







文章目录
1 基本信息
| 项目 | 信息 |
|---|---|
| 名称 | Matrix factorization techniques for recommender systems |
| 作者 | Yehuda Koren, Robert Bell, Chris Volinsky |
| 期刊 | Computer |
| 年份 | 2009 |
| 卷 | 42 |
| 期 | 8 |
| 页码 | 30–37 |
| DOI | https://doi.org/10.1109/MC.2009.263 |
| 引用量 | 10063 |
2 引言
正如 Netflix 奖竞赛所证明的那样,矩阵分解模型在生成产品推荐方面优于经典的最近邻技术,允许结合其他信息,例如隐式反馈、时间效应和置信度。
推荐系统的目标是使得不同的用户都尽可能得到满足,也即是个性化推荐,使得服务提供者获取用户的满意度和忠诚度。
3 推荐系统策略
从广义上讲,推荐系统基于两种策略之一。
- 内容过滤(content filtering) 方法为每个用户或产品创建一个画像(配置文件)以表征其性质。
- 协同过滤(collaborative filtering) 方法分析用户之间的关系和产品之间的相互依赖关系,以识别新的用户-项目关联。
协同过滤相比内容过滤,有两点优势:
- 不需要刻画画像,应用更广泛。
- 通常更准确。
协同过滤相比内容过滤,有一点劣势:
- 遭遇冷启动问题。
协同过滤的两个主要领域是邻域方法(neighborhood methods) 和潜在因子模型(latent factor models)。
