










概叙
科普文:Java基础之算法系列【一文搞懂哈希Hash、及其应用】_java 字符串hash算法映射范围100亿-CSDN博客
科普文:Java基础之算法系列【一文搞懂CRC32哈希、及其应用】_crc32 md5 sha1是什么意思-CSDN博客
科普文:Java基础之算法系列【Bitmap(位图)和RoaringBitmap(压缩位图) 原理分析】_bitmap csdn-CSDN博客
科普文:Java基础之算法系列【位图升级版:Roaring Bitmaps压缩位图】-CSDN博客
科普文:Java基础之算法系列【JDK自带位图BitSet源码解读】-CSDN博客
科普文:Java基础之算法系列【一文搞懂位图BitMap、及其应用】-CSDN博客
科普文:Java基础系列【一文搞懂字节、位运算、及其应用】_java 字节-CSDN博客
前面梳理完成位运算、哈希、位图,再来实现一个布隆过滤器Bloom Filter,基本上就是没啥大问题,毕竟Bloom Filter布隆过滤器就是哈希+位图。
布隆过滤器(Bloom Filter)简介
布隆过滤器(Bloom Filter)是一种空间效率很高的概率型数据结构,它允许存在一定的误判率,但绝不会将一个存在的元素误判为不存在。布隆过滤器主要用于判断一个元素是否在一个集合中,广泛应用于去重、防止缓存击穿等场景。
布隆过滤器(Bloom Filter)原理
布隆过滤器由一个很长的二进制向量(位数组)和一系列随机映射函数(哈希函数)组成。
当需要添加元素到布隆过滤器时,通过多个哈希函数将元素映射到位数组的多个位置,并将这些位置上的值设为1。
当需要判断一个元素是否存在于集合中时,同样通过这些哈希函数找到位数组中的对应位置,如果所有位置上的值都为1,则认为该元素可能存在;如果任何一个位置上的值为0,则确定该元素不存在。
布隆过滤器(Bloom Filter)优缺点
优点:
- 空间效率高:布隆过滤器通过允许一定比例的误判来换取存储空间的极大节省。
- 时间复杂度低:增加和查询元素的时间复杂度为O(k),其中k是哈希函数的数量,通常是一个相对较小的常数。
- 保密性强:布隆过滤器不存储元素本身,仅存储哈希结果,提供了一定程度的隐私保护。
缺点:
- 存在一定的误判率:布隆过滤器可能会错误地报告一个不存在的元素为存在,但永远不会报告一个存在的元素为不存在。
- 无法获取元素本身:由于布隆过滤器不存储元素的实际值,因此无法从布隆过滤器中检索出具体的元素。
- 删除元素困难:在布隆过滤器中删除元素是困难的,因为一个位可能对应多个元素。如果简单地将某一位设置回0,可能会影响其他元素的存在判断。
布隆过滤器(Bloom Filter)应用场景
- 缓存击穿防护:在缓存系统中,使用布隆过滤器可以快速判断请求的数据是否在缓存中,从而避免对后端数据库的无效访问。
- 黑名单校验:将所有黑名单项目存储在布隆过滤器中,可以快速判断某个项目是否在黑名单中。
- 垃圾邮件和恶意请求过滤:通过布隆过滤器过滤掉已知的垃圾邮件发送者或恶意请求者。
- 数据库查询优化:在数据库查询前,先使用布隆过滤器判断数据是否存在,减少不必要的IO操作。
- 网页代理缓存:在网页代理缓存服务器中使用布隆过滤器来管理缓存内容。
布隆过滤器(Bloom Filter)注意事项
- 误判率控制:布隆过滤器的误判率可以通过调整位数组的大小和哈希函数的数量来控制,但无法完全消除。需要根据具体应用场景来选择合适的参数。
- 删除元素问题:布隆过滤器不直接支持元素的删除操作。如果需要删除元素,可以考虑使用计数布隆过滤器或其他变种,但这通常需要更多的内存和计算资源。
- 初始化参数选择:在初始化布隆过滤器时,需要选择合适的位数组大小和哈希函数数量,这些参数直接影响布隆过滤器的性能和误判率。
- 容量规划:布隆过滤器的容量是有限的,当插入的元素数量超过其设计容量时,误判率会显著增加。因此,在使用布隆过滤器时,需要合理规划其容量,避免过载。
手搓布隆过滤器Bloom Filter
在前面哈希算法性能测试中:这7种hash算法性能不错{"StringHash", "ObjectHash", "BkdrHash", "ElfHash", "DjbHash", "RsHash", "SdbmHash"},那么我们就用这7种hash来计算字符串的“指纹”。

手搓布隆过滤器Bloom Filter = hash + bitmap
7种hash算法有了,那么我们位图就直接用自带的BitSet。
实现代码
package com.zxx.study.algorithm.hash.fliter;
import com.zxx.study.algorithm.hash.hash.HashFunction;
import com.zxx.study.algorithm.hash.hash.HashFunctionFactory;
import java.util.BitSet;
