






什么是数据降维
在现实世界中,很多数据是多余且耦合的,即数据之间存在相关性。
这造成了一些数据是无用的,对我的实验的结果是没有帮助的,反而会拉低我们实验的结果。
例如:高维数据的各个维度之间,存在着数据相关,而这些高相关的维度,通俗地讲,就是比较像的维度。
就好比一家公司只招收一 名会计,那么两名会计来应聘,就会录取一名,而淘汰一名,因为这两个人的技能太相似了。所以对于高相关的维度信息,我们选择保留其中一个维度即可,因为保留的这个维度,就可以近似代表与其高相关的维度信息。
因此,“降维” 顾名思义,其目的就是降低数据的维度。
很明显的,降低维度会损失原数据的一些信息,如果是损失冗余信息,倒也无伤大雅,但如果是损失了关键信息,那势必会对之后的工作产生严重的影响。
数据的好坏决定着模型的训练结果。
为什么要降维
目前很多实验所需要的数据均为高维数据,也就是多列变量值决定目标值。
高维数据有一定的优点,数据维度高,则其所包含的信息量就大,则可供决策的依据就较多。
但是数据不是维度越高越好,因为还需要考虑实际的计算能力,高维度数据的缺点,消耗计算资源,计算时间大,同时使得冗余且耦合的数据对实验结果造成影响,甚至造成“维度灾难”。
所以为了适应需要,获取数据的本质特征,降维算法随之诞生。
降维的目的
减少特征属性的个数,剔除不相关或冗余特征,减少特征个数,提高模型精确度,减少运行时,确保特征属性之间是相互独立的。
降维的目的总结几句话:
克服维数灾难,获取本质特征,节省存储空间,去除无用数据,实现数据可视化。
十种降维方法
数据降维分为特征选择和特征提取两类。
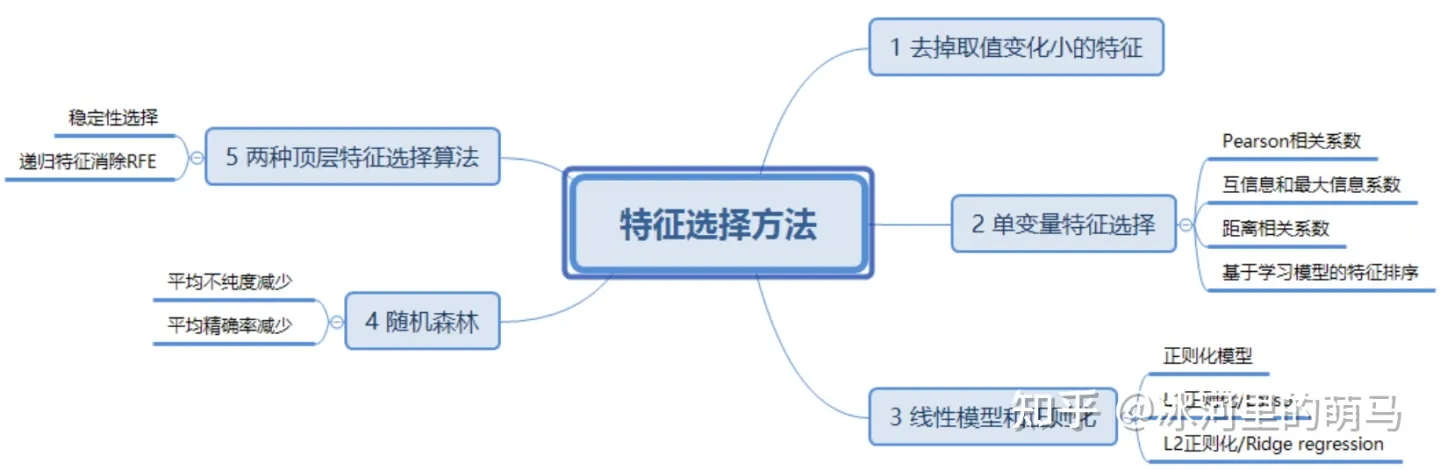
低方差滤波
如果我们有一个数据集,其中某列的数值基本一致,也就是它的方差非常低,那么这个变量还有价值吗?和上一种方法的思路一致,我们通常认为低方差变量携带的信息量也很少,所以可以把它直接删除。
该方法假设数据列变化非常小的列包含的信息量少。因此,所有的数据列方差小的列被移除。需要注意的一点是:方差与数据范围相关的,因此在采用该方法前需要对数据做归一化处理。
放到实践中,就是先计算所有变量的方差大小,然后删去其中最小的几个。需要注意的一点是:方差与数据范围相关的,因此在采用该方法前需要对数据做归一化处理。
步骤如下:
我们先估算缺失值
检查缺失值是否已经被填充
再计算所有数值变量的方差
删除方差非常小的值即可
高相关滤波
高相关滤波认为当两列数据变化趋势相似时,它们包含的信息也显示。这样,使用相似列中的一列就可以满足机器学习模型。对于数值列之间的相似性通过计算相关系数来表示,对于名词类列的相关系数可以通过计算皮尔逊卡方值来表示。相关系数大于某个阈值的两列只保留一列。同样要注意的是:相关系数对范围敏感,所以在计算之前也需要对数据进行归一化处理。
如果两个变量之间是高度相关的,这意味着它们具有相似的趋势并且可能携带类似的信息。同理,这类变量的存在会降低某些模型的性能(例如线性和逻辑回归模型)。为了解决这个问题,我们可以计算独立数值变量之间的相关性,如果相关系数超过某个阈值,就删除其中一个变量。
作为一般准则,我们应该保留那些与目标变量显示相当或高相关性的变量。
步骤如下:
首先,删除因变量,并将剩余的变量保存在新的数据列中
计算两两数据之间关联性
如果一对变量之间的相关性大于0.5-0.6,则为高相关变量
选择其中一种变量删除
随机森林