- 邻域方法的中心是计算项目之间或用户之间的关系。
- 潜在因素模型是一种替代方法,它试图通过对项目和用户进行表征,例如从评分模式推断出的 20 到 100 个因素来解释评分。
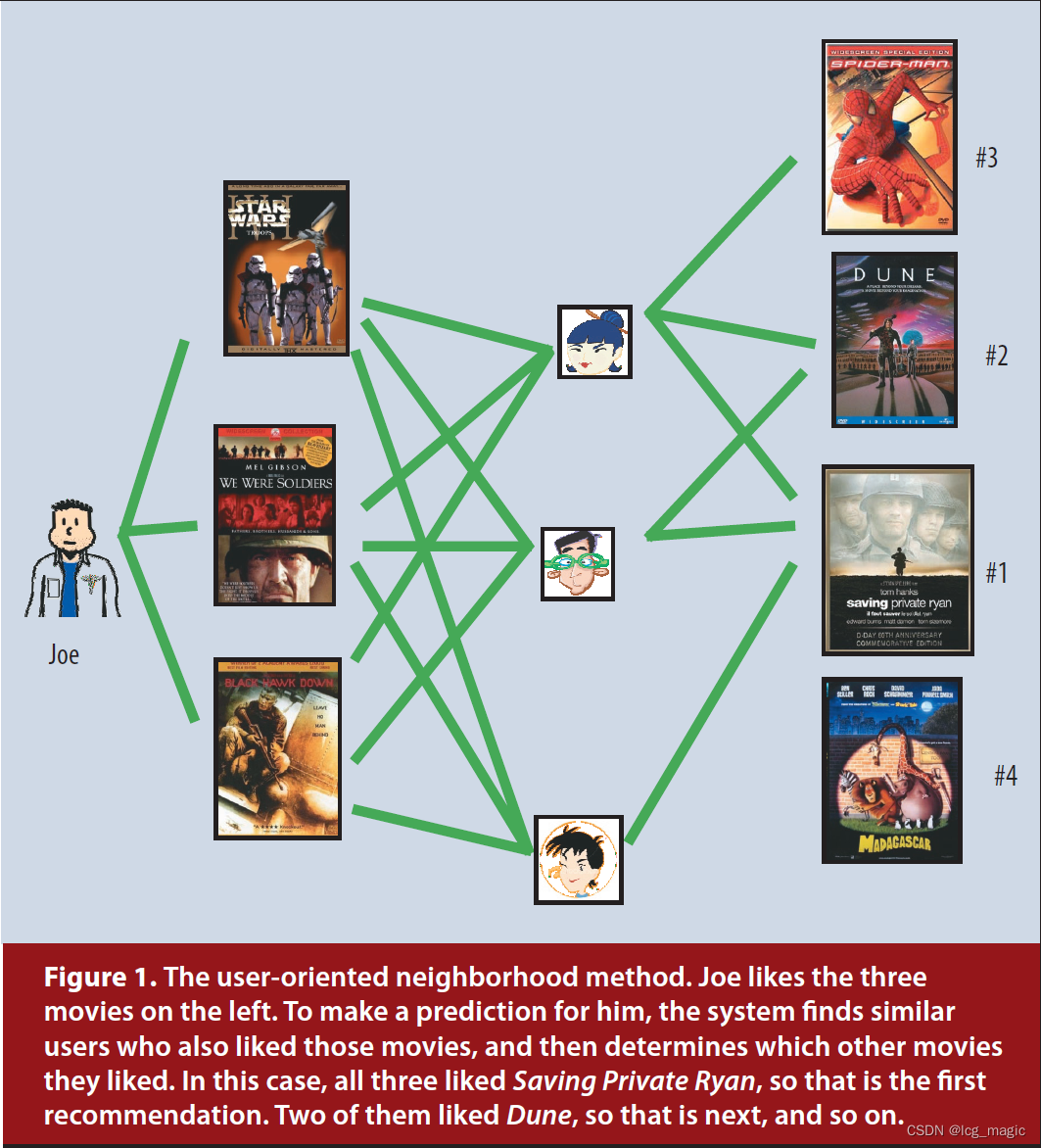
图 1 展示了面向用户的邻域方法。Joe 喜欢最左侧的 3 部电影。为了给 Joe 做预测,系统先找到同样喜欢这些电影的 3 个用户(中间)。那么如何向 Joe 推荐(预测)呢?这 3 个用户都喜欢 Saving Private Ryan 这部电影,那么最建议推荐就是它。其次,有两个用户喜欢 Dune,那么这个是第二推荐的。以此类推。
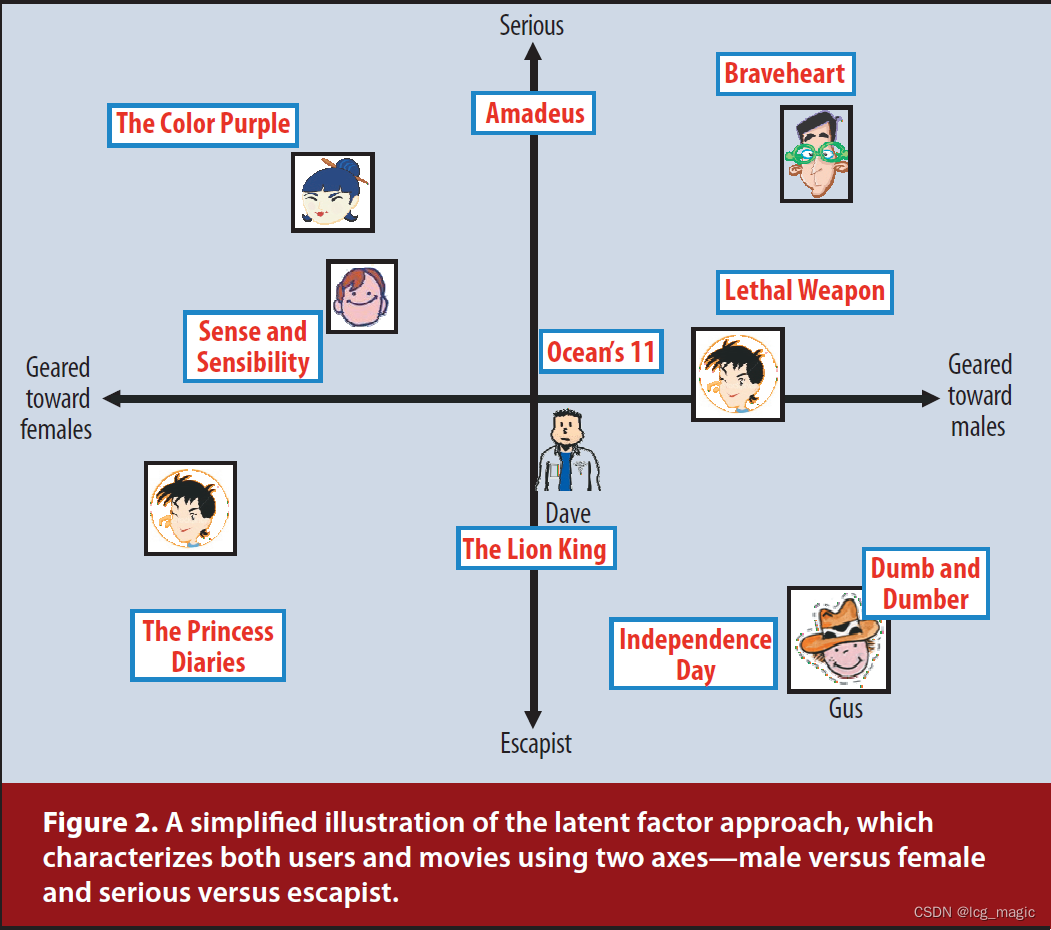
图 2 展示了潜在因子方法在 2 维下的一个简化例子。考虑两个假设维度,即女性(左)与男性(右)导向以及严肃(上)与逃避现实(下)。该图显示了几部知名电影和少数虚构用户可能落在这两个维度上的位置。对于这个模型,用户对电影的预测评分,相对于电影的平均评分,将等于电影和用户在图表上的位置的点积。例如,我们希望 Gus 喜欢 Dumb and Dumber,讨厌 The Color Purple,并对Braveheart 评分一般。
4 矩阵分解方法
潜在因子模型的一些最成功的实现是基于矩阵分解(Matrix Factorization)。在其基本形式中,矩阵分解通过从项目评分模式推断出的因子向量来表征项目和用户。项目和用户因子之间的高度对应导致推荐。
