






西风 发自 凹非寺
量子位 | 公众号 QbitAI
“我想问在座一个问题,无论是求真书院还是丘成桐少年班的同学,如果这个问题都不知道,那你就不应该在这个班!”
2024国际基础科学大会“基础科学与人工智能论坛”上,联想集团CTO、欧洲科学院外籍院士芮勇此言一出,全场都有些紧张了起来。
但紧接着,他抛出的问题却是:13.11和13.8哪个大?

好家伙,就问谁还不知道这个梗。
不过,这次不是嘲笑模型失智。来自学界业界的几位AI大牛,分析了模型“幻觉”等等一连串问题,引出了他们对“人工智能的下一步该怎么走”的看法。

总结来说,包括以下几个观点:
大模型发展下一步要走出“没有抽象能力、没有主观价值、没有情感知识”的搜索范式。
商业应用落后于模型本身规模增长,缺乏一个超级产品,能真正把投入的价值体现出来。
幻觉限制下,下一步可以思考如何再扩大模型的泛化性和互动性,多模态是一个选择。
使智能体知道自己的能力边界,是一个很重要的问题。
……
香港大学数据学院院长、香港大学计算机系系主任马毅在讨论过程中甚至为现在主流在做的“人工智能”打上了问号:
人工智能技术发展积累了很多的经验,有些我们可以解释,有些我们不能解释,现在正好就是非常需要理论的时候。实际上过去这十几年我们的scholarship可以说是没有太多突破的,很大可能是被产业、被工程技术的快速发展影响了学术本身的节奏。

一起来看大佬们具体都说了啥。
何为智能本质?
现场,香港大学数据学院院长、香港大学计算机系系主任马毅,特别以“回归理论基石,探寻智能本质”为题发表了主旨演讲。
其中的观点与其在圆桌上讨论的问题不谋而合。
马毅教授演讲主题是“回归理论基石,探寻智能本质”,其中回顾了AI历史发展进程,并对目前AI发展提出了自己的看法。

他首先讲了生命与智能的进化。
在他个人看来,生命就是智能的载体,生命能产生能进化,就是智能机制作用的结果。而且,世界并不是随机的,是可预测的,生命在不断的进化过程中,学到更多世界可预测的知识。
物竞天择适者生存,这就是智能的一种反馈,类似于现在强化学习的概念。

从植物到动物、爬行动物、鸟类,再到人类,生命一直在提高自己的智能,但有一个现象,好像智能越高的生命出生以后跟随其爸爸妈妈的时间越长。为什么?
马毅教授进一步解释:因为基因不够,一些能力要去学习。学习能力越强,需要学习的东西越多,这才是智能体的更高级形式。
如果以个体方式进行学习,还是不够快不够好,所以人发明了语言,人的智能变成一个群体智能形式。
产生了群体智能,发生了一个质变。我们不光只是从经验观测去学习这些可预测的现象,还出现了抽象逻辑思维,我们把它叫做人的智能,或者后来叫做人工的智能。

接下来,他讲了机器智能的起源。
上世纪40年代起,人类开始尝试让机器模拟生物尤其是动物的智能。
人类开始从神经元建模,探索“大脑感知是怎么回事儿”,之后大家发现模拟动物神经系统这件事情应该从人工神经网络去搭建整体,研究变得越来越复杂。

