






基于puppeteer自动化启动项目
背景
由于公司前端项目中采用sso单点登录,需要在统一的sso平台上登录拿到 ticket 后通过后端进行颁发token,后续就携带token进行请求。
而每次前端本地开发时就需要把对应环境(开发&测试)上的token以及其他的本地存储信息复制到我们本地(localhost:8080)的localStorage中。然鹅,不可能每次都手动复制粘贴吧? 😅,所以我们通过chrome浏览器插件解决了这个问题。
but, 由于本地项目启动时并没有任何存储信息,所以如果在页面加载完成前没有token的话,就会自动跳转到开发(dev-***.com)或者测试环境(test-****.com)的登录页面,所以这个时候每次就得先打开开发者模式并设置slow3g,让请求暂时不那么快响应。
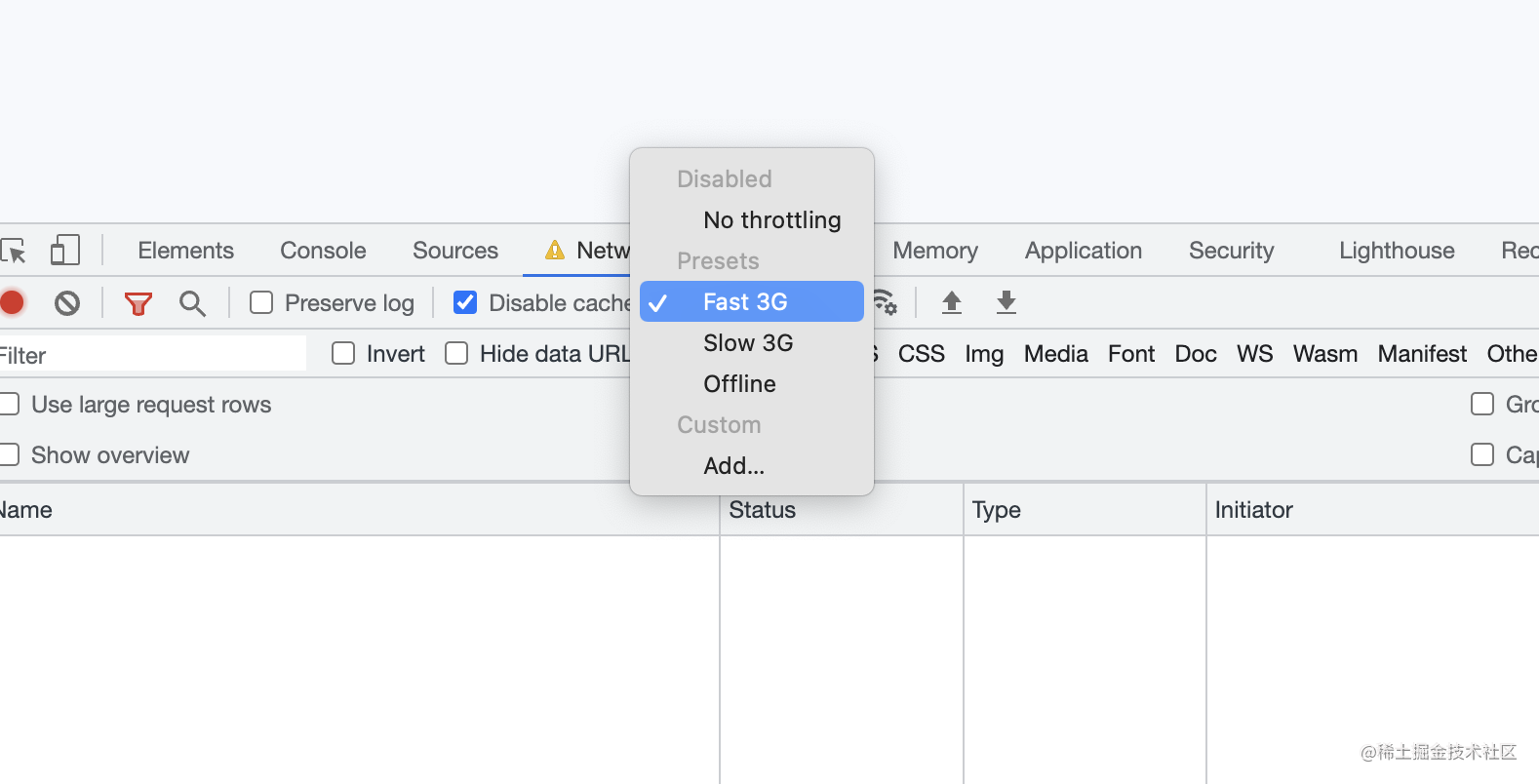
然后在通过插件进行复制粘贴到本地localStorage中。这一系列操作,让刚熟悉项目的我犹如受到了打击~,这他喵也太麻烦了吧…
需要解决的问题
解放双手, automation is good for me~ 😆 。程序员最擅长的就是摸鱼,哦,不是… 用程序代替双手解决问题。
所以我们需要解决的问题就是,如何能让我在启动项目的时候或者说token过期后更快的能够进行本地开发而不浪费时间?