推荐系统依赖不同类型的输入数据,通常表示为一个矩阵,矩阵的一个维度表示用户,另外一个维度表示感兴趣的项目。最方便的数据是高质量的显式反馈,其中包括用户关于他们对产品的兴趣的明确输入。文中以评分(ratings) 作为显式用户反馈。通常,显式反馈包含一个稀疏矩阵,因为任意单一用户可能只对一小部分可能的项目进行了评分。
矩阵分解的一个优点是它允许合并额外的信息。当显式反馈不可用时,推荐系统可以使用隐式反馈推断用户偏好,隐式反馈通过观察用户行为间接反映意见,包括购买历史、浏览历史、搜索模式,甚至鼠标移动。 隐式反馈通常表示事件的存在或不存在,因此它通常由一个密集填充的矩阵表示。
5 基本矩阵分解模型
符号表如下所示
| 符号 | 含义 |
|---|---|
| f f f | 联合潜在因子空间维度 |
| i i i | 项目 |
| q i ∈ R f q_i \in \mathbb{R}^f qi∈Rf | 和 i i i 相关联的向量 |
| u u u | 用户 |
| p u ∈ R f p_u \in \mathbb{R}^f pu∈Rf | 和 u u u 相关联的变量 |
| r u i r_{ui} rui | 用户 u u u 对项目 i i i 的评分 |
对于给定的项目
i
i
i,
q
i
q_i
qi 的元素衡量该项目拥有这些因素的程度,无论是积极的还是消极的。
对于给定的用户
u
u
u,
p
u
p_u
pu 的元素衡量用户对相应因素高的项目的兴趣程度,同样,积极或消极。
结果的点积
q
i
T
p
u
q^{\rm{T}}_i p_u
qiTpu 捕获了用户
u
u
u 和项目
i
i
i 之间的交互——用户对项目特征的整体兴趣。
u
u
u 对
i
i
i 评分的一个估计:
r
^
u
i
=
q
i
T
p
u
.
