









《Virtio: An I/O virtualization framework for Linux》
目录
Virtio: An I/O virtualization framework for Linux
Paravirtualized I/O with KVM and lguest
Full virtualization vs. paravirtualization
An abstraction for Linux guests
什么是 virtio#
virtio 是一种 I/O 半虚拟化解决方案,是一套通用 I/O 设备虚拟化的程序,是对半虚拟化 Hypervisor 中的一组通用 I/O 设备的抽象。提供了一套上层应用与各 Hypervisor 虚拟化设备(KVM,Xen,VMware等)之间的通信框架和编程接口,减少跨平台所带来的兼容性问题,大大提高驱动程序开发效率。
为什么是 virtio#
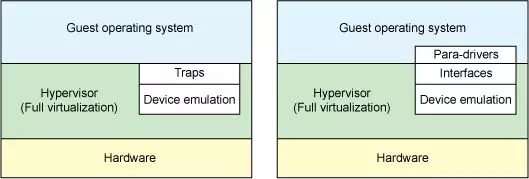
在完全虚拟化的解决方案中,guest VM 要使用底层 host 资源,需要 Hypervisor 来截获所有的请求指令,然后模拟出这些指令的行为,这样势必会带来很多性能上的开销。半虚拟化通过底层硬件辅助的方式,将部分没必要虚拟化的指令通过硬件来完成,Hypervisor 只负责完成部分指令的虚拟化,要做到这点,需要 guest 来配合,guest 完成不同设备的前端驱动程序,Hypervisor 配合 guest 完成相应的后端驱动程序,这样两者之间通过某种交互机制就可以实现高效的虚拟化过程。
由于不同 guest 前端设备其工作逻辑大同小异(如块设备、网络设备、PCI设备、balloon驱动等),单独为每个设备定义一套接口实属没有必要,而且还要考虑扩平台的兼容性问题,另外,不同后端 Hypervisor 的实现方式也大同小异(如KVM、Xen等),这个时候,就需要一套通用框架和标准接口(协议)来完成两者之间的交互过程,virtio 就是这样一套标准,它极大地解决了这些不通用的问题。
virtio 的架构#
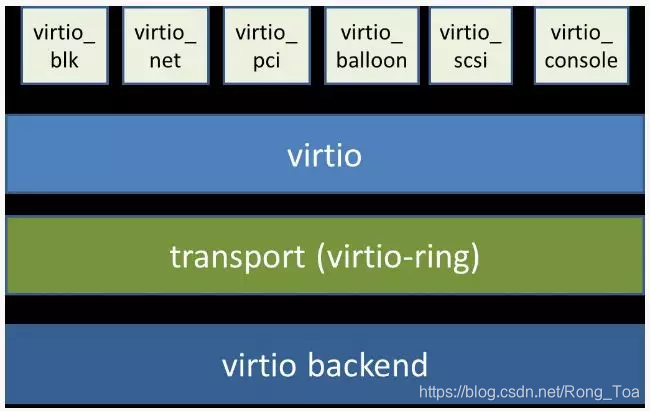
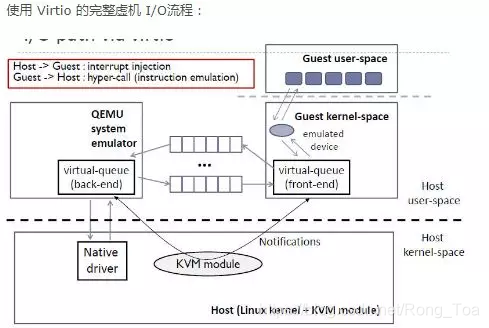
从总体上看,virtio 可以分为四层,包括前端 guest 中各种驱动程序模块,后端 Hypervisor (实现在Qemu上)上的处理程序模块,中间用于前后端通信的 virtio 层和 virtio-ring 层,virtio 这一层实现的是虚拟队列接口,算是前后端通信的桥梁,而 virtio-ring 则是该桥梁的具体实现,它实现了两个环形缓冲区,分别用于保存前端驱动程序和后端处理程序执行的信息。
严格来说,virtio 和 virtio-ring 可以看做是一层,virtio-ring 实现了 virtio 的具体通信机制和数据流程。或者这么理解可能更好,virtio 层属于控制层,负责前后端之间的通知机制(kick,notify)和控制流程,而 virtio-vring 则负责具体数据流转发。
virtio 数据流交互机制#
vring 主要通过两个环形缓冲区来完成数据流的转发,如下图所示。
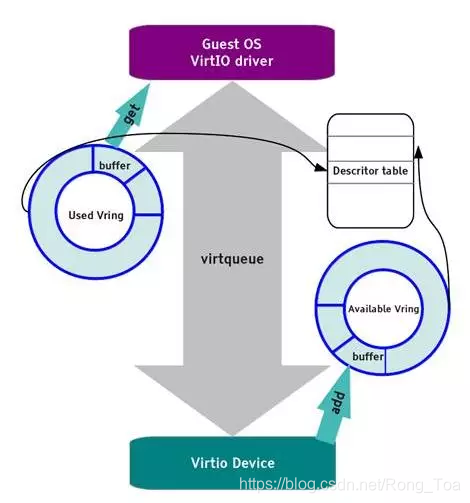
vring 包含三个部分,描述符数组 desc,可用的 available ring 和使用过的 used ring。