puppeteer很好的帮助了我解决这个问题 👍
puppeter自动化获取数据
每当token过期时,系统都会跳转到sso平台去通过验证码登录,那么我们如果在项目启动时就能自动登录并拿到token,就能不用每次手动操作存储信息
首先 puppeteer 能够打开一个无头浏览器进行模拟人工操作,我们只需要利用控制台输入手机号以及验证码,然后再模拟鼠标点击登录即可。
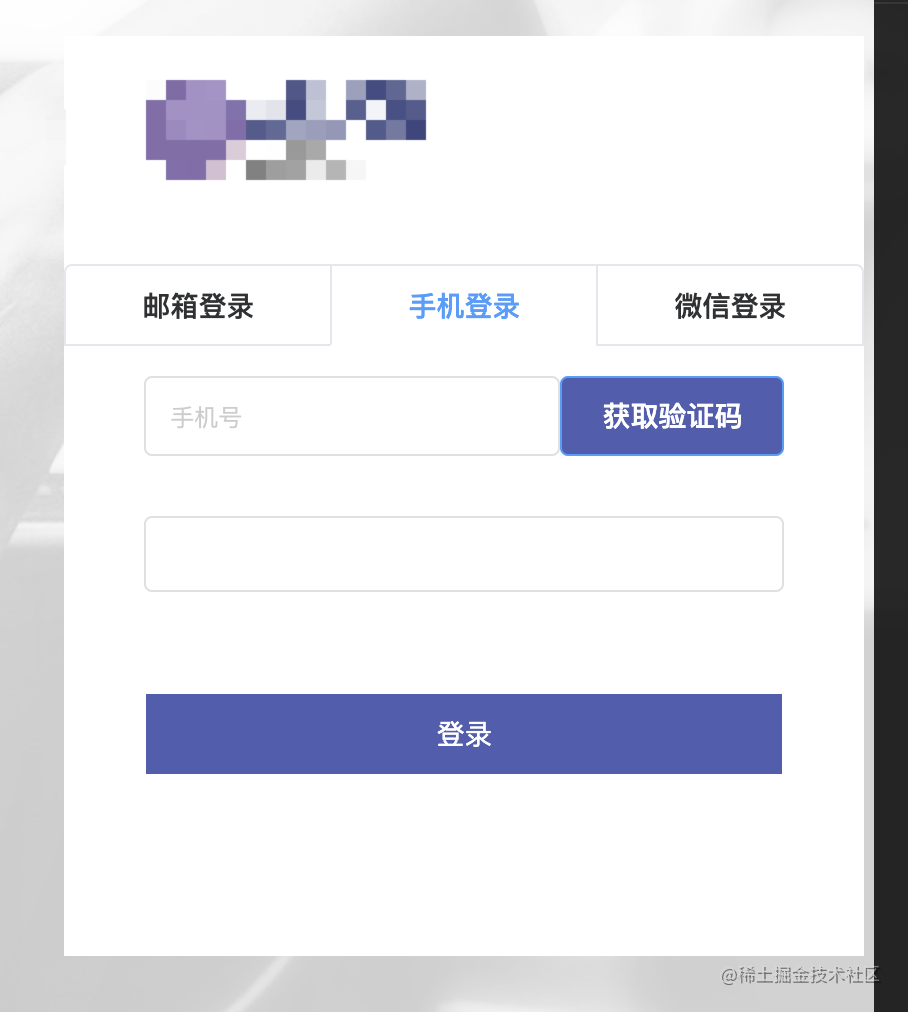
那么我们首先来看如何输入手机号并点击获取验证码呢?
