







准备工作
安装selenium, pyquery, json模块。
使用的是火狐浏览器,所以还要安装geckodriver, 下载好后,把geckodirver.exe文件放在python.exe同一文件夹下即可。
如果使用chrome浏览器,需要安装chromedriver,需要对应好版本号,否则运行不起来。把下载后的chromedriver.exe放在python的Scripts文件夹下即可。
本次爬取使用火狐浏览器。
爬取步骤
爬虫最重要的一步就是如何获取到网页源代码,对于现在各种各样的动态网页,有时候可以使用Ajax请求直接获取到数据,但是大多数时候Ajax请求中的参数繁多也难以确定规律,所以本次使用selenium来获取网页的源代码,所见即所爬。
1、获取网页源码
首先确定我们需要访问的网页网址。

中间的部分就是你想要爬取的QQ号。这里解释下后面的main为主页。将main换成了其他的一些数字,例如311,334等等,这些可以直接访问到说说,留言版等等,感兴趣的可以直接访问说说界面开始爬取信息,这里不做考虑,还是直接从主页开始一步步访问说说。
这里放一张图片,为什么是311可以直接访问到说说。(右键检查(查看元素)或者F12进入)
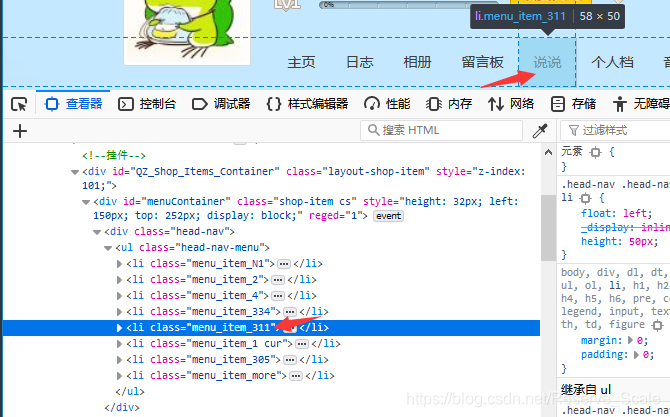
在进入空间主页后,我们接下来需要确定“说说”按钮,有两个说说按钮,获取其中一个就行。(详细代码后面再放)
btn_ss = wait.until(
EC.element_to_be_clickable((By.CSS_SELECTOR, '#QM_Profile_Mood_A span')))
btn_ss.click()
等待按钮可点击后,点击按钮,网页即跳转到说说界面。这里有个坑,如果这时候你直接获取网页源代码是获取不全的。
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章















 1148
1148











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









