







1.前言
词法分析是自然语言处理的基本工具,主要包括分词、词性标注和实体识别等功能。目前各类词法分析工具大行其道,有免费开源的,也有商业收费的;有高校研发的,也有企业开发的;有支持Java的,也有支持Python的,甚至还有支持安卓平台的。不久前百度带来了LAC2.0版本,据说做了很多改进,我们通过实战来体验一下(百度打钱!!!)。
2.百度LAC2.0介绍
根据百度官方消息,LAC全称Lexical Analysis of Chinese,是百度NLP(自然语言处理部)研发的一款词法分析工具,可实现中文分词、词性标注、专名识别等功能。
百度方面宣称,LAC在分词、词性、专名识别的整体准确率超过90%,以专名识别为例,其效果要比同类词法分析工具提升10%以上。
目前,百度已经发布了LAC2.0版本,之前的1.0版本我也写过一篇博文加以探讨,彼时的1.0版本还是融合在paddlehub中的一个模型,详见利用百度超大规模预训练模型进行分词 一文。在2.0版本中LAC已经成为了独立模块,可以直接通过pip 安装。
pip install LAC
使用起来也非常方便
from LAC import LAC
lac = LAC()
lac.run("雷帅于2020年6月24日毕业于上海财经大学信息管理与工程学院计算机科学与技术系")
结果如下
[['雷帅', '于', '2020年6月24日', '毕业', '于', '上海财经大学信息管理与工程学院', '计算机科学与技术系'],
['PER', 'p', 'TIME', 'v', 'p', 'ORG', 'nz']]
结合官方给出的对照表进行转换,可以得到如下词性
[['雷帅', '于', '2020年6月24日', '毕业', '于', '上海财经大学信息管理与工程学院', '计算机科学与技术系'],
['人名', '介词', '时间', '普通动词', '介词', '机构名', '其他专名']]
3.与其他分词工具速度对比
在本文中,我们主要选取了结巴分词、foolnltk和THULAC三个工具来和百度的LAC2.0进行比较。
| 工具 | 机构/作者 | 算法/模型 |
|---|---|---|
| LAC2.0 | 百度 | BiGRU-CRF |
| jieba | Sun Junyi | HMM等 |
| foolnltk | 郑午 | BiLSTM |
| thulac | thu | 不知道呀 |
需要注意的是,foolnltk对TensorFlow的版本有要求,推荐使用TensorFlow==1.14.0
