







文章目录
论文(AV-HuBERT):LEARNING AUDIO-VISUAL SPEECH REPRESENTATION BY MASKED MULTIMODAL CLUSTER PREDICTION
原文地址:AV-HuBERT。本文是在阅读原文时的简要总结和记录。

Abstract
1.本文解决的任务
从语音和其对应的唇部视频中学习帧级(frame-level)Audio-Visual Speech Representation/Hidden Unit,以捕获跨模态相关性,并通过在单一模态输入的任务上微调改善下游lip-reading或ASR任务性能。
2.本文提出的方法
利用self-supervised的框架,通过mask video input,预测和迭代优化(iteratively refine)自动发现的多模态hidden unit(这个过程类似于HuBERT)。
3. 本文得到的结果
将预训练的AV-HuBERT模型在lip-reading和ASR任务上finetune,均取得了最佳结果。
4. 本文的代码和模型地址
https://github.com/facebookresearch/av_hubert
Introduction
1.联合学习Audio-Visual Hidden Unit的动机
- speech production和perception的过程都是multimodal的,audio和visual lip movement之间的联系紧密。
- 已有的语音预训练方法只基于语音一个模态,已有的lip-reading方法依赖大量有标注数据来实现良好的性能。
2.本文贡献:AV-HuBERT
- 通过ResNet-Transformer框架将masked audio和对应的lip images sequence编码为audio-visual features,并根据这个features预测预先定义好的离散cluster assignments序列;
- 预测目标即cluster assignments最初是从基于信号处理的声学特征(如MFCC)中通过KMeans聚类产生的;在训练过程中,cluster assignments还会通过将学到的audio-visual features重新聚类进一步迭代细化。
- AV-HuBERT同时从lip movement和audio中捕获unmasked区域的语言(linguistic)和音素(phonetic)信息到其潜在表示中,然后编码它们的长期时间关系以解决屏蔽预测(masked-prediction)任务。学到的audio-visual features即希望学到的hidden unit。
3. 实验结果
- 将预训练模型在lip-reading任务上(只有visual modality输入)微调,在low-resource的情况下也能获得很好的效果;
- AV-HuBERT和self-training可以互相补充;
- 从AV-HuBERT中获得的multimodal-clusters可以用于预训练HuBERT模型并进一步用于ASR任务。
Proposed Approach
1. Audio HuBERT的简单回顾
在两个步骤中反复切换:feature clustering和masked prediction。
- First Step:利用KMeans对声学帧 A 1 : T \bf{A}_{1:T} A1:T(通常是MFCC)进行聚类,获得帧级assignments z 1 : T a \bf{z}^a_{1:T} z1:Ta;
- Second Step:通过最小化masked prediction loss,预测 ( A 1 : T , z 1 : T a ) (\bf{A}_{1:T}, \bf{z}^a_{1:T}) (A1:T,z1:Ta)对,学习新的feature;
- Iterative Refine:对新学习的feature作聚类,作为下一步预测的cluster assignments。这样做有助于提升cluster质量,从而提升学习到的feature质量。
预测masked frame的cluster assignments的压力迫使模型学习unmasked frame的良好的局部声学表示和潜在特征之间的长期时间依赖性。
2. Single-modal Visual HuBERT
通过使用visual features预测cluster assignments将HuBERT拓展到visual domain。
1). feature clustering
- 输入图片序列 I 1 , T \bf{I}_{1,T} I1,T,首先获得图片的特征 G ( I t ) G(\bf{I}_t) G(It);其中 G G G是visual feature extractor;在初始时, G G G是可以是HoG特征提取器;