组合决策树通常又被成为随机森林,它在进行特征选择与构建有效的分类器时非常有用。一种常用的降维方法是对目标属性产生许多巨大的树,然后根据对每个属性的统计结果找到信息量最大的特征子集。例如,我们能够对一个非常巨大的数据集生成非常层次非常浅的树,每颗树只训练一小部分属性。如果一个属性经常成为最佳分裂属性,那么它很有可能是需要保留的信息特征。对随机森林数据属性的统计评分会向我们揭示与其它属性相比,哪个属性才是预测能力最好的属性。
步骤如下:
在开始降维前,我们先把数据转换成数字格式,因为随机森林只接受数字输入
我们可以把数据序号这列删除,这个不影响结果
拟合模型后,根据特征的重要性绘制成图(Python实现)
我们可以手动选择最顶层的特征来减少数据集中的维度
如果你用的是sklearn,可以直接使用SelectFromModel,它根据权重的重要性选择特征
反向特征消除
在该方法中,所有分类算法先用 n 个特征进行训练。每次降维操作,采用 n-1 个特征对分类器训练 n 次,得到新的 n 个分类器。将新分类器中错分率变化最小的分类器所用的 n-1 维特征作为降维后的特征集。不断的对该过程进行迭代,即可得到降维后的结果。第 k 次迭代过程中得到的是 n-k 维特征分类器。通过选择最大的错误容忍率,我们可以得到在选择分类器上达到指定分类性能最小需要多少个特征。
步骤如下:
先获取数据集中的全部n个变量,然后用它们训练一个模型
计算模型的性能
在删除每个变量(n次)后计算模型的性能,即我们每次都去掉一个变量,用剩余的n-1个变量训练模型
确定对模型性能影响最小的变量,把它删除
重复此过程,直到不再能删除任何变量
前向特征选择
前向特征构建是反向特征消除的反过程。在前向特征过程中,我们从 1 个特征开始,每次训练添加一个让分类器性能提升最大的特征。前向特征构造和反向特征消除都十分耗时。它们通常用于输入维数已经相对较低的数据集。
步骤如下:
选择一个特征,用每个特征训练模型n次,得到n个模型
选择模型性能最佳的变量作为初始变量
每次添加一个变量继续训练,重复上一过程,最后保留性能提升最大的变量
一直添加,一直筛选,直到模型性能不再有明显提高
缺失值比率
当获得一个新的数据集,在建立模型之前我们需要分析数据,查看数据信息。当我们发现数据中有缺失值时,我们就要分析这个变量产生缺失值的原因以便于我们补齐还是丢弃这个变量。通常我们会设置一个阈值,如果缺失值比率超过阈值,则变量中有用信息较少,我们就丢弃这个变量;如果缺失值比率小于阈值,则保留这个变量,并用一些方法去弥补缺失值;
该方法的是基于包含太多缺失值的数据列包含有用信息的可能性较少。因此,可以将数据列缺失值大于某个阈值的列去掉。阈值越高,降维方法更为积极,即降维越少。
步骤如下:
检查每个变量中缺失值的占比
缺失值很少。我们设阈值为20%
删除高于阈值的列
主成分分析(PCA)
主成分分析方法,是一种使用最广泛的数据降维算法。PCA的主要思想是将n维特征映射到k维上,这k维是全新的正交特征也被称为主成分,是在原有n维特征的基础上重新构造出来的k维特征。
PCA的工作就是从原始的空间中顺序地找一组相互正交的坐标轴,新的坐标轴的选择与数据本身是密切相关的。其中,第一个新坐标轴选择是原始数据中方差最大的方向,第二个新坐标轴选取是与第一个坐标轴正交的平面中使得方差最大的,第三个轴是与第1,2个轴正交的平面中方差最大的。依次类推,可以得到n个这样的坐标轴。通过这种方式获得的新的坐标轴,我们发现,大部分方差都包含在前面k个坐标轴中,后面的坐标轴所含的方差几乎为0。
