







前言
很多使用Elasticsearch的同学会关心数据存储在ES中的存储容量,会有这样的疑问:xxTB的数据入到ES会使用多少存储空间。这个问题其实很难直接回答的,只有数据写入ES后,才能观察到实际的存储空间。比如同样是1TB的数据,写入ES的存储空间可能差距会非常大,可能小到只有300~400GB,也可能多到6-7TB,为什么会造成这么大的差距呢?究其原因,我们来探究下Elasticsearch中的数据是如何存储。文章中我以Elasticsearch 2.3版本为示例,对应的lucene版本是5.5,Elasticsearch现在已经来到了6.5版本,数字类型、列存等存储结构有些变化,但基本的概念变化不多,文章中的内容依然适用。
Elasticsearch索引结构
Elasticsearch对外提供的是index的概念,可以类比为DB,用户查询是在index上完成的,每个index由若干个shard组成,以此来达到分布式可扩展的能力。比如下图是一个由10个shard组成的index。
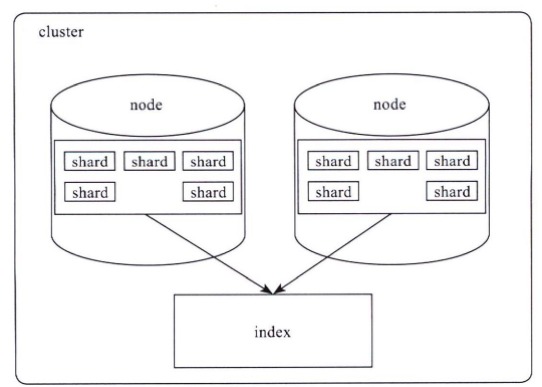
shard是Elasticsearch数据存储的最小单位,index的存储容量为所有shard的存储容量之和。Elasticsearch集群的存储容量则为所有index存储容量之和。
一个shard就对应了一个lucene的library。对于一个shard,Elasticsearch增加了translog的功能,类似于HBase WAL,是数据写入过程中的中间数据,其余的数据都在lucene库中管理的。
所以Elasticsearch索引使用的存储内容主要取决于lucene中的数据存储。
lucene数据存储
下面我们主要看下lucene的文件内容,在了解lucene文件内容前,大家先了解些lucene的基本概念。
lucene基本概念
- segment : lucene内部的数据是由一个个segment组成的,写入lucene的数据并不直接落盘,而是先写在内存中,经过了refresh间隔,lucene才将该时间段写入的全部数据refresh成一个segment,segment多了之后会进行merge成更大的segment。lucene查询时会遍历每个segment完成。由于lucene* 写入的数据是在内存中完成,所以写入效率非常高。但是也存在丢失数据的风险,所以Elasticsearch基于此现象实现了translog,只有在segment数据落盘后,Elasticsearch才会删除对应的translog。
- doc : doc表示lucene中的一条记录
- field :field表示记录中的字段概念,一个doc由若干个field组成。
- term :term是lucene中索引的最小单位,某个field对应的内容如果是全文检索类型,会将内容进行分词,分词的结果就是由term组成的。如果是不分词的字段,那么该字段的内容就是一个term。
- 倒排索引(inverted index): lucene索引的通用叫法,即实现了term到doc list的映射。
- 正排数据:搜索引擎的通用叫法,即原始数据,可以理解为一个doc list。
- docvalues :Elasticsearch中的列式存储的名称,Elasticsearch除了存储原始存储、倒排索引,还存储了一份docvalues,用作分析和排序。
lucene文件内容
lucene包的文件是由很多segment文件组成的,segments_xxx文件记录了lucene包下面的segment文件数量。每个segment会包含如下的文件。
| Name | Extension | Brief Description |
|---|---|---|
| Segment Info | .si | segment的元数据文件 |
| Compound File | .cfs, .cfe | 一个segment包含了如下表的各个文件,为减少打开文件的数量,在segment小的时候,segment的所有文件内容都保存在cfs文件中,cfe文件保存了lucene各文件在cfs文件的位置信息 |
| Fields | .fnm | 保存了fields的相关信息 |
| Field Index | .fdx | 正排存储文件的元数据信息 |
| Field Data | .fdt | 存储了正排存储数据,写入的原文存储在这 |
| Term Dictionary | .tim | 倒排索引的元数据信息 |
| Term Index | .tip | 倒排索引文件,存储了所有的倒排索引数据 |
| Frequencies | .doc | 保存了每个term的doc id列表和term在doc中的词频 |
| Positions | .pos | Stores position information about where a term occurs in the index 全文索引的字段,会有该文件,保存了term在doc中的位置 |