这件事情并不是一帆风顺,中间经历了两个寒冬,大家发现了神经网络的一些局限性,有些人仍在坚持解决这些挑战。
之后数据算力发展,训练神经网络变成了可能,越来越深的网络开始发展起来,性能越来越好。
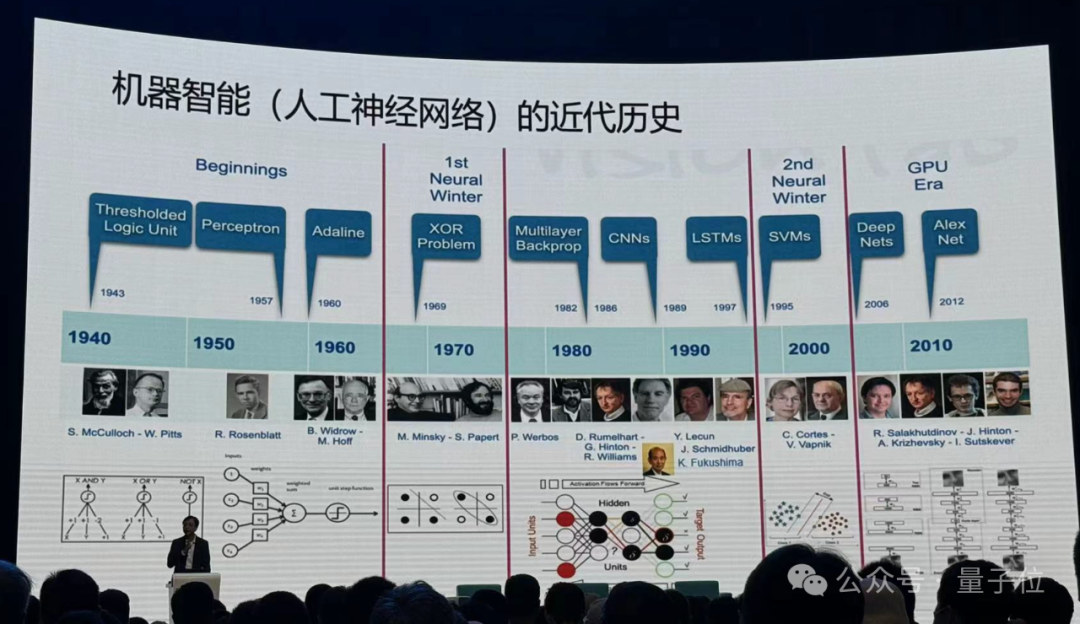
但有个最大的问题:这些网络都是经验设计的,它是个黑盒子,而且这个盒子越来越大,人们不知道里面在干什么。
黑盒有何不好?从技术角度,经验设计也可以,可以不断试错。但是其中代价很大,周期很长,结果很难控。此外:
只要这个世界上有大家解释不了的但是很重要的现象,很多人被蒙在鼓里,就会制造恐慌,现在这个事情正在发生。
所以,如何把黑盒打开?马毅教授提出要回到本来的问题:为什么要学习?生命为什么能进化?
他特别强调,一定要谈能通过计算实现的东西:
不要谈任何抽象的东西,这是我给大家的建议,你一定要谈怎么去计算,怎么去执行这件事情。

