






最近花了不少经历在搞 AI 相关的内容,经过一系列的尝试,也算是选定了一个方向,也是现在比较成熟的地方 文档搜索。
架构设计
首先我们来看看做一个文档搜索我们要做什么,和平常的文档搜索有什么不同。
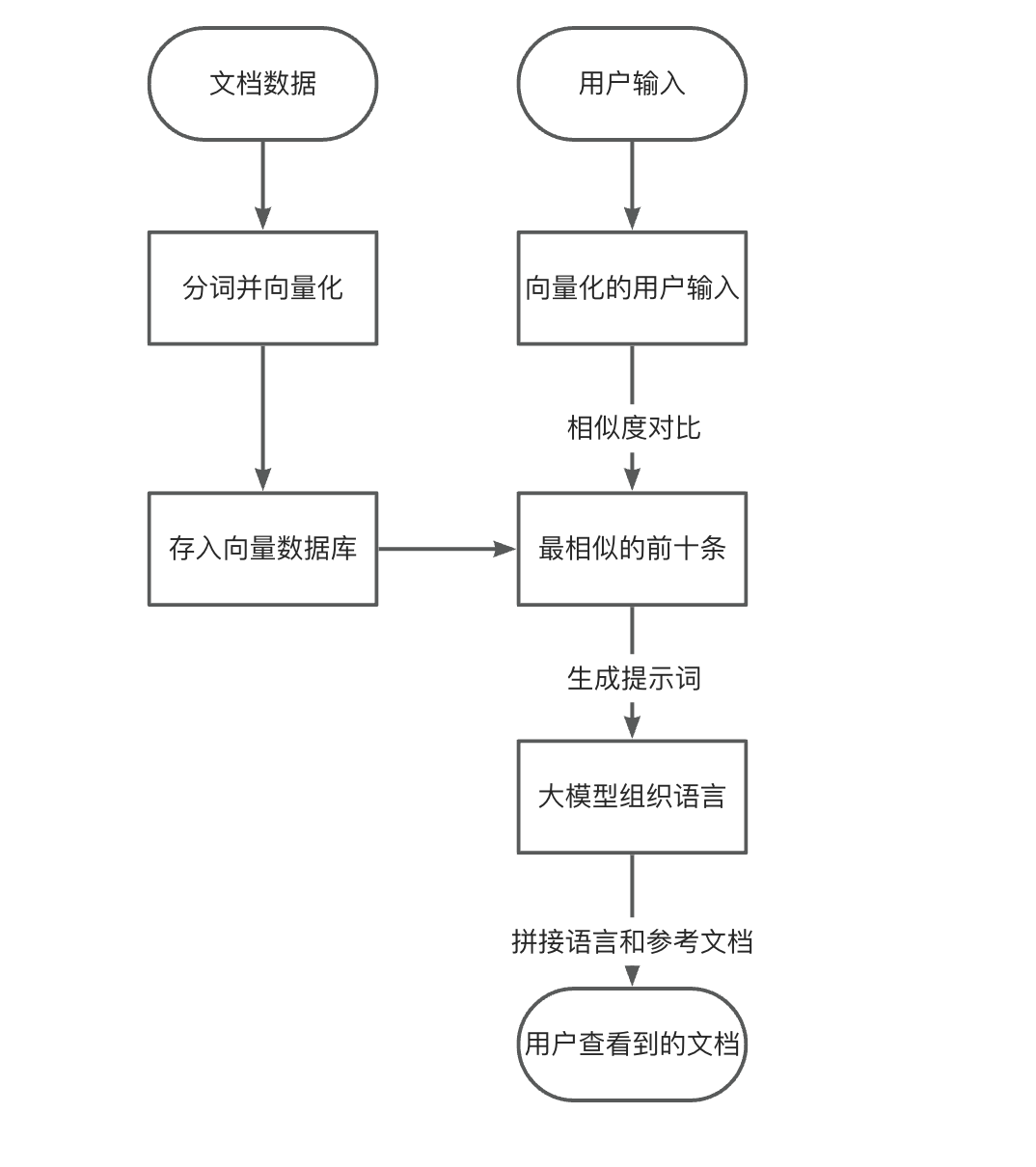 可以看到这个流程和原来的流程其实区别不大,唯一不同的是文档数据和用户的输入都需要一步向量化。那么为什么要向量化呢?