于是,我们可以忽略余下的坐标轴,只保留前面k个含有绝大部分方差的坐标轴。事实上,这相当于只保留包含绝大部分方差的维度特征,而忽略包含方差几乎为0的特征维度,实现对数据特征的降维处理。
步骤如下:
去除平均值
计算协方差矩阵
计算协方差矩阵的特征值和特征向量
将特征值排序
保留前N个最大的特征值对应的特征向量
将原始特征转换到上面得到的N个特征向量构建的新空间中(最后两步,实现了特征压缩)
独立分量分析(ICA)
独立分量分析基于信息理论,是最广泛使用的降维技术之一。PCA 和 ICA之间的主要区别在于,PCA寻找不相关的因素,而 ICA 寻找独立因素。
如果两个变量不相关,它们之间就没有线性关系。如果它们是独立的,它们就不依赖于其他变量。例如,一个人的年龄和他吃了什么/看了什么电视无关。
该算法假设给定变量是一些未知潜在变量的线性混合。它还假设这些潜在变量是相互独立的,即它们不依赖于其他变量,因此它们被称为观察数据的独立分量。
步骤如下:
对X零均值处理
消除原始各道数据间二阶相关,以后只需要考虑高阶矩量(因为独立时各阶互累积量为0),使很多运算过程简化。
寻求解混矩阵U,使Y=UZ,Y各道数据尽可能独立(独立判据函数G)。
由于独立判据函数G的不同,以及步骤不同,有不同的独立分量分析法。
输入球化数据z,经过正交阵U处理,输出Y=Uz
输入球化数据z,经过正交阵某一行向量处理(投影)
提取出某一独立分量
将此分量除去,按次序依次提取下去,得到所有的值
得到独立的基向量U
局部线性嵌入(LLE)
LLE属于流形学习的一种。因此我们首先看看什么是流形学习。流形学习是一大类基于流形的框架。数学意义上的流形比较抽象,不过我们可以认为LLE中的流形是一个不闭合的曲面。这个流形曲面有数据分布比较均匀,且比较稠密的特征,有点像流水的味道。基于流行的降维算法就是将流形从高维到低维的降维过程,在降维的过程中我们希望流形在高维的一些特征可以得到保留。
一个形象的流形降维过程如下图。我们有一块卷起来的布,我们希望将其展开到一个二维平面,我们希望展开后的布能够在局部保持布结构的特征,其实也就是将其展开的过程,就想两个人将其拉开一样。
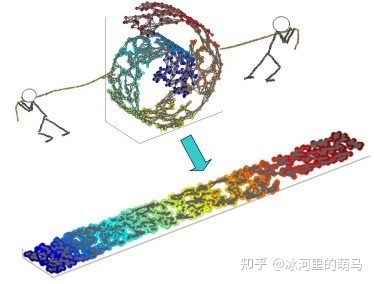
实现步骤:
(1)找到数据点的k个近邻点
(2)由每个近邻点构建改样本点的局部重建矩阵
(3)由局部重建矩阵和近邻点计算重建后的样本点
t-随机邻近嵌入(t-SNE)
t-随机邻近嵌入,它是一种嵌入模型,能够将高维空间中的数据映射到低维空间中,并保留数据集的局部特性,当我们想对高维数据集进行分类,但又不清楚这个数据集有没有很好的可分性(同类之间间隔小、异类之间间隔大)时,可以通过t-SNE将数据投影到2维或3维空间中观察一下:如果在低维空间中具有可分性,则数据是可分的;如果在低维空间中不可分,则可能是因为数据集本身不可分,或者数据集中的数据不适合投影到低维空间。
t-SNE将数据点之间的相似度转化为条件概率,原始空间中数据点的相似度由高斯联合分布表示,嵌入空间中数据点的相似度由学生t分布表示。通过原始空间和嵌入空间的联合概率分布的KL散度(用于评估两个分布的相似度的指标,经常用于评估机器学习模型的好坏)来评估嵌入效果的好坏,即将有关KL散度的函数作为损失函数(loss function),通过梯度下降算法最小化损失函数,最终获得收敛结果。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