desc 用于存储一些关联的描述符,每个描述符记录一个对 buffer 的描述,available ring 则用于 guest 端表示当前有哪些描述符是可用的,而 used ring 则表示 host 端哪些描述符已经被使用。
Virtio 使用 virtqueue 来实现 I/O 机制,每个 virtqueue 就是一个承载大量数据的队列,具体使用多少个队列取决于需求,例如,virtio 网络驱动程序(virtio-net)使用两个队列(一个用于接受,另一个用于发送),而 virtio 块驱动程序(virtio-blk)仅使用一个队列。
具体的,假设 guest 要向 host 发送数据,首先,guest 通过函数 virtqueue_add_buf 将存有数据的 buffer 添加到 virtqueue 中,然后调用 virtqueue_kick 函数,virtqueue_kick 调用 virtqueue_notify 函数,通过写入寄存器的方式来通知到 host。host 调用 virtqueue_get_buf 来获取 virtqueue 中收到的数据。
存放数据的 buffer 是一种分散-聚集的数组,由 desc 结构来承载,如下是一种常用的 desc 的结构:
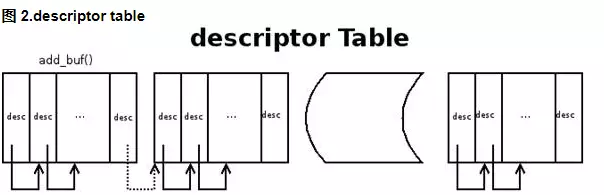
当 guest 向 virtqueue 中写数据时,实际上是向 desc 结构指向的 buffer 中填充数据,完了会更新 available ring,然后再通知 host。
当 host 收到接收数据的通知时,首先从 desc 指向的 buffer 中找到 available ring 中添加的 buffer,映射内存,同时更新 used ring,并通知 guest 接收数据完毕。
总结:#
virtio 是 guest 与 host 之间通信的润滑剂,提供了一套通用框架和标准接口或协议来完成两者之间的交互过程,极大地解决了各种驱动程序和不同虚拟化解决方案之间的适配问题。
virtio 抽象了一套 vring 接口来完成 guest 和 host 之间的数据收发过程,结构新颖,接口清晰。
英文原文
Virtio: An I/O virtualization framework for Linux
Paravirtualized I/O with KVM and lguest
By M. Jones
Published January 29, 2010
In a nutshell, virtio is an abstraction layer over devices in a paravirtualized hypervisor. virtio was developed by Rusty Russell in support of his own virtualization solution called lguest. This article begins with an introduction to paravirtualization and emulated devices, and then explores the details of virtio. The focus is on the virtio framework from the 2.6.30 kernel release.
