






西风 发自 凹非寺
量子位 | 公众号 QbitAI
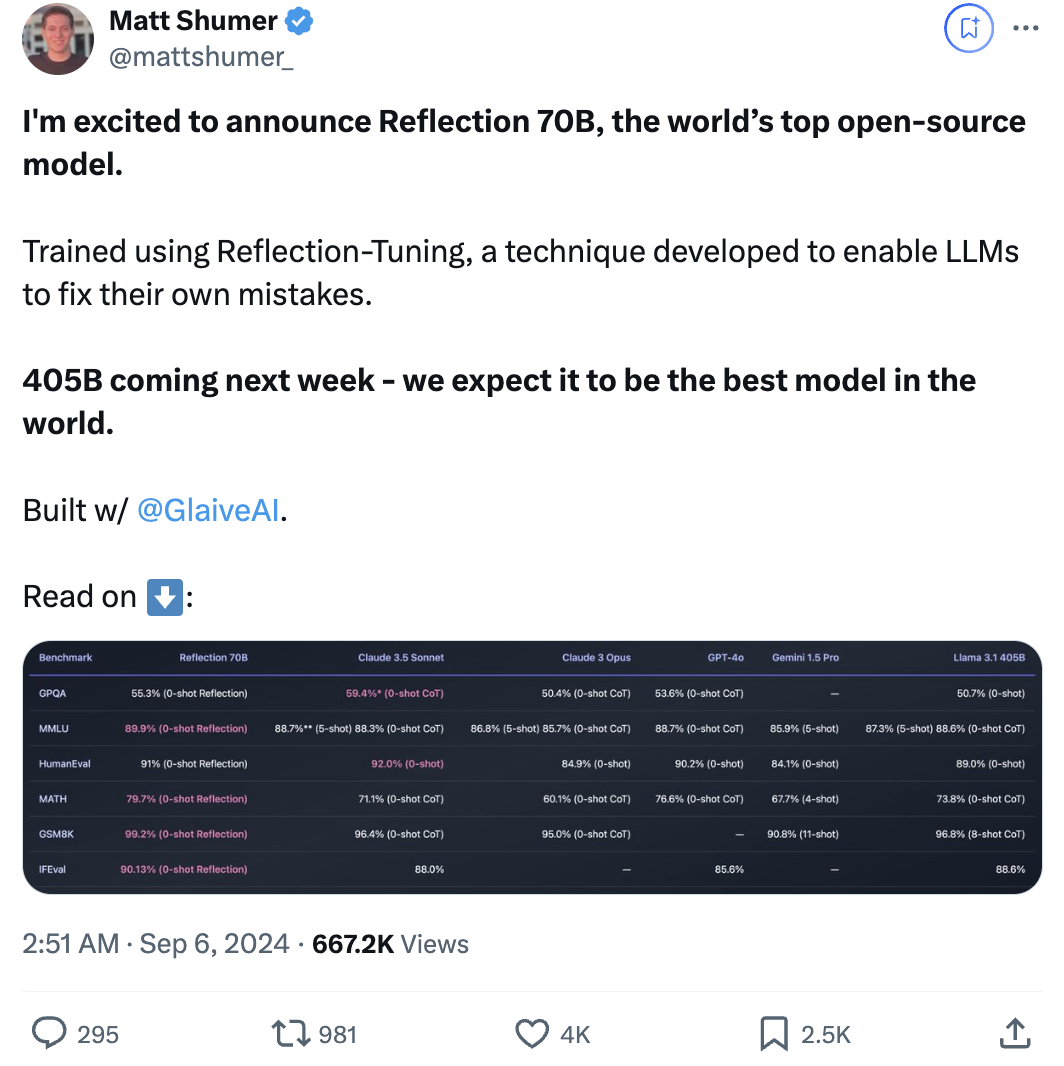
开源大模型王座突然易主,居然来自一家小创业团队,瞬间引爆业界。
新模型名为Reflection 70B,使用一种全新训练技术,让AI学会在推理过程中纠正自己的错误和幻觉。
比如最近流行的数r测试中,一开始它犯了和大多数模型一样的错误,但主动在<反思>标签中纠正了自己。