| Payloads | .pay | Stores additional per-position metadata information such as character offsets and user payloads 全文索引的字段,使用了一些像payloads的高级特性会有该文件,保存了term在doc中的一些高级特性 |
| Norms | .nvd, .nvm | 文件保存索引字段加权数据 |
| Per-Document Values | .dvd, .dvm | lucene的docvalues文件,即数据的列式存储,用作聚合和排序 |
| Term Vector Data | .tvx, .tvd, .tvf | Stores offset into the document data file 保存索引字段的矢量信息,用在对term进行高亮,计算文本相关性中使用 |
| Live Documents | .liv | 记录了segment中删除的doc |
测试数据示例
下面我们以真实的数据作为示例,看看lucene中各类型数据的容量占比。
写100w数据,有一个uuid字段,写入的是长度为36位的uuid,字符串总为3600w字节,约为35M。
数据使用一个shard,不带副本,使用默认的压缩算法,写入完成后merge成一个segment方便观察。
使用线上默认的配置,uuid存为不分词的字符串类型。创建如下索引:
PUT test_field
{
"settings": {
"index": {
"number_of_shards": "1",
"number_of_replicas": "0",
"refresh_interval": "30s"
}
},
"mappings": {
"type": {
"_all": {
"enabled": false
},
"properties": {
"uuid": {
"type": "string",
"index": "not_analyzed"
}
}
}
}
}首先写入100w不同的uuid,使用磁盘容量细节如下:
health status index pri rep docs.count docs.deleted store.size pri.store.size
green open test_field 1 0 1000000 0 122.7mb 122.7mb
-rw-r--r-- 1 weizijun staff 41M Aug 19 21:23 _8.fdt
-rw-r--r-- 1 weizijun staff 17K Aug 19 21:23 _8.fdx
-rw-r--r-- 1 weizijun staff 688B Aug 19 21:23 _8.fnm
-rw-r--r-- 1 weizijun staff 494B Aug 19 21:23 _8.si
-rw-r--r-- 1 weizijun staff 265K Aug 19 21:23 _8_Lucene50_0.doc
-rw-r--r-- 1 weizijun staff 44M Aug 19 21:23 _8_Lucene50_0.tim
-rw-r--r-- 1 weizijun staff 340K Aug 19 21:23 _8_Lucene50_0.tip
-rw-r--r-- 1 weizijun staff 37M Aug 19 21:23 _8_Lucene54_0.dvd
-rw-r--r-- 1 weizijun staff 254B Aug 19 21:23 _8_Lucene54_0.dvm
-rw-r--r-- 1 weizijun staff 195B Aug 19 21:23 segments_2
-rw-r--r-- 1 weizijun staff 0B Aug 19 21:20 write.lock可以看到正排数据、倒排索引数据,列存数据容量占比几乎相同,正排数据和倒排数据还会存储Elasticsearch的唯一id字段,所以容量会比列存多一些。
35M的uuid存入Elasticsearch后,数据膨胀了3倍,达到了122.7mb。Elasticsearch竟然这么消耗资源,不要着急下结论,接下来看另一个测试结果。
我们写入100w一样的uuid,然后看看Elasticsearch使用的容量。
health status index pri rep docs.count docs.deleted store.size pri.store.size
green open test_field 1 0 1000000 0 13.2mb 13.2mb
-rw-r--r-- 1 weizijun staff 5.5M Aug 19 21:29 _6.fdt
-rw-r--r-- 1 weizijun staff 15K Aug 19 21:29 _6.fdx
-rw-r--r-- 1 weizijun staff 688B Aug 19 21:29 _6.fnm
-rw-r--r-- 1 weizijun staff 494B Aug 19 21:29 _6.si
-rw-r--r-- 1 weizijun staff 309K Aug 19 21:29 _6_Lucene50_0.doc