可以看到这个流程和原来的流程其实区别不大,唯一不同的是文档数据和用户的输入都需要一步向量化。那么为什么要向量化呢?
embedding
向量化即 embedding ,可以翻译为的 "向量映射", 抛开背后的技术,向量化的主要目标是为了找同义词。越“相似”的内容,向量化后距离越小。比如 喜悦 欢喜 愿意 快活 愉快 欢乐 快乐 忻悦 兴奋 夷愉 高兴 乐意 得意 雀跃 欢快 欢跃 欣喜 痛快 和 开心 向量化之后的距离应该很小。 也就是用户输入 开心 ,那么查询的结果就应该查出 喜悦 欢喜 愿意 快活 愉快 欢乐 快乐 忻悦 兴奋 夷愉 高兴 乐意 得意 雀跃 欢快 欢跃 欣喜 痛快。
那么 embedding 的效果就决定了最后的查询效果。我们可以在 huggingface 排行榜中看看具体的效果。
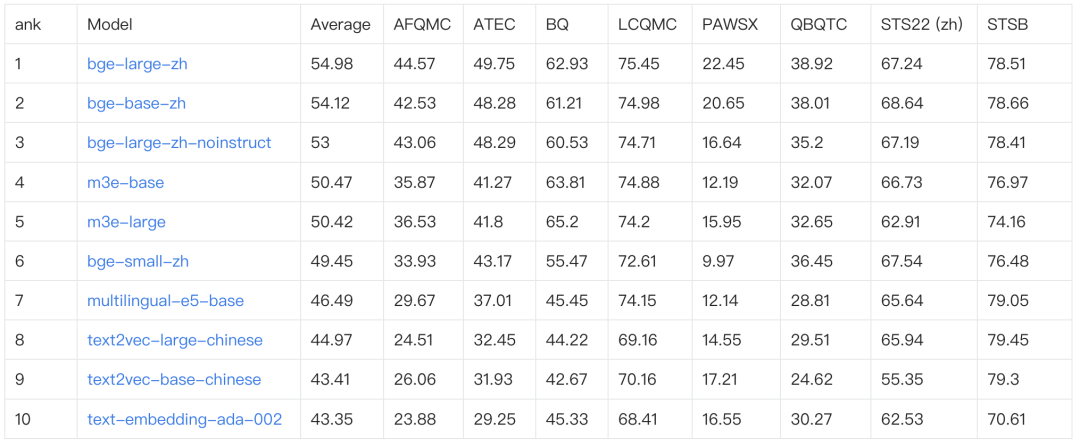 huggingface.co我选了一下排名第一的中文分词,试了试效果。这就是 embedding 的效果,远比我们的文本搜所要效果好。
huggingface.co我选了一下排名第一的中文分词,试了试效果。这就是 embedding 的效果,远比我们的文本搜所要效果好。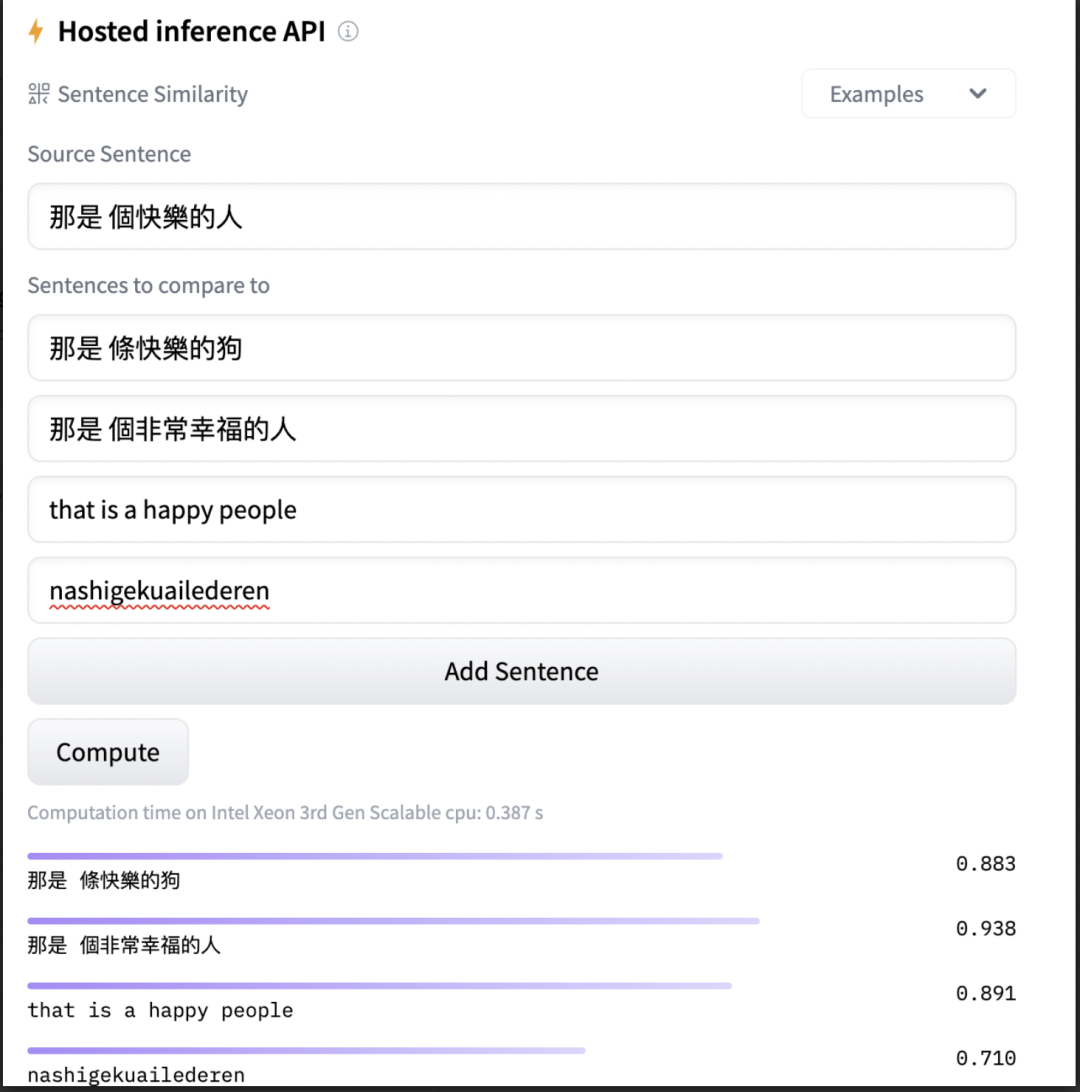 现在的训练集没怎么训练拼音的,拼音效果很差。
现在的训练集没怎么训练拼音的,拼音效果很差。
向量数据库
上面了解了一下 embedding 的效果,在实际的使用中我们不太可能实时的进行 embedding ,尤其是对巨量的数据来说,embedding 可能要好几个小时,为了用户体验我们一般会预先 embedding,embedding 的结果是一些向量,为了方便查找我们会使用专门的向量数据库来进行向量的管理。
向量数据库 现在已经非常成熟,我们可以随意选一下,很多老牌数据库也可以通过插件来实现向量数据库。
 如果自己想试试可以 Chroma 来试试效果,用起来和 nosql 数据库差不多。chroma-core
如果自己想试试可以 Chroma 来试试效果,用起来和 nosql 数据库差不多。chroma-core
python 实现
各种路径都走通了,我们用 python 来实现一下这些功能,这里我们故意没用 langchain,用了 langchain 可以快速实现,但是每一步之间就不能做自由定制了。
from FlagEmbedding import FlagModel
import chromadb
import json
# 读取JSON文件
with open("./src/app/pro.json", "r", encoding="utf-8") as file:
json_data = file.read()
# 解析JSON数据
json_dict = json.loads(json_data)
client = chromadb.Client()
model = FlagModel(
"BAAI/bge-base-zh", query_instruction_for_retrieval="为这个句子生成表示以用于检索相关文章:"
)
collection = client.create_collection("pro-table")
index = 0
for item in json_dict:
collection.add(
// 默认的向量只是个二维的效果不是很好,这里使用第三方的
embeddings=[model.encode(item["text"]).tolist()],
documents=[item["text"]],
metadatas=[item], # filter on these!
