







第一部分:矩阵的基础知识
1.结合性 (AB)C=A(BC).
2.对加法的分配性 (A+B)C=AC+BC,C(A+B)=CA+CB .
3.对数乘的结合性 k(AB)=(kA)B =A(kB).
4.关于转置 (AB)'=B'A'.
一个矩阵就是一个二维数组,为了方便声明多个矩阵,我们一般会将矩阵封装一个类或定义一个矩阵的结构体,我采用的是后者。
第二部分:矩阵相乘
矩阵相乘的规则:矩阵与矩阵相乘 第一个矩阵的列数必须等于第二个矩阵的行数 假如第一个是m*n的矩阵 第二个是n*p的矩 阵则结果就是m*p的矩阵且得出来的矩阵中元素具有以下特点:
第一行第一列元素为第一个矩阵的第一行的每个元素和第二个矩阵的第一列的每个元素乘积的和 以此类推 第i行第j列的元素就是第一个矩阵的第i行的每个元素与第二个矩阵第j列的每个元素的乘积的和。
单位矩阵: n*n的矩阵 mat ( i , i )=1; 任何一个矩阵乘以单位矩阵就是它本身 n*单位矩阵=n, 可以把单位矩阵等价为整数1。(单位矩阵用在矩阵快速幂中)若A为n×k矩阵,B为k×m矩阵,则它们的乘积AB(有时记做A·B)将是一个n×m矩阵。
其乘积矩阵AB的第i行第j列的元素为:

举例:A、B均为3*3的矩阵:C=A*B,下面的代码会涉及到两种运算顺序,第一种就是直接一步到位求,第二种就是每次求一列,比如第一次,C00+=a00*b00,C01+=a00*b01……第二次C00+=a00*b10,C01+=a01*b11……以此类推。。。
C00 = a00*b00 + a01*b10 + a02*b20C01 = a00*b01 + a01*b11 + a02*b21
C02 = a00*b02 + a01*b12 + a02*b22
C10 = a10*b00 + a11*b10 + a12*b20
C11 = a10*b00 + a11*b11 + a12*b21
C12 = a10*b02 + a11*b12 + a12*b22
C20 = a20*b00 + a21*b10 + a22*b20
C21 = a20*b01 + a21*b11 + a22*b21
C22 = a20*b02 + a21*b12 + a22*b22
C00 = a00*b00 + a01*b10 + a02*b20
C01 = a00*b01 + a01*b11 + a02*b21
C02 = a00*b02 + a01*b12 + a02*b22