-rw-r--r-- 1 weizijun staff 7.0M Aug 19 21:29 _6_Lucene50_0.tim
-rw-r--r-- 1 weizijun staff 195K Aug 19 21:29 _6_Lucene50_0.tip
-rw-r--r-- 1 weizijun staff 244K Aug 19 21:29 _6_Lucene54_0.dvd
-rw-r--r-- 1 weizijun staff 252B Aug 19 21:29 _6_Lucene54_0.dvm
-rw-r--r-- 1 weizijun staff 195B Aug 19 21:29 segments_2
-rw-r--r-- 1 weizijun staff 0B Aug 19 21:26 write.lock这回35M的数据Elasticsearch容量只有13.2mb,其中还有主要的占比还是Elasticsearch的唯一id,100w的uuid几乎不占存储容积。
所以在Elasticsearch中建立索引的字段如果基数越大(count distinct),越占用磁盘空间。
我们再看看存100w个不一样的整型会是如何。
health status index pri rep docs.count docs.deleted store.size pri.store.size
green open test_field 1 0 1000000 0 13.6mb 13.6mb
-rw-r--r-- 1 weizijun staff 6.1M Aug 28 10:19 _42.fdt
-rw-r--r-- 1 weizijun staff 22K Aug 28 10:19 _42.fdx
-rw-r--r-- 1 weizijun staff 688B Aug 28 10:19 _42.fnm
-rw-r--r-- 1 weizijun staff 503B Aug 28 10:19 _42.si
-rw-r--r-- 1 weizijun staff 2.8M Aug 28 10:19 _42_Lucene50_0.doc
-rw-r--r-- 1 weizijun staff 2.2M Aug 28 10:19 _42_Lucene50_0.tim
-rw-r--r-- 1 weizijun staff 83K Aug 28 10:19 _42_Lucene50_0.tip
-rw-r--r-- 1 weizijun staff 2.5M Aug 28 10:19 _42_Lucene54_0.dvd
-rw-r--r-- 1 weizijun staff 228B Aug 28 10:19 _42_Lucene54_0.dvm
-rw-r--r-- 1 weizijun staff 196B Aug 28 10:19 segments_2
-rw-r--r-- 1 weizijun staff 0B Aug 28 10:16 write.lock从结果可以看到,100w整型数据,Elasticsearch的存储开销为13.6mb。如果以int型计算100w数据的长度的话,为400w字节,大概是3.8mb数据。忽略Elasticsearch唯一id字段的影响,Elasticsearch实际存储容量跟整型数据长度差不多。
我们再看一下开启最佳压缩参数对存储空间的影响:
health status index pri rep docs.count docs.deleted store.size pri.store.size
green open test_field 1 0 1000000 0 107.2mb 107.2mb
-rw-r--r-- 1 weizijun staff 25M Aug 20 12:30 _5.fdt
-rw-r--r-- 1 weizijun staff 6.0K Aug 20 12:30 _5.fdx
-rw-r--r-- 1 weizijun staff 688B Aug 20 12:31 _5.fnm
-rw-r--r-- 1 weizijun staff 500B Aug 20 12:31 _5.si
-rw-r--r-- 1 weizijun staff 265K Aug 20 12:31 _5_Lucene50_0.doc
-rw-r--r-- 1 weizijun staff 44M Aug 20 12:31 _5_Lucene50_0.tim
-rw-r--r-- 1 weizijun staff 322K Aug 20 12:31 _5_Lucene50_0.tip
-rw-r--r-- 1 weizijun staff 37M Aug 20 12:31 _5_Lucene54_0.dvd
-rw-r--r-- 1 weizijun staff 254B Aug 20 12:31 _5_Lucene54_0.dvm
-rw-r--r-- 1 weizijun staff 224B Aug 20 12:31 segments_4