await puppeteer.page.setJavaScriptEnabled(true);
await puppeteer.page.setViewport({
width: 1440,
height: 780,
});
await puppeteer.page.goto(SSO_LOGIN); // 打开sso地址
await puppeteer.page.click('#djHideToolBarButton'); // 切换到通过手机登录
await puppeteer.page.click('div[aria-controls="pane-second"]'); // 焦点放到手机输入框输入框上
await delay(1000);
const phone = await promiseReadLine('请输入手机号: '); // 这里通过readline封装读取终端的输入
console.log('您的手机号为: ', phone);
await puppeteer.page.type('input[placeholder=手机号]', phone);
await delay(1000);
await puppeteer.page.click('#TencentCaptcha'); // 点击获取验证码
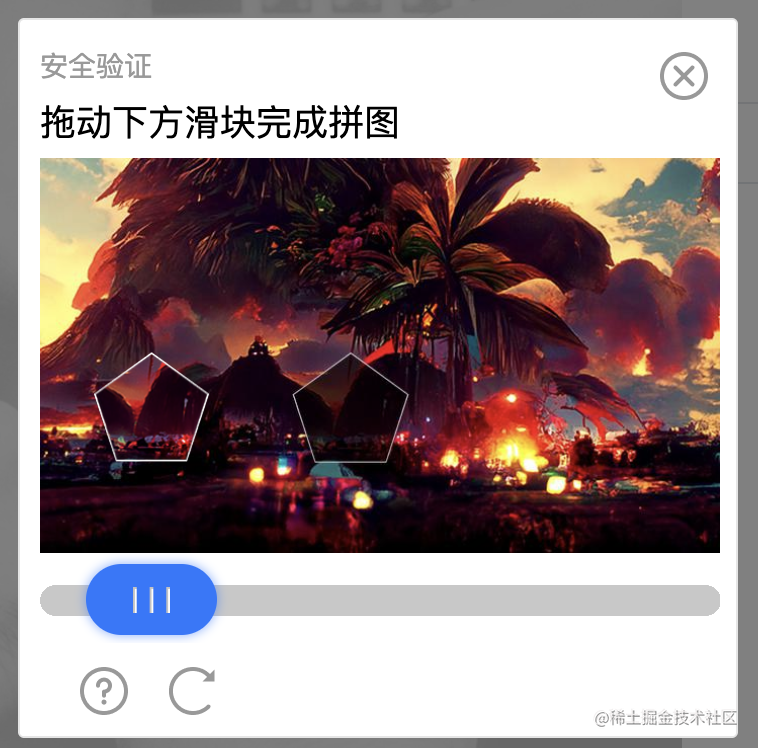
这时就会去请求验证码,那么我们只需要将验证图片拖动到缺口位置就能收到验证码并填入。(我们如何自动拖拽,后面会展开描述,感兴趣可以直接跳转到验证码拖拽)
通过 puppeteer 的on方法监听response事件
puppeteer.page.on('response', async function Request(res) {
if (new URL(res.url()).pathname === '/sms/login_code/' && res.ok()) {
rl.question('请输入手机验证码: ', async (phone_code) => {
console.log(phone_code);
await puppeteer.page.type('input[name="phone_code"]', phone_code);
await delay(1000);
console.log('点击登录');
await puppeteer.page.click('button[type="submit"]');
rl.close();
});
}
if (new URL(res.url()).pathname === '获取权限接口' && res.ok()) {
console.log('权限接口获取完毕, 开始获取本地数据');
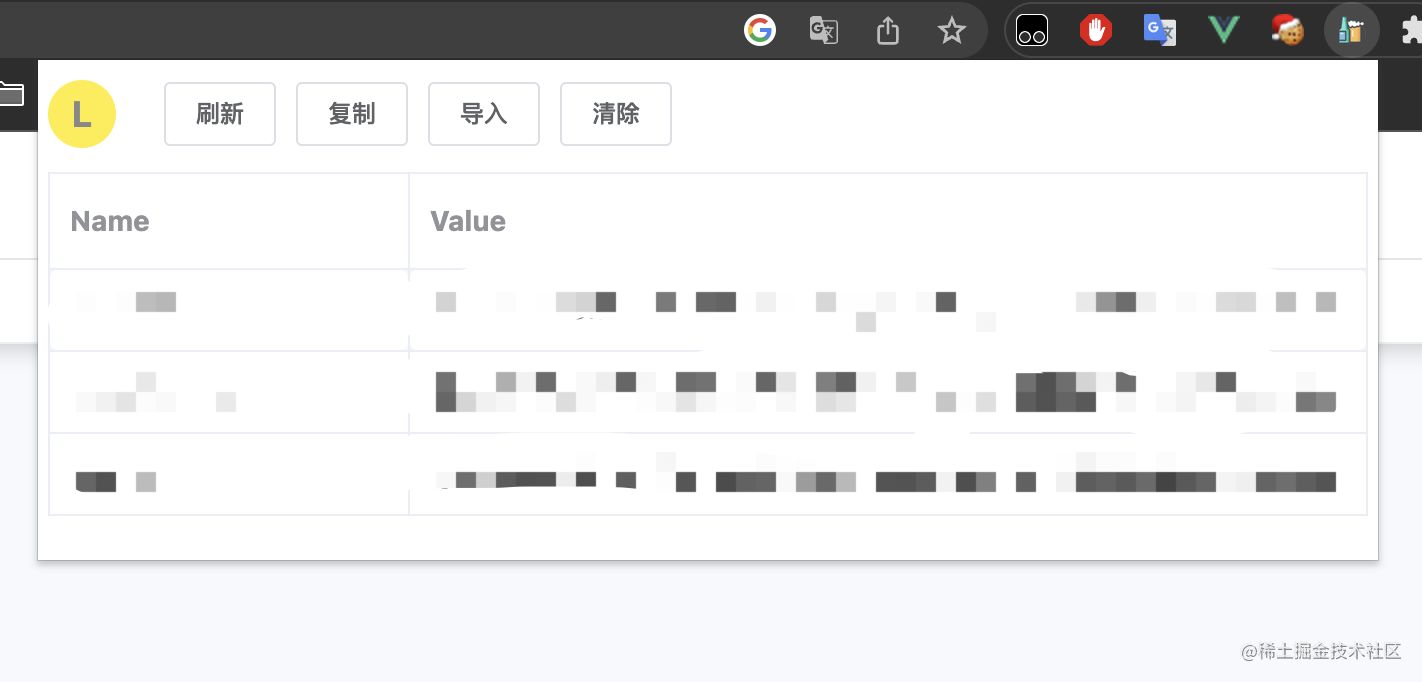
const localStorage = await puppeteer.page.evaluate(() => {