Linux is the hypervisor playground. As my article on Linux as a hypervisor showed, Linux offers a variety of hypervisor solutions with different attributes and advantages. Examples include the Kernel-based Virtual Machine (KVM), lguest, and User-mode Linux. Having these different hypervisor solutions on Linux can tax the operating system based on their independent needs. One of the taxes is virtualization of devices. Rather than have a variety of device emulation mechanisms (for network, block, and other drivers), virtio provides a common front end for these device emulations to standardize the interface and increase the reuse of code across the platforms.
Full virtualization vs. paravirtualization
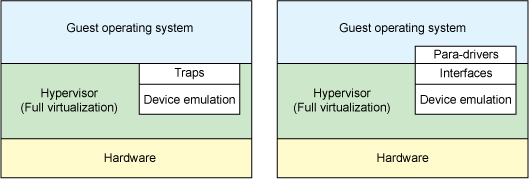
Let’s start with a quick discussion of two distinct types of virtualization schemes: full virtualization and paravirtualization. In full virtualization, the guest operating system runs on top of a hypervisor that sits on the bare metal. The guest is unaware that it is being virtualized and requires no changes to work in this configuration. Conversely, in paravirtualization, the guest operating system is not only aware that it is running on a hypervisor but includes code to make guest-to-hypervisor transitions more efficient (see Figure 1).
In the full virtualization scheme, the hypervisor must emulate device hardware, which is emulating at the lowest level of the conversation (for example, to a network driver). Although the emulation is clean at this abstraction, it’s also the most inefficient and highly complicated. In the paravirtualization scheme, the guest and the hypervisor can work cooperatively to make this emulation efficient. The downside to the paravirtualization approach is that the operating system is aware that it’s being virtualized and requires modifications to work.
Hardware continues to change with virtualization. New processors incorporate advanced instructions to make guest operating systems and hypervisor transitions more efficient. And hardware continues to change for input/output (I/O) virtualization, as well (see resources on the right to learn about Peripheral Controller Interconnect [PCI] passthrough and single- and multi-root I/O virtualization).
But in traditional full virtualization environments, the hypervisor must trap these requests, and then emulate the behaviors of real hardware. Although doing so provides the greatest flexibility (namely, running an unmodified operating system), it does introduce inefficiency (see the left side of Figure 1). The right side of Figure 1 shows the paravirtualization case. Here, the guest operating system is aware that it’s running on a hypervisor and includes drivers that act as the front end. The hypervisor implements the back-end drivers for the particular device emulation. These front-end and back-end drivers are where virtio comes in, providing a standardized interface for the development of emulated device access to propagate code reuse and increase efficiency.
Virtio alternatives
virtiois not entirely alone in this space. Xen provides paravirtualized device drivers, and VMware provides what are called Guest Tools.
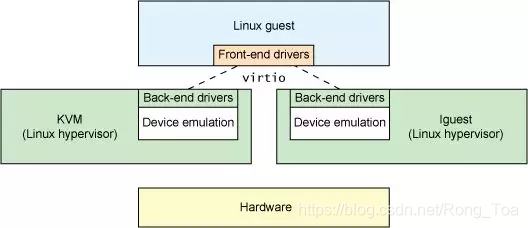
An abstraction for Linux guests
From the previous section, you can see that virtio is an abstraction for a set of common emulated devices in a paravirtualized hypervisor. This design allows the hypervisor to export a common set of emulated devices and make them available through a common application programming interface (API). Figure 2 illustrates why this is important. With paravirtualized hypervisors, the guests implement a common set of interfaces, with the particular device emulation behind a set of back-end drivers. The back-end drivers need not be common as long as they implement the required behaviors of the front end.
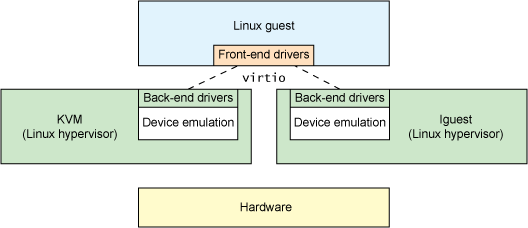
Note that in reality (though not required), the device emulation occurs in user space using QEMU, so the back-end drivers communicate into the user space of the hypervisor to facilitate I/O through QEMU. QEMU is a system emulator that, in addition to providing a guest operating system virtualization platform, provides emulation of an entire system (PCI host controller, disk, network, video hardware, USB controller, and other hardware elements).