-rw-r--r-- 1 weizijun staff 0B Aug 20 12:00 write.lock结果中可以发现,只有正排数据会启动压缩,压缩能力确实强劲,不考虑唯一id字段,存储容量大概压缩到接近50%。
我们还做了一些实验,Elasticsearch默认是开启_all参数的,_all可以让用户传入的整体json数据作为全文检索的字段,可以更方便的检索,但在现实场景中已经使用的不多,相反会增加很多存储容量的开销,可以看下开启_all的磁盘空间使用情况:
health status index pri rep docs.count docs.deleted store.size pri.store.size
green open test_field 1 0 1000000 0 162.4mb 162.4mb
-rw-r--r-- 1 weizijun staff 41M Aug 18 22:59 _20.fdt
-rw-r--r-- 1 weizijun staff 18K Aug 18 22:59 _20.fdx
-rw-r--r-- 1 weizijun staff 777B Aug 18 22:59 _20.fnm
-rw-r--r-- 1 weizijun staff 59B Aug 18 22:59 _20.nvd
-rw-r--r-- 1 weizijun staff 78B Aug 18 22:59 _20.nvm
-rw-r--r-- 1 weizijun staff 539B Aug 18 22:59 _20.si
-rw-r--r-- 1 weizijun staff 7.2M Aug 18 22:59 _20_Lucene50_0.doc
-rw-r--r-- 1 weizijun staff 4.2M Aug 18 22:59 _20_Lucene50_0.pos
-rw-r--r-- 1 weizijun staff 73M Aug 18 22:59 _20_Lucene50_0.tim
-rw-r--r-- 1 weizijun staff 832K Aug 18 22:59 _20_Lucene50_0.tip
-rw-r--r-- 1 weizijun staff 37M Aug 18 22:59 _20_Lucene54_0.dvd
-rw-r--r-- 1 weizijun staff 254B Aug 18 22:59 _20_Lucene54_0.dvm
-rw-r--r-- 1 weizijun staff 196B Aug 18 22:59 segments_2
-rw-r--r-- 1 weizijun staff 0B Aug 18 22:53 write.lock
开启_all比不开启多了40mb的存储空间,多的数据都在倒排索引上,大约会增加30%多的存储开销。所以线上都直接禁用。
然后我还做了其他几个尝试,为了验证存储容量是否和数据量成正比,写入1000w数据的uuid,发现存储容量基本为100w数据的10倍。我还验证了数据长度是否和数据量成正比,发现把uuid增长2倍、4倍,存储容量也响应的增加了2倍和4倍。在此就不一一列出数据了。
lucene各文件具体内容和实现
lucene数据元信息文件
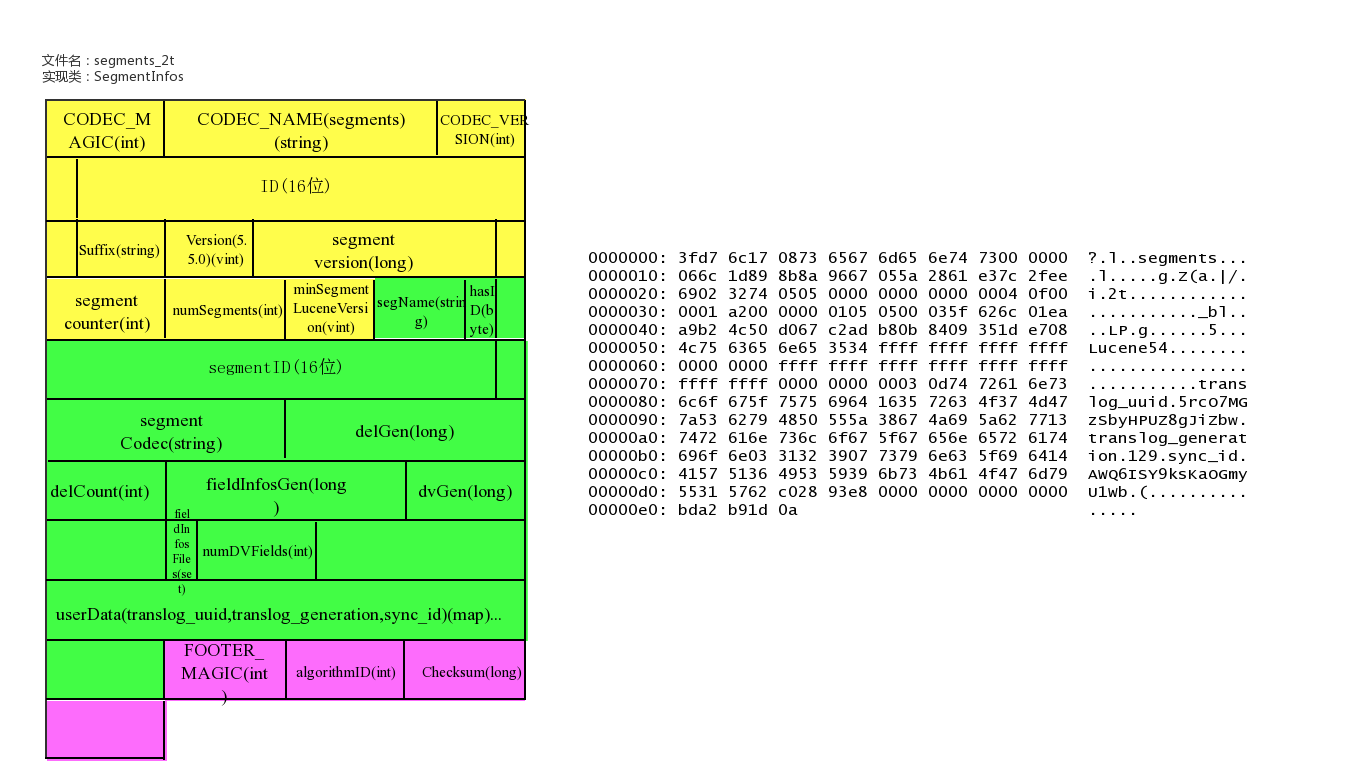
文件名为:segments_xxx
该文件为lucene数据文件的元信息文件,记录所有segment的元数据信息。
该文件主要记录了目前有多少segment,每个segment有一些基本信息,更新这些信息定位到每个segment的元信息文件。
lucene元信息文件还支持记录userData,Elasticsearch可以在此记录translog的一些相关信息。
文件示例
具体实现类
public final class SegmentInfos implements Cloneable, Iterable<SegmentCommitInfo> {
// generation是segment的版本的概念,从文件名中提取出来,实例中为:2t/101
private long generation; // generation of the "segments_N" for the next commit
private long lastGeneration; // generation of the "segments_N" file we last successfully read
// or wrote; this is normally the same as generation except if
// there was an IOException that had interrupted a commit
/** Id for this commit; only written starting with Lucene 5.0 */
private byte[] id;
/** Which Lucene version wrote this commit, or null if this commit is pre-5.3. */