我大致用自己的电脑各跑几百条数据看下速度,这里我从微博上拿到了700+条,用各个工具进行分词标注词性。懒得多次测试了,可能有偶然性,仅供参考。
| 工具 | 启动耗时(秒) | 运行耗时(秒) |
|---|---|---|
| LAC2.0 | 5 | 11.9 |
| jieba | 2.71 | 20.4 |
| foolnltk | 18.3 | 45 |
| THULAC | 5 | 261 |
可以看到LAC 2.0在处理时的速度非常快(百度打钱啊!),而THULAC的数据比较反常,也可能是我测试的问题(以后可以分析一下这个问题)。实际上THULAC还有fast_cut快速分词功能,但是现实找不到so文件,懒得解决了,能用就行。
在本段落中我们仅比较了不同工具之间的启动速度和处理速度。至于效果,有很多开源的测试集,很容易找到这些工具的测试结果。我就不再啰嗦啦。
然而仅仅看测试结果,而不去实际应用,就会有准确而不具体的问题。为了更直观的比较四种工具的效果,我们以词云图为例,观察通过四种工具对同一文章生成的词云图,比较其分词和标注的效果。
4.生成词云图
生成词云图非常简单,只需要用到第三方工具WordCloud即可,可以通过pip 安装
pip install wordcloud
然后生成词云对象并设置参数
wc = WordCloud(
background_color="white",#背景色
max_words=500,
min_font_size=15,
max_font_size=100,
width=540,
height=384,
font_path="Alibaba-PuHuiTi-Light.ttf"#中文字体
)
需要特别注意的是,如果要生成中文词云图,必须手动指定字体路径(相对)。这里我们选用阿里巴巴普惠体,主要是免费,用得起,良心过得去。
另外还需注意,如果是在某些没有GUI的linux服务器上生成词云图,还需要安装PyQt4,否则会报错。我总以为PyQt4是一个python的包,但其实不是的,而是一个系统工具,通过yum安装即可。
yum install PyQt4
然后就可以生成词云图啦
wc.generate(texts)
这里的texts是一个以空格为分隔符的词表字符串,可以通过分词工具获得。
5.效果展示
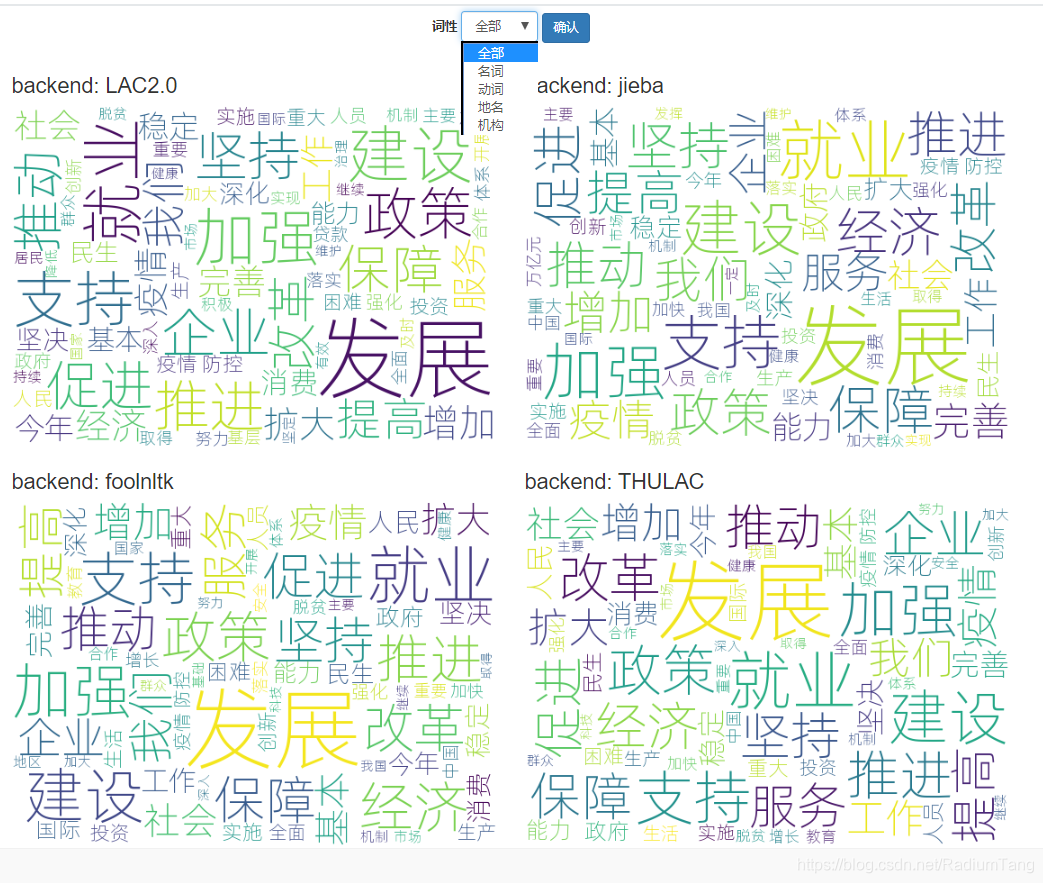
这里我们选用的是 2020年政府工作报告来生成词云图。并同时在页面上展示4个工具分词生成的词云图。并支持查看单一词性词云图。
链接为fgb2019.top:5001/index
也可以扫描二维码