所以要学什么?
马毅教授认为,要学可预测的规律性的东西。
比如手里拿着一根笔,一松手,大家都知道会发生什么,而且动作快的话还能抓住。这在牛顿之前就是已知的。人和动物貌似都是对外部世界做了很好的建模。
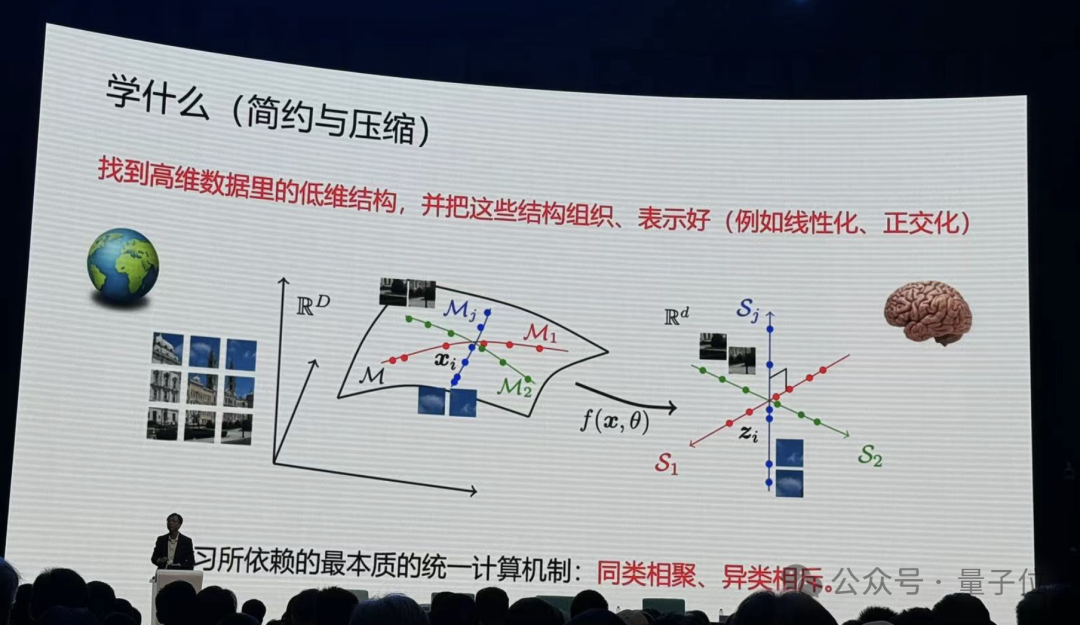
而在数学上,可预测的信息都统一以数据在高维空间中的低维结构体现出来。
那么统一的计算机制是什么?马毅教授给出了回答:同类相聚、异类相斥,本质就这么简单。
如何度量做的好不好?为什么要压缩?
他举了个例子,如下图。比如说世界是随机的,什么都不知道,所有的事情皆可发生,如果用蓝色球代替,下一秒钟所有蓝色球都是可能发生的。
但如果要记住其中一件事情发生,就要对整个空间编码,给它一个代码,只有绿色球的区域才可能发生,蓝色球的部分就会少很多。
当我们知道的会发生的区域越细后,我们对这个世界的未知就变得越来越少,40年代信息理论就是在建立这个事情。
要想更好找到这些绿色区域,就要在大脑里面把它组织的更好。所以我们的大脑是在对这种现象,对这个低维的结构在做这种组织。
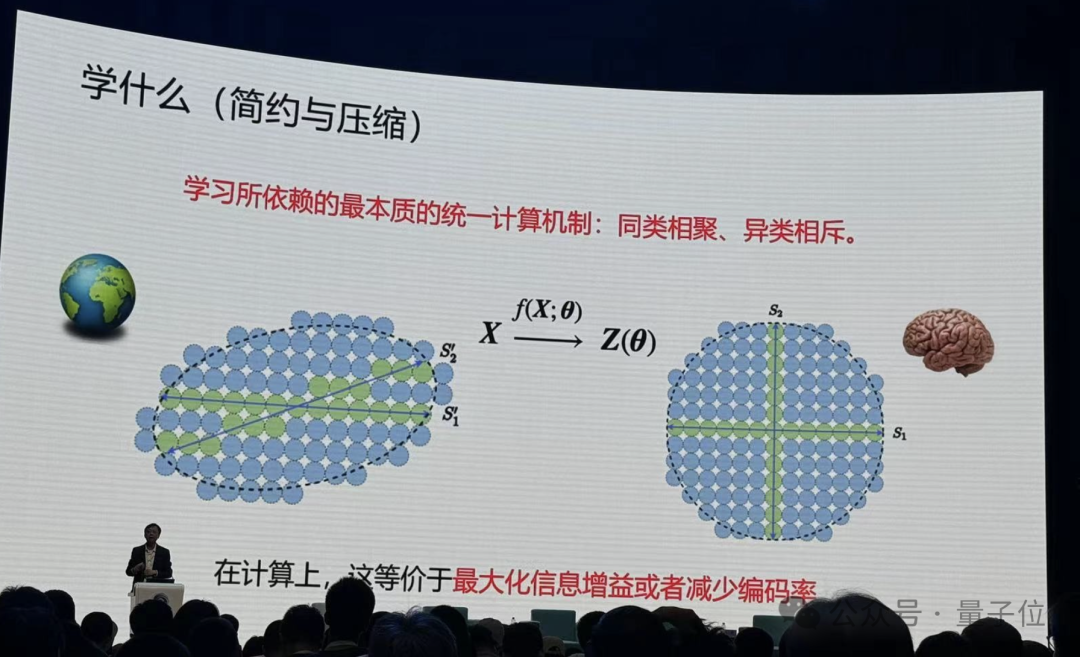
在计算上如何实现这个目标?