private Version luceneVersion;
/** Counts how often the index has been changed. */
public long version;
/** Used to name new segments. */
// TODO: should this be a long ...?
public int counter;
/** Version of the oldest segment in the index, or null if there are no segments. */
private Version minSegmentLuceneVersion;
private List<SegmentCommitInfo> segments = new ArrayList<>();
/** Opaque Map<String, String> that user can specify during IndexWriter.commit */
public Map<String,String> userData = Collections.emptyMap();
}
/** Embeds a [read-only] SegmentInfo and adds per-commit
* fields.
*
* @lucene.experimental */
public class SegmentCommitInfo {
/** The {@link SegmentInfo} that we wrap. */
public final SegmentInfo info;
// How many deleted docs in the segment:
private int delCount;
// Generation number of the live docs file (-1 if there
// are no deletes yet):
private long delGen;
// Normally 1+delGen, unless an exception was hit on last
// attempt to write:
private long nextWriteDelGen;
// Generation number of the FieldInfos (-1 if there are no updates)
private long fieldInfosGen;
// Normally 1+fieldInfosGen, unless an exception was hit on last attempt to
// write
private long nextWriteFieldInfosGen; //fieldInfosGen == -1 ? 1 : fieldInfosGen + 1;
// Generation number of the DocValues (-1 if there are no updates)
private long docValuesGen;
// Normally 1+dvGen, unless an exception was hit on last attempt to
// write
private long nextWriteDocValuesGen; //docValuesGen == -1 ? 1 : docValuesGen + 1;
// TODO should we add .files() to FieldInfosFormat, like we have on
// LiveDocsFormat?
// track the fieldInfos update files
private final Set<String> fieldInfosFiles = new HashSet<>();
// Track the per-field DocValues update files
private final Map<Integer,Set<String>> dvUpdatesFiles = new HashMap<>();
// Track the per-generation updates files
@Deprecated
private final Map<Long,Set<String>> genUpdatesFiles = new HashMap<>();
private volatile long sizeInBytes = -1;
}
segment的元信息文件
文件后缀:.si
每个segment都有一个.si文件,记录了该segment的元信息。
segment元信息文件中记录了segment的文档数量,segment对应的文件列表等信息。
文件示例

具体实现类
/**
* Information about a segment such as its name, directory, and files related
* to the segment.