import java.util.HashMap;
import java.util.Map;
/**
* @author zhouxx
* @create 2025-01-05 13:33
*/
public class BloomFilter {
private final static int _initSize = 10000; // 布隆过滤器的大小
private final static int _initSeeds = 3; // 哈希函数的次数
private final int size; // 布隆过滤器的大小
private final int seeds; // 哈希函数的次数
private final BitSet bitSet; // 位数组
public static final Map<String, HashFunction> hashFunction = new HashMap<>();
/**
* 3.从哈希冲突和耗时两方面都比较优秀的是:java自带的String.hashCode()、Objects.hash(),而我们自己实现的则有
* <p>
* BkdrHash冲突概率: 0/10000000=0.0 总耗时:5520ms
* ElfHash冲突概率: 0/10000000=0.0 总耗时:5576ms
* DjbHash冲突概率: 0/10000000=0.0 总耗时:5707ms
* RsHash冲突概率: 0/10000000=0.0 总耗时:7310ms
* SdbmHash冲突概率: 0/10000000=0.0 总耗时:13110ms
*/
private final static String[] HashFunctionNames = {"StringHash", "ObjectHash", "BkdrHash", "ElfHash", "DjbHash", "RsHash", "SdbmHash"};
// 构造函数,初始化布隆过滤器
public BloomFilter() {
this(_initSize, _initSeeds);
}
// 构造函数,初始化布隆过滤器
public BloomFilter(int size, int hashCount) {
if (hashCount <= 0 || hashCount > HashFunctionNames.length) {
throw new RuntimeException("Out of Hash seeds:"+hashCount);
}
this.seeds = hashCount;
this.size = size;
this.bitSet = new BitSet(size);
for (String hashName : HashFunctionNames) {
hashFunction.put(hashName, HashFunctionFactory.getHashFunction(hashName));
}
}
// 添加元素到布隆过滤器中
public void add(String value) {
for (int seed = 0; seed < seeds; seed++) {
bitSet.set(((Integer)hashFunction.get(HashFunctionNames[seed]).hash(value) & 0x7FFFFFFF), true);
}
}
// 检查布隆过滤器中是否可能包含某个元素
public boolean mightContain(String value) {
for (int seed = 0; seed < seeds; seed++) {
if (!bitSet.get(((Integer)hashFunction.get(HashFunctionNames[seed]).hash(value) & 0x7FFFFFFF))) {
return false;
}
}
return true;
}
public int trueCount(){
int trueCount = 0; // 用于记录true的数量
for (int i = bitSet.nextSetBit(0); i >= 0; i = bitSet.nextSetBit(i + 1)) {
//System.out.println(i);
trueCount++;
}
return trueCount;
}
}
测试结果
package com.zxx.study.algorithm.hash.fliter;
/**
* @author zhouxx
* @create 2025-01-05 14:00
*/
public class Test {
// 主函数,用于测试布隆过滤器
public static void main(String[] args) {