ids=[str(index)], # unique for each doc
)
index = index + 1
QUERY = "如何使用 ProTable?"
results = collection.query(query_embeddings=model.encode(QUERY).tolist(), n_results=2)
print(results)执行之后搜到了两条数据。

纯前端实现
用 python 实现效果挺好的,但是对我们前端来说我们有变成了调接口的人和 AI 没有任何关系,而且 embedding 和 向量数据库都需要巨大的服务器资源,如果能搬到前段实现,性能消耗也能减少很多的。根据上面的架构设计,其实只有三个地方需要大模型,最后一步可以做成列表就不需要 大模型了,所以我们找到能在浏览器中跑的 embedding 和 向量数据库就能试下纯前端。 简单 google 了一下,发现这两个东西还真的有浏览器端实现的,果不其然用了 WASM,这里我们使用了
● WebAI https://github.com/visheratin/web-ai
● Voy https://github.com/tantaraio/voy
我这里简单的写了个代码
import { TextModel } from '@visheratin/web-ai/text';
// Create text embeddings
console.time('model-load');
const model = await (await TextModel.create('gtr-t5-quant')).model;
console.timeEnd('model-load');
console.time('token processed');
const processed = (await Promise.all(
proJson
.slice(0, 10)
.map(async (q) => {
try {
// @ts-ignore
return (await model.process(q.text)) as {
result: number[];
};
} catch (error) {
console.log(q.text);
return '';
}
})
.filter(Boolean)
)) as {
result: number[];
}[];
console.timeEnd('token processed');
// Index embeddings with voy
const data = processed.map(({ result }, i) => ({
id: String(i),
title: proJson[i].text,
url: `/path/${i}`,
embeddings: result,
}));
console.time('Voy insert');
const resource = { embeddings: data };
const { Voy } = await import('voy-search');
const index = new Voy(resource);
console.timeEnd('Voy insert');
console.time('query Voy');
const query = '如何使用 ProTable?';
// Perform similarity search for a query embeddings
// @ts-ignore
const q = (await model.process(query)) as {
result: Float32Array;
};
