







模型泛化
在得到模型之后,对模型进行分析~
1. 泛化性能分析
在一个项目中,我们通过设计和训练得到了一个model,该model的泛化可能很好,也可能不尽如人意,其背后的决定因素是什么呢?或者说我们可以从哪些方面去改进从而使下次得到的model更加令人满意呢?
1.1 概论
-
泛化误差/预测误差
学习算法的预测误差, 或者说泛化误差(generalization error)可以分解为三个部分: 偏差(bias), 方差(variance) 和噪声(noise). 在估计学习算法性能的过程中, 我们主要关注偏差与方差. 因为噪声属于不可约减的误差 (irreducible error). -
偏差:描述模型输出结果的期望与样本真实结果的差距。
(“偏”——偏离,偏离真实的标签。) -
方差:描述模型对于给定值的输出稳定性。
(在统计学中,方差描述的是这个随机变量的离散程度,也就是该随机变量在其期望值附近的波动程度。)
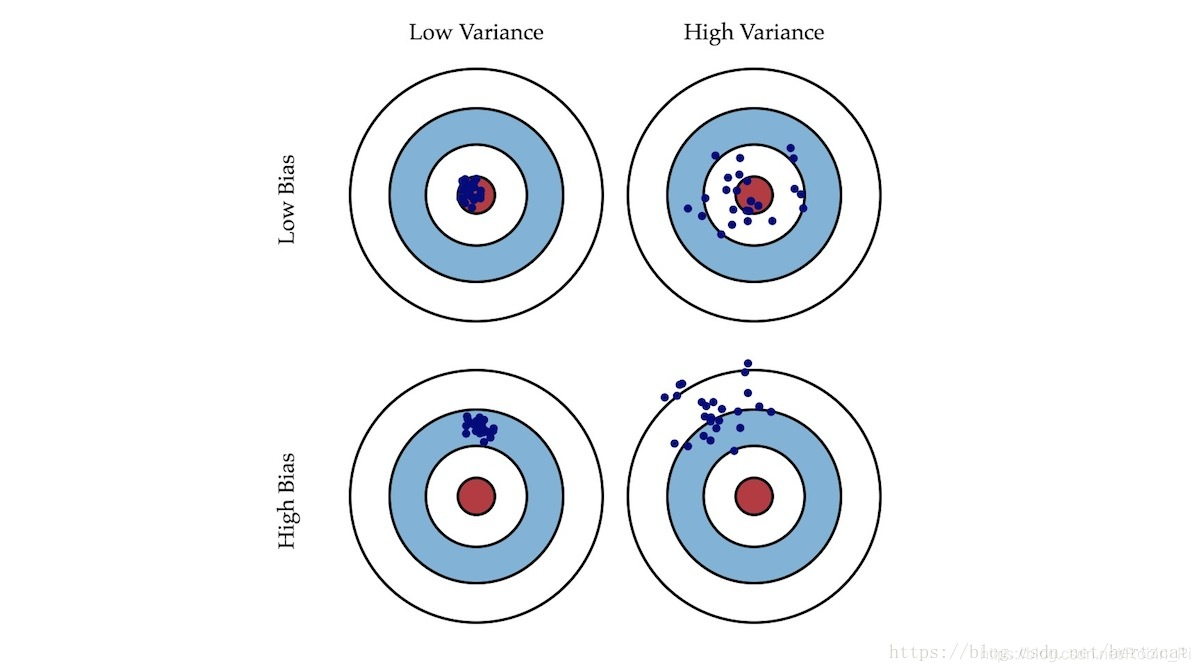
就像打靶一样,偏差描述了我们的射击总体是否偏离了我们的目标,而方差描述了射击准不准。
1.2 解释工具:”偏差-方差分解“