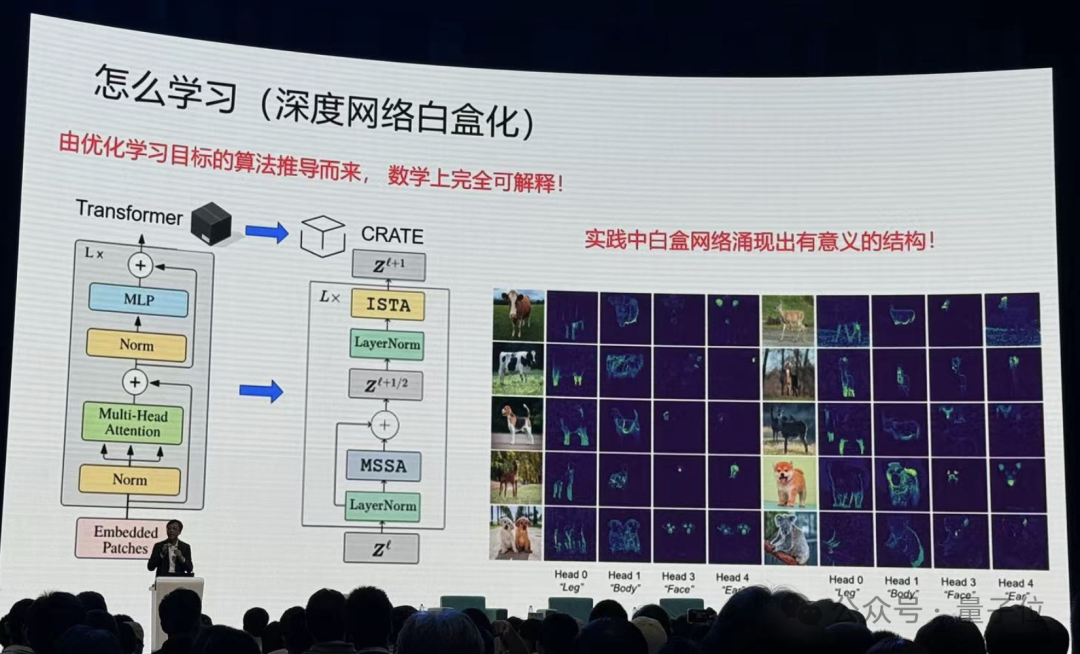
马毅教授表示,所有深度网络实际上都在做这件事情。像现在Transformer,对图像进行分割,进行分类识别,就在做这个事情。
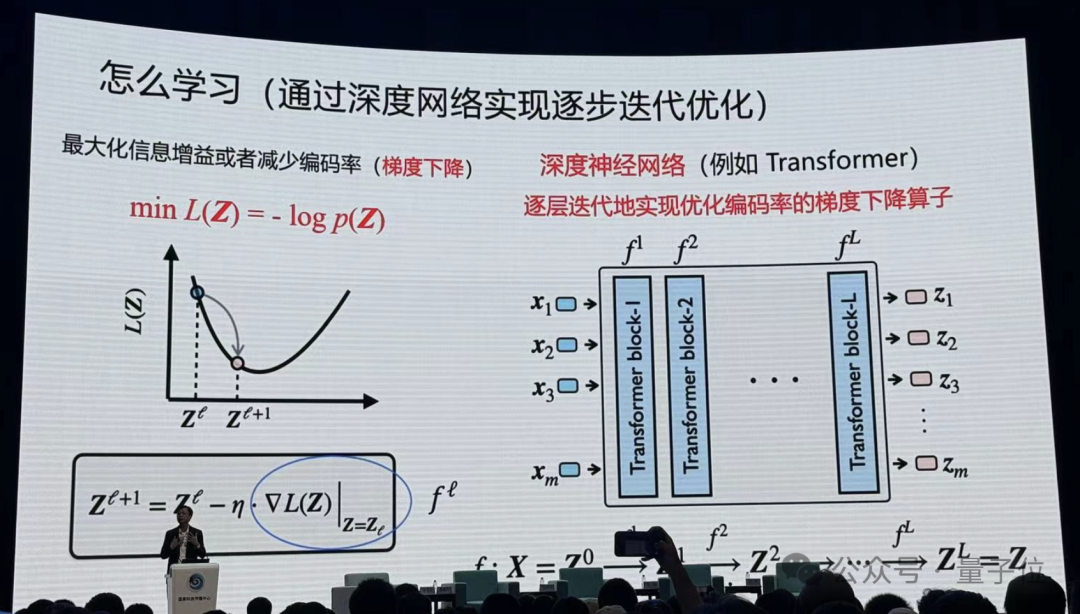
实际上神经网络每一层就是在压缩数据。
在这当中数学起到非常重要的作用,你去严格度量要优化什么东西,严格去讲怎么去优化,当你把这两件事做完以后,你会发现你得到的算子跟现在经验找到的很多算子非常相似。
Transformer也好,ResNet也好, CNN也好,都是做这件事情以不同的实现方式。而且在统计、几何上完全可以解释它在干什么。
但优化本身最优解未必是正确解,在压缩过程中可能丢掉了重要信息,怎么证明现有的信息维度是好的呢?怎么证明不会产生幻觉?
回到学习的根本,我们为什么要记住这些东西?是为了要在大脑里对物理世界做仿真,为了更好地在物理空间中进行预测。
之后马毅提到了对齐这一概念:
所以对齐不是跟人对齐,对齐是这个模型自己跟自己学到的东西对齐。
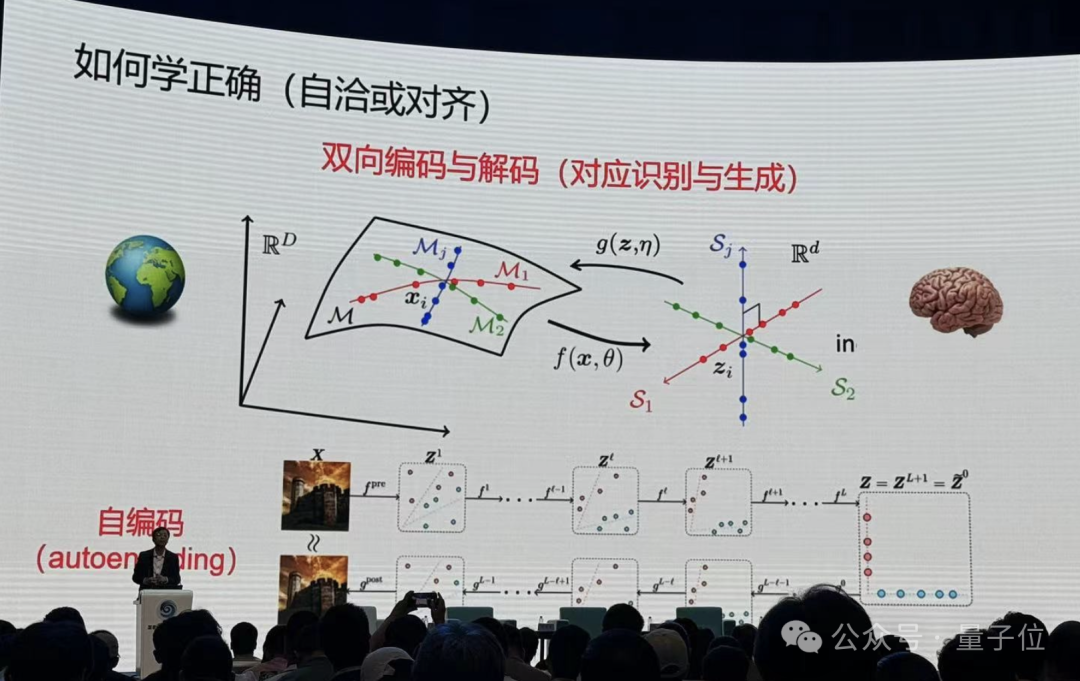
从里到外两边学到一个autoencoding并不够,自然界的动物是如何学习外部世界的物理模型的——