const result = index.search(q.result, 2);
console.timeEnd('query Voy');
// Display search result
result.neighbors.forEach((result) => {
console.log(`✨ voy similarity search result: "${result.url}"`, result.id);
console.log(result);
});这里速度有点慢,尤其是的文档的向量化,如果要达到可用,要先预热一下,存在用户的本地的。或者在文档发布的时候直接生成,存到一个静态 json 中。
model-load: 10266.1708984375 ms
token processed: 91146.5810546875 ms
Voy insert: 52.3447265625 ms
query Voy: 81.072021484375 ms效果对比
测试代码
输入数据
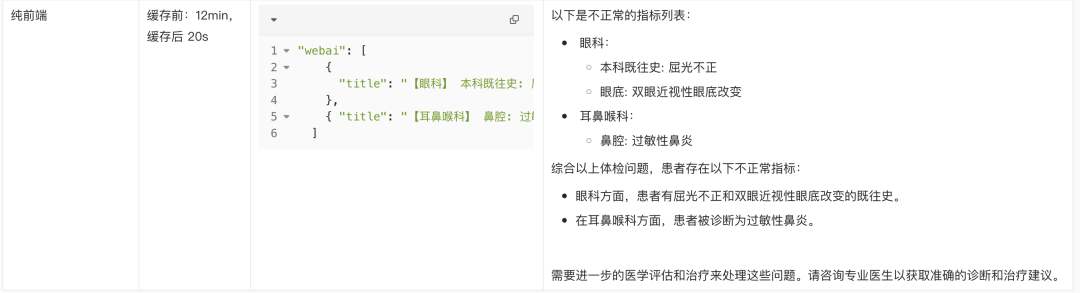
【一般检查】 体重指数: 26.98 ↑18.5-23.9
【外科】 本科既往史: T161980417 无殊
【眼科】 本科既往史: 屈光不正 眼底:双眼近视性眼底改变
【耳鼻喉科】 鼻腔: 过敏性鼻炎
【检验结果】 尿酸: 483 μmol/L ↑ 208-428
甘油三酯: 1.82 mmol/L ↑ 0.00-1.70
【B 超结果】 膀胱、前列腺 B 超: 前列腺超声检查未见明显异常
肝胆脾胰双肾 B 超(空腹): 轻度脂肪肝
甲状腺 B 超: 双侧甲状腺未见明显异常 心电图: 窦性心动过缓 (53 次/分) 体检小结依据 体重指数: 26.98 ↑18.5-23.9 既往史: 屈光不正 眼底: 双眼近视性眼底改变鼻腔: 过敏性鼻炎尿酸: 483 μmol/L ↑ 208-428
甘油三酯: 1.82 mmol/L ↑ 0.00-1.70 B 超: 轻度脂肪肝 心电图: 窦性心动过缓 (53 次/分)
【超重】 我国成人体重指数正常范围为 18.5-23.9; 24-27.9 为超重; 超过 28 为肥胖。超重的原因有摄入过多、消耗较少、多食少动 ,还与遗传因素和脂肪代谢异常有关。肥胖人群会增加心脑血 管疾病、动脉粥样硬化、高血压、高血脂、高血糖等疾病风险 ,所以应积极控制体重,建议: 1. 规律饮食、控制进食速度。2. 减少膳食热量,控制碳水化合物、食用油和脂肪、精白米,近视眼底改变过敏性鼻炎尿酸增高甘油三脂(TG)增高、肥肉等的摄入。3. 减重,科学有氧运动,每周 150 分钟,每周 3-5 天中等强度以 上运动,适当增加对抗性运动。 4.必要时接收专业减重教育与运动指导。
【双眼近视眼底改变】 1、注意用眼卫生,常做眼保健操。 2、定期检查视力,采光要充足,阅读距离保持 30-35 厘米。 3、积极锻炼身体,躺着、乘车、走路均不要看书。
【过敏性鼻炎】 1、防止接触过敏原,如花粉、皮毛、尘埃、冷气等。 2、查过敏原。 3、增强体质。 4、耳鼻喉科随诊。
【尿酸增高】 尿酸是体内嘌呤代谢异常所致的终产物,易在受寒、劳累、饮 酒、高蛋白、高嘌呤饮食而诱发痛风,建议: 1. 改善生活方式: 坚持运动和控制体重,每日中等强度运动 30 分钟以上。2.调节和改善饮食结构: 避免偏食,低脂、低糖、低蛋白清淡 饮食,严格控制高嘌呤(内脏、海鲜)等食物摄入;多饮水。3.有烟酒嗜好者戒烟限酒,尤其禁啤酒和白酒。 4.结合临床,定期复查,如有不适,请内科就诊。