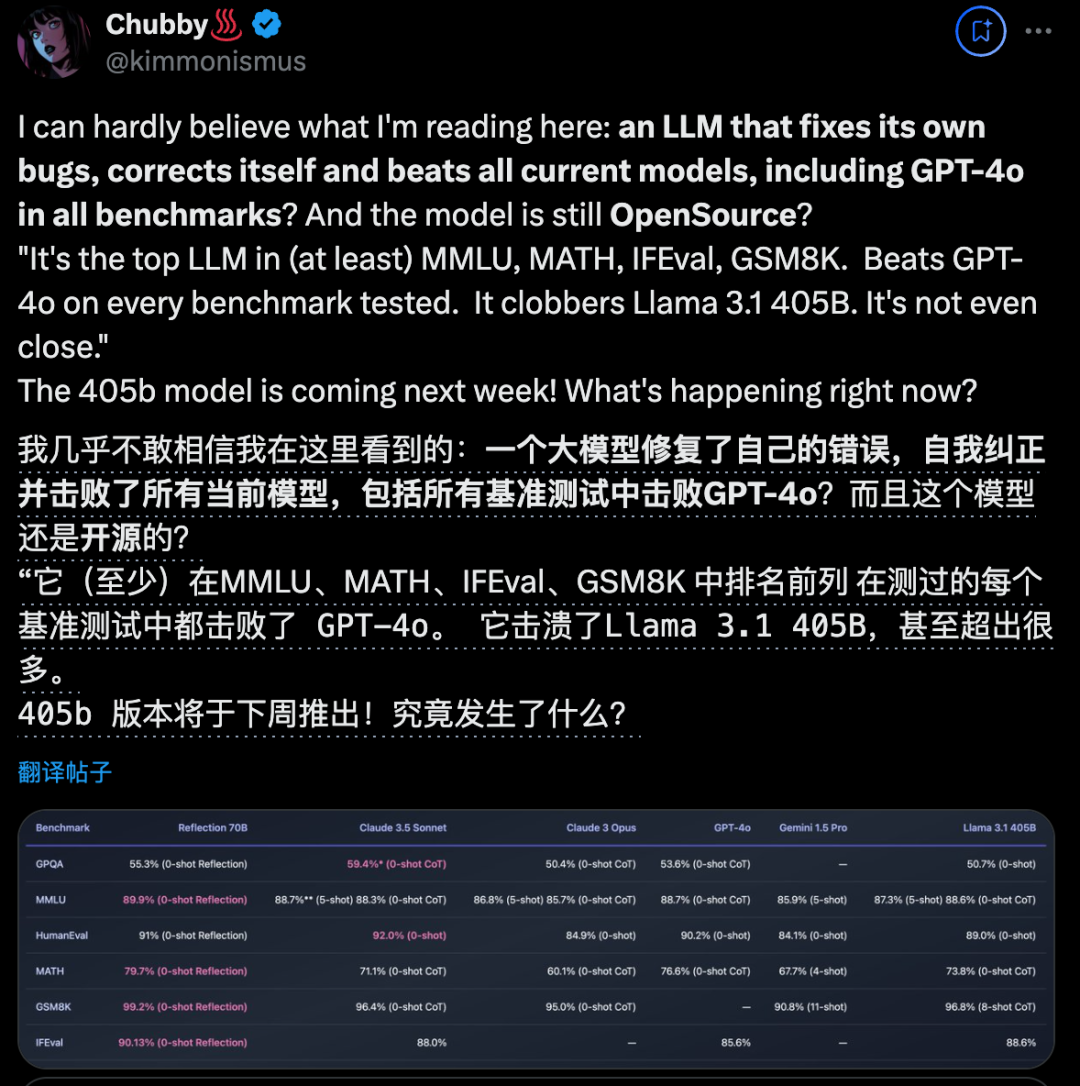
在官方评测中,70B模型全面超越最强开源Llama 3.1 405B、GPT-4o、Claude 3 Opus、Gemini 1.5 Pro,特别是数学基准GSM8K上直接刷爆,得分99.2%。
这个结果也让OpenAI科学家、德扑AI之父Noam Brown激情开麦:
GSM8K得分99%!是不是可以正式淘汰这个基准了?