(1)
\qquad \qquad \qquad \hat{r}_{ui}=q^{\rm{T}}_i p_u. \qquad \qquad \qquad \textbf{(1)}
r^ui=qiTpu.(1)
这种模型与奇异值分解 (SVD) 密切相关,奇异值分解是一种在信息检索中识别潜在语义因素的成熟技术。在协同过滤域中应用 SVD 需要考虑用户项目评分矩阵。由于用户项目评分矩阵中的稀疏性导致缺失值的比例很高,这通常会带来困难。
为了学习因子向量(
p
u
p_u
pu 和
q
i
q_i
qi),系统最小化一组已知评分的正则化平方误差:
min
q
∗
,
p
∗
∑
(
u
,
i
)
∈
κ
(
r
u
i
−
q
i
T
p
u
)
2
+
λ
(
∥
q
i
∥
2
+
∥
p
u
∥
2
)
,
(2)
\min_{q^{\ast}, p^{\ast}} \sum_{(u,i) \in \kappa} \left( r_{ui} - q^{\rm{T}}_i p_u \right)^2 + \lambda \left( \Vert q_i \Vert^2 + \Vert p_u \Vert^2 \right), \qquad \textbf{(2)}
q∗,p∗min(u,i)∈κ∑(rui−qiTpu)2+λ(∥qi∥2+∥pu∥2),(2)其中
κ
\kappa
κ 是已知
r
u
i
r_{ui}
rui 的(训练集)
(
u
,
i
)
(u,i)
(u,i) 对的集合。常数
λ
\lambda
λ 控制正则化的程度,通常由交叉验证确定。
个
人
理
解
:
{\color{Orange}个人理解:}
个人理解:
真实评分
r
u
i
r_{ui}
rui,预测评分
q
i
T
p
u
q^{\rm{T}}_i p_u
qiTpu,两者误差为
(
r
u
i
−
q
i
T
p
u
)
(r_{ui} - q^{\rm{T}}_i p_u)
(rui−qiTpu)。那么,为了模型预测更准确,肯定希望误差越小越好。误差有正有负,为了避免正负误差互相抵消,所以使用误差平方来衡量。对于已知
r
u
i
r_{ui}
rui 的
(
u
,
i
)
(u,i)
(u,i) 对来讲,有
min
(
r
u
i
−
q
i
T
p
u
)
2
\min (r_{ui} - q^{\rm{T}}_i p_u)^2
min(rui−qiTpu)2。对于所有的
(
u
,
i
)
∈
κ
(u,i) \in \kappa
(u,i)∈κ,有
∑
(
u
,
i
)
∈
κ
(
r
u
i
−
q
i
T
p
u
)
2
\sum\limits_{(u,i) \in \kappa} (r_{ui} - q^{\rm{T}}_i p_u)^2
(u,i)∈κ∑(rui−qiTpu)2。
(
∥
q
i
∥
2
+
∥
p
u
∥
2
)
(\Vert q_i \Vert^2 + \Vert p_u \Vert^2)
(∥qi∥2+∥pu∥2) 是机器学习中常使用的正则项,用于调整模型拟合,避免过拟合(overfitting)。常数
λ
\lambda
λ 控制正则化的程度。
6 学习算法
最小化方程 2 的两种方法是随机梯度下降(Stochastic Gradient Descent) 和交替最小二乘法(Alternating Least Squares,ALS)。
6.1 随机梯度下降
随机梯度下降算法循环遍历训练集中所有的评分。对于每一个给定的训练样例,系统预测
r
u
i
r_{ui}
rui 并计算相关的预测误差
e
u
i
=
d
e
f
r
u
i
−
q
i
T
p
u
.
e_{ui} \stackrel{def}{=} r_{ui}- q^{\rm{T}}_i p_u.
eui=defrui−qiTpu.
个
人
理
解
:
{\color{Orange}个人理解:}
个人理解:
将上式代入公式 (2) 中,记为
f
f
f:
{
f
=
e
u
i
2
+
λ
(
q
i
2
+
p
u
2
)
e
u
i
=
r
u
i
−
q
i
T
p
u
\left\{\begin{matrix} f = e^2_{ui} + \lambda \left( q_i^2 + p_u^2 \right) \\ e_{ui} = r_{ui} - q^{\rm{T}}_i p_u \end{matrix}\right.