【甘油三脂(TG)增高】 高脂血症包括高胆固醇血症、高甘油三酯血症、低密度胆固醇 增高,和/或兼有的混合型高脂血症。高脂血症是动脉粥样硬化 和心脑血管疾病发生的主要原因,也是代谢综合征的重要表现 之一。因此,调整血脂水平可预防动脉粥样硬化,明显减少心 血管疾病的发生,建议: 1. 低盐低脂饮食,多进食蔬菜水果。 2.有氧运动: 直到出汗和呼吸加深但无明显喘气。建议每周 3-5 天,每周 150 分钟,如: 慢跑、游泳、羽毛球、竞走、太极拳等 。 3.定期复查血脂,内科就诊,必要时在医生指导下药物调脂治疗。
【轻度脂肪肝】 脂肪肝是由于体内过多的脂肪沉积在肝脏所致。常见于代谢障 碍性疾病,如糖尿病、高血脂、肥胖等。亦见于经常饮酒者。 脂肪肝有时会引起肝功能的异常。建议: 1、合理膳食,荤素搭配,控制高热量、高脂肪、高能量的食品 进食量,尽量少吃甜食;戒烟限酒。2、控制体重,坚持一定量的运动方式: 竞走、游泳等,加强体 内脂肪的消耗。3、慎用药物,以避免对肝脏的进一步损害。4、定期复查肝功能、血脂,肝胆 B 超,追踪观察,内科随诊。
【窦性心动过缓】 正常心率 60-100 次/分,大多数心动过缓无重要的临床意义,例 如运动员、经常运动健身者,少数见于冠心病、病窦综合征等 。建议: 1. 窦性心动过缓心率不低于每分钟 50 次,无症状者,一般无需 治疗。 2.如心率低于每分钟 40 次,且出现头晕、乏力等症状者,心内 科就诊。 脂肪肝窦性心动过缓问题
有哪些异常状态?
效果

总结
一句话总结
如果对性能和效果要求较高,并且有足够的预算和资源,可以考虑选择 OpenAI,它提供最好的效果和速度。然而,需要注意数据安全性的问题。
如果对成本敏感,并且愿意投入研发资源,可以选择开源大模型。虽然效果中等,但可以根据自己的需求进行定制开发,并且数据存储在自己的服务器上,更加安全,如果有很好的技术人员,推荐选择这个。
如果对数据安全性要求较高,并且预算和资源有限,可以选择纯前端方案。尽管效果较差,但通过缓存可以提升性能,并且数据不会离开用户的电脑,安全性较高,同样的开发成本也不会太高,特别适合文档站。
对比表格

使用场景
在信息查询领域,成本最高的是embedding和向量数据库。对于大型文档数据库,建议使用常用的数据挂向量数据库插件,以最小程度侵入业务流程。
● 大型项目:使用自优化的嵌入技术和异步的向量数据库进行持久化。
● 小型项目:使用WebAI嵌入技术和预处理的向量JSON,再结合次抛(incremental)WASM向量数据库。
● 中等项目:对于500MB以下的数据,推荐使用次抛WASM向量数据库,嵌入选择OpenAI,以获得最佳整体性能。对于500MB以上的数据,搭配持久化向量数据库和自优化的嵌入技术,效果会更好。
技术难点
● 分词的效果非常重要,好的分句比大模型还要重要一些。(投入运营同学)
● 向量数据库,数据更新比较麻烦,可能需要定时删除,对版本管理不太有好。(日抛数据库,每次全量计算)
● 速度不算快,如果需要大模型总结,需要 5s 以上,比正常搜索慢多了。(先出查询结果,再出总结)
送人玫瑰,手留余香,觉得有收获的朋友可以点赞,关注一波 ,我们组建了高级前端交流群,如果您热爱技术,想一起讨论技术,交流进步,不管是面试题,工作中的问题,难点热点都可以在交流群交流,为了拿到大Offer,邀请您进群,入群就送前端精选100本电子书以及 阿里面试前端精选资料 添加 下方小助手二维码或者扫描二维码 就可以进群。让我们一起学习进步.

推荐阅读
(点击标题可跳转阅读)
[面试必问]-你不知道的 React Hooks 那些糟心事
[面试必问]-全网最全 React16.0-16.8 特性总结
[架构分享]- 微前端qiankun+docker+nginx自动化部署
觉得本文对你有帮助?请分享给更多人
关注「React中文社区」加星标,每天进步



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









