









记录一次cephfs内核客户端死锁问题定位过程
原文地址:https://zhuanlan.zhihu.com/p/375464867
一、 问题背景
Ceph是一款开源分布式存储系统,其具有丰富的功能和高可靠、高扩展性,并且提供统一存储服务,可以同时提供文件、对象、块服务。随着集群规模和业务量的增大,在使用文件的过程中遇到文件系统内核客户端死锁的问题,本文将详细介绍问题的定位过程和解决方案。
二、架构介绍
为了更好的阐述问题,先简单的介绍一下文件系统的整体架构,架构如下
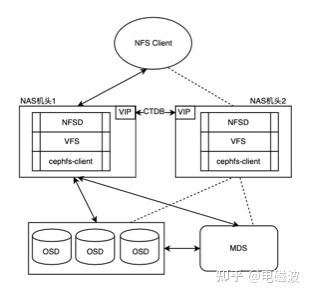
图1 系统架构图
从图中可以看出,我们向外提供了NFS服务,用户可以通过NFS 客户端挂载的方式来访问文件服务,以写操作为例,IO数据流首先是由用户的NFS客户端通过网络发送到机头所在节点的内核态的NFSD服务,NFSD服务调用VFS接口,然后到cephfs内核态的客户端,最终cephfs内核态客户端把数据存储到OSD,元数据存储到MDS。其中为了高可用,我们引入了CTDB组件,由CTDB管理和分配VIP,每个机头配置一个VIP,机头通过VIP向外提供服务,当一个机头出现异常时,该机头所在的VIP会漂移到正常的机头上,同时业务也会漂移到正常的机头上,从而保证了业务的高可用,不会因为单个节点故障,导致业务中断。
三、问题现象
在某天的早晨突然收到告警,NAS机头1上面的VIP切换到了NAS机头2上面,初步判断可能是NAS机头1所在的节点硬件发生了异常,使用堡垒机登陆该节点,发现该节点可以正常登陆,硬件异常可以排除掉了,是什么原因导致的呢?
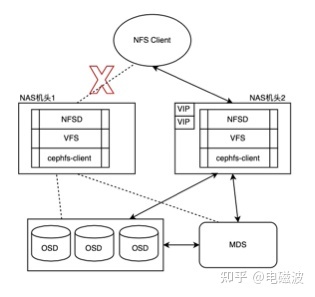
图2 NAS机头1异常,VIP切换
既然硬件无异常,那最大的可能是NFS服务端的export目录发生了异常,使用ls命令查看导出目录是否可以正常访问,果然出现了卡死无法返回现象。CTDB会监测NFS的导出目录,当导出目录发生异常时,为了不影响正常业务,CTDB会把该节点的VIP漂移到另外的节点,业务也会迁移到新的节点,不会因为单节点异常导致业务中断。
思路整理:
VIP切换的原因找到了,是因为NFS的export目录无法访问导致,但是NFS的导出目录为什么会访问不了呢?需要进一步进行分析。
四、问题定位
从系统架构图中可以看出,服务端的NFS导出目录,底层使用的是ceph的文件系统,即通过内核态的cephfs-client挂载的,后面全部简称客户端,大概率可能是客户端发生了异常,顺着这个思路我们继续往下排查,查看MDS的日志,发现有下面的打印:
log_channel(cluster) log [WRN] : evicting unresponsive client YZ-25 (10137), after 300.2789 seconds
正常情况下,MDS和客户端之间有心跳进行保活,客户端会定期发送renewcaps保活消息给MDS,MDS收到renewcaps消息后会更新时间戳,当超过session_autoclose时间内未收到客户端的心跳,MDS会认为客户端出现异常,进而把它evict掉,流程如图3所示,