let store = window.localStorage; // 获取浏览器localStorage数据
let obj = {};
for (let key in store) {
if (store.hasOwnProperty(key)) {
obj[key] = store[key];
}
}
return obj;
});
console.log('返回的数据为: ', localStorage);
fs.writeFileSync('localStore.json', JSON.stringify(localStorage, null, 4)); // 存入项目目录中
puppeteer.page.removeListener('response', Request);
await puppeteer.page.close();
console.log('存储完毕....自动化脚本正在退出...');
process.exit(0);
}
});
上述代码中,通过有两个判断语句。
- 第一个通过监听验证码的url请求,当手机收到验证码后填入并登录此时进入到项目中
- 第二个通过监听用户权限接口,获取到用户权限以及token并存入目录文件中
这个时候 puppeteer 的工作就算结束了。
读取数据并启动项目
经过上面👆的操作,我们就能看到一个localStore.json这个文件,那么我们运行项目时就只需要先读取这个文件的json数据并存入到本地浏览器中,即可进行欢乐的开发~
// initStore.js
(async () => {
try {
if (process.env.NODE_ENV === 'localhost') {
// 读取puppeeter目录下的localStore.json文件并进行存储
const context = require.context('./puppeteer', false, /localStore.json/);
// 判断文件存在且当前浏览器没有localStorage时才进行覆写
if (context.keys().length) {
const jsonName = context.keys()[0];
const json = context(jsonName);
for (let key in json) {
if (json.hasOwnProperty(key)) {
window.localStorage.setItem(key, json[key]);
}
}
}
}
} catch (e) {
console.log(e);
}
})();
当token过期后,只需要通过替换localStore.json里的数据。那么有了这个操作,我们提供了本地连接测试&开发&生产环境的方式,能够使得我们在fix bug阶段能够拿到线上环境数据,本地修复后并得到反馈。
那么有同学会问?怎么通过配置和一条命令就能启动的呢?