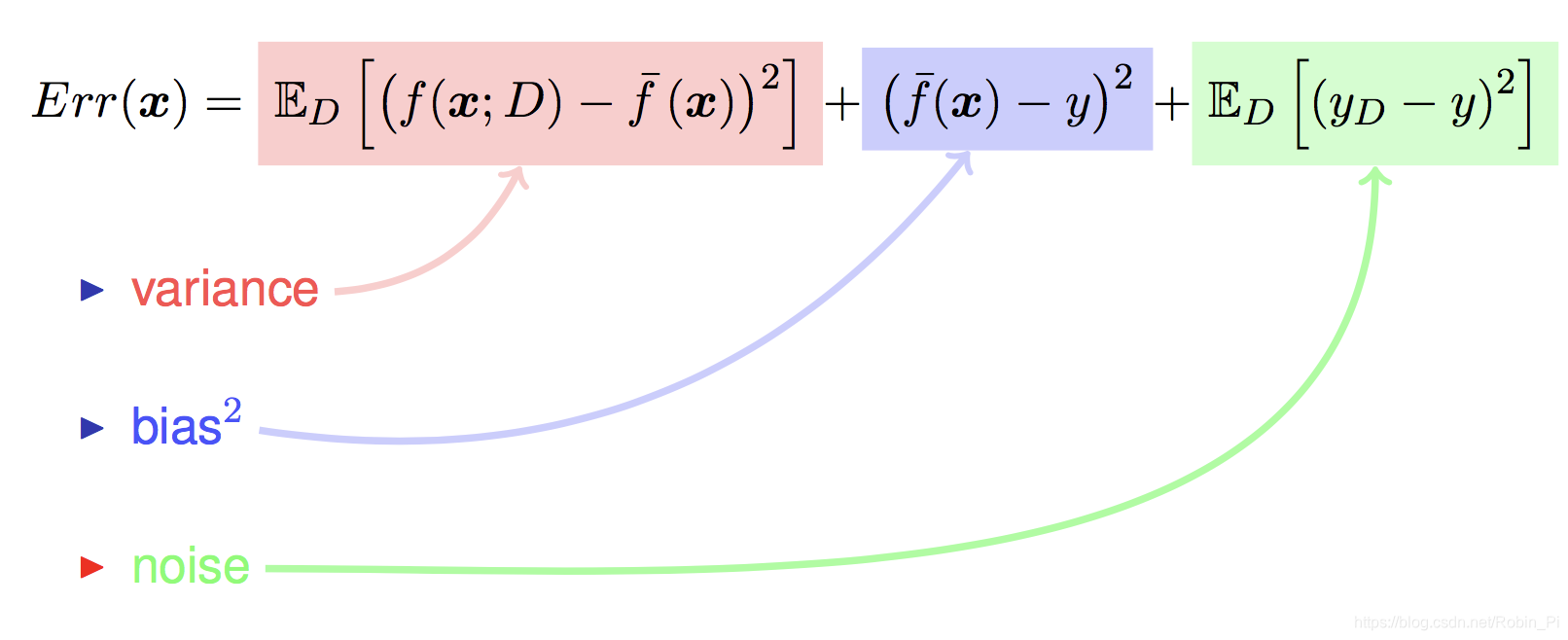
泛化误差 = 偏差 + 方差 + 噪声
算法的预测误差, 或者说泛化误差(generalization error)可以分解为三个部分: 偏差(bias), 方差(variance) 和噪声(noise)。
在估计学习算法性能的过程中, 我们主要关注偏差与方差. 因为噪声属于不可约减的误差 (irreducible error)。
假设:
-
测试样本:X
-
训练集:D
-
标记:yd(
有可能出现噪声使得 yd != y,即所谓的打标样本不纯) -
x 的真实标记:y
-
在训练集 D 上训练得到的模型 :f
-
模型 f 对 x 的预测输出:f(x;D)
-
模型 f 对 x 的 期望预测 输出: f ‾ \overline{f} f(x)
以回归任务为例,学习算法的期望预测为:
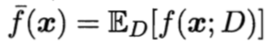
(再次验证,线性回归的本质就是均值预测)
注: f ‾ \overline{f} f(x) 可以理解为通过世间所有(无限)样本训练得来的期望模型对x的预测输出;f(x;D)t通过数据集 D 产生的期望模型对x的预测输出!