不断通过自己的观测,去预测外部世界,只要和观测是一致的,就可以了。这就涉及到一个闭环的概念。
只要活着的生物,只要智能的生物,全是闭环性。
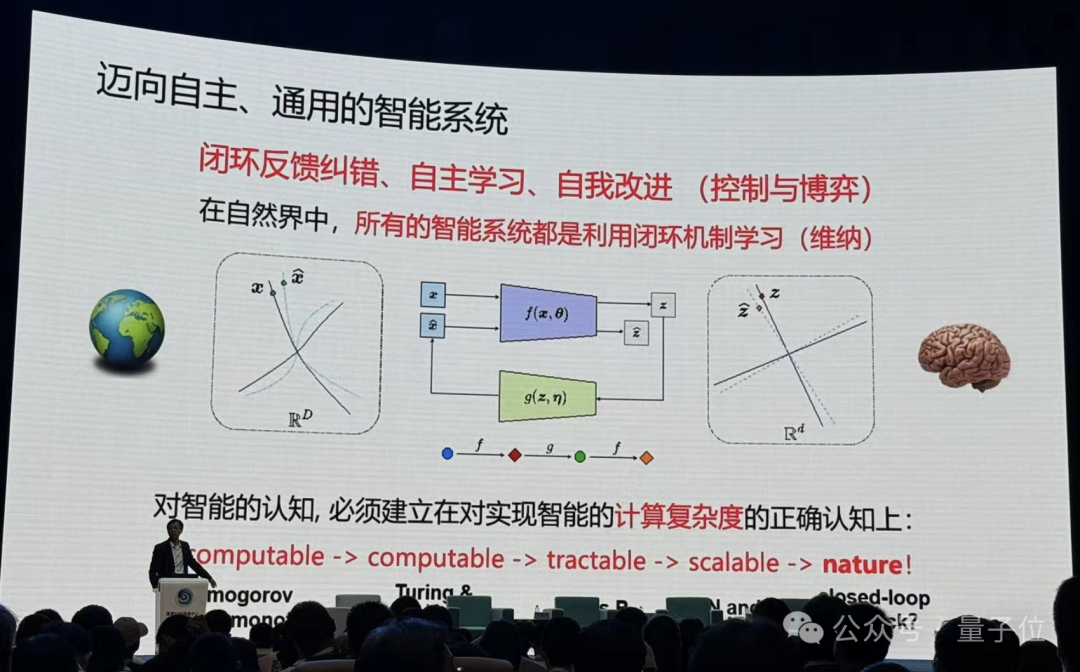
之后马毅教授引出,我们离真正的智能还差很远。
什么是智能?大家经常把知识和智能混在一起,一个系统有知识就是有智能吗?一个智能系统,必须具备自我改进、增加自己知识的基础。
最后马毅教授进行了总结。
回顾历史,40年代大家都想让机器去模仿动物,但是50年代图灵提出了一件事——机器能不能像人类一样思考。1956年达特茅斯会议,一群人坐在一起,他们的目的就是一定要做人区别于动物特有的智能:抽象能力、符号运算、逻辑推理、因果分析等。
这是1956年他们定义的人工智能要做的事情,后来这些人基本上都得图灵奖。所以你以后要得图灵奖,是选择去从众还是做一些独特的东西……
回看我们过去10年到底在干什么?
目前的“人工智能”在做图像识别、图像生成、文本生成、压缩去噪、强化学习,马毅教授认为,从基础上我们做的事情就是动物这一层的事情,包括预测下一个token、下一帧图像。
不是说后来我们没有人在做。但不是主流的大模型。