通过词云图我们可以直观的看到不同的工具的区别。
对于名词和动词,四款工具分词都很不错,看不出明显的差别,而对于地名和机构名,差异比较明显。LAC2.0和结巴明显能识别出较多机构名,其他两个工具稍稍逊色。地名方面LAC2.0表现也不错。

地名方面,LAC2.0和THULAC表现较好,而jieba和foolnltk明显出现较多错误(见红框标注)
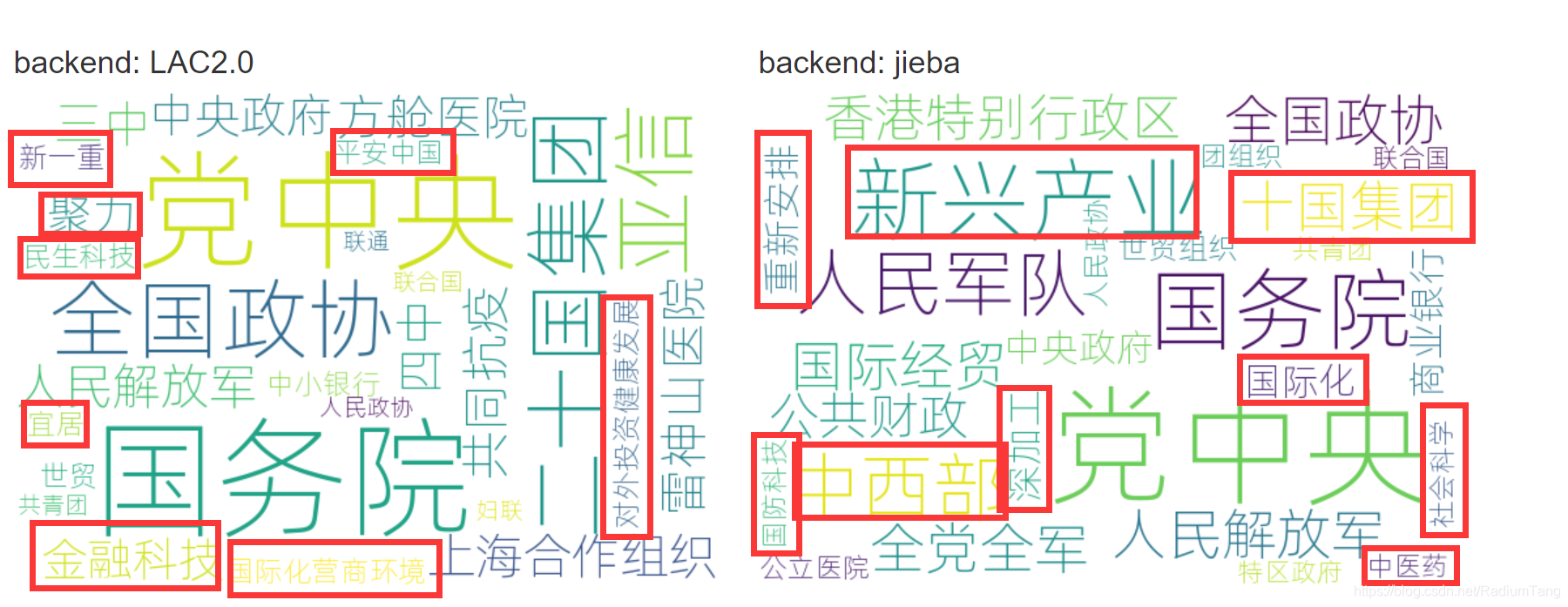
而机构方面,foolnltk和THULAC几乎仅能识别出党中央、国务院等机构,LAC2.0和jieba识别出了较多机构,也各有一些错误。但就识别正确的词而言,LAC2.0效果较好,比如LAC2.0能够识别出二十国集团,而jieba认为是“十国集团”
6.总结
总的来说,百度的LAC2.0在各方面性能上算得上优秀,尤其是在地名和机构名的识别上。实际上LAC2.0对人名识别也比较准确,本文没有具体测试。
//本文也是受邀撰写,感谢百度方面的邀请,但是!没收钱!!!!!!!
到这里,细心的读者应该已经发现了,我用的端口是5001端口,这说明我很可能用的是Flask框架,同时5000端口被占用。如果这样想,那你可能在第五层,但其实我就是更喜欢5001,5000上什么也没有,所以我也只是在第二层。














 4095
4095











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









