






最近一直在写微信小程序,没时间看nodejs,今天就把之前写的图片爬虫拉出来晒一晒,免得彻底忘记~写的还不完善,还没时间继续,请开始嘲笑我的烂代码~
首页展示
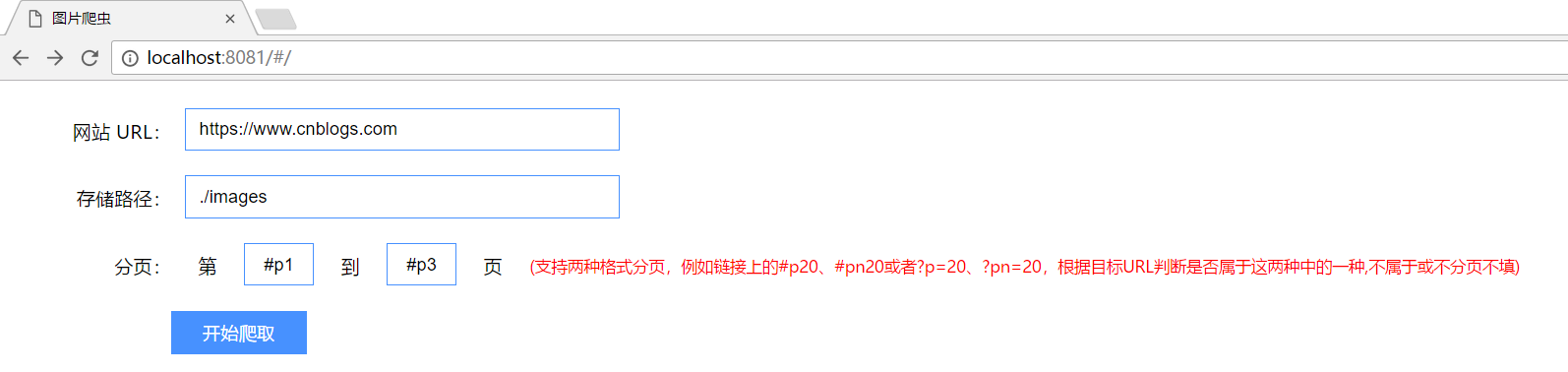
开始爬取图片
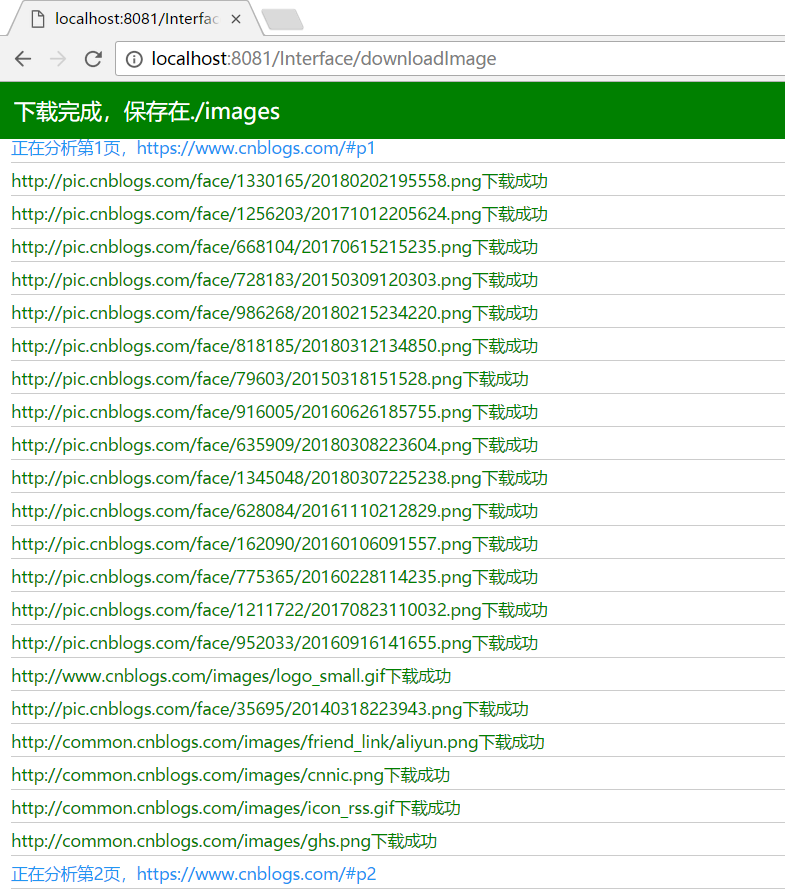
下载图片
前端界面 index.html
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8">
<title>图片爬虫</title>
<style>
</style>
</head>
<body>
<form method="post" autocomplete="off" action="/Interface/downloadImage">
<div><span class="title">网站 URL:</span><input name="url" type="text" value="https://www.cnblogs.com">
</div>
<div><span class="title">存储路径:</span><input type="text" name="savePath" value="./images" /></div>
<div>
<span class="title">分 页:</span>
<span>第</span>
<input name="beginPage" placeholder="#p1" class="page" value="#p1" />
<span>到</span>
<input placeholder="#p3" name="endPage" class="page"value="#p3" />
<span>页</span>
<span style="color: red;font-size: 12px;">(支持两种格式分页,例如链接上的#p20、#pn20或者?p=20、?pn=20,根据目标URL判断是否属于这两种中的一种,不属于或不分页不填)</span>
</div>
<div><input type="submit" class="submit" value="开始爬取"></div>
</form>
</body>
</html>
index.js(启动 node index.js)
var http = require('http');
var fs = require('fs');
var url = require('url');
var path = require("path");
var querystring = require('querystring');
var downloadImg = require('./downloadimg');
// 创建服务器
http.createServer(function(request, response) {
var body = "";
request.on('data', function(chunk) {
body += chunk;
});
request.on('end', function() {
// 解析参数
body = querystring.parse(body);
if(body.url) { // 输出提交的数据
POST(body, response)
} else {
// 解析请求,包括文件名
var pathname = url.parse(request.url).pathname.substr(1);
if(pathname == "") {
pathname = "index.html"
}
// 从文件系统中读取请求的文件内容
fs.readFile(pathname, function(err, data) {
if(err) {
console.log(err);
response.writeHead(404, {
'Content-Type': 'text/html'
});
} else {
// HTTP 状态码: 200 : OK
// Content Type: text/plain
switch(path.extname(pathname)) {
case ".html":
response.writeHead(200, {
'Content-Type': 'text/html'
});
break;
case ".js":
response.writeHead(200, {
'Content-Type': 'text/javascript'
});
break;
}
// 响应文件内容
response.write(data.toString());
}
// 发送响应数据
response.end();
});
}
});
}).listen(8081);
//处理post请求
function POST(body, response) {
if(body.url) {
// 设置响应头部信息及编码
response.writeHead(200, {
'Content-Type': 'text/html; charset=utf8'
});
response.write("<p style='margin:2px 0;padding:3px 0;'>正在准备下载..</p>")
setTimeout(function() {