The virtio API relies on a simple buffer abstraction to encapsulate the command and data needs of the guest. Let’s look at the internals of the virtio API and its components.
Virtio architecture
In addition to the front-end drivers (implemented in the guest operating system) and the back-end drivers (implemented in the hypervisor), virtio defines two layers to support guest-to-hypervisor communication. At the top level (called virtio) is the virtual queue interface that conceptually attaches front-end drivers to back-end drivers. Drivers can use zero or more queues, depending on their need. For example, the virtio network driver uses two virtual queues (one for receive and one for transmit), where the virtio block driver uses only one. Virtual queues, being virtual, are actually implemented as rings to traverse the guest-to-hypervisor transition. But this could be implemented any way, as long as both the guest and hypervisor implement it in the same way.
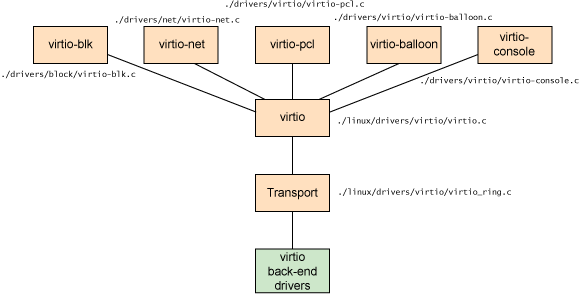
As shown in Figure 3, five front-end drivers are listed for block devices (such as disks), network devices, PCI emulation, a balloon driver (for dynamically managing guest memory usage), and a console driver. Each front-end driver has a corresponding back-end driver in the hypervisor.
Concept hierarchy
From the perspective of the guest, an object hierarchy is defined as shown in Figure 4. At the top is the virtio_driver, which represents the front-end driver in the guest. Devices that match this driver are encapsulated by the virtio_device (a representation of the device in the guest). This refers to the virtio_config_ops structure (which defines the operations for configuring the virtio device). The virtio_device is referred to by the virtqueue (which includes a reference to the virtio_device to which it serves). Finally, each virtqueue object references the virtqueue_ops object, which defines the underlying queue operations for dealing with the hypervisor driver. Although the queue operations are the core of the virtio API, I provide a brief discussion of discovery, and then explore the virtqueue_ops operations in more detail.
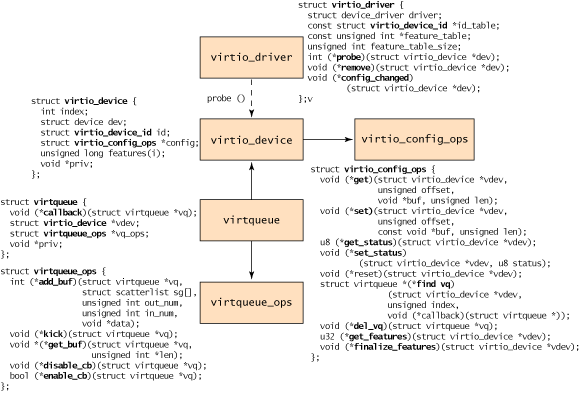
The process begins with the creation of a virtio_driver and subsequent registration via register_virtio_driver. The virtio_driver structure defines the upper-level device driver, list of device IDs that the driver supports, a features table (dependent upon the device type), and a list of callback functions. When the hypervisor identifies the presence of a new device that matches a device ID in the device list, the probe function is called (provided in the virtio_driver object) to pass up the virtio_device object. This object is cached with the management data for the device (in a driver-dependent way). Depending on the driver type, the virtio_config_ops functions may be invoked to get or set options specific to the device (for example, getting the Read/Write status of the disk for a virtio_blk device or setting the block size of the block device).
Note that the virtio_device includes no reference to the virtqueue (but the virtqueue does reference the virtio_device). To identify the virtqueues that associate with this virtio_device, you use the virtio_config_ops object with the find_vq function. This object returns the virtual queues associated with this virtio_device instance. The find_vq function also permits the specification of a callback function for the virtqueue (see the virtqueue structure in Figure 4), which is used to notify the guest of response buffers from the hypervisor.