BloomFilter bloomFilter = new BloomFilter(1000, 5);
// 添加元素
bloomFilter.add("hello");
bloomFilter.add("world");
bloomFilter.add(Integer.MAX_VALUE+"");
bloomFilter.add(Integer.MIN_VALUE+"");
bloomFilter.add(Long.MAX_VALUE+"");
bloomFilter.add(Long.MIN_VALUE+"");
// 检查元素
System.out.println(bloomFilter.mightContain("hello")); // 输出: true(可能存在误判)
System.out.println(bloomFilter.mightContain("world")); // 输出: true(可能存在误判)
System.out.println(bloomFilter.mightContain("java")); // 输出: false(不在的一定不在)
System.out.println(bloomFilter.trueCount());//18
BloomFilter bloomFilter2 = new BloomFilter(1000, 2);
// 添加元素
bloomFilter2.add("hello");
bloomFilter2.add("world");
bloomFilter2.add(Integer.MAX_VALUE+"");
bloomFilter2.add(Integer.MIN_VALUE+"");
bloomFilter2.add(Long.MAX_VALUE+"");
bloomFilter2.add(Long.MIN_VALUE+"");
// 检查元素
System.out.println(bloomFilter2.mightContain("hello")); // 输出: true(可能存在误判)
System.out.println(bloomFilter2.mightContain("world")); // 输出: true(可能存在误判)
System.out.println(bloomFilter2.mightContain("java")); // 输出: false(不在的一定不在)
System.out.println(bloomFilter2.trueCount());//18
BloomFilter bloomFilter3 = new BloomFilter();
// 添加元素
bloomFilter3.add("hello");
bloomFilter3.add("world");
bloomFilter3.add(Integer.MAX_VALUE+"");
bloomFilter3.add(Integer.MIN_VALUE+"");
bloomFilter3.add(Long.MAX_VALUE+"");
bloomFilter3.add(Long.MIN_VALUE+"");
// 检查元素
System.out.println(bloomFilter3.mightContain("hello")); // 输出: true(可能存在误判)
System.out.println(bloomFilter3.mightContain("world")); // 输出: true(可能存在误判)
System.out.println(bloomFilter3.mightContain("java")); // 输出: false(不在的一定不在)
System.out.println(bloomFilter3.trueCount());//18
}
}
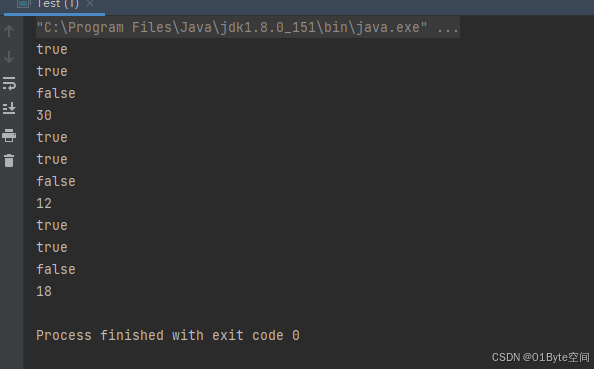
总共创建了3个布隆过滤器实例:bloomFilter、bloomFilter2、bloomFilter3;
每一个里面都是插入了6个不重复的字符串。
bloomFilter.trueCount()统计过滤器中,字符串的hash位置。
BloomFilter bloomFilter = new BloomFilter(1000, 5); //使用5个hash计算位置 30=6*5 BloomFilter bloomFilter2 = new BloomFilter(1000, 2); //使用2个hash计算位置12=6*2 BloomFilter bloomFilter3 = new BloomFilter(); //默认使用3个hash计算位置18=6*3


















 6274
6274

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