- 将图片特征通过KMeans聚类到离散单元序列 z 1 : T i \bf{z}^i_{1:T} z1:Ti,其中 z t i = K M e a n s ( G ( I t ) ) ∈ { 1 , 2 , … , V } z_t^i=KMeans(G(\bf{I}_t))\in\{1,2,\dots,V\} zti=KMeans(G(It))∈{1,2,…,V}, V V V是codebook的大小;
- cluster assignments z 1 : T i \bf{z}^i_{1:T} z1:Ti是模型masked-prediction任务的预测目标;在后续的迭代时,HuBERT模型的中间层用作图片特征提取器 G G G,也即对中间层特征重新聚类获得assignments,再执行masked-prediction任务。
2). masked prediction
- 在执行masked-prediction task时,模型首先利用ResNet将 I 1 , T \bf{I}_{1,T} I1,T编码为中间特征 f 1 : T i \bf{f}^i_{1:T} f1:Ti,再进一步通过一个binary mask M M M获得masked特征 f ~ 1 : T v \widetilde{f}^v_{1:T} f 1:Tv;掩码策略与HuBERT中相同~~(掩码策略很简单,但细节要参考HuBERT和wav2vec2.0的原文或代码,我没有很搞清楚这个learned mask embedding是什么东西)~~ ;
- masked特征 f ~ 1 : T v \widetilde{f}^v_{1:T} f 1:Tv通过transformer编码出上下文特征 e 1 : T \bf{e}_{1:T} e1:T;
- 上下文特征 e 1 : T \bf{e}_{1:T} e1:T再通过线性层和softmax预测cluster assignments;
- CEloss在全部masked region计算,并选择性的以概率
α
\alpha
α在unmasked region上计算,如下式:
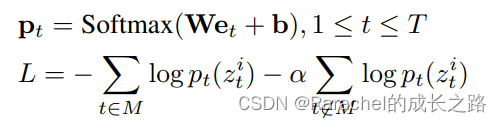
3. Cross-Modal Visual HuBERT
音频特征(如MFCC)或预训练的audio HuBERT与图片特征相比与音素的关系更大。因此,将与visual features对齐的audio features A 1 : T \bf{A}_{1:T} A1:T也加入训练。迭代策略在audio-visual两个encoder之间切换。
1) 具体做法
在每一次迭代中:
- audio encoder E a E^a Ea首先用于生成目标cluster assignments z 1 : T a \bf{z}^a_{1:T} z1:Ta;
- visual encoder E v E^v Ev利用 ( I 1 : T , z 1 : T a ) (\bf{I_{1:T}}, \bf{z}^a_{1:T}) (I1:T,z1:Ta)进行迭代;
- z 1 : T a \bf{z}^a_{1:T} z1:Ta也用于作为新的target训练下一次迭代中的audio encoder E a E^a Ea。
2) 分析
- Cross-Modal Visual HuBERT 可以看作是通过从audio中提取知识来对visual进行建模,其中 z 1 : T a \bf{z}^a_{1:T} z1:Ta表示audio知识。
- 使用masked prediction迫使模型捕捉时间关系,这有助于预测同音音素(即具有相同视觉形状的声音组例如,‘p’-‘b’, ‘f’-‘v’, ‘sh’-‘ch’,它们使用单个图像帧无法区分),这对于下游任务如lip-reading至关重要。
4. Audio-Visual HuBERT
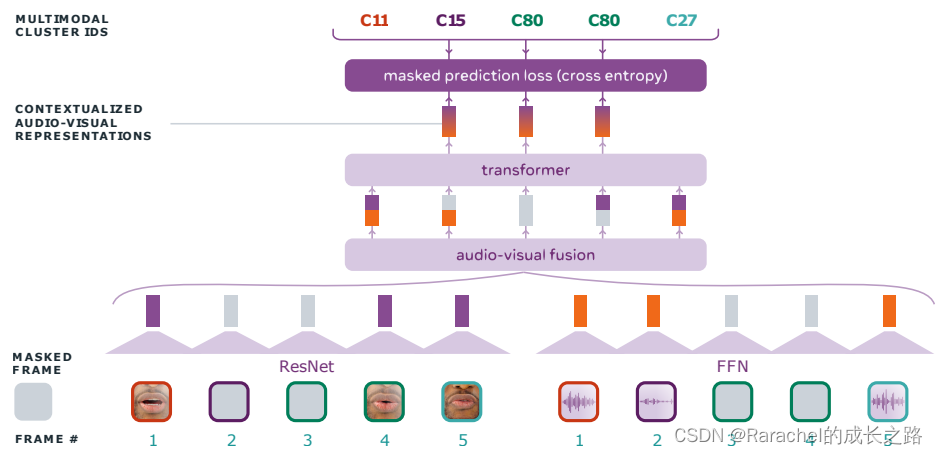
与上述HuBERT相比,有以下4点改进:
1. 同时使用audio-visual input:
- 图像序列和声学特征通过各自的轻量级modality-specific encoder产生中间特征;
- 这些特征t通过拼接进行融合,并馈送到共享的transformer中以进行masked prediction;
- 预测目标是通过聚类 音频特征 或 从先前迭代中生成的中间特征 而生成的。
2. Modality dropout
通常来说,如果同时使用audio-visual输入,模型很容易被audio主导;这一问题在初始cluster是由acoustic features生成时尤为严重。
- 为了解决过于依赖audio stream的这一问题:
- 仅使用一个简单的线性层对acoustic input进行编码,迫使audio encoder学习简单的特征;
- 在将modality encoder提取的特征融合馈送给transformer之前,使用modality dropout,即以一定的概率完全mask掉某一模态的全部特征,如下式