The virtqueue is a simple structure that identifies an optional callback function (which is called when the hypervisor consumes the buffers), a reference to the virtio_device, a reference to the virtqueue operations, and a special priv reference that refers to the underlying implementation to use. Although the callback is optional, it’s possible to enable or disable callbacks dynamically.
But the core of this hierarchy is the virtqueue_ops, which defines how commands and data are moved between the guest and the hypervisor. Let’s first explore the object that is added or removed from the virtqueue.
Virtio buffers
Guest (front-end) drivers communicate with hypervisor (back-end) drivers through buffers. For an I/O, the guest provides one or more buffers representing the request. For example, you could provide three buffers, with the first representing a Read request and the subsequent two buffers representing the response data. Internally, this configuration is represented as a scatter-gather list (with each entry in the list representing an address and a length).
Core API
Linking the guest driver and hypervisor driver occurs through the virtio_device and most commonly through virtqueues. The virtqueue supports its own API consisting of five functions. You use the first function, add_buf, to provide a request to the hypervisor. This request is in the form of the scatter-gather list discussed previously. To add_buf, the guest provides the virtqueue to which the request is to be enqueued, the scatter-gather list (an array of addresses and lengths), the number of buffers that serve as out entries (destined for the underlying hypervisor), and the number of in entries (for which the hypervisor will store data and return to the guest). When a request has been made to the hypervisor through add_buf, the guest can notify the hypervisor of the new request using the kick function. For best performance, the guest should load as many buffers as possible onto the virtqueue before notifying through kick.
Responses from the hypervisor occur through the get_buf function. The guest can poll simply by calling this function or wait for notification through the provided virtqueue callback function. When the guest learns that buffers are available, the call to get_buf returns the completed buffers.
The final two functions in the virtqueue API are enable_cb and disable_cb. You can use these functions to enable and disable the callback process (via the callback function initialized in the virtqueue through the find_vq function). Note that the callback function and the hypervisor are in separate address spaces, so the call occurs through an indirect hypervisor call (such as kvm_hypercall).
The format, order, and contents of the buffers are meaningful only to the front-end and back-end drivers. The internal transport (rings in the current implementation) move only buffers and have no knowledge of their internal representation.
Example virtio drivers
You can find the source to the various front-end drivers within the ./drivers subdirectory of the Linux kernel. The virtio network driver can be found in ./drivers/net/virtio_net.c, and the virtio block driver can be found in ./drivers/block/virtio_blk.c. The subdirectory ./drivers/virtio provides the implementation of the virtio interfaces (virtio device, driver, virtqueue, and ring). virtio has also been used in High-Performance Computing (HPC) research to develop inter-virtual machine (VM) communications through shared memory passing. Specifically, this was implemented through a virtualized PCI interface using the virtio PCI driver. You can learn more about this work in the resources section on the right.
You can exercise this paravirtualization infrastructure today in the Linux kernel. All you need is a kernel to act as the hypervisor, a guest kernel, and QEMU for device emulation. You can use either KVM (a module that exists in the host kernel) or with Rusty Russell’s lguest (a modified Linux guest kernel). Both of these virtualization solutions support virtio (along with QEMU for system emulation and libvirt for virtualization management).
The result of Rusty’s work is a simpler code base for paravirtualized drivers and faster emulation of virtual devices. But even more important, virtio has been found to provide better performance (2-3 times for network I/O) than current commercial solutions. This performance boost comes at a cost, but it’s well worth it if Linux is your hypervisor and guest.
Going further
Although you may never develop front-end or back-end drivers for virtio, it implements an interesting architecture and is worth understanding in more detail. virtio opens up new opportunities for efficiency in paravirtualized I/O environments while building from previous work in Xen. Linux continues to prove itself as a production hypervisor and a research platform for new virtualization technologies. virtio is yet another example of the strengths and openness of Linux as a hypervisor.

















 1469
1469

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