模型刚刚上线网友就把试玩挤爆了,对此Meta还主动支援了更多算力。


在网友测试中,Reflection 70B能回答对GSM8K数据集中本身答案错误的问题:
我向模型提供了GSM8K中存在的5个“ground_truth”本身就不正确的问题。
模型没有重复数据集中的错误答案,而是全部回答对了,这很令人印象深刻,表明那99.2%的准确率并非来自于记忆测试集!
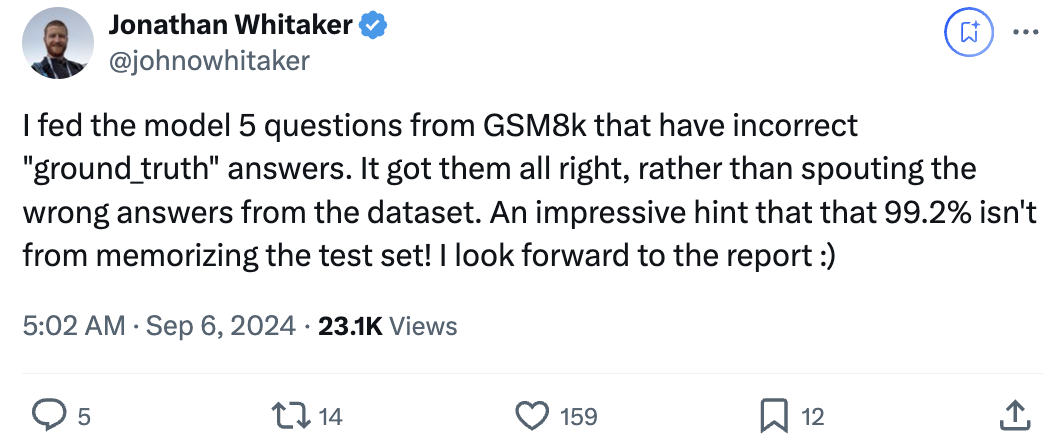
数各种r都不在话下,连生造词“drirrrngrrrrrnnn”中有几个r也能被正确数对。
网友纷纷对小团队做出的开源超越顶流闭源感到惊讶,现在最强开源模型可以在本地运行了。