*
* @lucene.experimental
*/
public final class SegmentInfo {
// _bl
public final String name;
/** Where this segment resides. */
public final Directory dir;
/** Id that uniquely identifies this segment. */
private final byte[] id;
private Codec codec;
// Tracks the Lucene version this segment was created with, since 3.1. Null
// indicates an older than 3.0 index, and it's used to detect a too old index.
// The format expected is "x.y" - "2.x" for pre-3.0 indexes (or null), and
// specific versions afterwards ("3.0.0", "3.1.0" etc.).
// see o.a.l.util.Version.
private Version version;
private int maxDoc; // number of docs in seg
private boolean isCompoundFile;
private Map<String,String> diagnostics;
private Set<String> setFiles;
private final Map<String,String> attributes;
}fields信息文件
文件后缀:.fnm
该文件存储了fields的基本信息。
fields信息中包括field的数量,field的类型,以及IndexOpetions,包括是否存储、是否索引,是否分词,是否需要列存等等。
文件示例

具体实现类
/**
* Access to the Field Info file that describes document fields and whether or
* not they are indexed. Each segment has a separate Field Info file. Objects
* of this class are thread-safe for multiple readers, but only one thread can
* be adding documents at a time, with no other reader or writer threads
* accessing this object.
**/
public final class FieldInfo {
/** Field's name */
public final String name;
/** Internal field number */
//field在内部的编号
public final int number;
//field docvalues的类型
private DocValuesType docValuesType = DocValuesType.NONE;
// True if any document indexed term vectors
private boolean storeTermVector;
private boolean omitNorms; // omit norms associated with indexed fields
//index的配置项
private IndexOptions indexOptions = IndexOptions.NONE;
private boolean storePayloads; // whether this field stores payloads together with term positions
private final Map<String,String> attributes;
// docvalues的generation
private long dvGen;
}数据存储文件
文件后缀:.fdx, .fdt
索引文件为.fdx,数据文件为.fdt,数据存储文件功能为根据自动的文档id,得到文档的内容,搜索引擎的术语习惯称之为正排数据,即doc_id -> content,es的_source数据就存在这
索引文件记录了快速定位文档数据的索引信息,数据文件记录了所有文档id的具体内容。
文件示例

具体实现类
/**
* Random-access reader for {@link CompressingStoredFieldsIndexWriter}.
* @lucene.internal
*/
public final class CompressingStoredFieldsIndexReader implements Cloneable, Accountable {
private static final long BASE_RAM_BYTES_USED = RamUsageEstimator.shallowSizeOfInstance(CompressingStoredFieldsIndexReader.class);
final int maxDoc;
//docid索引,快速定位某个docid的数组坐标
final int[] docBases;
//快速定位某个docid所在的文件offset的startPointer
final long[] startPointers;
//平均一个chunk的文档数
final int[] avgChunkDocs;
//平均一个chunk的size
final long[] avgChunkSizes;
final PackedInts.Reader[] docBasesDeltas; // delta from the avg
final PackedInts.Reader[] startPointersDeltas; // delta from the avg
}
/**
* {@link StoredFieldsReader} impl for {@link CompressingStoredFieldsFormat}.