{f=eui2+λ(qi2+pu2)eui=rui−qiTpu
对上式
f
f
f 求偏导,得到梯度:
{
∂
f
∂
q
i
=
2
e
u
i
(
−
p
u
)
+
2
λ
q
i
=
0
∂
f
∂
p
u
=
2
e
u
i
(
−
q
i
)
+
2
λ
p
u
=
0
⇒
{
∂
f
∂
q
i
=
−
e
u
i
p
u
+
λ
q
i
=
0
∂
f
∂
p
u
=
−
e
u
i
q
i
+
λ
p
u
=
0
.
\left\{\begin{matrix} \cfrac{\partial f}{\partial q_i} = 2e_{ui}(-p_u) + 2\lambda q_i = 0 \\ \cfrac{\partial f}{\partial p_u} = 2e_{ui}(-q_i) + 2\lambda p_u = 0 \\ \end{matrix}\right. \Rightarrow \left\{\begin{matrix} \cfrac{\partial f}{\partial q_i} = -e_{ui}p_u + \lambda q_i = 0 \\ \cfrac{\partial f}{\partial p_u} = -e_{ui} q_i + \lambda p_u = 0 \\ \end{matrix}\right..
⎩⎪⎪⎨⎪⎪⎧∂qi∂f=2eui(−pu)+2λqi=0∂pu∂f=2eui(−qi)+2λpu=0⇒⎩⎪⎪⎨⎪⎪⎧∂qi∂f=−euipu+λqi=0∂pu∂f=−euiqi+λpu=0.
它在梯度的相反方向将参数修改为与
γ
\gamma
γ 成比例的幅度,产生:
- q i ← q i + γ ⋅ ( e u i ⋅ p u − λ ⋅ q i ) q_i \leftarrow q_i + \gamma \cdot (e_{ui} \cdot p_u - \lambda \cdot q_i) qi←qi+γ⋅(eui⋅pu−λ⋅qi)
- p u ← p u + γ ⋅ ( e u i ⋅ q i − λ ⋅ p u ) p_u \leftarrow p_u + \gamma \cdot (e_{ui} \cdot q_i - \lambda \cdot p_u) pu←pu+γ⋅(eui⋅qi−λ⋅pu)
这种流行的方法结合了易于实施和相对较快的运行时间。然而,在某些情况下,使用 ALS 优化是有益的。
6.2 交替最小二乘
因为 q i q_i qi 和 p u p_u pu 都未知,公式 (2) 不是凸的。但是,如果我们固定其中一个未知数,优化问题就会变成二次问题并且可以得到最优解。因此, ALS 在固定 q i q_i qi 和 p u p_u pu 之间轮转。当所有的 p u p_u pu 固定时,系统通过解决最小二乘问题重新计算 q i q_i qi,反义亦然。
一般来讲,随机梯度下降比交替最小二乘简单且运行更快。但交替最小二乘在两种情况下更好:
- 并行化。
- 针对隐式数据为中心的系统。
7 增加偏差
式子 (1) 试图捕捉产生不同评分值的用户和项目之间的交互。然而,观察到的评分值的大部分变化是由于与用户或项目相关的影响,称为偏差(biases) 或截距(intercepts),与任何交互无关。例如,典型的协同过滤数据表现出很大的系统倾向,即某些用户给出的评分高于其他用户,而某些项目的评分高于其他项目。毕竟,一些产品被广泛认为比其他产品更好(或更差)。
因此,通过
q
i
T
p
u
q^{\rm{T}}_i p_u
qiTpu 形式的交互来解释完整的评分值是不明智的。相反,系统会尝试识别这些值中单个用户或项目偏差可以解释的部分,只对数据的真实交互部分进行因子建模。
评分
r
u
i
r_{ui}
rui 所涉及的偏差的一阶近似如下:
b
u
i
=
μ
+
b
i
+
b
u
.
