






萧箫 发自 凹非寺
量子位 | 公众号 QbitAI
多模态大模型,终于迎来“大一统”时刻!
从声音、文字、图像到视频,所有模态被彻底打通,如同人脑一般,实现了真正意义上的任意输入,任意输出。
要知道,多模态一直是学术界公认要达到更强智能的必经之路,连GPT-4都在往这个方向发展。

也正是因此,这项来自微软、北卡罗来纳大学教堂山分校的新研究一经po出,立即在社交媒体上爆火,有网友惊叹:
这是我最近见过最不可思议的一篇论文!
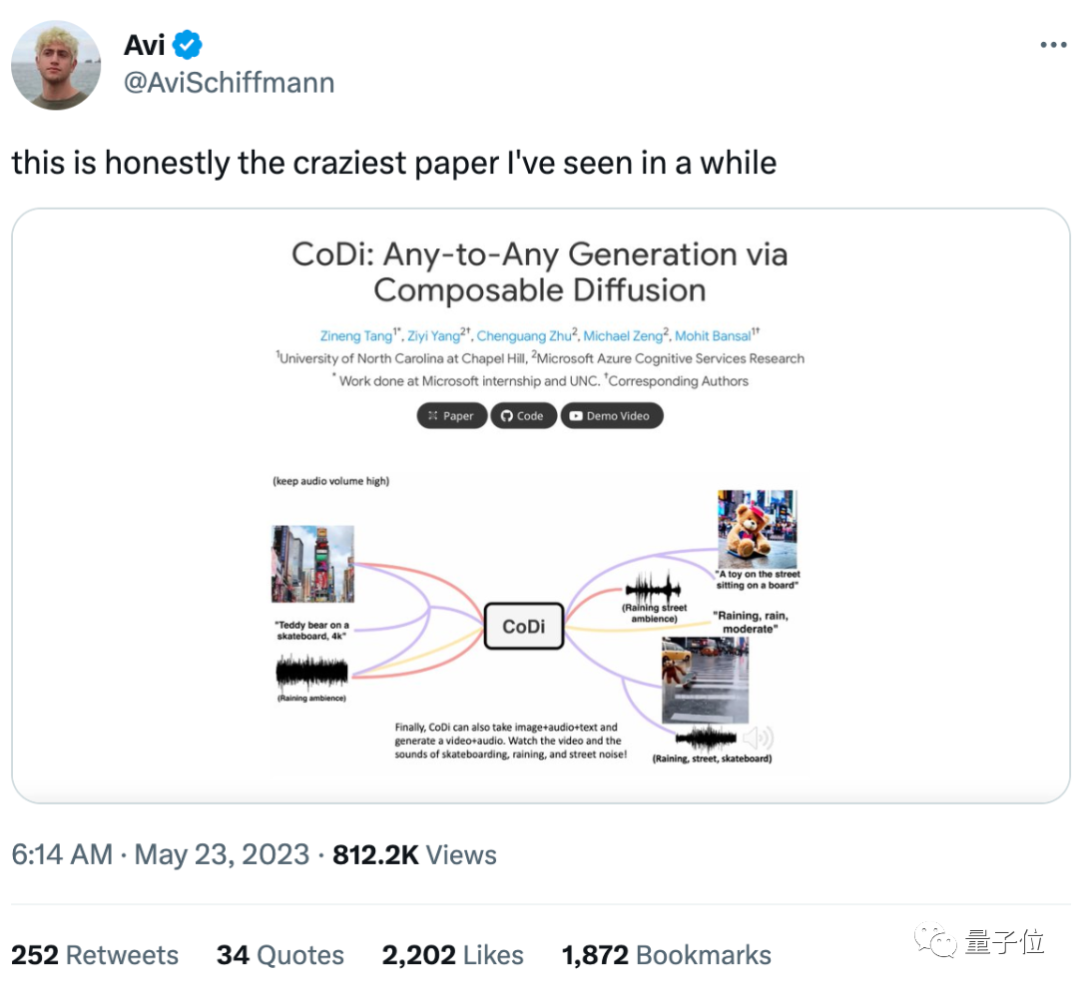
究竟有多不可思议?
只需告诉大模型,想要“一只玩滑板的泰迪熊”,并输入一张照片+一段声音:

它立刻就能精准get要点,生成一段在下雨天在城市里玩滑板的心碎小熊录像,仔细听还会发现配上了新的雨声:
效果太过于鹅妹子嘤,以至于不少网友表示“有被吓到”:


还有网友感叹“新时代的到来”:
等不及看到创作者们用这些AI工具制作各种沉浸式故事体验了。这简直给RPG角色扮演游戏赋予了全新的意义。

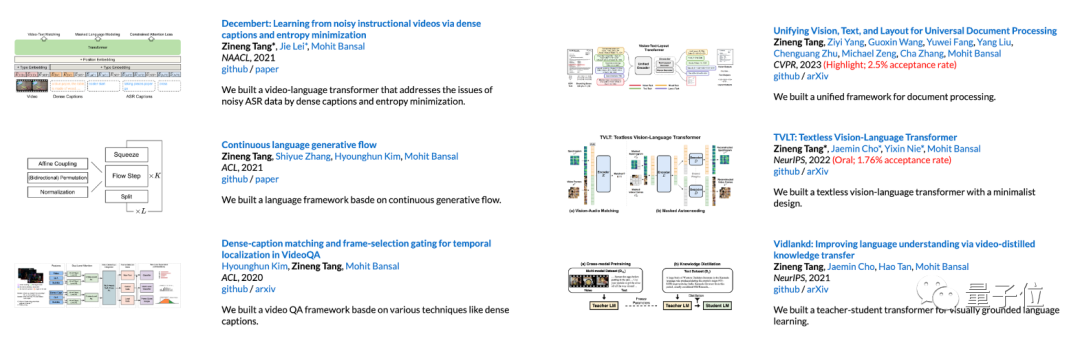
值得一提的是,一作Zineng Tang虽然本科还没毕业,但他已经在CVPR、发了6篇顶会论文,其中5篇都是一作。
所以,这个号称能够“转一切”(any-to-any)的大一统大模型,实现效果究竟如何?
4种模态随意选,打出“组合拳”
大模型CoDi,具有任意输入和输出图、文、声音、视频4种模态的能力。
无论是单模态生成单模态(下图黄)、多模态生成单模态(下图红)、还是多模态生成多模态(下图紫),只要指定输入和输出的模态,CoDi就能理解并生成想要的效果:
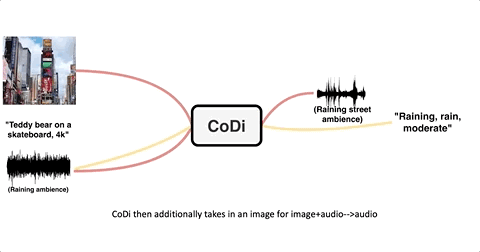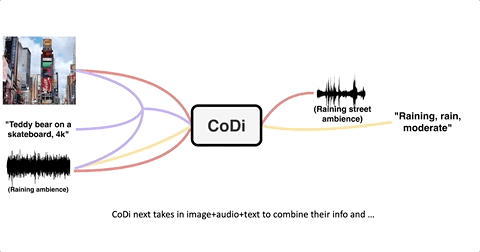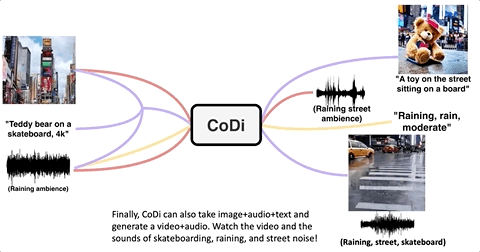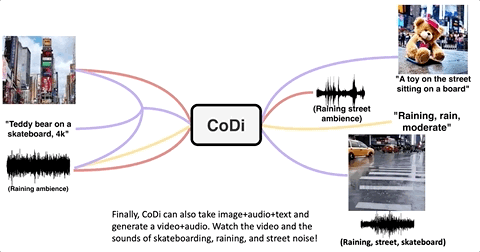
先来看单模态生成单模态。
输入任意一种模态,CoDi都能联想并输出指定的模态,例如,输入一张风景图像,就能输出“山景,日出”这样的文字提示词:

或是输入一段铁轨碰撞声,就能生成一张地铁图像:
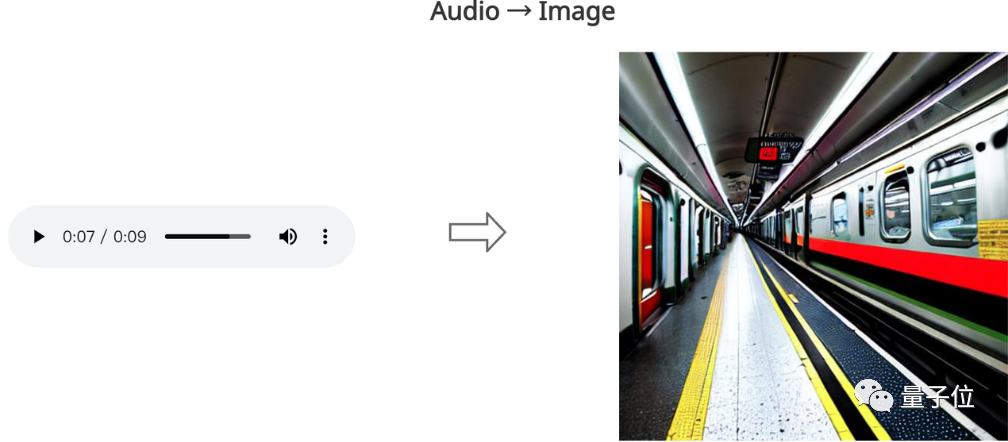
面对多模态生成单模态时,CoDi威力同样不减。
输入一张“熊猫吃竹子”图像,加上一段“在咖啡桌上吃”的文字要求:

CoDi就能生成一段大熊猫坐在咖啡桌旁吃竹子的视频:

或是输入一组文字提示词“油画,恐怖画风,优雅复杂的概念艺术,克雷格·穆林斯(CG绘画之父)风格”,加上一段拍打木板的水声:
CoDi在经过联想后,就能输出一张精致的、气势恢宏的黄昏时分海盗船画像:

最后来看看多模态生成多模态的效果。
给CoDi提供一段钢琴声,加上一张森林中的照片:

CoDi就能想象出一段“在森林中弹钢琴”的文字,并配上对应的插图:

要知道在这之前,AI生成的视频不少都没有配音,停留在老式的“无声电影”阶段。
然而CoDi不仅能生成视频,还能生成搭配视频食用的声音。
例如根据一个“天空中的花火”文字提示词+一段对应的音频,就能生成一个带有爆炸声音的烟花录像:
所以,CoDi究竟是如何做到理解不同的模态,并“打出组合拳”的?
用“对齐”来节省大模型训练数据
事实上,CoDi的打造面临两个难点。
首先是缺少训练数据的问题,以作者们能收集到的数据集为例:
无论是像Laion400M这样的文图数据集、还是像AudioSet之类的音频文字数据集,或是油管上的图像音视频数据集,以及Webvid10M之类的视频数据集,都属于“单模态生成单个或两个模态”的类型。
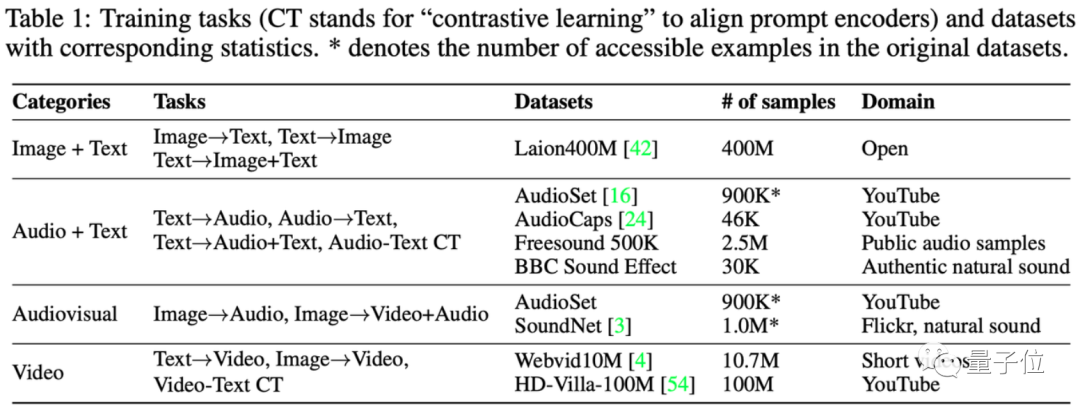
然而,多模态大模型的训练数据需求,随着模态数量的增加呈指数级增长,许多输入输出组合,往往缺少对应的训练数据集。
其次,已有的扩散模型大多是1v1的类型,如何设计并训练模型,确保多模态输入输出的效果,同样是个问题。
针对这两个问题,作者们决定分两个阶段打造CoDi,让它不仅能实现单模态“完美输出”、还能做到多模态“1+1>2”。
在阶段一,组合条件训练,给每个模态都打造一个潜在扩散模型(LDM),进行组合训练。
针对A模态生成B模态数据集缺失的问题,作者们提出了一种名为桥接对齐(Bridging Alignment)的策略。
具体来说,就是以带文本模态的数据集为“中介”,对齐另外几种模态的训练效果。
以音频生成图像为例。
虽然音频生成图像数据集不多,但文本生成音频、文本生成图像的数据集却有不少,因此可以将这两类数据集合并起来,用于训练文本+音频生成图像的效果。
在此期间,文本和音频输入经过模型处理,会被“放置”进一个共享特征空间,并用输出LDM来处理输入输入的组合特征,输出对应的图像结果。
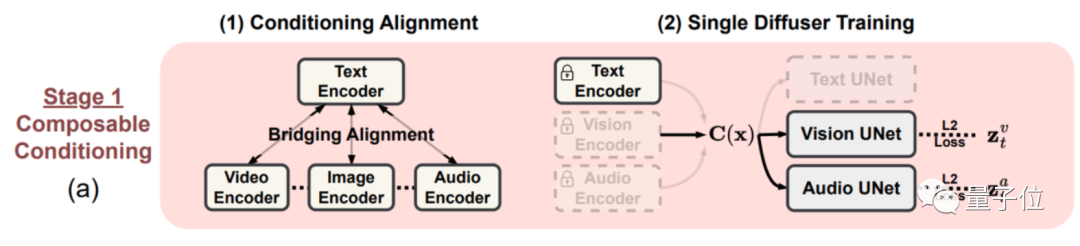
阶段二,进一步增加生成的模态数量。
在阶段一的基础上,给每个潜在扩散模型和环境编码器上增加一个交叉注意力模块,就能将潜在扩散模型的潜变量投射到共享空间中,使得生成的模态也进一步多样化。
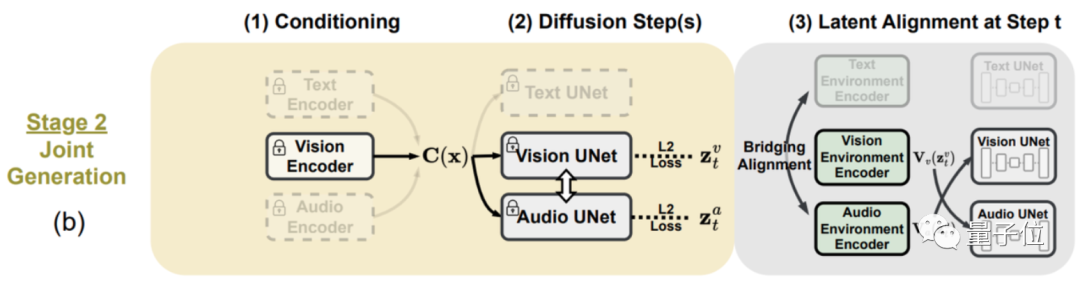
最终训练出来的模型,虽然训练数据类型不是“全能的”,但也具备了多模态输入、多模态输出的能力。