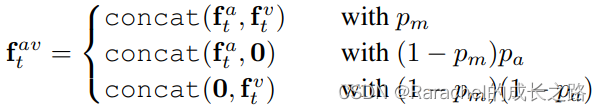
- 注意, modality dropout是在sequence level做的,而不是frame-level,即对某一utterance的所有帧都执行modality dropout;
- 分析
- 帮助AVHuBERT有效处理visual-only, audio-only, or audio-visual input
- 可防止模型忽略visual input
- 解决了后续在lip-reading任务上finetune与pretraining的mismatch问题
3. Audio-Visual Clustering
- 在两种模式上进行pretraining的一个好处是能够生成多模态聚类分配,作为下一次迭代的掩码预测任务的目标标签。
- 与audio/single-modal visual/cross-modal visual HuBERT相比,AV-HuBERT的clustering在第一次迭代后自然是多模态的
- lip movement为audio提供补充信息,结合这两种modality可以为 AV-HuBERT 生成更高质量的cluster assignments。
4. Masking by substitution:针对visual stream而设
- 具体做法:通过用来自同一视频的随机片段进行替换来mask visual input的片段。
- 分析:
1)模型需要首先识别fake trame,然后推断属于original frame的cluster assignments;
2) 由于“填充”片段来自真实视频片段并且在时间上是平滑的,因此与使用vanilla mask或用非连续帧替换相比,假片段检测子任务变得不那么琐碎 - audio和visual stream的mask是独立进行的;
- 由于audio mask策略更简单,因此从masked audio stream中推断cluster assignments更简单,因此要为audio masking设置更高的概率;但不能为visual masking设置更高的概率,因为visual masking已经很复杂了,从masked visual stream中推断cluster assignments已经很难,如果再设置更高的mask概率会损害模型学习有意义特征的能力
Audio-Visual HuBERT training loss:
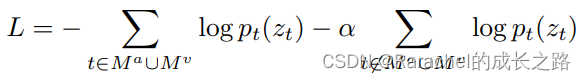
M
a
,
M
v
M^a, M^v
Ma,Mv分布表示audio和visual stream中被mask掉的帧。
5. Fine-tuning
在lip-reading任务上利用CTC或S2S Loss进行finetune。
Experiment
1. 实验设置
- 数据集
- LRS3: 433h 带文本的英语视频。
- VoxCeleb2: 只用了其中1326h的unlabeled英语视频。
- audio & visual preprocessing & encoder
- preprocessing
visual:lip ROI; audio: log filterbank energy feature - encoder
visual: modified ResNet-18; audio: 1 linear projection layer
- preprocessing
- model configuration
- BASE with 12 transformer blocks and LARGE with 24 transformer blocks. transformer细节结构设置参考原文
- 只在masked region计算loss,即 α = 0 \alpha=0 α=0
- pre-training时一共做了5次feature clustering和masked prediction的迭代
- Self-Training
使用finetune的HuBERT为未标记数据生成伪标签,并结合伪标记视频和原始标记视频对pre-trained AV-HuBERT模型进行finetune。
2. 主要结果(在lip-reading任务上finetune的结果)
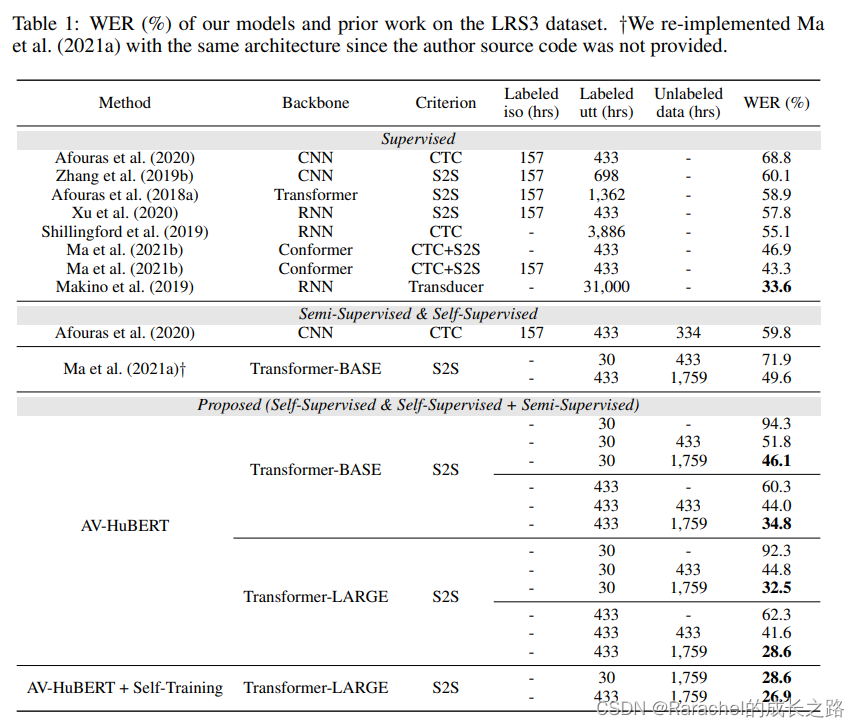
- 使用1,759 小时未标记数据进行预训练,仅使用30小时标记数据进行finetune,AV-HuBERT-LARGE优于所有先前的唇读模型
- 对 LRS3 的整个训练集进行finetune进一步降低了 WER
- 结合self-training获得了一个新的 SOTA 结果,也表明 AV-HuBERT 和self-training是相辅相成的。

















 614
614

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