(3)
\qquad \qquad \qquad b_{ui} = \mu + b_i + b_u. \qquad \qquad \qquad \textbf{(3)}
bui=μ+bi+bu.(3)
评分
r
u
i
r_{ui}
rui 中包含的偏差用
b
u
i
b_{ui}
bui 表示,并计算用户和项目的效应。总体平均评分用
μ
\mu
μ 表示,参数
b
u
b_u
bu 和
b
i
b_i
bi 分别表示观察到的用户
u
u
u 和项目
i
i
i 的与平均值的偏差。
举个例子:
Joe 对电影 Titanic 评分的一阶估计。现在,假设所有电影的平均评分
μ
\mu
μ 为 3.7 颗星。此外,泰坦尼克号比一般电影要好,因此它的评分往往比平均水平高 0.5 星。另一方面,Joe 是一个挑剔的用户,他的评分往往比平均水平低 0.3 星。因此,Joe 对 Titanic 评分的估计可能是 3.9(3.7 + 0.5 - 0.3)。
偏差将式 (1) 扩展如下:
r
^
u
i
=
μ
+
b
i
+
b
u
+
q
i
T
p
u
.
(4)
\qquad \qquad \qquad \hat{r}_{ui} = \mu + b_i + b_u + q^{\rm{T}}_i p_u. \qquad \qquad \qquad \textbf{(4)}
r^ui=μ+bi+bu+qiTpu.(4)
观察评分被分解为四个成分:全局平均值、项目偏差、用户偏差和用户项目交互。这允许每个组件仅解释与其相关的信号部分。
在式 (4) 的基础上,系统通过最小化平方误差函数来学习:
min
p
∗
,
q
∗
,
b
∗
∑
(
u
,
i
)
∈
κ
(
r
u
i
−
μ
−
b
i
−
b
u
−
q
i
T
p
u
)
+
λ
(
∥
p
u
∥
2
+
∥
q
i
∥
2
+
b
u
2
+
b
i
2
)
.
(5)
\min_{p^{\ast}, q^{\ast}, b^{\ast}} \sum_{(u,i) \in \kappa} (r_{ui} - \mu - b_i - b_u - q^{\rm{T}}_i p_u) + \lambda (\Vert p_u \Vert^2 + \Vert q_i \Vert^2 + b^2_u + b^2_i). \qquad \textbf{(5)}
p∗,q∗,b∗min(u,i)∈κ∑(rui−μ−bi−bu−qiTpu)+λ(∥pu∥2+∥qi∥2+bu2+bi2).(5)
8 额外的输入源
系统通常必须处理冷启动问题,其中许多用户提供的评级很少,因此很难就他们的品味得出一般性结论。缓解此问题的一种方法是合并有关用户的其他信息源。推荐系统可以使用隐式反馈来深入了解用户偏好。事实上,无论用户是否愿意提供明确的评级,他们都可以收集行为信息。除了客户可能提供的评级外,零售商还可以使用客户的购买或浏览历史来了解他们的倾向。
为了简介,考虑一个带有布尔隐式反馈的情况。
N
(
u
)
N(u)
N(u) 表示用户
u
u
u 表达隐含偏好的项目集。这样,系统通过他们隐式偏好的项目来描述用户。在这里,需要一组新的项目因素,其中项目
i
i
i 与
x
i
∈
R
f
x_i \in \mathbb{R}^f
xi∈Rf 相关联。因此,对 $N(u)$0 中的项目表现出偏好的用户的特征是向量
∑
i
∈
N
(
u
)
x
i
.
\sum_{i \in N(u)} x_i.
i∈N(u)∑xi.
归一化总和通常是有益的,例如,使用
∣
N
(
u
)
∣
−
0.5
∑
i
∈
N
(
u
)
x
i
.
\lvert N(u) \rvert^{-0.5} \sum_{i \in N(u)} x_i.
∣N(u)∣−0.5i∈N(u)∑xi.
另一个信息源是已知的用户属性,例如人口统计。同样,为简单起见,考虑布尔属性,其中用户
u
u
u 对应于属性集
A
(
u
)
A(u)
A(u),可以描述性别、年龄组、邮政编码、收入水平等。
一个不同的因子向量
y
a
∈
R
f
y_a \in \mathbb{R}^f
ya∈Rf 对应于每个属性,通过用户相关属性的集合来描述一个用户:
∑
a
∈
A
(
u
)
y
a
.
\sum_{a \in A(u)} y_a.
a∈A(u)∑ya.
矩阵分解模型应集成所有信号源,并增强用户表示:
r
^
u
i
=
μ
+
b
i
+
b
u
+
q
i
T
[
p
u
+
∣
N
(
u
)
∣
−
0.5
∑
i
∈
N
(
u
)
x
i
+
∑
a
∈
A
(
u
)
y
a
]
.
