







由于pointRCNN源码的训练和inference很详细,但是没有可视化的代码,本文介绍其3d框结果的可视化方法
1. 跑通pointRCNN
https://github.com/sshaoshuai/PointRCNN
pointRCNN的运行本文就不赘述了。
我是下载的作者训练好的模型,跑了一遍inference,因为生成的检测结果在下面可视化时会用到
2. 将pointRCNN预测结果拷贝到KITTI数据集
pointRCNN的结果存储在:(里面包含000001.txt等等,存的是3d框的预测结果)
PointRCNN/output/rcnn/default/eval/epoch_no_number/val/final_result
把整个文件夹复制到kitti数据集的training目录下,文件夹命名pred
数据组织结构如下:
(注意,这里的training里面是全部7481张图,不然会报错没有000000.txt)
kitti
object
testing
calib
image_2
label_2
velodyne
training
calib
image_2
label_2
velodyne
pred # 这个是需要自己复制过来的
3. 运行可视化源码kitti_object_vis
源码地址:https://github.com/kuixu/kitti_object_vis
下载源码并进到源码文件夹
git clone https://github.com/kuixu/kitti_object_vis
把上述kitti数据集的object/目录,链接到data/目录下过去,并命名为obj(因为这个源码需求)
cd kitti_object_vis/data
ln -s /home/ubuntu/dataset/KITTI/object obj
下载源码和源码所需的库(mayavi之类的),照readme里面去做
运行命令分为几种:
(1) 只显示LiDAR 仅真值
cd kitti_object_vis
python3 kitti_object.py --show_lidar_with_depth --img_fov --const_box --vis