值得一提的是,可别以为这种方法会降低模型生成的质量。
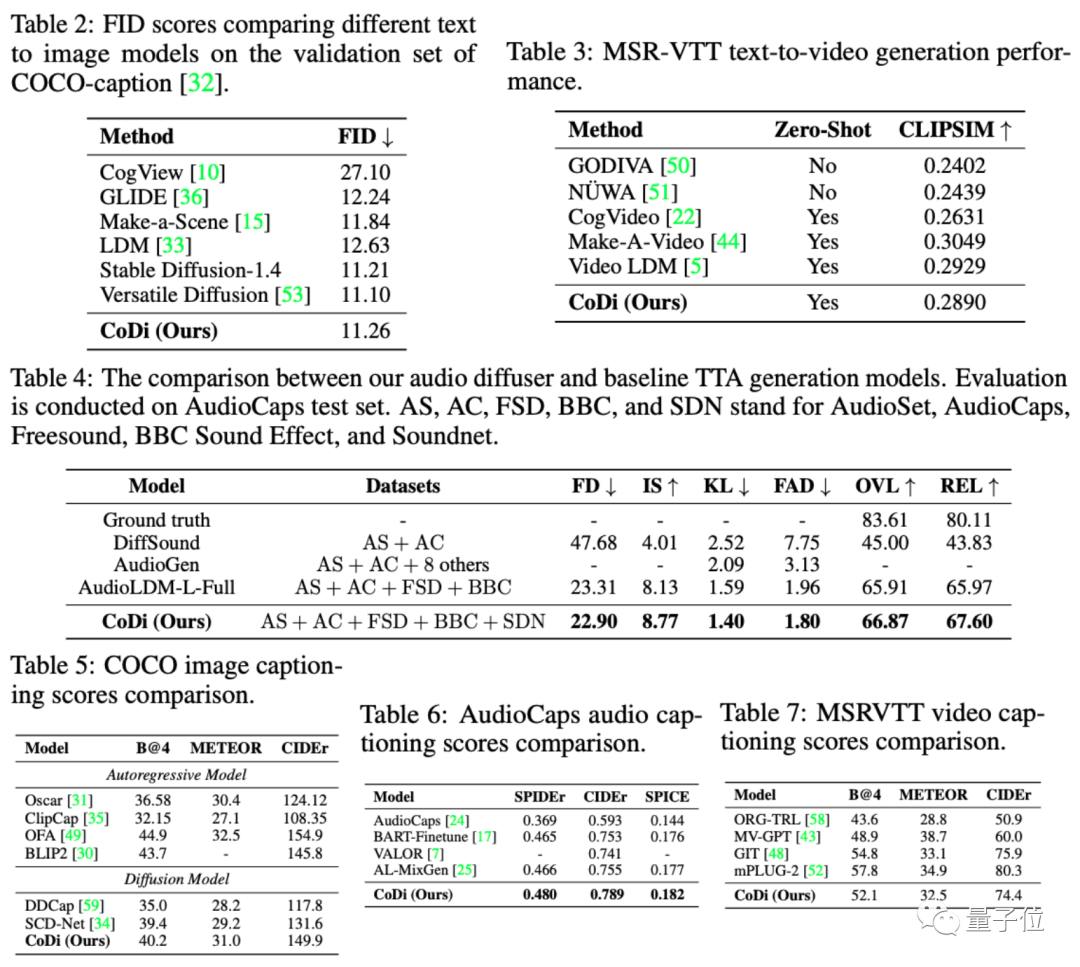
事实上,在多种评估方法上,CoDi均超越了现有多模态大模型的生成效果。
华人本科生,5篇顶会论文一作
一作Zineng Tang,本科就读于北卡罗来纳大学教堂山分校,也是微软研究院的实习生,今年6月将进入加州大学伯克利分校读博。
他的研究兴趣在于多模态学习、机器学习和NLP领域,而从大一开始,他就在NeurIPS、CVPR、ACL和NAACL等顶会上相继发了6篇文章,其中5篇一作。
就在今年1月,Zineng Tang还获得了2023年的美国计算机研究学会(CRA)设立的优秀本科生研究员奖。
每年全美国能获得这个奖项的本科生,只有4人。

这一奖项旨在表彰在计算机研究领域有杰出研究潜力的本科生,包括MIT、斯坦福、哈佛和耶鲁大学等不少北美名校在内,每年都会提名一些优秀学生,经过层层筛选后决定获奖者。
通讯作者Ziyi Yang,目前是微软Azure认知服务研究团队(CSR)的高级研究员,研究方向是多模态理解和生成,文档智能和NLP等。
在加入微软之前,他本科毕业于南京大学物理系,并于斯坦福大学获得电气工程硕士和机械工程博士学位。
通讯作者Mohit Bansal,是北卡罗来纳大学教堂山分校计算机系教授。他于加州大学伯克利分校获得博士学位,目前研究方向是NLP和多模态机器学习,尤其侧重语言生成问答和对话、以及可解释深度学习等。
你感觉多模态大模型发展的下一阶段,会是什么样子?
论文地址:
https://arxiv.org/abs/2305.11846
项目地址:
https://github.com/microsoft/i-Code/tree/main/i-Code-V3
参考链接:
[1]https://twitter.com/AviSchiffmann/status/1660771055676588033
[2]https://twitter.com/ZinengTang/status/1660726736642887681
[3]https://cra.org/2023-outstanding-undergraduate-researcher-award-recipients/
[4]https://codi-gen.github.io/
















 6
6











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