(6)
\hat{r}_{ui} = \mu + b_i + b_u + q^{\rm{T}}_i \left[ p_u + \lvert N(u) \rvert^{-0.5} \sum_{i \in N(u)} x_i + \sum_{a \in A(u)} y_a \right]. \qquad \textbf{(6)}
r^ui=μ+bi+bu+qiT⎣⎡pu+∣N(u)∣−0.5i∈N(u)∑xi+a∈A(u)∑ya⎦⎤.(6)
9 时间动态
目前为止,提出的模型都是静态的。实际上,随着新选择的出现,产品的认知度和受欢迎程度会不断变化。同样,顾客的喜好也在演变,导致他们重新定义自己的品味。因此,系统应该考虑反映用户项目交互的动态、时间漂移性质的时间效应。
随时间变化的项:项目偏差
b
i
(
t
)
b_i(t)
bi(t)、用户偏差
b
u
(
t
)
b_u(t)
bu(t) 和用户偏好
p
u
(
t
)
p_u(t)
pu(t)。
b
i
(
t
)
b_i(t)
bi(t) 解决了项目受欢迎程度可能随时间变化的事实。
b
u
(
t
)
b_u(t)
bu(t) 允许用户随时间改变他们的基线评分。
p
u
(
t
)
p_u(t)
pu(t) 可能反映了几个因素,包括用户评分量表的自然漂移、用户分配评分相对于其他最近评分的事实,以及评分者在家庭中的身份可能随时间变化的事实。不同于人类,项目本质上是静态的。
时变参数的参数的精确参数化导致将公式 (4) 替换为时间
t
t
t 评分的动态预测规则:
r
^
u
i
(
t
)
=
μ
+
b
i
(
t
)
+
b
u
(
t
)
+
q
i
T
p
u
(
t
)
.
(7)
\hat{r}_{ui}(t) = \mu + b_i(t) + b_u(t) + q^{\rm{T}}_i p_u(t). \qquad \qquad \qquad \textbf{(7)}
r^ui(t)=μ+bi(t)+bu(t)+qiTpu(t).(7)
10 具有不同置信水平的输入
在几种设置中,并非所有观察到的评级都应具有相同的权重或置信度。例如,大量广告可能会影响对某些项目的投票,这不能恰当地反映长期特征。同样,系统可能会面对试图倾斜某些项目评级的敌对用户。
矩阵分解模型可以很容易地接受不同的置信水平,这使得它对不太有意义的观察给予较少的权重。
如果观察
r
u
i
r_{ui}
rui 的置信度表示为
c
u
i
c_{ui}
cui,然后模型增强成本函数(等式 (5))以说明置信度,如下所示:
min
p
∗
,
q
∗
,
b
∗
∑
(
u
,
i
)
∈
κ
c
u
i
(
r
u
i
−
μ
−
b
u
−
b
i
−
p
u
T
q
i
)
2
+
λ
(
∥
p
u
∥
2
+
∥
q
i
∥
2
+
b
u
2
+
b
i
2
)
.
(8)
\min_{p^{\ast},q^{\ast},b^{\ast}} \sum_{(u,i) \in \kappa} c_{ui} \left(r_{ui} - \mu - b_u - b_i - p^{\rm{T}}_u q_i \right)^2 + \lambda \left(\Vert p_u \Vert^2 + \Vert q_i \Vert^2 + b^2_u + b^2_i \right). \qquad \qquad \textbf{(8)}
p∗,q∗,b∗min(u,i)∈κ∑cui(rui−μ−bu−bi−puTqi)2+λ(∥pu∥2+∥qi∥2+bu2+bi2).(8)
有关涉及此类方案的实际应用程序的信息,请参阅 “隐式反馈数据集的协作过滤”。
11 Netflix 大奖赛
略……
参考
- Y. Koren, R. Bell, C. Volinsky, Matrix factorization techniques for recommender systems. Computer 42, 30–37 (2009).
- Latex 颜色设置…














 250
250











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