downloadImg.downloadimg(
body,
function(msg, err) {
if(err) {
response.write("<p style='color:#2196f3;margin:2px 0;border-bottom:1px solid #CCC;padding:3px 0;font-size:12px;'>" + err + '</p>')
} else {
response.write("<p style='color:green;margin:2px 0;border-bottom:1px solid #CCC;padding:3px 0;font-size:12px;'>" + msg + '</p>')
}
},
function(successMsg, errMsg) {
if(successMsg) response.end("<p style='background:green;color:#FFF;position:fixed;top:0;left:0;width:100%;padding:10px;margin:0'>" + successMsg + "</p>")
if(errMsg) response.end("<p style='background:red;color:#FFF;position:fixed;top:0;left:0;width:100%;padding:10px;margin:0'>" + errMsg + "</p>")
}
)
}, 2000)
}
}
downloadimg.js
//依赖模块
var fs = require('fs');
var request = require("request");
var cheerio = require("cheerio");
var mkdirp = require('mkdirp');
var http = require('http');
var urlm = require('url');
var querystring = require("querystring");
//创建目标网址http请求模块
var downloadimg = function(body, imgcallback, endcallback) {
//解析post参数
var url = body.url;
var dir = body.savePath || './images'; //获取保存目录
var page = {
begin: body.beginPage,
end: body.endPage
};
//创建目录
mkdirp(dir, function(err) {
if(err) {
console.log(err);
}
});
//第一次发送请求
getRequest(url, dir, imgcallback, endcallback, page);
}
//请求目标地址
var getRequest = function(url, dir, imgcallback, endcallback, page) {
//获取地址真实
var pageUrl = getPageUrl(page, url)
//打印当前请求地址
if(page.currentIndex) {
imgcallback(0, "正在分析第" + page.currentIndex + "页," + pageUrl)
} else {
imgcallback(0,"正在分析" + pageUrl)
}
//开始请求
request(url, function(error, response, body) {
if(!error && response.statusCode == 200) {
images = imageArrangement(body, url,
function(errmsg) {
//网站分析失败回调,传回错误信息
endcallback(0, errmsg)
},
function(imageSrcArr) {
console.log(imageSrcArr)
//网站body分析成功,返回图片完整地址数组:imageSrcArr
//初始化完成数量
var complateImageLength = 0;
for(var i = 0; i < imageSrcArr.length; i++) {
var item = imageSrcArr[i];
//获取图片名
var fileName = item.split('/').pop();
//创建下载
download(item, dir, fileName, function(imagsrc, err) {
complateImageLength++;
//一张下载完成
imgcallback(imagsrc + "下载成功", err)
//全部下载完成
if(complateImageLength == imageSrcArr.length) {
//分页
if(page.currentIndex < page.EndIndex) {
page.currentIndex++;
//获取分页地址
//var pageUrl = getPageUrl(page,urldata)
getRequest(url, dir, imgcallback, endcallback, page);