他进一步解释,足够多的钱砸进去,足够的数据砸进去,模型很多的性能还是会继续发展,但是长期没有理论会出现问题,就像盲人摸象。
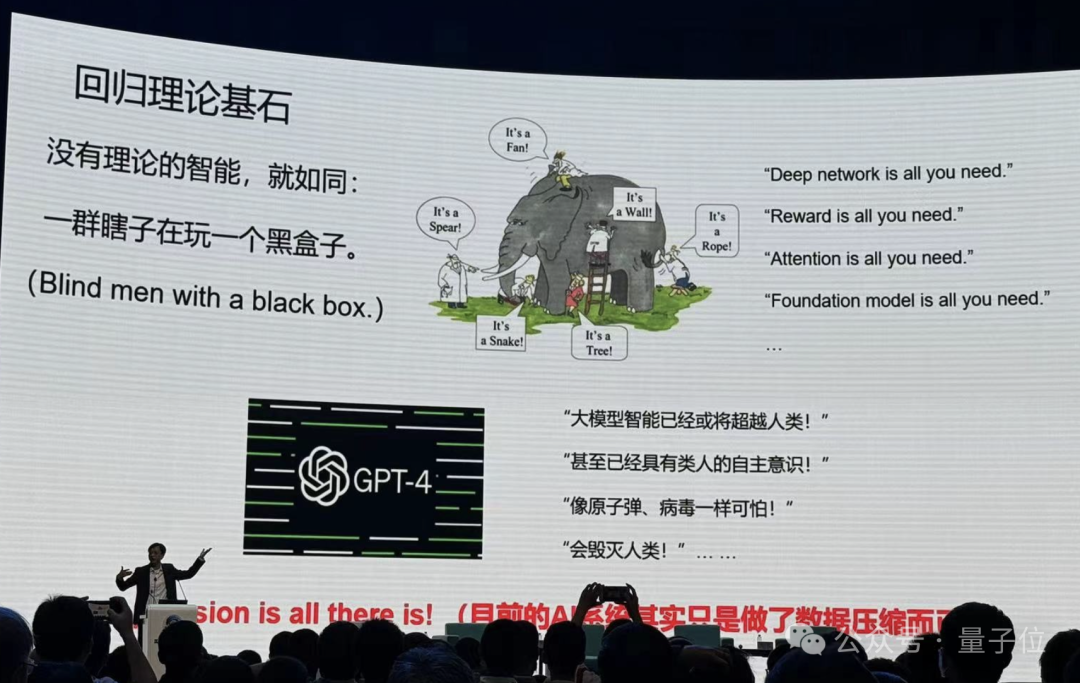
马毅教授表示,分享其个人的这段历程,希望能给年轻人一些启发。
有了原理我们就可以大胆去设计,就不再等着下一代谁再发明一个好像不错的网络,咱们再一起用。那你的机会在哪里呢?
下面来看圆桌论坛中,其他AI大牛对“人工智能下一步该怎么走?”这个问题是如何回答的。
人工智能下一步该怎么走?
大模型要有“范式”的变化
英国皇家工程院院士、欧洲科学院院士、香港工程科学院院士、香港科技大学首席副校长郭毅可认为,我们现在处于一个非常有趣的时刻——
因为Scaling Law被广泛接受,百模大战逐渐形成了一个资源大战。看似现在只需要做两件事,有了Transformer模型以后,要解决的就是大算力和大数据的问题。
然而,在他看来事实并非如此。当下AI发展还面临很多问题,其一是有限算力和无穷需求的问题。
在这种情况下,应该怎样做大模型?郭院士通过一些实践,分享了自己的思考。
首先郭院士提到了在算力限制下,采用更经济的MOE混合专家模型也能达到很好的效果。
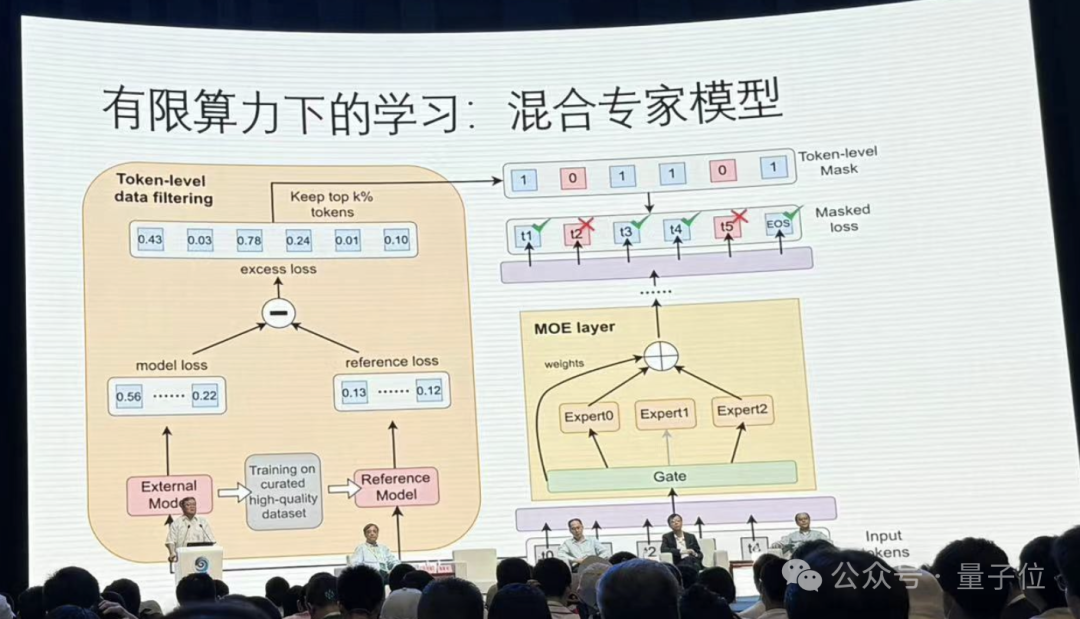
此外,怎样把一个模型训完之后,不断用新的数据改善,让它能够把该记住的记住,该忘的忘了,而且在需要的时候还能够记起已经忘了的东西,也是一个很难的问题。
对于业界的一些“数据已经是用完了”的说法,郭院士表示不认同,“实际上只是变成了模型被压缩了,而压缩好的数据可以再生成新的数据”,也就是用生成模型来生成数据。
接着,不是所有东西模型都要从头学习,可以把知识嵌入到基础模型里面。这方面也有很多工作要做。
除了算力,算法上还有一个问题:机器智能和人类智能本身的培养具有两极性。
郭院士认为,训练大模型,更重要的问题不在前面,而是在后面。
如下图所示,大模型的进化路径是从自我学习>间接知识>价值观>常识,而人类教育的培养路径与之相反。