* @lucene.experimental
*/
public final class CompressingStoredFieldsReader extends StoredFieldsReader {
//从fdt正排索引文件中获得
private final int version;
// field的基本信息
private final FieldInfos fieldInfos;
//fdt正排索引文件reader
private final CompressingStoredFieldsIndexReader indexReader;
//从fdt正排索引文件中获得,用于指向fdx数据文件的末端,指向numChunks地址4
private final long maxPointer;
//fdx正排数据文件句柄
private final IndexInput fieldsStream;
//块大小
private final int chunkSize;
private final int packedIntsVersion;
//压缩类型
private final CompressionMode compressionMode;
//解压缩处理对象
private final Decompressor decompressor;
//文档数量,从segment元数据中获得
private final int numDocs;
//是否正在merge,默认为false
private final boolean merging;
//初始化时new了一个BlockState,BlockState记录下当前正排文件读取的状态信息
private final BlockState state;
//chunk的数量
private final long numChunks; // number of compressed blocks written
//dirty chunk的数量
private final long numDirtyChunks; // number of incomplete compressed blocks written
//是否close,默认为false
private boolean closed;
}倒排索引文件
索引后缀:.tip,.tim
倒排索引也包含索引文件和数据文件,.tip为索引文件,.tim为数据文件,索引文件包含了每个字段的索引元信息,数据文件有具体的索引内容。
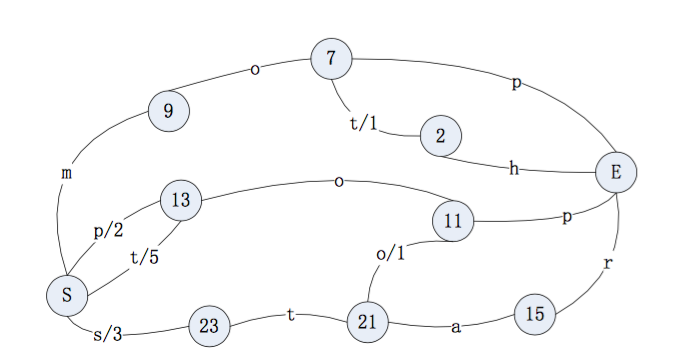
5.5.0版本的倒排索引实现为FST tree,FST tree的最大优势就是内存空间占用非常低 ,具体可以参看下这篇文章:http://www.cnblogs.com/bonelee/p/6226185.html
http://examples.mikemccandless.com/fst.py?terms=&cmd=Build+it 为FST图实例,可以根据输入的数据构造出FST图
输入到 FST 中的数据为:
String inputValues[] = {"mop","moth","pop","star","stop","top"};
long outputValues[] = {0,1,2,3,4,5};生成的 FST 图为:
文件示例

具体实现类
public final class BlockTreeTermsReader extends FieldsProducer {
// Open input to the main terms dict file (_X.tib)
final IndexInput termsIn;
// Reads the terms dict entries, to gather state to
// produce DocsEnum on demand
final PostingsReaderBase postingsReader;
private final TreeMap<String,FieldReader> fields = new TreeMap<>();
/** File offset where the directory starts in the terms file. */
/索引数据文件tim的数据的尾部的元数据的地址
private long dirOffset;
/** File offset where the directory starts in the index file. */
//索引文件tip的数据的尾部的元数据的地址
private long indexDirOffset;
//semgent的名称
final String segment;
//版本号
final int version;
//5.3.x index, we record up front if we may have written any auto-prefix terms,示例中记录的是false
final boolean anyAutoPrefixTerms;
}
/**
* BlockTree's implementation of {@link Terms}.
* @lucene.internal
*/
public final class FieldReader extends Terms implements Accountable {
//term的数量
final long numTerms;
//field信息
final FieldInfo fieldInfo;
final long sumTotalTermFreq;
//总的文档频率
final long sumDocFreq;
//文档数量
final int docCount;
//字段在索引文件tip中的起始位置
final long indexStartFP;
final long rootBlockFP;
final BytesRef rootCode;
final BytesRef minTerm;
final BytesRef maxTerm;
//longs:metadata buffer, holding monotonic values
final int longsSize;
final BlockTreeTermsReader parent;
final FST<BytesRef> index;
}倒排链文件
文件后缀:.doc, .pos, .pay
.doc保存了每个term的doc id列表和term在doc中的词频
全文索引的字段,会有.pos文件,保存了term在doc中的位置
全文索引的字段,使用了一些像payloads的高级特性才会有.pay文件,保存了term在doc中的一些高级特性
文件示例

具体实现类
/**
* Concrete class that reads docId(maybe frq,pos,offset,payloads) list
* with postings format.
