并发工作,提供数据处理能力。
缺点
1.不擅长实时计算
MapReduce无法像MySQL- -样,在毫秒或者秒级内返回结果。
2.不擅长流式计算
流式计算的输入数据是动态的,而MapReduce的输入数据集是静态的,不能
动态变化。这是因为MapReduce自身的设计特点决定了数据源必须是静态的。
3.不擅长DAG (有向图)计算
多个应用程序存在依赖关系,后- -个应用程序的输入为前一一个的输出。在
这种情况下,MapReduce并不是不能做,而是使用后,每个MapReduce作业
的输出结果都会写入到磁盘,会造成大量的磁盘IO,导致性能非常的低下。
1.3 MapReduce核心思想
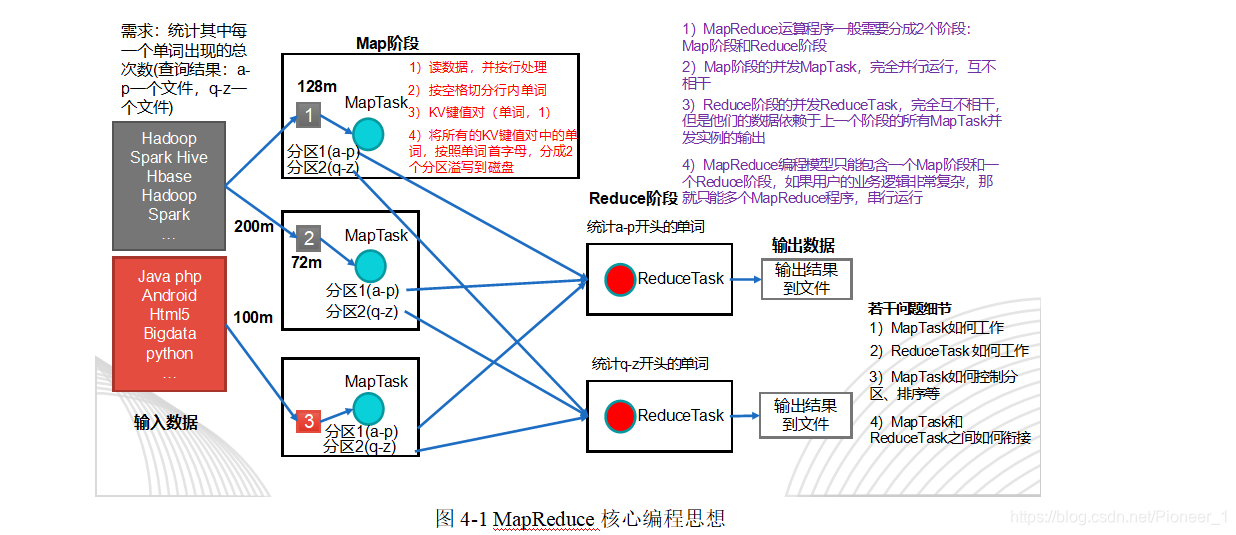
1)分布式的运算程序往往需要分成至少2个阶段。
2)第一个阶段的MapTask并发实例,完全并行运行,互不相干。
3)第二个阶段的ReduceTask并发实例互不相干,但是他们的数据依赖于上一个阶段的所有MapTask并发实例的输出。
4)MapReduce编程模型只能包含一个Map阶段和一个Reduce阶段,如果用户的业务逻辑非常复杂,那就只能多个MapReduce程序,串行运行。
总结:分析WordCount数据流走向深入理解MapReduce核心思想。
1.4 MapReduce进程
一个 完整的MapReduce程序在分布式运行时有三E类实例进程:
- MrAppMaster: 负责整个程序的过程调度及状态协调。
- MapTask:
负责Map阶段的整个数据处理流程。 - ReduceTask:
负责Reduce段的整个数据处理流程。
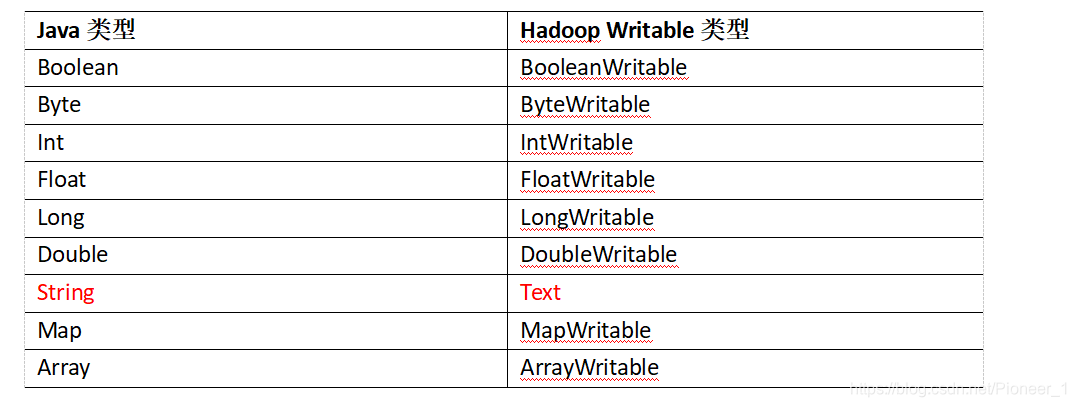
1.6 常用数据序列化类型
1.7 MapReduce编程规范
- Mapper阶段
(1)用户自定义的Mapper要继承自己的父类
(2) Mapper的输入数据是KV对
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 895
895

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