对算法的期望泛化误差进行分解:
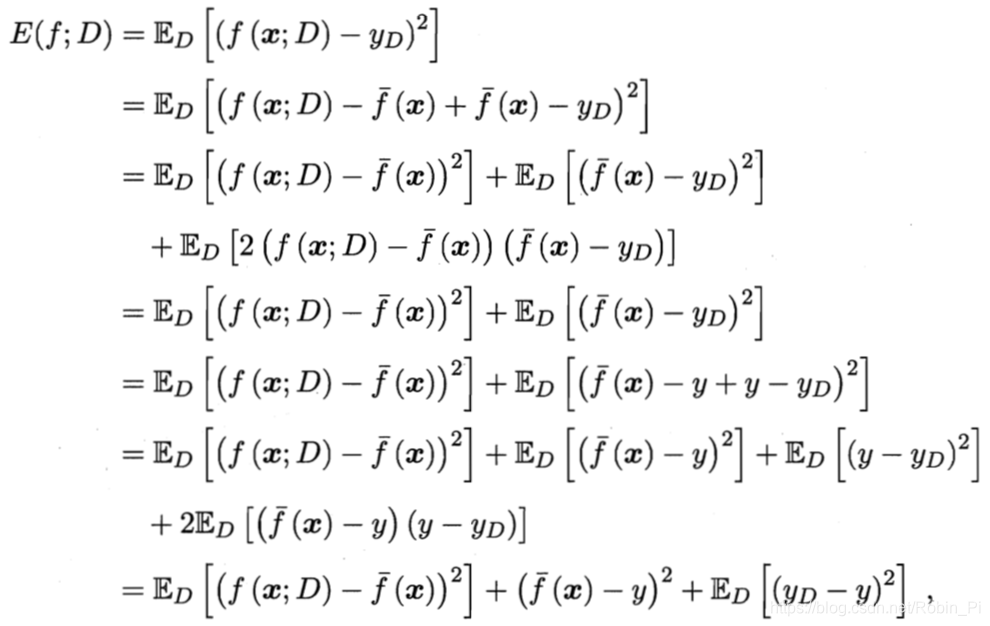
整理得:
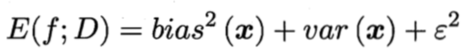
即,泛化误差可分解为:偏差、方差、噪声之和。
泛化误差 = 偏差 + 方差 + 噪声
如何直观理解?
三个对象:① 我们期望通过训练所有样本得到的模型(期望风险模型)的结果输出、②我们期望根据所拥有的样本集D训练得到的(经验风险模型)的结果输出、③模型实际产生输出的结果
注:①、②之所以叫“期望”是因为都跟现实—③有差距!