其中c[i][j]为A的第i行与B的第j列对应乘积的和,即:
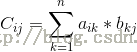
具体该怎么实现两个矩阵相乘呢?
一般会用O(n^3)的方法。。。配合剪枝【添条件,设门槛。。。】,如下:其实主要就是函数 MATRIX mat_multiply (MATRIX a , MATRIX b , int n);
//O(n^3)算法
#include <iostream>
#include <cstdio>
#include <cstring>
#include <cstdlib>
#include <cmath>
#include <algorithm>
using namespace std;
#define LL __int64
#define MOD 1000
typedef struct MATRIX
{
int mat[50][50];
}MATRIX;
MATRIX mat_multiply (MATRIX a,MATRIX b,int n)
{
MATRIX c; //c[i][j]= Σ a[i][k]*b[k][j]
memset(c.mat,0,sizeof(c.mat));
/*
for(int i=0;i<n;i++) //a矩阵一行一行往下
for(int j=0;j<n;j++) //b矩阵一列一列往右
for(int k=0;k<n;k++) //使a矩阵 第i行第k个元素 乘以 b矩阵 第j列第k个元素
if(a[i][k] && b[k][j]) //剪枝(添条件,设门槛),提高效率,有一个是0,相乘肯定是0
c.mat[i][j]+=a.mat[i][k]*b.mat[k][j];
*/
//上面也是可以的,但是下面的剪枝更好一些,效率更高一些,但是运算顺序有点难想通,,,
//上面就是C[i][j]一次就求出来,下面就是每次c[i][j]求出一项【就是上面红体字,每次各求一列】
for(int k=0;k<n;k++) //这个可以写到前面来,
for(int i=0;i<n;i++)
if(a.mat[i][k]) //剪枝:如果a.mat[i][k]是0,就不执行了
for(int j=0;j<n;j++)
if(b.mat[k][j]) //剪枝:如果b.mat[i][k]是0,就不执行了
{
c.mat[i][j]+=a.mat[i][k]*b.mat[k][j];
if(c.mat[i][j]>=MOD) //这个看实际需求,要不要取模
c.mat[i][j]%=MOD; //取模的复杂度比较高,所以尽量减少去模运算,添加条件,只有当大于等于MOD的时候才取余
}
return c;
}
int main()<span style="white-space:pre"> </span>//这个只是用来测试用的。。。
{
int n;
MATRIX A,B,C;
memset(A.mat,0,sizeof(A.mat));
memset(B.mat,0,sizeof(B.mat));
memset(C.mat,0,sizeof(C.mat));
scanf("%d",&n); //矩阵规模,这里是方阵,行数等于列数
for(int i=0;i<n;i++) //初始化A矩阵
for(int j=0;j<n;j++)
scanf("%d",&A.mat[i][j]);
for(int i=0;i<n;i++) //初始化B矩阵
for(int j=0;j<n;j++)
scanf("%d",&B.mat[i][j]);
C=mat_multiply (A,B,n);
for(int i=0;i<n;i++) //打印C矩阵
{
for(int j=0;j<n;j++)
printf("%3d",C.mat[i][j]);
printf("\n");
}
return 0;
}
第三部分:矩阵快速幂
神马是幂?【很多时候会被高大上的名字吓到。。。导致学习效率降低。。。其实没辣么可怕,很简单!!!】
幂又称乘方。表示一个数字乘若干次的形式,如n个a相乘的幂为a^n ,或称a^n为a的n次幂。a称为幂的底数,n称为幂的指数。——引自.度娘百科
这类题,指数都是很大很大很大很大很大很大很大的。。。霸王硬上弓的话,很容易超时的 T_T 。。。所以得快速幂→_→
学过之后发现,其实矩阵快速幂 的核心思想跟 以前学过的快速幂取模非常非常相似,只是矩阵乘法需要另外写个函数,就是上面那个代码。。。
【一会去写快速幂取模的专题,棒!】
快速幂的思路就是:
设A为矩阵,求A的N次方,N很大,1000000左右吧。。。
先看小一点的,A的9次方
A^9
= A*A*A*A*A*A*A*A*A 【一个一个乘,要乘9次】
= A*(A*A)*(A*A)*(A*A)*(A*A)【保持格式的上下统一,所以加上这句】
= A*(A^2)^4 【A平方后,再四次方,还要乘上剩下的一个A,要乘6次】
= A*((A^2)^2)^2【A平方后,再平方,再平方,还要乘上剩下的一个A,要乘4次】
也算是一种二分思想的应用吧,1000000次幂,暴力要乘1000000次,快速幂就只要(log2底1000000的对数) 次,大约20次。。。这。。。我没错吧。。。
但是因为是矩阵,矩阵乘法的复杂度是O(n^3)。。。所以快速幂的复杂度是O(n^3 * logn)
上代码!矩阵乘法的代码和上面一样,添加了mat_quick_index(MATRIX a,int N,int n)函数,主函数做了些许修改,以便检验。。。
//矩阵快速幂
#include <iostream>
#include <cstdio>
#include <cstring>
#include <cstdlib>
#include <cmath>
#include <algorithm>
using namespace std;
#define LL __int64
#define MOD 1000
typedef struct MATRIX
{
int mat[50][50];
}MATRIX;
MATRIX mat_multiply (MATRIX a,MATRIX b,int n)
{
MATRIX c; //c[i][j]= Σ a[i][k]*b[k][j]
memset(c.mat,0,sizeof(c.mat));
/*
for(int i=0;i<n;i++) //a矩阵一行一行往下
for(int j=0;j<n;j++) //b矩阵一列一列往右
for(int k=0;k<n;k++) //使a矩阵 第i行第k个元素 乘以 b矩阵 第j列第k个元素
if(a[i][k] && b[k][j]) //剪枝(添条件,设门槛),提高效率,有一个是0,相乘肯定是0
c.mat[i][j]+=a.mat[i][k]*b.mat[k][j];
*/
//上面也是可以的,但是下面的剪枝更好一些,效率更高一些,但是运算顺序有点难想通,,,
//上面就是C[i][j]一次就求出来,下面就是每次c[i][j]求出一项【就是上面红体字,每次各求一列】
for(int k=0;k<n;k++) //这个可以写到前面来,
for(int i=0;i<n;i++)
if(a.mat[i][k]) //剪枝:如果a.mat[i][k]是0,就不执行了
for(int j=0;j<n;j++)
if(b.mat[k][j]) //剪枝:如果b.mat[i][k]是0,就不执行了
{
c.mat[i][j]+=a.mat[i][k]*b.mat[k][j];
if(c.mat[i][j]>=MOD) //这个看实际需求,要不要取模
c.mat[i][j]%=MOD; //取模的复杂度比较高,所以尽量减少去模运算,添加条件,只有当大于等于MOD的时候才取余
}
return c;
}
MATRIX mat_quick_index(MATRIX a,int N,int n)
{
MATRIX E; //单位矩阵,就像数值快速幂里,把代表乘积的变量初始化为1
// memset(E.mat,0,sizeof(E.mat)); //置零,单位矩阵除了主对角线都是1,其他都是0
// for(int i=0;i<n;i++) //初始化单位矩阵【就是主对角线全是1】
// E.mat[i][i]=1;
for(int i=0;i<n;i++)
for(int j=0;j<n;j++)
E.mat[i][j]=(i==j); //酷炫*炸天的初始化!!!
while(N>0)
{
if(N & 1)
E=mat_multiply(E,a,n);
N>>=1;
a=mat_multiply(a,a,n);
}
return E;
}
int main()
{
int n,N; //n为矩阵(方阵)规模,几行,N为指数
MATRIX A,C;
memset(A.mat,0,sizeof(A.mat));
memset(C.mat,0,sizeof(C.mat));
scanf("%d",&n); //矩阵规模,这里是方阵,行数等于列数
for(int i=0;i<n;i++) //初始化A矩阵
for(int j=0;j<n;j++)
scanf("%d",&A.mat[i][j]);
scanf("%d",&N);
C=mat_quick_index(A,N,n);
for(int i=0;i<n;i++) //打印C矩阵
{
for(int j=0;j<n;j++)
printf("%3d",C.mat[i][j]);
printf("\n");
}
return 0;
}
第四部分:矩阵快速幂求快速求斐波那契数列第N项
对于矩阵乘法与递推式之间的关系:

如:在斐波那契数列之中
fi[i] = 1*fi[i-1]+1*fi[i-2] fi[i-1] = 1*f[i-1] + 0*f[i-2];
即
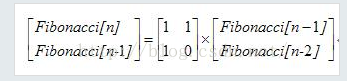
所以
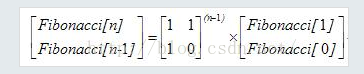
矩阵快速幂:
因为矩阵乘法满足结合律,原因如下
所以,我们可以用类似数字快速幂的算法来解决矩阵快速幂。(前提:矩阵为n*n的矩阵,原因见矩阵乘法定义)
代码
Matrix fast_pow(Matrix a, int x) {
Matrix ans;
ans.x = a.x;
for(int i = 0; i < ans.x; i++)
ans.a[i][i] = 1;
while(x) {
if(x&1)
ans = ans*a;
a = a*a;
x >>= 1;
}
return ans;
}用矩阵快速幂求斐波那契数列的第N项的代码:
#include<bits/stdc++.h>
using namespace std;
typedef long long ll;
const int MOD=10000;
struct mat
{
ll a[2][2];
};
mat mat_mul(mat x,mat y)
{
mat res;
memset(res.a,0,sizeof(res.a));
for(int i=0;i<2;i++)
for(int j=0;j<2;j++)
for(int k=0;k<2;k++)
res.a[i][j]=(res.a[i][j]+x.a[i][k]*y.a[k][j])%MOD;
return res;
}
void mat_pow(int n)
{
mat c,res;
c.a[0][0]=c.a[0][1]=c.a[1][0]=1;
c.a[1][1]=0;
memset(res.a,0,sizeof(res.a));
for(int i=0;i<2;i++) res.a[i][i]=1;
while(n)
{
if(n&1) res=mat_mul(res,c);
c=mat_mul(c,c);
n=n>>1;
}
printf("%I64d\n",res.a[0][1]);
}
int main()
{
int n;
while(~scanf("%d",&n)&&n!=-1)
{
mat_pow(n);
}
return 0;
}
参考博客:http://blog.csdn.net/u013795055/article/details/38599321
https://i-blog.csdnimg.cn/blog_migrate/ebecd66b374807896911807bad87573e.png















 1881
1881

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