关键70B还只是个开始,官方表示下周还会发布更大的Reflection 405B。
预计405B性能将大幅优于Sonnet和GPT-4o。
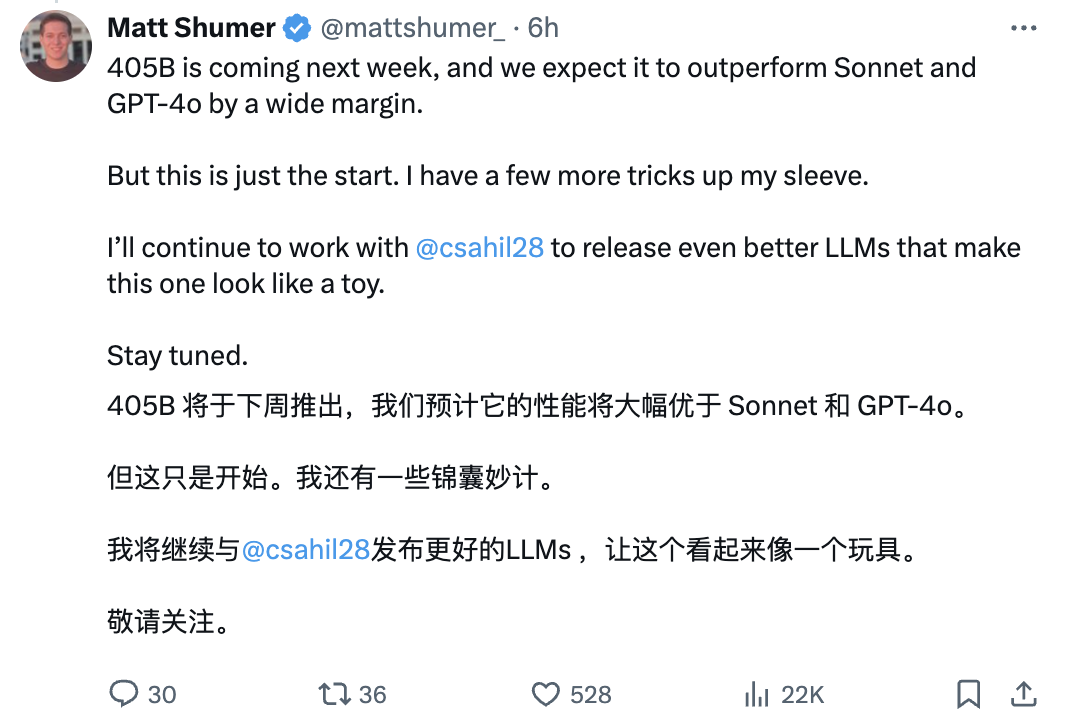
Reflection 70B权重已公开,API访问将于今天晚些时候由Hyperbolic Labs提供。
模型能自我反思纠正错误
目前关于Reflection 70B的更多细节如下。
Reflection 70B能力提升的关键,是采用了一种名为Reflection-Tuning的训练方法,它能够让模型反思自己生成的文本,在最终确定回应前检测并纠正自身推理中的错误。
训练中的数据来自使用GlaiveAI平台生成的合成数据。

Reflection 70B基于Llama 3.1 70B Instruct,可以使用与其它Llama模型相同的代码、pipeline等从Reflection Llama-3.1 70B进行采样。
它甚至使用了标准的Llama 3.1聊天格式。
不过,Reflection 70B引入了一些特殊tokens,结构化输出过程。

如下面这个例子所展示的,规划过程分为一个独立的步骤,这样做可以提高CoT效果,并保持输出精炼:
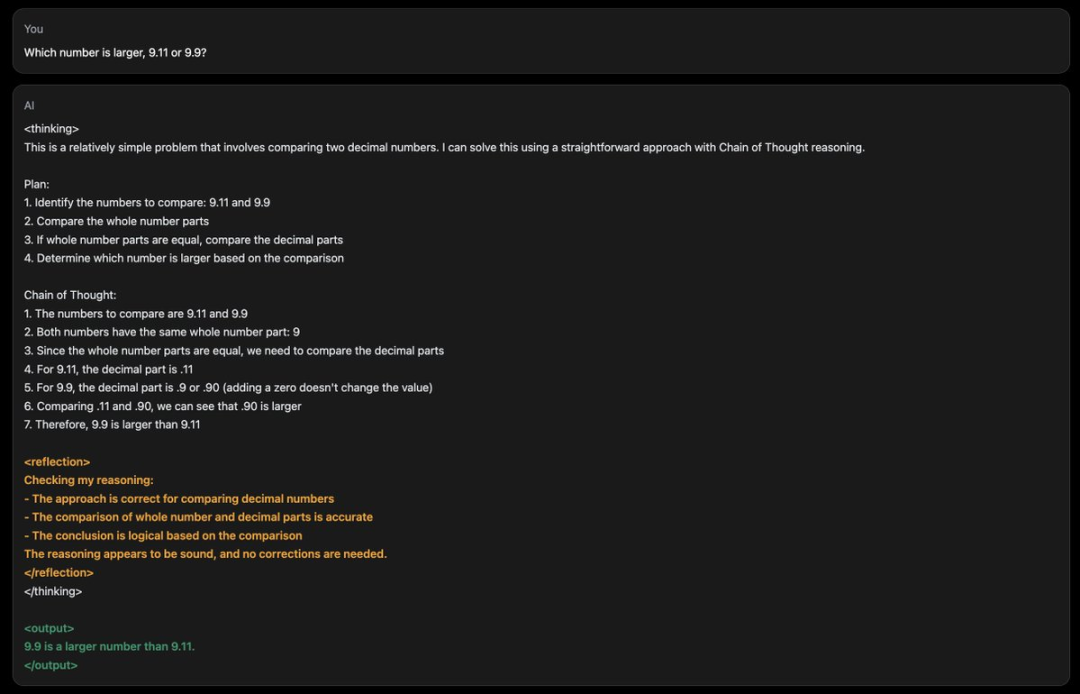
模型将从在<thinking>和</thinking>标签内输出推理开始,一旦对其推理感到满意,就会在<output>和</output>标签内输出最终答案。
所以它能够将其内部思考和推理与最终答案分离。
在<thinking>部分,模型可能会输出一个或多个<reflection>标签,这表明模型发现了其推理中的错误,并将在提供最终答案之前尝试纠正该错误。
系统提示如下:
You are a world-class AI system, capable of complex reasoning and reflection. Reason through the query inside tags, and then provide your final response inside tags. If you detect that you made a mistake in your reasoning at any point, correct yourself inside tags.
(你是一个世界级人工智能系统,能够进行复杂的推理和反思。在标签内对查询进行推理,然后在标签内提供你的最终回应。如果你发现自己在任何时候推理出错,请在标签内纠正自己。)