拿着最理想的期望结果①,与较为实际的期望结果②、以及实际的结果③,分别作比较,得到的两个差值(variance 和 bias)的和,再加上一个不可约减的噪声误差(noise),三者之和即为总共的误差和(模型泛化误差Err(x))。
注:为什么①是最理想状态?——因为我们的数据总是匮乏的,不可能达到“无限”的状态,所以对应的误差叫做期望风险,根据现实的数据集D建立起来的模型和真实结果的误差,被叫做经验误差。更多,可以参考关键点1。
噪声:错误标记
噪声为真实标记与数据集中的实际标记间的偏差:
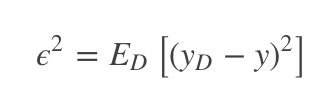
模型在当前任务能达到的期望泛化误差的下届 - 数据决定算法的上界,算法只是在逼近这个上界。
方差: 数据扰动对模型的影响
在一个训练集 D 上模型 f 对测试样本 x 的预测输出为 f(x;D), 那么学习算法 f 对测试样本 x 的 期望预测 为:
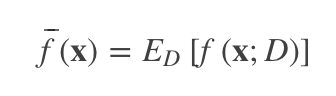
使用样本数相同的不同训练集产生的方差为:
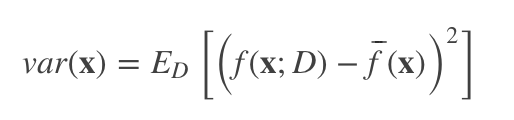
偏差:考察模型本身拟合能力
预测与真实标记的误差称为偏差(bias), 即:
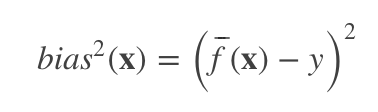
它体现了模型的拟合能力,这其实也就是经验风险的计算公式。