终端按回车键进行下一张图
(2) 显示LiDAR和image 仅真值
python3 kitti_object.py --show_lidar_with_depth --img_fov --const_box --vis --show_image_with_boxes
终端按回车键进行下一张图
(3) 显示特定某张图的LiDAR和image 仅真值
python3 kitti_object.py --show_lidar_with_depth --img_fov --const_box --vis --show_image_with_boxes --ind 100
ind 100表示就是图像编号为000100.txt
注:红色是预测框,绿色是真值框
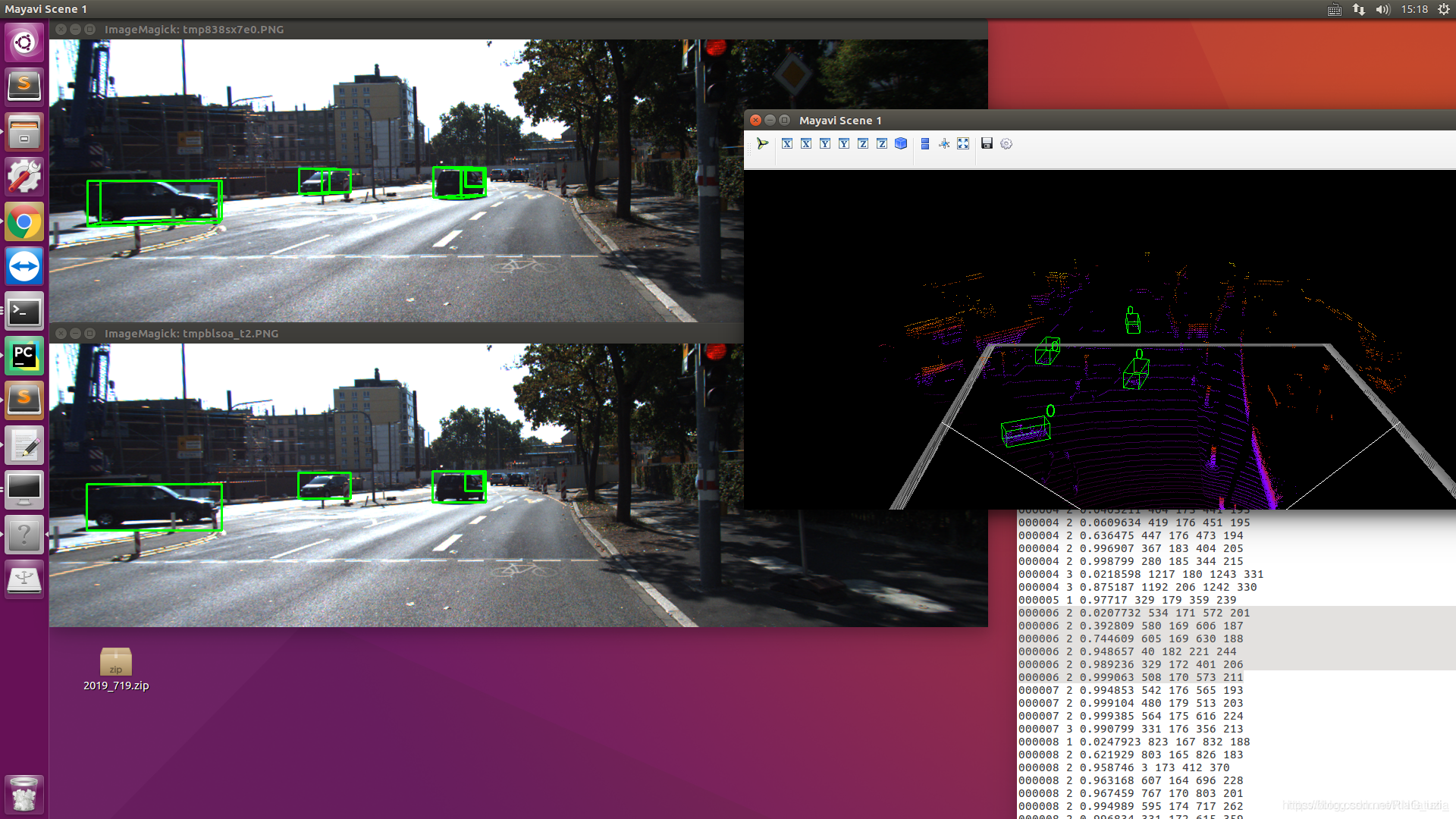
(4) 显示pointRCNN预测值+真值对比
在以上所有命令后面加 -p
例:
python3 kitti_object.py --show_lidar_with_depth --img_fov --const_box --vis --show_image_with_boxes --ind 6 -p
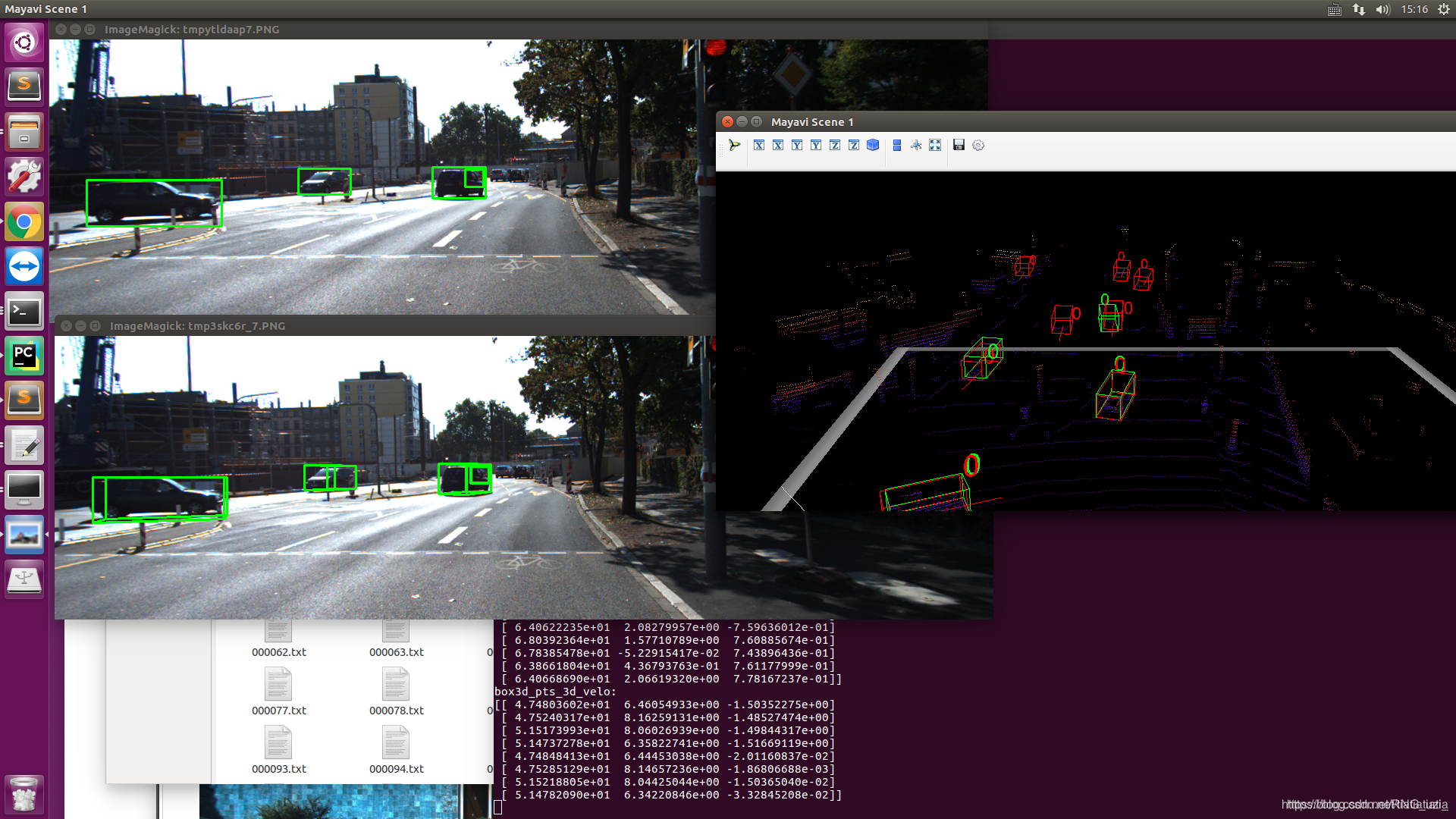
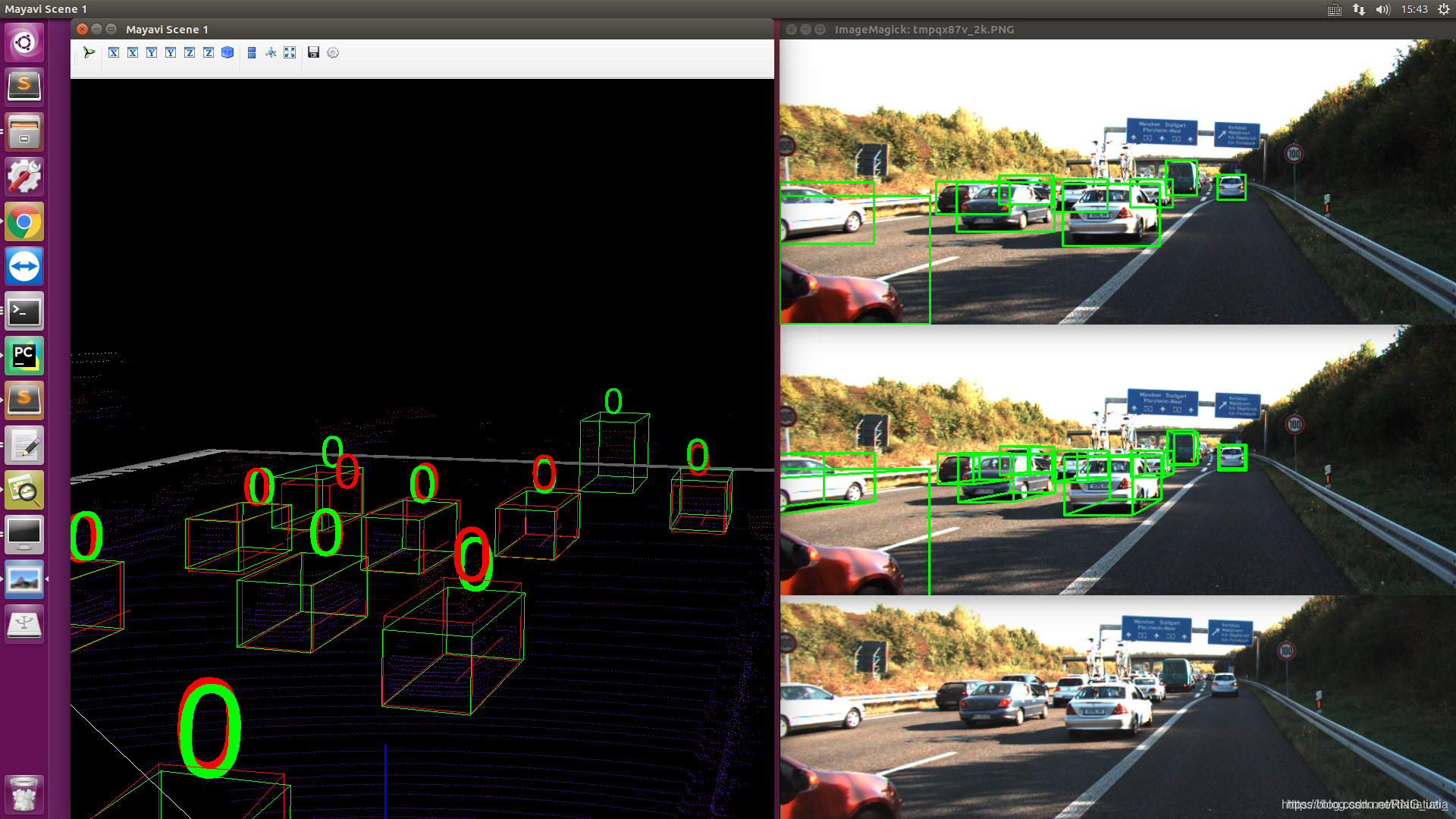
目前有几个疑问:
image中只能显示gt,无法显示预测结果。
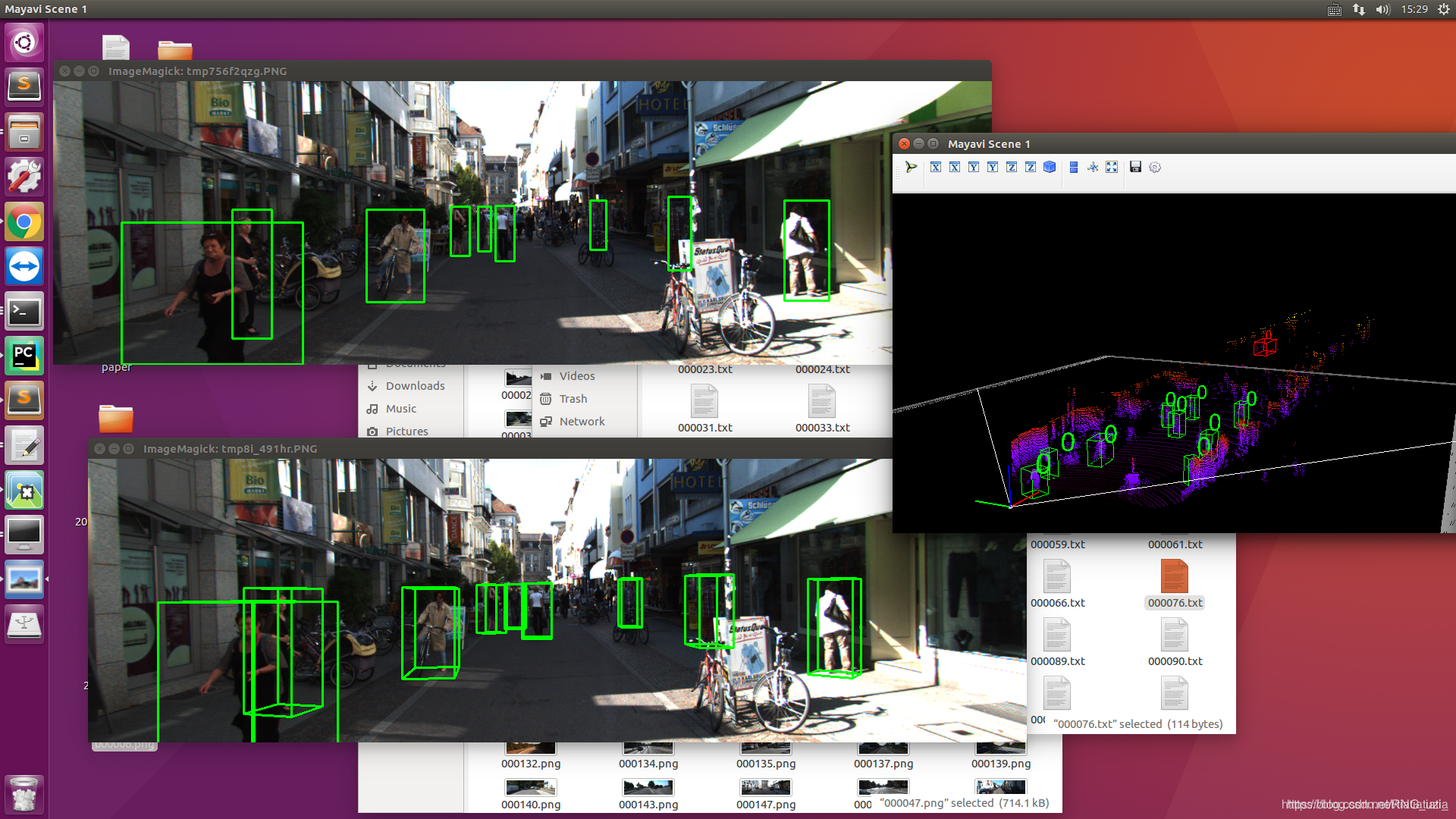
0是啥意思?类别吗,但个别的带人的图上面标号也都是0,如下:
(运行kitti的tracking数据,三维显示数据框里面没有标记出label,只有红色框?)
感谢前辈:https://blog.csdn.net/tiatiatiatia/article/details/97765165















 2984
2984











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