正因为如此,郭院士认为应该走出今天大模型“没有抽象能力、没有主观价值、没有情感知识”的搜索范式。
我们都知道人类的语言是伟大的,人类语言里面不仅是内容,不仅是信息,更多的是人性,是信息的能量,那么这些东西怎样归类到模型中去?是我们未来研究的一个重要的方向。

总结来说,对于人工智能下一步该怎么走,郭院士认为有三个发展阶段:
第一个阶段以真实性为本;第二个阶段以价值为本,机器要有能力阐述自己的观点,要形成自己的一种主观价值,并且这个观点可以根据它的环境来改变;第三当它有了价值观以后,才懂得什么是新奇,有了新奇才可能进行创造。
到了创造这个模式,所谓的幻觉不是问题,因为幻觉只有在范式模式下才是个问题。写小说一定是幻觉,没有幻觉,写不出小说来,它只要保持一致性,不需要真实性,所以只要反映一种价值就可以了,所以从这个意义上来讲,大模型的发展实际上要有范式的变化。
大模型发展缺一个“超级产品”
京东集团副总裁、华盛顿大学兼职教授、博士生导师何晓冬认为AI下一步面临三个问题。
首先,他认为从某种意义上来说现在大模型发展进入了一个平台期。
由于数据和算力限制,如果简单基于规模来提升,有可能达到天花板,算力资源也会成为一个越来越重的负担。如果按照最新的价格战(标价),很可能大模型产生的经济效益连电费都覆盖不了,那么自然是不可持续的。
其次,何教授认为整个商业应用有些落后于模型本身的规模增长,中长期来看,这终将会成为一个问题:
特别是我们看到这么大规模的时候,他不再简单是一个科学问题,它也会成为一个工程问题,比如说参数到了万亿级,调用数据到10万亿token级别。那么必然需要提出一个问题:它带来的社会价值。
由此,何教授认为目前缺乏一个超级应用和超级产品,能够真正把投入的价值体现出来。
第三个问题是一个相对比较具体的问题,即大模型幻觉。
如果我们想在大模型之上建设一个AI产业大厦,就要对基础大模型幻觉有极高的要求。如果基础大模型错误率很高,那么很难想象这上面可以叠加更多商业应用。
严肃的产业应用是需要解决幻觉的。
何教授认为在幻觉限制下,下一步可以思考如何再扩大模型的泛化性和互动性,而多模态是一个必然的选择。