小结
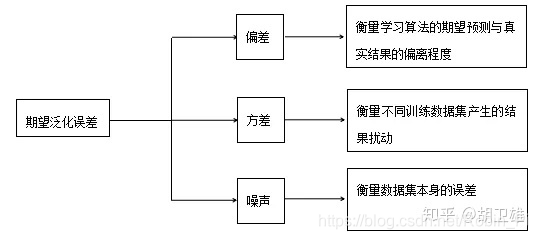
- 偏差
偏差度量了学习算法的期望预测与真实结果的偏离程序, 即 刻画了学习算法本身的拟合能力 .
- 方差
方差度量了同样大小的训练集的变动所导致的学习性能的变化, 即 刻画了数据扰动所造成的影响 .
- 噪声
噪声表达了在当前任务上任何学习算法所能达到的期望泛化误差的下界, 即 刻画了学习问题本身的难度 .
偏差-方差囧境(bias-variance dilemma)
偏差-方差分解说明,泛化性能是由学习算法的能力、数据的充分性以及学习任务本身的难度共同决定的。给定一个学习任务,为了取得好的泛化性能,则需使偏差较小,即能够充分拟合数据,并且使方差较小,即使得数据扰动产生的影响小。
一般来说,偏差与方差是有冲突的,这称为”偏差-方差窘境“,下图中,给定学习任务,假定我们能控制学习算法的训练程度,则在不同训练程度下,偏差-方差的取值曲线如下:
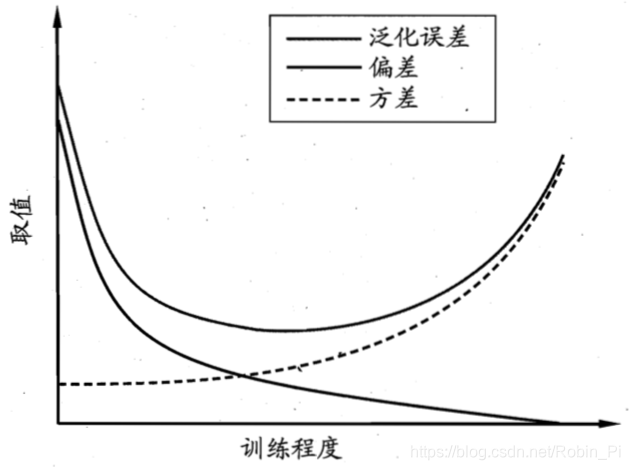
在训练不足时,学习器的拟合能力不够强,训练数据的扰动不足以使学习器产生显著变化,此时偏差主导了泛化错误率;
随着训练程度的加深,学习器的拟合能力逐渐增强,训练数据发生的扰动渐渐能被学习器学到,方差逐渐主导了泛化错误率;
