









1、查看数据库当前实例使用的是哪个UNDO表空间
SQL> show parameter undo_tablespace
NAME TYPE VALUE
------------------------------------ ----------- ------------------------------
undo_tablespace string UNDOTEMP
2、查看UNDO表空间对应的数据文件和大小
SQL> set lines 200 pages 200
SQL> col file_name for a60
SQL> col tablespace_name for a20
SQL> select tablespace_name,file_name,bytes/1024/1024 MB from dba_data_files where tablespace_name like '%UNDO%';
TABLESPACE_NAME FILE_NAME MB
-------------------- ------------------------------------------------------------ ----------
UNDOTEMP /oradata/wind2/undotbstemp02.dbf 32610
UNDOTEMP /oradata/wind2/undotbstemp01.dbf 19.5390625
UNDOTEMP /backup/file/undotbstemp03.dbf 32767.9844
3、查看undo表空间属性
SQL> show parameter undo
NAME TYPE VALUE
------------------------------------ ----------- ------------------------------
temp_undo_enabled boolean FALSE
undo_management string AUTO
undo_retention integer 900
undo_tablespace string UNDOTEMP
SQL> select retention,tablespace_name from dba_tablespaces where tablespace_name like '%UNDO%';
RETENTION TABLESPACE_NAME
----------- --------------------
NOGUARANTEE UNDOTEMP
4、查看undo表空间当前的使用情况
SQL> set lines 200 pages 200
SQL> col tablespace_name for a30
SQL> select tablespace_name,status,sum(bytes)/1024/1024 MB from dba_undo_extents group by tablespace_name,status;
TABLESPACE_NAME STATUS MB
------------------------------ --------- ----------
UNDOTEMP UNEXPIRED 144.75
UNDOTEMP EXPIRED 2893.375
undo段中区的状态说明:
-
free:区未分配给任何一个段
-
active:已经被分配给段,并且这个段被事务所使用,且事务没有提交,不能覆盖。 (区被未提交的事务使用)
-
unexpired:事务已经提交,但是区还在段中,还没有被覆盖且未达到undo_retention设定的时间。
-
expired:oracle希望已提交事务对应的 undo 表空间中的 undo 段中的区再保留一段时间(保留的时间就是undo_retention)。
NOGUARANTEE 情况下,原则上 oracle 尽量不覆盖 unexpired 的区,但是如果 undo 空间压力较大,oracle 也会去覆盖。
GUARANTEE 情况下,oracle 强制保留 retention 时间内的内容,这时候 free 和 expired 空间不足的话,新事物将失败。
unexpired 的区存在时间超过 undo_retention 设定的时间,状态就会变为 expired 。过期后的区就可以被覆盖了。原则上expired的区一般不会释放成 free 。
生产环境不建议将 UNDOTBS 的 retention 设置成 GUARANTEE,这是很危险的。
与一般的用户表空间不同,undo表空间不能通过dba_free_spaces来确定实际的使用情况,undo表空间除了active状态的extent不能被覆盖外。其他状态的extent都是可以空间复用的。
如果 active 的 extent 总大小很大,说明系统中存在大事务。如果 undo 资源耗尽(active 接近 undotbs 的总大小),可能导致事务失败。
5、查看什么事务占用了过多的 undo
SQL> select addr,used_ublk,used_urec,inst_id from gv$transaction order by 2 desc;
ADDR USED_UBLK USED_UREC INST_ID
---------------- ---------- ---------- ----------
0000000845C45250 1 1 1
ADDR: 事务的内存地址
USED_UBLK:事务使用的undo block数量
USED_UREC:事务使用的undo record(undo前镜像的条数,例如:delete删除的记录数)
6、查看占用undo的事务执行了什么sql:
SQL> set lines 200 pages 200
SQL> col program for a30
SQL> col machine for a30
SQL> select sql_id,last_call_et,program,machine from gv$session where taddr='0000000845C45250';
SQL_ID LAST_CALL_ET PROGRAM MACHINE
------------- ------------ ------------------------------ ------------------------------
6tvs53tr463f1 1813 JDBC Thin Client STUDY
LAST_CALL_ET: 上一次调用到现在为止过了多长时间,单位为秒,途中显示过了1813s (既可以理解为sql已经运行了1813s)。
SQL> set long 99999
SQL> set lines 100 pages 1000
SQL> select sql_fulltext from v$sql where SQL_ID='6tvs53tr463f1';
SQL_FULLTEXT
-------------------------------------------------------------
delete from test
7.显示undo使用情况的统计信息:
SQL> SELECT TO_CHAR(BEGIN_TIME,'HH24:MI:SS') BEGIN_TIME,TO_CHAR(END_TIME,'HH24:MI:SS') END_TIME,UNDOBLKS FROM V$UNDOSTAT;
BEGIN_TI END_TIME UNDOBLKS
-------- -------- ----------
20:34:17 20:38:53 331
20:24:17 20:34:17 907
20:14:17 20:24:17 716
20:04:17 20:14:17 788
19:54:17 20:04:17 1055
19:44:17 19:54:17 729
8.查询undo segment的信息
SQL> SELECT a.name, b.xacts, b.writes, b.extents FROM v$rollname a, v$rollstat b WHERE a.usn=b.usn;
NAME XACTS WRITES EXTENTS
------------------------------ ---------- ---------- ----------
SYSTEM 0 2232428 17
_SYSSMU1_82673609$ 0 1541332906 4
_SYSSMU2_1782568576$ 0 1032641054 4
_SYSSMU3_3560362476$ 0 2566194908 4
_SYSSMU4_740531384$ 0 1892215558 4
_SYSSMU5_763993634$ 0 1061775626 4
USN:Rollback segment number
XACTS:Number of active transactions
EXTENTS:Number of extents in the rollback segment
WRITES:Number of bytes written to the rollback segment
补充知识
1、undo的读取方式是单块读的,所以事务的回滚比较慢
2、system表空间中有一个系统回滚段,如下情况会用到系统回滚段
- 对数据字典进行操作时(eg:修改表结构)
- undo表空间出现问题时
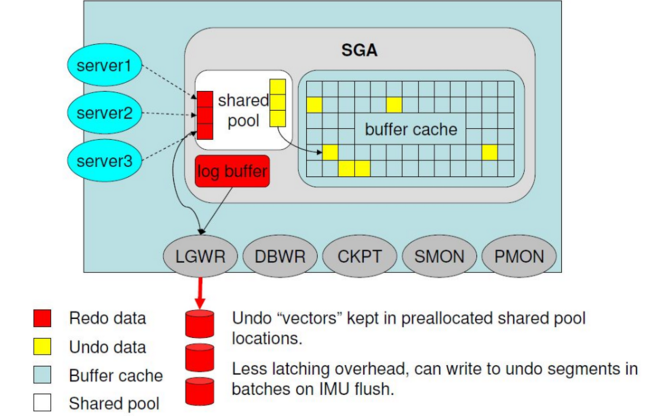
3.一个事务开始的时候,在shared pool中分一个IMU(in memory undo) buffer,将所有的回滚信息写到IMU buffer中。一个事务开始后,需要回滚块的时候不需要从从磁盘读undo block,直接从shared pool 中分IMU BUFFER,之后回滚信息写到imubuffer中,回滚信息写入的时候也要产生redo,但是imubuffer减少了物理io ,针对IMUbuffer 在shared中会生成专门供其使用的redo日志区,叫做private redo 。















 1162
1162

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