图 3 客户端超时被evict流程图
联想到最近有几个新业务迁移到该集群,难道是因为客户端压力太大,无法及时发送心跳导致客户端被踢掉,默认情况下客户端被踢掉之后不会进行主动重连,最终导致客户端无法正常处理IO?
如果是这个原因,调整session_autoclose和mds_session_blacklist_on_time配置之后,应该可以解决该问题,第一个参数增加超时时间,第二个参数是客户端被evict掉之后,客户端不会被加入黑名单,有新的请求到来时,可以进行自动重连。光明似乎就在眼前,经过内部评估后,在线上进行了配置更改,希望该问题可以得到解决。
不幸的事情发生了,三天之后问题再次出现,心里顿时哇凉哇凉。超时时间已经由300s改为了600s,并且evict掉之后客户端还会重连,为什么目录还会卡死,是多大的压力才能导致600s内客户端都不发心跳给MDS?
思路整理:
问题定位方向是不是出问题了,会不会是由于客户端的进程出现了死锁,导致发送心跳的函数,根本就没有被执行?如果是这样的话,客户端所在节点应该有线程处于D状态。
线程D状态做存储的应该都不陌生,D (TASK_UNINTERRUPTIBLE)是不可中断的睡眠状态,一个IO请求被发送后,在等待回复的时候,为了防止被异常中断,该线程会被置为D状态,一直等待回复到来重新被唤醒。使用ps -aux | grep D查看系统所有线程状态,发现系统有213个线程处于D状态,问题正在朝着我们的猜想发展。
思路整理:
系统有大量的线程处于D状态,D状态原因的大部分情况是在等待IO请求的回复,下一步要确认的是否有IO请求,OSD或者MDS没有回复?
在客户端的/sys/kernel/debug/ceph/xxx/目录下保存了客户端的一些调试信息,其中osdc文件中保存了已经发送给osd,osd还有回复的消息,同理mdsc中保存了已经发送给mds,mds还没有回复的消息,查看osdc和mdsc文件,发现两个文件中都有消息未收到回复,难道是由于osd和mds有消息没有回给客户端?如果是这样的话,mds或者osd进程应该有slow request打印,slow request是当请求在30s未被及时处理时,mds或者osd会进行打印并上报给monitor,但是查看相关打印,并未发现有slow request打印,难道是由于网络不稳定有丢包,导致请求被丢掉?局域网内用的是tcp协议,请求被丢掉的可能性几乎没有。
再次梳理思路:
客户端记录有请求没有收到回复,但是osd和mds没有slow request请求,网络也不大可能出现问题,那现在的问题只能是客户端本身自己的问题了。
问题定位到现在,已经没有捷径可以走了,只能收集线程堆栈对着代码,一步步梳理了。收集所有处于D状态的线程堆栈,即/proc/pid/stack中的堆栈信息,经过分析,213个D状态的堆栈,可以分为三类,分别以A、B、C代替:
A:
[<0>] io_schedule+0x12/0x40
[<0>] __lock_page+0x105/0x150
[<0>] truncate_inode_pages_range+0x4ac/0x860
[<0>] evict+0x183/0x1a0
[<0>] __dentry_kill+0xd7/0x180
[<0>] dentry_kill+0x4d/0x110
[<0>] dput+0xb5/0xd0
[<0>] __fput+0x12b/0x210
[<0>] delayed_fput+0x21/0x30
[<0>] process_one_work+0x171/0x370
[<0>] worker_thread+0x49/0x3f0
[<0>] kthread+0xf8/0x130
[<0>] ret_from_fork+0x35/0x40
[<0>] 0xffffffffffffffff
B:
[<0>] __wait_on_freeing_inode+0xaa/0xe0
[<0>] find_inode+0x7a/0xb0
[<0>] ilookup5_nowait+0x6c/0xa0
[<0>] ilookup5+0x2a/0x90
[<0>] iget5_locked+0x26/0x80
[<0>] ceph_get_inode+0x2d/0xc0 [ceph]
[<0>] ceph_fill_trace+0x28a/0x950 [ceph]
[<0>] handle_reply+0x4c6/0xc90 [ceph]
[<0>] dispatch+0x134/0xab0 [ceph]
[<0>] try_read+0x801/0x11f0 [libceph]
[<0>] ceph_con_workfn+0xa8/0x5c0 [libceph]
[<0>] process_one_work+0x171/0x370
[<0>] worker_thread+0x49/0x3f0
[<0>] kthread+0xf8/0x130
[<0>] ret_from_fork+0x35/0x40
[<0>] 0xffffffffffffffff
C:
[<0>] ceph_check_caps+0x4d8/0xb50 [ceph] m
[<0>] ceph_put_wrbuffer_cap_refs+0x1da/0x2d0 [ceph]
[<0>] writepages_finish+0x292/0x430 [ceph]
[<0>] __complete_request+0x26/0x80 [libceph]
[<0>] dispatch+0x354/0xbc0 [libceph]
[<0>] try_read+0x801/0x11f0 [libceph]
[<0>] ceph_con_workfn+0xa8/0x5c0 [libceph]
[<0>] process_one_work+0x171/0x370
[<0>] worker_thread+0x49/0x3f0
[<0>] kthread+0xf8/0x130
[<0>] ret_from_fork+0x35/0x40
[<0>] 0xffffffffffffffff
\1. 首先看A线程的堆栈,inode正在被销毁,inode的状态被置为freeing状态,但是该inode对应的page并不是干净的,被置为了locked状态,导致该操作被阻塞,等待被唤醒。正常情况下,文件在读写请求时,会把对应的page置为locked状态,当请求被处理完成后,locked状态被清理。
\2. 从B线程的堆栈堆栈可以看出,客户端收到mds的回复后,从hashtable里面获取inode,发现该inode的状态为freeing状态,操作被阻塞,等待inode的freeing状态被清理后唤醒,但是在调用ceph_fill_trace前,该线程会持有session->s_mutex锁和mdsc->snap_rwsem信号量。
\3. 从C线程的堆栈可以看出,在处理回复消息时卡在了ceph_check_caps函数中,ceph_check_caps函数代码有200多行,直接看代码,分析起来比较慢,可以使用gdb工具,根据堆栈中的偏移值找到线程阻塞的具体的代码行号。
具体步骤如下:
l 使用gdb ceph.ko命令加载ceph.ko模块
l 使用disassemble ceph_check_caps命令对ceph_check_caps进行反汇编
从上文的堆栈中可以看出,ceph_check_caps函数阻塞的相对偏移地址是0x4d8,换算成十进制是1240,查看反汇编,确定在ko内的绝对偏移地址
0x0000000000018fa3 <+1235>: callq 0x18fa8 <ceph_check_caps+1240>
l 知道绝对偏移地址后使用info line *0x0000000000018fa3命令查看具体代码行号
(gdb) info line *0x0000000000018fa3
Line 2013 of “fs/ceph/caps.c” starts at address 0x18fa0 <ceph_check_caps+1232> and ends at 0x18fa8 <ceph_check_caps+1240>.
l 查看fs/ceph/caps.c代码第2013行
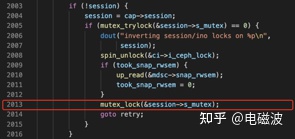
从中可以看出,在获取session->s_mutex时,操作被阻塞。看到这里,是否已经发现问题了,线程之间,互相死锁了。
思路总结:
死锁的原因:C线程等待B线程中的session->s_mutex锁,B线程由于inode处于freeing状态被阻塞,等待A线程修改inode状态后被唤醒,A线程等待C线程处理完OSD回复后把page的locked状态清理掉。