在训练程度充足后,学习器的拟合能力已非常强,训练数据发生的轻微扰动都会导致学习器发生显著变化,若训练数据自身的、非全局的普遍特性被学习器学到了,则将发生过拟合。
经验误差与泛化能力之间的矛盾
其实说白了,还是因为真实数据无法达到无限的水平造成的过拟合问题:
如果完全依赖手里的数据集 D ,则训练出来的模型则会对训练数据表现得非常好(偏差小),但是对数据集 D 之外的数据集,即新数据,表现得不好(方差大);
若限制模型对数据集 D 的依赖,添加惩罚(正则项),则模型会增加了模型对数据扰动的抵抗能力(模型稳定性),但反过来又限制了模型自身的稳定性(偏差变大)。
2. 分析:泛化误差评估方法
通常,我们通过实验测试来对学习器的泛化误差进行评估并进而做出选择。为此,需要一个和训练集互斥的数据集来测试学习器对新样本的判别能力,然后我们以测试集上的”测试误差(testing error)“作为泛化误差的近似。
有几种方法得到测试集:
- 留出法(hold-out)
- 交叉验证法(cross validation)
- 自助法(bootstrapping)
不管我们采取了什么测试集划分方法,在评估结束后,模型参数选定后,我们需要采用全集D进行训练,将数据集D训练得到的模型交付给业务方,这才是我们最终的模型。
2.1 模型复杂程度的影响
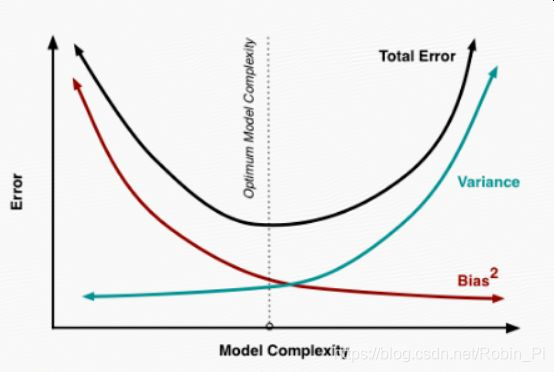
以多项式回归,
- 次数
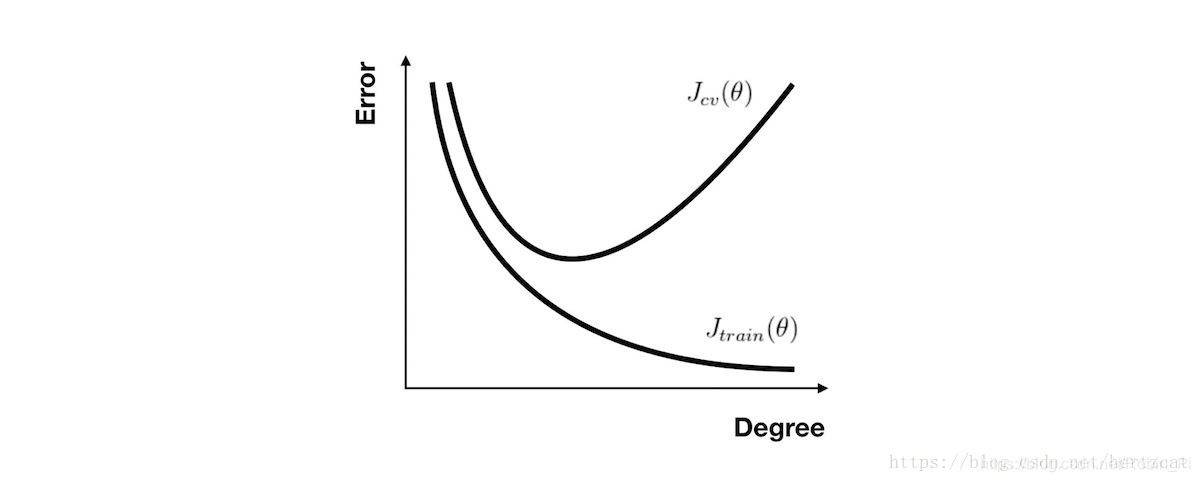