npm run puppeteer development --prefix puppeteer && npm run local
最关键命令的就是 --prefix 能在 puppeteer 目录下运行npm run puppeteer development 传入命令,而puppeteer项目通过环境变量去匹配不同线上环境的sso平台。 npm run local 也是同理: 通过 vue.config.js配置proxy匹配不同环境的target进行代理转发
此时,我们就可以进行愉快的开发了~
验证码拖拽
上面主要描述了整个自动化脚本的流程,而最重要(难点,也是困扰了好久)的点是如果进行验证码拖拽到指定位置,而每次验证码缺口的位置也是不确定的。
最初看到时,参考了一些网上的验证码滑块校验案例,大致思路是:拿到完整背景图和含缺口的背景图通过三方库(例如 resemble.js)进行像素比较,得到像素差异点距离即是需要滑块滑动的位置,然后模拟滑动即可
但对比dom后发现公司sso平台所用的腾讯验证码平台并不存在上述两张图片,而是
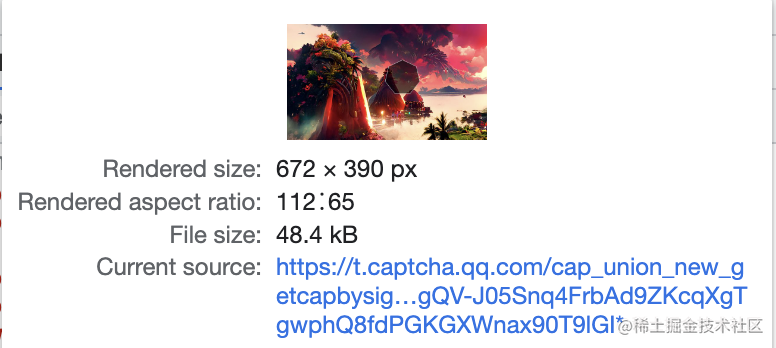

通过css background-position进行裁剪并通过js进行动态匹配,所以如果用三方库的对比算法的话是拿不到差异点的位置的。(eg: 腾讯验证码的iframe的dom层级会随机改变,导致我在获取dom的时候费了大力气~
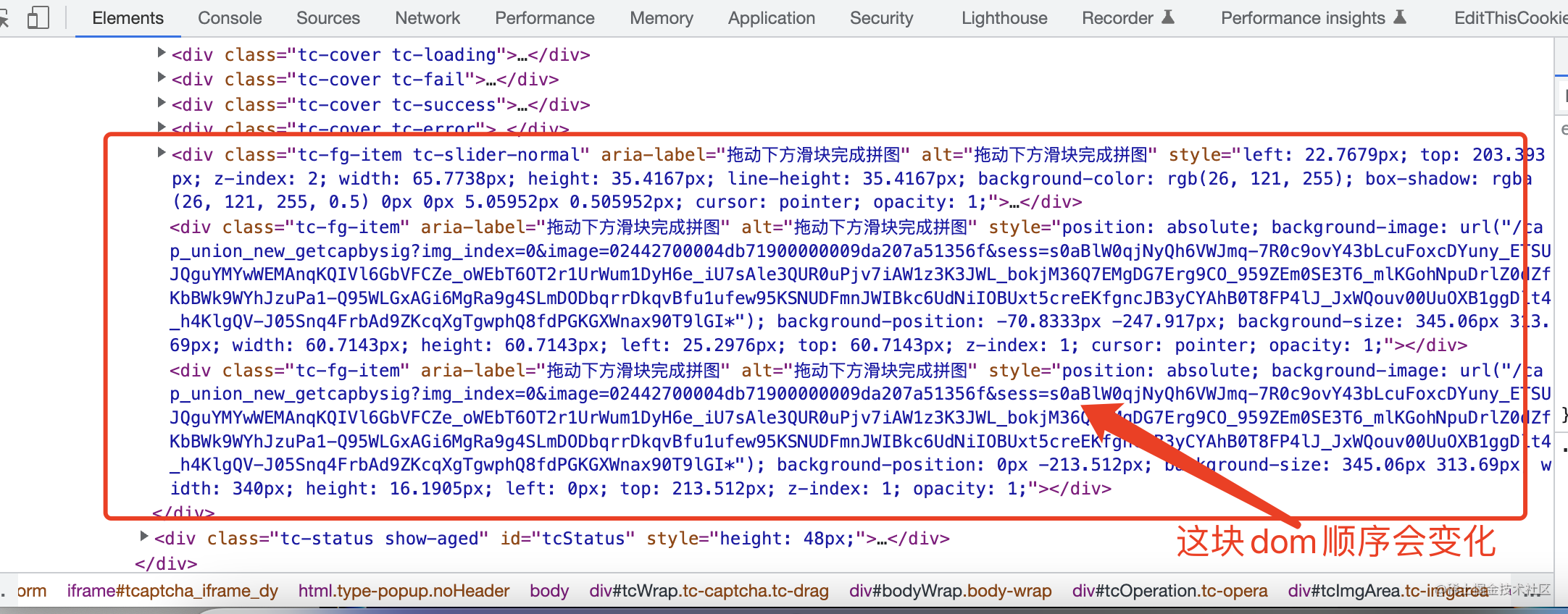
所以后面就考虑使用openCV进行识别,在node中可以使用opencv官方提供的opencv.js方案,详情可参考hi-upchen.medium.com/如何在-nodejs-…
但尝试后随之而来的问题就是opencv.js编译后的包比较大加载会慢(有些功能冗余),而且opencv.js提供的场景需要以浏览器dom为基础(cv.imread load the image from [外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-8WKI3d7k-1672317730289)(null)],不支持传入image,且 cv.Mat() 返回的数据类型也不是简单的ImageData导致转换会出现问题。一系列的问题,让我思考🤔: 为什么我要使用阉割版的opencv,直接使用python版的不就好了?那么就有了下面的测试代码:
'''
Author: tzyito
Date: 2022-10-24
LastEditTime: 2022-10-26
LastEditors: tzyito
Description:
'''
import cv2
def show(name):
'''展示圈出来的位置'''
cv2.imshow('Show', name)
cv2.waitKey(0)
cv2.destroyAllWindows()
def _tran_canny(image):
"""消除噪声"""
image = cv2.GaussianBlur(image, (3, 3), 0)
return cv2.Canny(image, 50, 150)
def detect_displacement(img_slider_path, image_background_path):
"""detect displacement"""