} else {
endcallback('下载完成,保存在' + dir)
}
}
});
}
})
}
});
}
//网站body分析,图片整理,返回图片地址数组
var imageArrangement = function(body, url, errorcallback, successcallback) {
//errorcallback:网站爬取失败回调
var $ = cheerio.load(body);
//找到img所在标签目录
var images = $('img');
//排除非正常图片
images.each(function(index, item) {
var img = $(this)
var src = img.attr('src') + "";
//base64暂时不下载
if(src == 'undefined' || src.length == 0 || src.indexOf('base64') > -1) {
images.splice(index, 1)
return;
}
});
var imageSrcArr = [];
images.each(function(index, item) {
var img = $(this)
var src = item.attribs.src.split('?')[0]; //下载文件路径含有search时会造成下载失败
//获取文件根路径
var rootPathname = urlm.parse(src).pathname.substr(0, 1) == '/' ? urlm.parse(src).pathname : '/' + urlm.parse(src).pathname;
//防止图片地址不完整从新拼接
if(!/(http|https)/.test(src)) {
src = src.substr(0, 2) == '//' ? 'http:' + src : 'http://' + urlm.parse(url).host + rootPathname;
} else if(!/\.(gif|jpg|jpeg|png|bmp|GIF|JPG|PNG)$/.test(src)) {
//排除非图片后缀
return;
}
imageSrcArr.push(src)
})
//图片数目为0,返回错误结束响应
if(!imageSrcArr.length) {
//网站不包含图片标签,结束下载
errorcallback('下载失败:该网站不包含图片或者网站禁止爬虫')
return;
}
successcallback(imageSrcArr)
}
//图片下载方法,保存到dir
var download = function(url, dir, filename, callback) {
request.head(url, function(err, res, body) {
if(err) console.log(err)
//callback下载完成回调
//传入流:fsa.pipe(fsb),fsa必须是存在的流,但fsb不存在会创建;pipe方法是可读流导入可写流
request(url).pipe(fs.createWriteStream(dir + "/" + filename)).on('close', function() {
//下载完成传回地址,错误信息
callback(url, err)
})
});
};
//获取分页真实地址
function getPageUrl(page, url) {
var urldata = urlm.parse(url);
if(!urldata.protocol && !urldata.host) {
//请求出地址不完整,结束
//return;
}
if( page.begin && page.end ) {
page.BeginIndex = page.begin.replace(/[^0-9]/ig, "");
page.EndIndex = page.end.replace(/[^0-9]/ig, "");
var pageIag = page.begin.replace(/\d+/g, '');
page.currentIndex = page.currentIndex || page.BeginIndex;
if(page.BeginIndex && page.EndIndex) {
//hash分页
if(/#/.test(page.begin) && /#/.test(page.end)) {
url = urldata.protocol + '//' + urldata.host + urldata.path + pageIag + page.currentIndex
//querystring分页
} else if(/=/.test(page.begin) && /=/.test(page.end)) {
var querystringData = querystring.parse(url);
}
}
}
return url;
}
//导出下载模块
exports.downloadimg = downloadimg;















 189
189











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