大模型缺乏“能力边界”认知
联想集团CTO、欧洲科学院外籍院士芮勇从工业界视角,给出了他对AI下一步的看法。
他表示,从工业界来看,更重要的是模型如何落地。在落地方面,芮勇博士主要讲了两点:
光有大模型是不够,一定要发展智能体。
光有云测大模型也是不够,需要有一个混合框架。

具体来说,芮勇博士首先列举了一些研究,并指出大模型目前局限性越来越明显。比如开头提到的“13.8和13.11哪个大”的问题,可以看出模型没有真正理解问题。
在他看来,目前大模型其实只是把在高维语义空间里看到的海量碎片信息连接起来,光靠堆砌大算力大网络来造生成式大模型是不够的,而下一步应该朝着智能体的方向发展。
芮勇博士特别强调了大模型能力边界问题。
今天的大模型其实并不知道它自己的能力边界在哪。
为什么大模型会出现幻觉,为什么会一本正经胡说八道?其实它不是想骗我们,而是不知道自己知道什么,也不知道自己不知道什么,这是一个很重要的问题,所以我觉得第一步要使智能体知道自己的能力边界。
此外,芮勇博士表示AI落地光有智能也不够,云上的公有大模型需要面向企业进行私有化。数据驱动加上知识驱动,形成混合的AI模型,而且小模型在很多情况下也非常有用,还有面向个人的模型,能够知道个人的喜好。
它将不是完全基于云测的大模型,而是一个混合的端边云相结合的大模型。
— 完 —
量子位年度AI主题策划正在征集中!
欢迎投稿专题 一千零一个AI应用,365行AI落地方案
或与我们分享你在寻找的AI产品,或发现的AI新动向

点这里👇关注我,记得标星哦~
















 16
16

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