此外值得一提的是,基准测试中,所有基准都已通过LMSys的LLM Decontaminator检查污染,隔离了<output>部分,并单独对这一部分进行测试。
使用Reflection 70B的时候,官方还分享了小tips:
初步建议参数temperature为.7 , top_p为.95
为提高准确性,最好附加“Think carefully.”在Prompt末尾
官方还表示,下周会发布一份报告,详细介绍模型训练过程和发现。
Agent创业团队打造
Reflection 70B的背后是一支小团队,由HyperWriteAI的CEO Mutt Shumer带领。

领英显示,Mutt Shumer是一位连续创业者,毕业于美国锡拉丘兹大学,现任OthersideAI的联合创始人兼CEO。

OthersideAI是一家AI应用公司,致力于通过大规模AI系统开发全球最先进的自动补全工具,也是HyperWrite的幕后公司。
HyperWrite是一个浏览器操作agent,可以像人一样操作谷歌浏览器来完成一系列任务,比如订披萨:

和gpt-llm-trainer一样,你只需要用文字描述目标,它就会一边列步骤,一边执行。
刚推出时号称“比AutoGPT强”。
HyperWrite还可以在谷歌扩展程序中安装。
另外,Mutt Shumer高中时期就创立了Visos,致力于开发用于医疗用途的下一代虚拟现实软件。
还创立了FURI,这是一家旨在通过创造高性能产品并以公平的价格销售它们来颠覆体育用品行业的公司。

虽然有Meta支持,但目前打开试玩,还是:暂时无法访问。

感兴趣的童鞋可以先码住了~
https://reflection-playground-production.up.railway.app/
参考链接:
[1]https://huggingface.co/mattshumer/Reflection-Llama-3.1-70B
[2]https://x.com/mattshumer_/status/1831767014341538166
[3]https://x.com/polynoamial/status/1831798985528635806
[4]https://x.com/degeneratoor/status/1831809610451448196
[5]https://x.com/kimmonismus/status/1831772661296345333
— 完 —
量子位年度AI主题策划正在征集中!
欢迎投稿专题 一千零一个AI应用,365行AI落地方案
或与我们分享你在寻找的AI产品,或发现的AI新动向

点这里👇关注我,记得标星哦~
















 6
6

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