# # 参数0是灰度模式
image = cv2.imread(img_slider_path, 0)
template = cv2.imread(image_background_path, 0)
# 寻找最佳匹配
res = cv2.matchTemplate(_tran_canny(image), _tran_canny(template), cv2.TM_CCOEFF_NORMED)
# 最小值,最大值,并得到最小值, 最大值的索引
min_val, max_val, min_loc, max_loc = cv2.minMaxLoc(res)
top_left = max_loc[0] # 横坐标
# 展示圈出来的区域
x, y = max_loc # 获取x,y位置坐标
w, h = image.shape[::-1] # 宽高
cv2.rectangle(template, (x, y), (x + w, y + h), (7, 249, 151), 2)
show(template)
return top_left
if __name__ == '__main__':
top_left = detect_displacement("img2.png", "img.png")
print(top_left)
然后不出意外就出意外了 😵💫,单纯且简单的算法并没有经过调参就出现了某些时候的图像识别不准的情况,这导致我十分的焦灼(本垃圾佬真的太菜了)…. 经过一天的调试,随后求助了一下算法组大佬 🙇⇒ 直接调他的算法服务了~ 大佬一顿调参并部署成了api调用的形式, 丝滑地帮我解决了这个问题~
调用api后拿到移动位置后续就比较简单了,就是模拟鼠标进行移动。这里需要注意的是,在截取图片的时候由于iframe处于沙盒中,直接通过 eval 方法可能获取不到dom。可通过 Page.frames() 获取iframeList并通过iframe url进行匹配,拿到iframe的page后再获取内部的dom
整理难点:
- iframe隔离且dom层级动态,需要的dom获取困难,且拿到dom后需要截图,所以需要去除干扰元素后在截取
- 验证码缺口块的位置识别,方法踩坑以及协调解决
- 滑块验证通过后,需要监听浏览器请求并特定的请求后输入验证码
- iframe沙盒隔离,puppeteer不能监听到内部的request,导致滑块如果失败后会无响应需要做兜底或重试
- 登录后需要获取localStorage json数据并存在本地,启动项目前加入到浏览器中
总结过程:
-
在启动项目前先使用puppeteer抓取对应环境的登录token
- 其中环境通过配置文件以及运行命令抓取对应的网站
- 其中在通过puppeteer获取dom时也遇到了困难,腾讯验证码的dom层级是动态的,所以导致不能很好的匹配上,而且验证码通过iframe沙盒隔离,所以处理位置时需要多次调参。
- 火星系统中使用腾讯验证码验证,需要识别出缺口位置并模拟滑动,相比于其他验证码缺少通用爬虫需要的完整背景图片。所以考虑采用识别算法opencv进行识别,这里前期考虑使用opencv.js但是由于js版被功能被阉割过,最后还是协调算法组同事提供识别服务并返回中心位置。
- 拿到位置后,发起请求并在终端输入验证码,随后登录系统拿到token。最后存到本地,等启动项目的时候把数据存到浏览器中。
解决了什么问题?不足是什么?