图4 线程死锁
其中有几点需要特殊说明下:
l 系统中的inode在没有使用的情况下,操作系统会定期进行回收
l 客户端在发送写请求的时候,会使用ihold对inode进行引用,在收到写请求回复的时候,会调用iput进行引用计数释放。
l 但是在文件发送预读请求时,并未对inode进行引用,所以会出现inode被销毁的同时,page有可能处于locked的情况。
l 当可用的线程全部被阻塞,读请求回复无法被处理,page的locked状态将会无法被清理。
五、问题修改
知道原因后,问题修改就比较容易了。具体的修改思路是,在B线程获取inode的时候,在持有session->s_mutex锁和mdsc->snap_rwsem信号量的情况下可能会被阻塞,应该在持锁之前,提前获取到inode,inode是从hashtable中获取的,并不需要上面的两个锁,避免在锁里面进入阻塞状态,代码详见:
https://tracker.ceph.com/issues/47998?next_issue_id=47991&prev_issue_id=48009
六、总结
定位偶现问题,犹如破案,特别是没有直接的错误日志情况下,在定位的过程中,不能放过任何蛛丝马迹,在“大胆假设,小心求证”的思路下,不断的通过证据验证自己的想法,问题总是会得到解决。
tracker.ceph.com/issues/47998%3Fnext_issue_id%3D47991%26prev_issue_id%3D48009)
六、总结
定位偶现问题,犹如破案,特别是没有直接的错误日志情况下,在定位的过程中,不能放过任何蛛丝马迹,在“大胆假设,小心求证”的思路下,不断的通过证据验证自己的想法,问题总是会得到解决。
编辑于 2021-05-26 16:47















 587
587











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