- 正则化参数
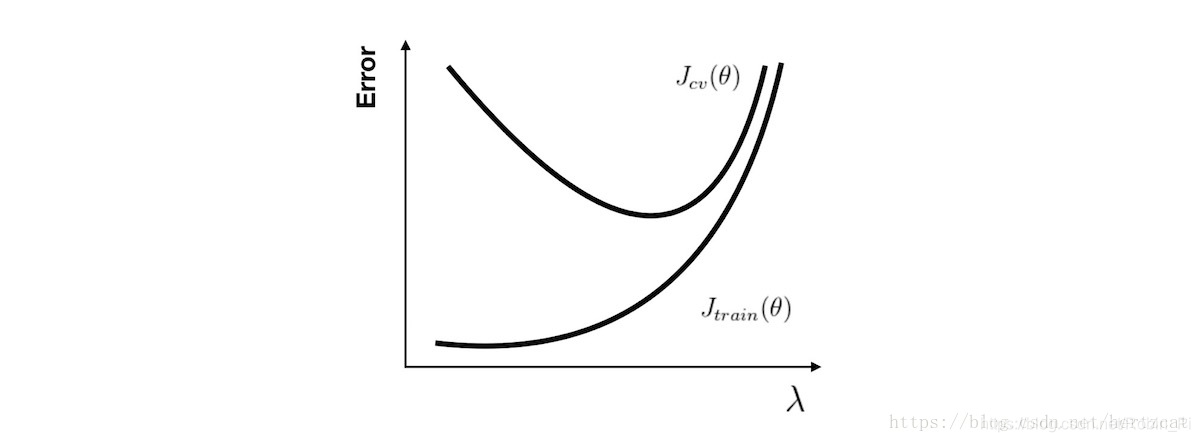
2.2 训练程度的影响:使用学习曲线分析
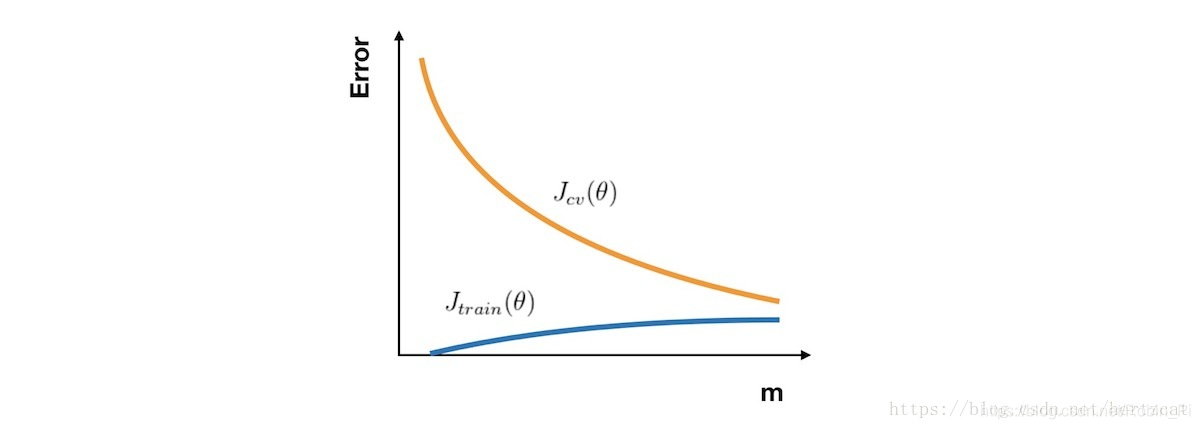
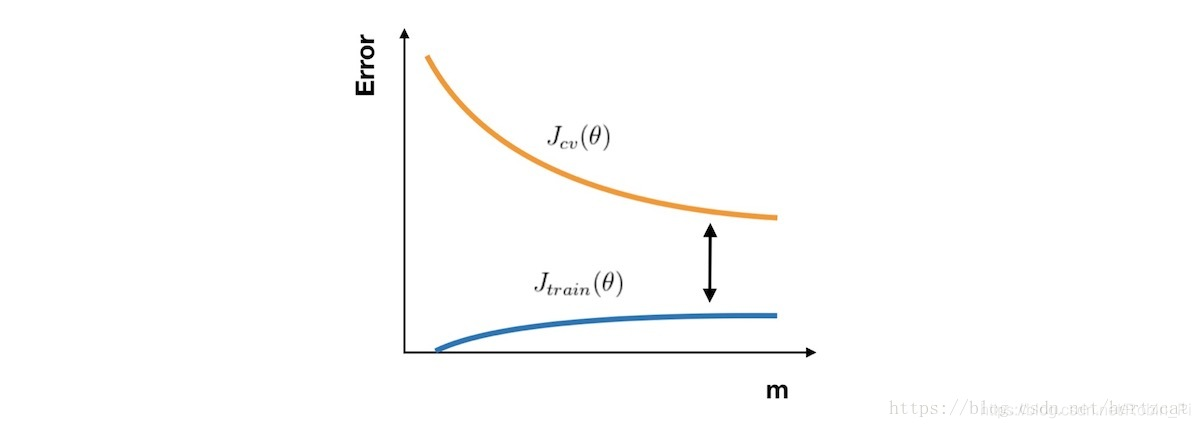
无论你是要检查你的学习算法是否正常工作或是要改进算法的表现,学习曲线 都是一个十分直观有效的工具。学习曲线 的横轴是样本数,纵轴为 训练集 和 交叉验证集 的 误差。
- 合理:Jcv(θ) 因为训练数据增加而拟合得更好不断下降,接近Jtrain(θ) ,且误差 很小
- 高偏差:Jtrain(θ) 与 Jcv(θ) 已经十分接近,但是 误差 很大
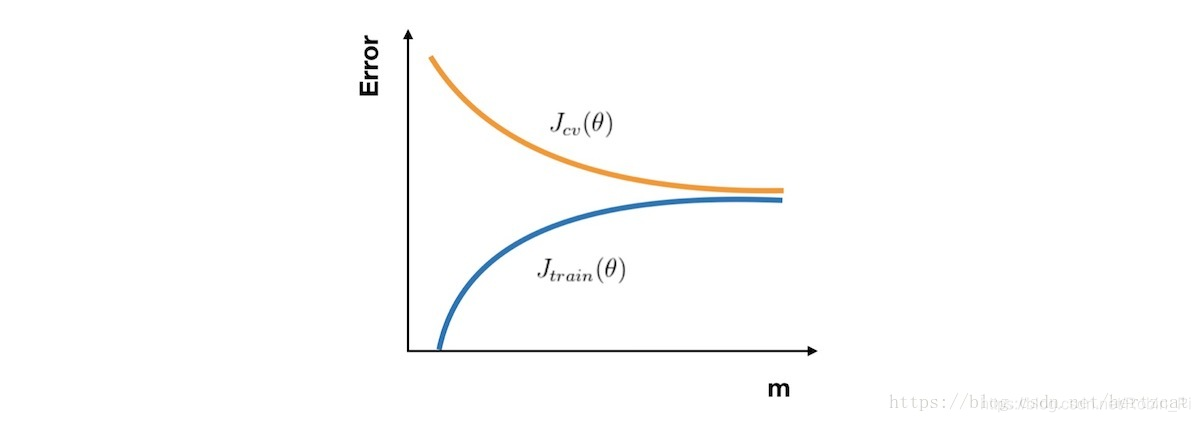
- 高方差:Jtrain(θ) 的 误差 较小,Jcv(θ) 比较大
3. 解决办法
[高方差] 采集更多的样本数据
[高方差] 减少特征数量,去除非主要的特征
[高偏差] 引入更多的相关特征
[高偏差] 采用多项式特征
[高偏差] 减小正则化参数 λ
[高方差] 增加正则化参数 λ
参考














 1960
1960











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