- 由于前端需要真实环境的token才能在本地开发,虽然有chrome插件可以复制粘贴localStorage的数据,但是由于每次需要手动复制并调试浏览器网络才能够复制成功,有时候还会复制错环境的数据(比如开发复制了测试环境的数据)。而且项目上手成本也比较高
- 所以提供了自动化的脚本,在启动的时候就已经拿到对应环境的数据,并且配合自定义配置文件,能在本地随时连接后端服务,在遇到问题时能够快速定位以及解决后验证。
- 其中有不足是,由于puppeteer采用的是无痕浏览器启动,所以每次都需要先执行爬虫脚本才能启动项目,可能第一次启动项目时间比之前比较会长一些,后期可以做一些缓存优化,达到不用每次获取爬虫,加快打开项目的速度
这里给大家分享一份Python全套学习资料,包括学习路线、软件、源码、视频、面试题等等,都是我自己学习时整理的,希望可以对正在学习或者想要学习Python的朋友有帮助!
CSDN大礼包:全网最全《全套Python学习资料》免费分享🎁
😝有需要的小伙伴,可以点击下方链接免费领取或者V扫描下方二维码免费领取🆓

1️⃣零基础入门
① 学习路线
对于从来没有接触过Python的同学,我们帮你准备了详细的学习成长路线图。可以说是最科学最系统的学习路线,你可以按照上面的知识点去找对应的学习资源,保证自己学得较为全面。

② 路线对应学习视频
还有很多适合0基础入门的学习视频,有了这些视频,轻轻松松上手Python~
③练习题
每节视频课后,都有对应的练习题哦,可以检验学习成果哈哈!

因篇幅有限,仅展示部分资料
2️⃣国内外Python书籍、文档
① 文档和书籍资料

3️⃣Python工具包+项目源码合集
①Python工具包
学习Python常用的开发软件都在这里了!每个都有详细的安装教程,保证你可以安装成功哦!
②Python实战案例
光学理论是没用的,要学会跟着一起敲代码,动手实操,才能将自己的所学运用到实际当中去,这时候可以搞点实战案例来学习。100+实战案例源码等你来拿!
③Python小游戏源码
如果觉得上面的实战案例有点枯燥,可以试试自己用Python编写小游戏,让你的学习过程中增添一点趣味!
4️⃣Python面试题
我们学会了Python之后,有了技能就可以出去找工作啦!下面这些面试题是都来自阿里、腾讯、字节等一线互联网大厂,并且有阿里大佬给出了权威的解答,刷完这一套面试资料相信大家都能找到满意的工作。


5️⃣Python兼职渠道
而且学会Python以后,还可以在各大兼职平台接单赚钱,各种兼职渠道+兼职注意事项+如何和客户沟通,我都整理成文档了。


上述所有资料 ⚡️ ,朋友们如果有需要 📦《全套Python学习资料》的,可以扫描下方二维码免费领取 🆓
😝有需要的小伙伴,可以点击下方链接免费领取或者V扫描下方二维码免费领取🆓














 1224
1224











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