*
* @lucene.experimental
*/
public final class Lucene50PostingsReader extends PostingsReaderBase {
private static final long BASE_RAM_BYTES_USED = RamUsageEstimator.shallowSizeOfInstance(Lucene50PostingsReader.class);
private final IndexInput docIn;
private final IndexInput posIn;
private final IndexInput payIn;
final ForUtil forUtil;
private int version;
//不分词的字段使用的是该对象,基于skiplist实现了倒排链
final class BlockDocsEnum extends PostingsEnum {
}
//全文检索字段使用的是该对象
final class BlockPostingsEnum extends PostingsEnum {
}
//包含高级特性的字段使用的是该对象
final class EverythingEnum extends PostingsEnum {
}
}列存文件(docvalues)
文件后缀:.dvm, .dvd
索引文件为.dvm,数据文件为.dvd。
lucene实现的docvalues有如下类型:
- 1、NONE 不开启docvalue时的状态
- 2、NUMERIC 单个数值类型的docvalue主要包括(int,long,float,double)
- 3、BINARY 二进制类型值对应不同的codes最大值可能超过32766字节,
- 4、SORTED 有序增量字节存储,仅仅存储不同部分的值和偏移量指针,值必须小于等于32766字节
- 5、SORTED_NUMERIC 存储数值类型的有序数组列表
- 6、SORTED_SET 可以存储多值域的docvalue值,但返回时,仅仅只能返回多值域的第一个docvalue
- 7、对应not_anaylized的string字段,使用的是SORTED_SET类型,number的类型是SORTED_NUMERIC类型
其中SORTED_SET 的 SORTED_SINGLE_VALUED类型包括了两类数据 : binary + numeric, binary是按ord排序的term的列表,numeric是doc到ord的映射。
文件示例

具体实现类
/** reader for {@link Lucene54DocValuesFormat} */
final class Lucene54DocValuesProducer extends DocValuesProducer implements Closeable {
//number类型的field的列存列表
private final Map<String,NumericEntry> numerics = new HashMap<>();
//字符串类型的field的列存列表
private final Map<String,BinaryEntry> binaries = new HashMap<>();
//有序字符串类型的field的列存列表
private final Map<String,SortedSetEntry> sortedSets = new HashMap<>();
//有序number类型的field的列存列表
private final Map<String,SortedSetEntry> sortedNumerics = new HashMap<>();
//字符串类型的field的ords列表
private final Map<String,NumericEntry> ords = new HashMap<>();
//docId -> address -> ord 中field的ords列表
private final Map<String,NumericEntry> ordIndexes = new HashMap<>();
//field的数量
private final int numFields;
//内存使用量
private final AtomicLong ramBytesUsed;
//数据源的文件句柄
private final IndexInput data;
//文档数
private final int maxDoc;
// memory-resident structures
private final Map<String,MonotonicBlockPackedReader> addressInstances = new HashMap<>();
private final Map<String,ReverseTermsIndex> reverseIndexInstances = new HashMap<>();
private final Map<String,DirectMonotonicReader.Meta> directAddressesMeta = new HashMap<>();
//是否正在merge
private final boolean merging;
}
/** metadata entry for a numeric docvalues field */
static class NumericEntry {
private NumericEntry() {}
/** offset to the bitset representing docsWithField, or -1 if no documents have missing values */
long missingOffset;
/** offset to the actual numeric values */
//field的在数据文件中的起始地址
public long offset;
/** end offset to the actual numeric values */
//field的在数据文件中的结尾地址
public long endOffset;
/** bits per value used to pack the numeric values */
public int bitsPerValue;
//format类型
int format;
/** count of values written */
public long count;
/** monotonic meta */
public DirectMonotonicReader.Meta monotonicMeta;
//最小的value
long minValue;
//Compressed by computing the GCD
long gcd;
//Compressed by giving IDs to unique values.
long table[];
/** for sparse compression */
long numDocsWithValue;
NumericEntry nonMissingValues;
NumberType numberType;
}
/** metadata entry for a binary docvalues field */
static class BinaryEntry {
private BinaryEntry() {}
/** offset to the bitset representing docsWithField, or -1 if no documents have missing values */
long missingOffset;
/** offset to the actual binary values */
//field的在数据文件中的起始地址
long offset;
int format;
/** count of values written */
public long count;
//最短字符串的长度
int minLength;
//最长字符串的长度
int maxLength;
/** offset to the addressing data that maps a value to its slice of the byte[] */
public long addressesOffset, addressesEndOffset;
/** meta data for addresses */
public DirectMonotonicReader.Meta addressesMeta;
/** offset to the reverse index */
public long reverseIndexOffset;
/** packed ints version used to encode addressing information */
public int packedIntsVersion;
/** packed ints blocksize */
public int blockSize;
}
转自:https://elasticsearch.cn/article/6178


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









